All Activity
- Yesterday
-
 Skara joined the community
Skara joined the community -
 dsgsg joined the community
dsgsg joined the community -
 HiKitty joined the community
HiKitty joined the community - Last week
-
 zagaxicotencatl joined the community
zagaxicotencatl joined the community -

Asynchronous Call By Reference on Real-Time target (cRIO)
Mads replied to Sam Dexter's topic in LabVIEW General
They have to be compiled for the target yes, but you just include them in the application build and configure that to save them where they should be...I often just deploy the executable, then continue to work on the other VIs. If they are run from the development environment they still find the compiled dynamic VIs. It is not ideal, but not that big of a hassle. -

Asynchronous Call By Reference on Real-Time target (cRIO)
Sam Dexter replied to Sam Dexter's topic in LabVIEW General
Still, it looks rather cumbersome. I was hoping to get something configurable at the run time. Maybe need to look at the classes instead of simple super-loop VIs to get to a truly run-time configurable system. -
Asynchronous Call By Reference on Real-Time target (cRIO)
Sam Dexter replied to Sam Dexter's topic in LabVIEW General
Thank you Mads. There was a couple of issues with that project. First, the paths were Windows style and not understood by cRIO. Second, yes, you were right - the referenced VIs had to be in the folder on the cRIO. However, they still had to be compiled along with the launcher to be executable. Otherwise it didn't work. -
 wanwan joined the community
wanwan joined the community -
 ztb085524 joined the community
ztb085524 joined the community -
 ipovaric joined the community
ipovaric joined the community -
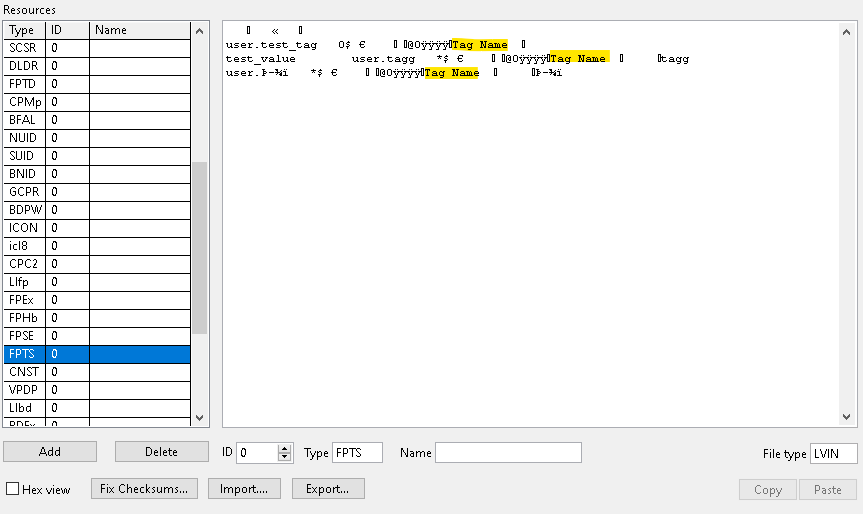
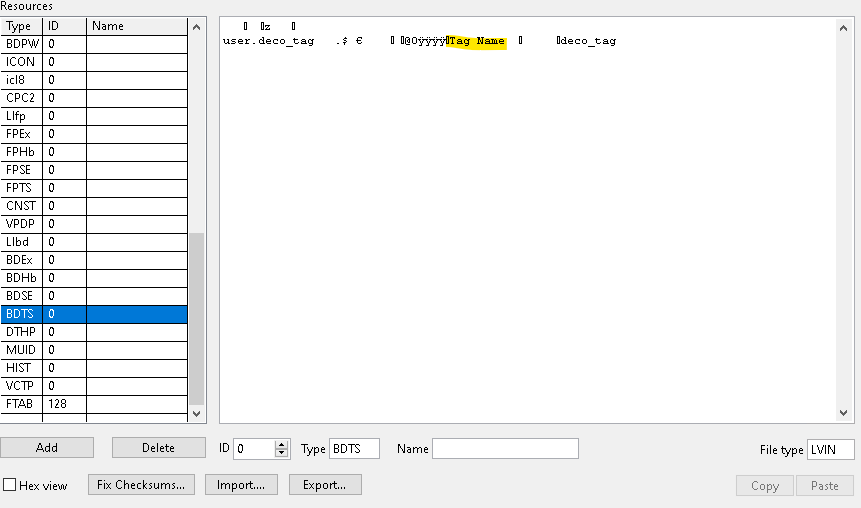
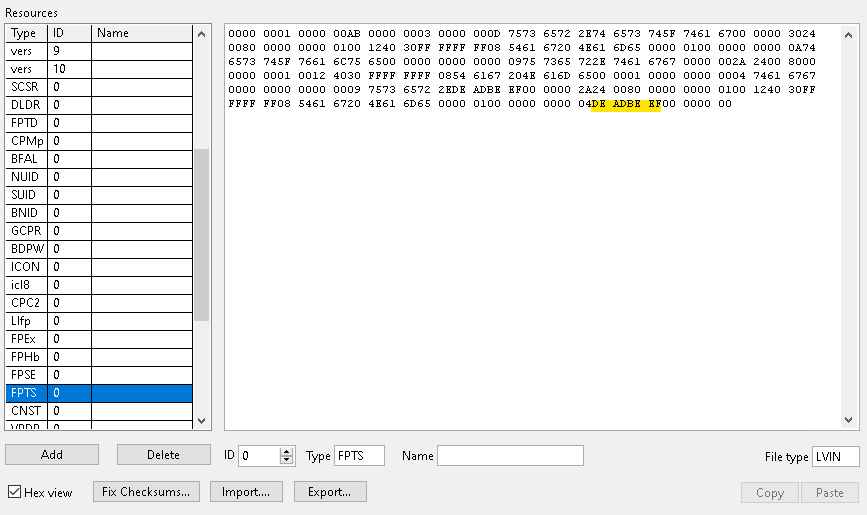
@Petru_Tarabuta If you are still looking for all the object tags rather than VI tags consider the examples below as it is LV version agnostic (or at least agnostic since the VI file format standard this tool supports). One thing to note is the method mentioned above assumes printable characters are in the tag name. Using the low level VI manipulation vi explorer from here https://github.com/flarn2006/VILab is a good way to see this. I think you are better off keying off "Tag Name" since tag names technically don't have to be printable ASCII. See example snip where DEADBEEF in hex would not be printable.

