All Activity
- Yesterday
-
 narwal2024 joined the community
narwal2024 joined the community -
 Of course not! But TDMS is binary, text is ... well text. And that means it needs a lot more memory. When you convert from TDMS to text, it needs temporarily whatever the TDMS file needs plus for the text which is requiring even more memory. Your Matlab and Python program is not going to do calculation on the text, so it needs to read the large text file, convert it back to real numbers and then do computation on those numbers. If you instead import the TDMS data directly to your other program it can do the conversion from TDMS to its own internal format directly and there is no need for any text file to share the data.
Of course not! But TDMS is binary, text is ... well text. And that means it needs a lot more memory. When you convert from TDMS to text, it needs temporarily whatever the TDMS file needs plus for the text which is requiring even more memory. Your Matlab and Python program is not going to do calculation on the text, so it needs to read the large text file, convert it back to real numbers and then do computation on those numbers. If you instead import the TDMS data directly to your other program it can do the conversion from TDMS to its own internal format directly and there is no need for any text file to share the data. -
 jaxka joined the community
jaxka joined the community -
It was equally as bad as Gemini in my work with Task Scheduler. It is far too much to paste in here but I created a Task with the command line, and provided it then said: This all works but I'd like to turn off the feature Stop the task if it runs longer than 3 days, and turn off the Start the task only if computer is on AC Power. What command line switches do I need for this? Gemini made up switches, and I had to keep pasting back the error I got over and over with Google eventually telling me it isn't possible. I just hit the limit on free Grok messages and it had similar behavior. I'd run the command it gave with a paragraph explaining how it should work. I'd reply back with the error. It would tell me why the error existed and what command to use. That would generate a new error which I would tell it, and it would do the same. Over and over until I can't chat with it anymore. I use AI primarily for writing assistance, but coding or technical assistance on the surface looks great. But in practice is lacking.
-
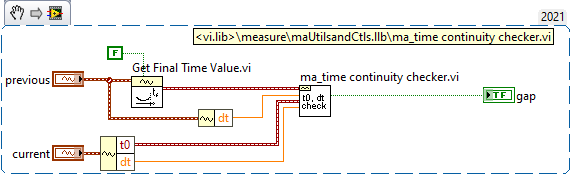
Aren't DVR's just LabVIEW's take on pointers?
-
 There should be a way to work with very large files in LabVIEW without having to keep the entire file in memory. Many years ago I worked with a very large file in Matlab (well, back then it was a very large file) and I extensively used the function memmapfile: https://se.mathworks.com/help/matlab/ref/memmapfile.html It is a way to map a file on the harddrive and access its content without having to keep the entire file in workspace memory. A bit slower I assume but far less load on the RAM! There must be a similar method in LabVIEW. EDIT: I found this old thread: https://forums.ni.com/t5/LabVIEW/Is-there-a-way-to-read-only-a-portion-of-a-TDMS-file-without/td-p/1784752 This is something similar to what cordm refers to: Best practice regardless of language must always be to handle large files in chunks.
There should be a way to work with very large files in LabVIEW without having to keep the entire file in memory. Many years ago I worked with a very large file in Matlab (well, back then it was a very large file) and I extensively used the function memmapfile: https://se.mathworks.com/help/matlab/ref/memmapfile.html It is a way to map a file on the harddrive and access its content without having to keep the entire file in workspace memory. A bit slower I assume but far less load on the RAM! There must be a similar method in LabVIEW. EDIT: I found this old thread: https://forums.ni.com/t5/LabVIEW/Is-there-a-way-to-read-only-a-portion-of-a-TDMS-file-without/td-p/1784752 This is something similar to what cordm refers to: Best practice regardless of language must always be to handle large files in chunks. -
 So, MATLAB or Python are more efficient to convert TMDS to .txt?