- Earlier
-
 Perfect for the OP if that suffices then.
Perfect for the OP if that suffices then. -
 There was a medium post for the 2023 release which made a lot of features available in the free edition https://archive.ph/53COu (originally: https://create.vi/ni-and-jki-partnering-on-package-management-in-labview-d243b13ae3a6. Apparently he deleted medium but never republished the content.) I did not realize until now that apparently VIPM API is also included in the free edition! The VI package configuration editor can automatically scan a project for dependencies and create a vipc file. The only pro feature left for vipc files seems to be including the packages' content (sort of).
There was a medium post for the 2023 release which made a lot of features available in the free edition https://archive.ph/53COu (originally: https://create.vi/ni-and-jki-partnering-on-package-management-in-labview-d243b13ae3a6. Apparently he deleted medium but never republished the content.) I did not realize until now that apparently VIPM API is also included in the free edition! The VI package configuration editor can automatically scan a project for dependencies and create a vipc file. The only pro feature left for vipc files seems to be including the packages' content (sort of). -
 Here is the Community Edition announcement. https://www.jki.net/blog/news/vipm-2020-community-edition
Here is the Community Edition announcement. https://www.jki.net/blog/news/vipm-2020-community-edition -
 I recently created a VIPC file with an unregistered free edition. I too thought it was a pro feature until I went to try to make one for the Icon Editor.
I recently created a VIPC file with an unregistered free edition. I too thought it was a pro feature until I went to try to make one for the Icon Editor. -
Just download VIPM today and activate a 30day trial to try out VIPC files. Pretty sure it is a pro feature. You may be able to use VIPC files in the Community version but I'm sure you can't create them without the pro version. Maybe it's changed since I last looked though.