So, MATLAB or Python are more efficient to convert TMDS to .txt? -
 hightd joined the community
hightd joined the community - Last week
-
Is there any way to create a strictly typed VI refnum to some regular labview code without having that code saved as it's own file? I'm okay with even the hackiest solutions/ideas that are not likely to break with every new release. Ideally, I'd be using this in an XNode to have a resizable structure, define the code in the lambda, and capture variables as well. One thing I thought about is getting LabVIEW to compile a temporary VI at edit time, storing the compiled code in a buffer on the block diagram, and finding some method to load VI's from memory if one exists. That way it can be used in an executable. Unfortunately, I don't know of any such methods. For context, I am trying to create anonymous functions in LabVIEW to facilitate some basic functional programming concepts. I already have malleable VIs made using Call By Reference for things like map, filter, and reduce that accept a strict VI ref and an iterable (map, array, set, etc.). I also have a quick drop plugin that automates stuffing code selected from a block diagram into a new, automatically generated VI with an obfuscated name, replacing the code on the original block diagram with a strict SVR to the new VI, and saving the new VI in a top level virtual folder called "lambdas" out of the way. My current goal is to eliminate the need to have the VI saved on disk and still be able to build executables and define the referenced code on the block diagram of the VI that will use it. I recently learned about XNodes and thought I could make a working version of the closure structure with them, but they appear to be just like vim's with VI scripting. Ultimately, they seem no better than my quick drop plugin for this.
-
You should have used Grok...
-
 Eduardo Ludgero joined the community
Eduardo Ludgero joined the community -
 rsaxvc joined the community
rsaxvc joined the community -
 Also, if you are exporting large TDMS files to even larger text files, you should think hard if that is really the right move. Find a way to handle TDMS files in the next program. People have written importers for e.g. MATLAB and Python.
Also, if you are exporting large TDMS files to even larger text files, you should think hard if that is really the right move. Find a way to handle TDMS files in the next program. People have written importers for e.g. MATLAB and Python. -
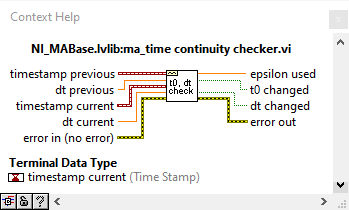
I don't see why there should be samples missing. If writing cannot keep up with acquisition, the DAQmx buffer will overflow and you get an error during acquisition. If you doubt your own code, use the built-in DAQmx logging shown above. Otherwise, use NI_MABase.lvlib::ma_time continuity checker.vi to to build a continuity checker for waveforms

-
 toto_ped joined the community
toto_ped joined the community -
 Fredcm joined the community
Fredcm joined the community -
You were right. How I could check if the there is not samples missing in-between splitting? This is my exporting vi: to_Asci_3_range_2.vi
-
 yahya joined the community
yahya joined the community -
Two possibilities: use 64 bit version and have more memory, or use the offset and count terminals of TDMS Read to read data subsets.
-
I don't think that's true. Most likely a problem with the exporting.
-
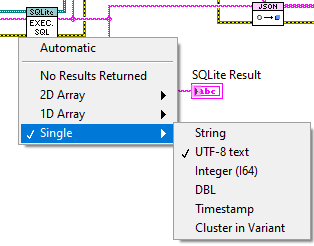
Thank you, The issue was I was binding the string to a sqlite db as a "utf-8 string" then reading it as a "string", which is why it was causing it to fail. I have made the execute sql vi read it as a single utf-8 which fixed it.
-
I've just spent an hour arguing with an LLM (Deepcoder). TL;DR A.I. is useless at programming. I had a bug. I'd spent about an hour trying to figure it out and not succeeding but it shouldn't be that hard-I'm just missing something obvious. So. Ideal scenario for a clever AI to show dominance and help out a poor old flesh-bag programmer, right? Just point out the mistake or mistakes and laugh at my stupidity like a real coder. The bug was that the address from recvfrom would be 0.0.0.0 instead of 127.0.0.1. The problem was either bind wasn't binding to a specific address (which it was supposed to) or the address translation was not working quite right. I gave it 3 functions where I thought the bug was and explained that IPv6 seemed to be reporting correctly but IPv4 was in error: one function (Listen) had the bind function one function had IPv6 and IPv4 address translation from a SOCKADDR_STORAGE structure to strings and the other function was the read function with the recvfrom. This is an abbreviation of the conversion: - Round one. The following code has a bug that returns 0.0.0.0 as the IPv4 address from "recvfrom" when it should be returning "127.0.0.1". Find the reason that the code is returning 0.0.0.0 instead of 127.0.0.1 and rewrite the code to fix the issue. It told me how to bind to a specific address and how to use the recvfrom function. It then basically wrote the example on the MS page for recvfrom but within the Listen function. - Round 2. I'm not using the "sockaddr_in" structures; I'm using SOCKADDR_STORAGE structures. Please modify your example to use SOCKADDR_STORAGE structures. It apologised made an excuse about misunderstanding and then proceeded to create an example, still using sockaddr_in structures, but this time hardcoding "127.0.0.1" in the bind address. - Round 3. No, no, no. It needs to support user entered IPv6 and IPv4 but there is a bug with the IPv4 address. It also needs to use SOCKADDR_STORAGE as in the code I supplied to you. Reevaluate the code and write a version of the code that fixes the bug. It apologised, said that it understands why it got it wrong, and then proceeded to create an example, still using sockaddr_in structures, but now hardcoding "::1" in the bind address. -Round 4. Look. It needs to support both IPv6 and IPv4 and that's the reason I'm using SOCKADDR_STORAGE. If you don't have enough information then ask for clarification but you have the code that the bug is in so find the damned bug FFS! Another apology, said it can understand my frustration and then proceeded to spit out the example from MS again. This went on for an hour. No code I could actually use in my functions, never pointed out the bug in my code and the prompts just got longer and longer as I tried to head-off it's stupidity. This was one of the functions. int Addr2Address(SOCKADDR_STORAGE addr, PCHAR Address, int *Port, int *IPvType) { int err = 0; *IPvType = 0; switch (addr.ss_family) { case AF_INET6: { if (Address == NULL) {return 46;} *IPvType = 2; char strAddress[46]; inet_ntop(addr.ss_family, (void*)&((sockaddr_in6 *)&addr)->sin6_addr, Address, sizeof(strAddress)); break; } case AF_INET: { if (Address == NULL) {return 16;} *IPvType = 1; char strAddress[16]; inet_ntop(addr.ss_family, (void*)&((sockaddr_in6 *)&addr)->sin6_addr, Address, sizeof(strAddress)); break; } default: {err = WSAEPROTONOSUPPORT; break;} } *Port = ntohs(((sockaddr_in6 *)&addr)->sin6_port); return err; } The bug is in the AF_INET case. inet_ntop(addr.ss_family, (void*)&((sockaddr_in6 *)&addr)->sin6_addr, Address, sizeof(strAddress)); It should not be an IPv6 address conversion, it should be an IPv4 conversion. That code results in a null for the address to inetop which is converted to 0.0.0.0. I found it after a good nights sleep and a fresh start.