-
This feature is the VI Package Configuration (VIPC) and is free and included in the community version of VIPM. The VIPC can contain a list of packages to install, or it can contain the list, along with the actual packages. This is quite handy since you can have a single VIPC file that you double click, and all those packages and their dependencies are installed offline (NIPM should take notes).
-
 Any good suggestion should be considered and integrated into the software.
Any good suggestion should be considered and integrated into the software. -
 Nice use of Tag Engine and muParser. I've done similar but without the nice UI. Is this an open source project?
Nice use of Tag Engine and muParser. I've done similar but without the nice UI. Is this an open source project? -
Asynchronous Call By Reference on Real-Time target (cRIO)
Mads replied to Sam Dexter's topic in LabVIEW General
If you start the VIs manually y clicking on the run-button you are really just launching VIs in memory from the host machine, not sourcing them from the file path. Have you deployed these VIs to the correct folders on the cRIO target so that the code will actually find them there (what error code doe sthe asyncronous call give?)? The atached project was not a real-time project so what the real-time application build pushed to the target is unclear...Once the files are where they are supposed to the launch will not be shown as they will run on the target with no user interface (unlike a VI that is manually started from the host) so you should add code to verify that they are indeed launching (make them write a log f.eks)... -
Curious if anybody can suggest a solution to my problem. I want to programatically call a few VIs and be able to stop them and restart on cRIO. A simple test project works fine on the PC but fails to restart the VIs on the real-time target. They do stop and I can manually restart them clicking the arrow but not programatically. I wonder if anybody can point out what I am doing wrong here (maybe overlooking something)? Thanks in advance. Async Call.zip
-
Another option would be to use the "Database Options" callback. This is called before client Main Sequence. The DB connection string is located at: Parameters.DatabaseOptions.ConnectionString Unfortunately it seems that there is no option to gather this string using TS API, but the custom Operator Interface at start can eventually run in background a dedicated sequence just to get it. In this case it would be better also to set: Parameters.DatabaseOptions.DisableDatabaseLogging = True to avoid adding useless log entries in DB when calling the dedicated sequence at each Operator Interface start.
-
 I do not think that copyright laws cares about what programming language you used to copy the UI of an application. You UI is an almost exact copy of the TestStand Sequence Editor, so why not use TestStand?
I do not think that copyright laws cares about what programming language you used to copy the UI of an application. You UI is an almost exact copy of the TestStand Sequence Editor, so why not use TestStand? -
 looking forward to your release
looking forward to your release -
What are some choices for producer-consumer protocols?
ShaunR replied to Reds's topic in LabVIEW General
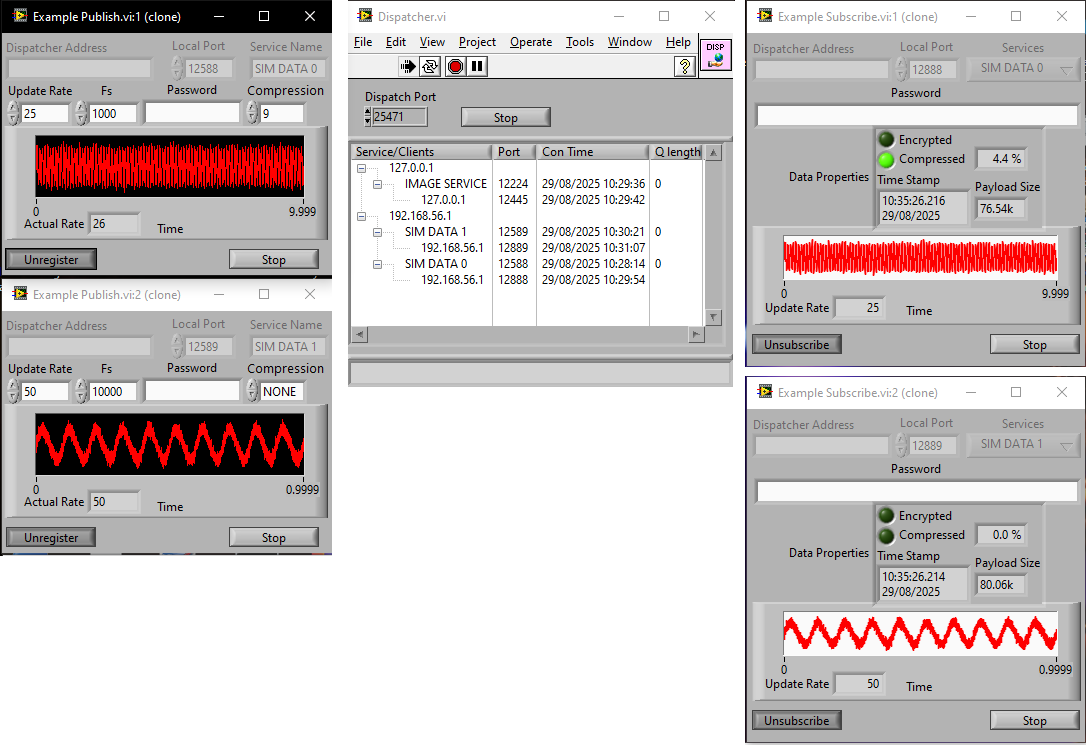
As an addendum... I did something very similar to you many moons ago. Maybe it will give you some ideas. Here is "Dispatcher". Should work fine for you as long as you don't select TLS. Just open the project and run the file Demo - Run ME.vi (then press Register and Subscribe buttons). It also does stuff like compression and blowfish encryption. It's a simple custom, home-grown, protocol that I wrote to explore high-speed data streaming before the more modern protocols were available. The Dispatcher, Publishers and Subscribers can run on any machine that has network access-they don't all have to be local to each other. There is an API that can be used to implement it in applications. It's not really a product so not much in the way of documentation, I'm afraid. Dispatcher.zip
-
What are some choices for producer-consumer protocols?
ShaunR replied to Reds's topic in LabVIEW General
Tough one for LabVIEW. It's a bit like RTSP - there's nothing until someone writes it. OpenSSL has QUIC support. M$ have .NET support and MsQuic. RabbitMQ is discussing whether they should or not. I will support it later this year (waiting for OpenSSL version 3.6). I have some LabVIEW prototypes that I've played with and it's damned fast with almost no overhead. It has in-built failover and multiplexed channels making it ideal for your use case. Your idea of streaming directly is a good one, though. You don't really need a higher protocol unless you can identify a particular problem you need to overcome. Websockets is another that would be a good start because you would be able to have an Apache/Nginx server for routing or even send the data directly to browsers. Hmmm. Yes. Considering where you are now I would recommend Websockets. They are probably the easiest and get you almost all the way to where you want to be and a good start for expansion later for streaming in other more efficient and scalable protocols like QUIC. I think there are a few LabVIEW Websocket implementations to choose from so you wouldn't have to write your own. -

What are some choices for producer-consumer protocols?
Reds replied to Reds's topic in LabVIEW General
In theory maybe.... But how would I get LabVIEW to create QUIC connections? -
Not sure what a "wheel" means in this context. I've only ever seen it in context of A.I. python scripts. If you are just looking at toolkits installed with the JKI Package Manager then the full version can create super packages where you can create a list of toolkits to install. you could then walk from PC to PC with that package and install them with the package manager.
-
What are some choices for producer-consumer protocols?
ShaunR replied to Reds's topic in LabVIEW General
QUIC -

What are some choices for producer-consumer protocols?
Antoine Chalons replied to Reds's topic in LabVIEW General
I would suggest rabbitmq, i want(ed) to present it at a LabVIEW user group (LUGE) but haven't done it yet. It's very powerful. I use redis and did a quick presentation (in french) at LUGE recently, i haven't used the stream feature though, I only used it as cache. -
 Interesting, thanks for the response
Interesting, thanks for the response -
No - I've always maintained completely separate office and development machines on two separate physical Ethernet networks. In my opinion, that will be unavoidable in the modern cyber threat environment. You can't give people (or even yourself) local Admin account access on any network that is used for browsing the Internet, reading email or doing normal office stuff. Personally, if I'm doing Dev stuff on my dev machine, I'll pop open a RDP session into my office machine to do normal office stuff. Devs needs to have Admin account access on their dev machines. Devs should never have Admin account access on their office machines. Full stop.