- 8 replies
-
- 1
-

-
- dvr
- ni software
- (and 2 more)
-
 251364wlau joined the community
251364wlau joined the community -
Discussion forums like LAVA and ni.com are challenged these days by LLMs that can answer in a well structured manner very quickly and handle follow-up questions on the spot. Forums have their stenghts, but when it comes to basic questions that LLMs can find a lot about, spread across multiple forums, the LLMs win. It is a bit of a catch 22 though, as the LLMs need the forums alive to stay up to date 😮 ------------------------------ Here is Grok answering you question of what a DVR is: DVRs as References: In LabVIEW, DVRs (Data Value References) are a mechanism to access data by reference rather than by value. This means that instead of creating copies of the data (as is typical in LabVIEW's dataflow paradigm), a DVR provides a pointer-like reference to a single memory location where the data resides. This avoids unnecessary data duplication, which can be critical for large datasets or performance-sensitive applications. Avoiding Copies: By using DVRs, you can manipulate the same data in memory without creating copies, which is especially useful for large arrays, clusters, or other complex data structures. This reduces memory usage and improves performance. Parallel Operations and Race Conditions: When multiple parallel operations (e.g., parallel loops or VIs) access the same DVR, there is a potential for race conditions if the access is not properly synchronized. LabVIEW provides the In-Place Element Structure to safely access and modify DVR data. This structure ensures that only one operation can read or write to the DVR at a time, preventing race conditions. Without this, simultaneous read/write operations could lead to unpredictable results or data corruption. Key Points to Add: Thread Safety: DVRs are not inherently thread-safe. You must use the In-Place Element Structure (or other synchronization mechanisms like semaphores) to avoid race conditions when multiple parallel tasks access the same DVR. Use Cases: DVRs are commonly used in scenarios where you need to share data between parallel loops, modules, or processes without copying, such as in real-time systems or when managing shared resources. Limitations: DVRs are only valid within the application instance where they are created, and the data they reference is freed when the reference is deleted or the application stops. --------------------- Before DVRs we typically had to resort to cloning of functional globals (VIs), but DVRs make this a little more dynamic and slick. You can have a single malleable VI operate on multiple types of DVRs too e.g., that opens up a lot of nice reuse. If you have an object that requires multiple circular buffers e.g. you can include circular buffer objects in the private data of that object, with the circular buffer objects containing a DVR to an array acting as that buffer... -------------------- Here is ChatGPT comparing functional globals with DVRs: Functional Globals (FGs) and Data Value References (DVRs) are both techniques used in programming (particularly in LabVIEW) to manage shared data, but they offer different approaches and have different strengths and weaknesses. FGs encapsulate data within a VI that provides access methods, while DVRs provide a reference to a shared memory location. Functional Globals (FGs): Encapsulation: FGs encapsulate data within a VI, often a subVI, that acts as an interface for accessing and modifying the data. This encapsulation can help prevent unintended modifications and promote better code organization. Control over Access: The FG's VI provides explicit methods (e.g., "Get" and "Set" operations) for interacting with the data, allowing for controlled access and potential validation or error handling. Potential for Race Conditions: While FGs can help avoid some race conditions associated with traditional global variables, they can still be susceptible if not implemented carefully, particularly if the access methods themselves are not synchronized. Performance: FGs can introduce some overhead due to the VI calls, but this can be mitigated by using techniques like inlining and careful design. Example: An FG could be used to manage a configuration setting, with a "Get Configuration" and "Set Configuration" VI providing access to the settings. Data Value References (DVRs): Shared Memory Reference: DVRs are references to a memory location, allowing multiple VIs to access and modify the same data. This is a more direct way of sharing data than FGs. Flexibility: DVRs can be used with various data types, including complex data structures, and can be passed as parameters to subVIs. Potential for Race Conditions: DVRs, like traditional globals, can be prone to race conditions if not handled carefully. Proper synchronization mechanisms (e.g., queues, semaphores, or action engines) are often needed to prevent data corruption. Performance: DVRs can be very efficient, especially when used with optimized data access patterns. Example: A DVR could be used to share a large array between different parts of an application, with one VI writing to the array and another reading from it. Key Differences and Considerations: Control vs. Flexibility: FGs offer more control over data access through their defined interface, while DVRs offer more flexibility in terms of the data types and structures that can be shared. Race Condition Mitigation: While both can be susceptible, FGs can be designed with built-in synchronization mechanisms (like action engines), while DVRs require explicit synchronization mechanisms to prevent race conditions. Performance Trade-offs: DVRs can offer better performance in many cases, especially when dealing with large data sets, but this can be offset by the complexity of managing synchronization. Code Readability and Maintainability: FGs can make code more readable and maintainable by encapsulating data access logic, but poorly designed FGs can also lead to confusion. In summary: Use Functional Globals when: You need controlled access to data, want to encapsulate data management logic, or need to ensure some level of synchronization. Use Data Value References when: You need to share data efficiently between multiple parts of your application, need flexibility in the data types you are sharing, or when performance is critical and synchronization can be handled externally. It's worth noting that in many cases, a combination of both techniques might be used to leverage the strengths of each approach. For example, a DVR might be used to share data, while a functional global (or an action engine) is used to manage access to that data in a controlled and synchronized manner.
-
 Ramon Taboada changed their profile photo
Ramon Taboada changed their profile photo -
This will work too:
-
Ramon Taboada joined the community
-
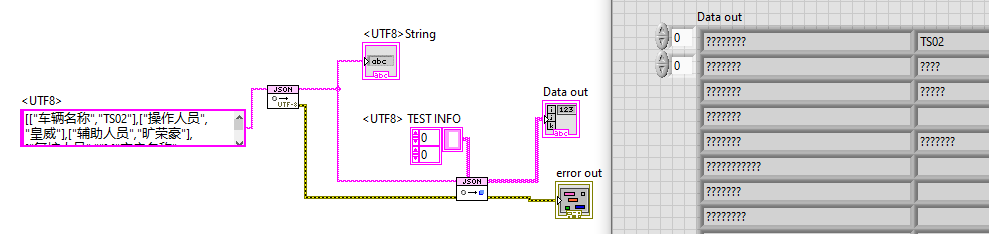
JSON is always in UTF-8, and JSONtext will try and convert to your computer's character set automatically, so I don't think you need any of that stuff that has "UTF8". Try simply using the single function to convert to a 2D array of strings. However, by sure you are actually passing true JSON, with UTF8 encoding, not whatever your computer is using.
-
Converting data file from TDMS to TXT - time format and headers.
cordm replied to sts123's topic in LabVIEW General
right-click the node, select "help" and read the manual, please why use a while loop? use an auto-indexing for loop!
-
Converting data file from TDMS to TXT - time format and headers.
sts123 replied to sts123's topic in LabVIEW General
It does not throw the names as expected. to_Asci_3_range_2.vi -
Converting data file from TDMS to TXT - time format and headers.
cordm replied to sts123's topic in LabVIEW General
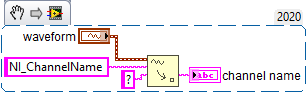
Use Get Waveform Attribute (Waveform>>Get Attribute) to read the NI_ChannelName string attribute from each waveform. Add another loop before the first one where you get it from each waveform and then write it to the file. DAQmx creates that attribute automatically. This is what Waveform Graphs use for plot names. -
Hi, I am using jsontext library in a project which I have been asked to localize to Chinese but get "??" out when using from jsontext. Is there a way to do this that I am missing, or am I doing something fundamentally wrong. The dev PC in windows has all the localization / regions set to Chinese. Thank you
-
My .vi works ok until input file is about 1GB in size. Otherwise, it doesn't run, throwing the error about memory. to_Asci_3_range.vi
-
At the moment, when the tdms i split, every individual fiel has time stamp reset to 0 at the start. Is is possible to do it the way that each file has time stamps that are continuing without disruption right from the beginning?
-
Converting data file from TDMS to TXT - time format and headers.
sts123 replied to sts123's topic in LabVIEW General
Any thoughts how can I add header to the file, that are the same name as channels names in the Task? -
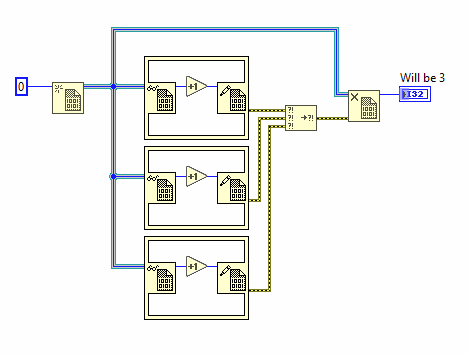
I've done it like this. Not sure if this is efficient and can avoid missing samples during split. I am using high sampling rates. RR_Spliting_2.vi