Leaderboard




Popular Content
Showing content with the highest reputation on 03/01/2016 in all areas
-
After reading this LabVIEW Idea exchange request: http://forums.ni.com/t5/LabVIEW-Idea-Exchange/Provide-a-better-way-to-implement-a-polymorphic-VI/idi-p/920487 I was inspired to create VI macro(s) to attempt to address the problem mentioned in the request. Attached is my first attempt and I'm looking for feedback since I know people here have strong opinions. The benefit of this method is that a single vim (or 2 could replace a polymorphic VI with over 48 separate VIs....unless I'm missing something. I know that VI macros are not officially supported by NI, but that hasn't stopped us from using unsupported features before. Some people have probably already done something like this, but I couldn't find an example. To use the files, unzip them and copy them all to your \LabVIEW (version)\user.lib\macros\ directory. Create the directory if it does not exist. For example: C:\Program Files (x86)\National Instruments\LabVIEW 2014\user.lib\macros\ And as described in the wait-ms-with pass through post below, modify your LabVIEW.ini file to have the following ExternalNodesEnabled=True and Optionally XNodeWizardMode=True http://forums.ni.com/t5/LabVIEW-Idea-Exchange/Wait-ms-with-error-pass-through/idc-p/3178218#M31820 Open the Example Changed.vi and review. Changed Example.zip1 point
-
Well I'm sure the GIT system was exactly developed for what you see as original idea. And it works amazingly well for certain projects with a central maintenance like the Linux kernel or the Wine project. However lacking such centralized maintenance it tends to get the cloning mess you allude to. Because most developers are just wanting to get this new awesome feature into the software and not worry about integrating it in the main branch. I still follow the Wine project a bit and it is the single most problem there, some contributor has a great new idea and drops a patch, but then when faced with the trouble of integrating it into the whole and complying with common styles, formatting and following proper error handling and making sure the modified code passes all unit test, the majority just starts to complain about the stringent rules and eventually abandons it. Even in text programming, merging a software branch back into the trunk is often a very tedious, and work intense process, that even advanced code merging algorithms never will be able to fully automate, since it is not always enough to just look at the factual differences in code, but the whole context often has an influence too. And with even basic automatic LabVIEW code merging being still a pipe dream, this makes the distributed development model of GIT more of a liability to LabVIEW source code control rather than an advantage.1 point
-
Glad I'm not the only one. Even if you account for not being able to diff LabVIEW code - which is a huge benefit of SCC - the creation of hundreds of clones of the source code trunk as a normalised workflow is an abomination. I think the idea was originally to be able to pick and choose code created by the herd of cats to improve the trunk but what actually happens is you end up with 1,000 slightly different variation of the same thing none of which are exactly what you want. So.....you create another clone .1 point
-
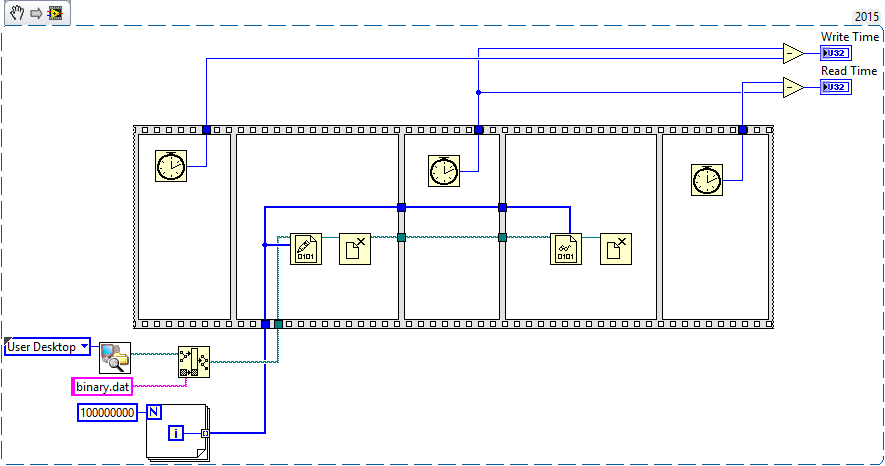
Okay, this is getting a bit off-topic as the discussion is about a specific problem which is not necessarily sqlite related. So I guess this should be moved to a separate thread. drjdpowell alredy mentioned, that sqlite is not the best solution if your data is not structured. TDMS on the other hand is for use with graph data, but creates index files in the process and stores data in a format readable to other applications (like Excel). That is what slows down your writing/reading speed. As far as I understand you want to store an exact copy of what you have in memory to disk in order to retrieve it at a later time. The most efficient way to do that are binary files. Binary files have no overhead. They don't index your data as TDMS files do, and they don't allow you to filter for specific items like an (sqlite) database. In fact the write/read speed is only limited by your hard drive, a limit that cannot be overcome. It works with any datatype and is similar to a BLOB. The only thing to keep in mind is, that binary files are useless if you don't know the exact datatype (same as BLOBs). But I guess for your project that is not an issue (you can always build a converter program if necessary). So I created a little test VI to show the performance of binary files: This VI creates a file of 400MB on the users desktop. It takes about 2 seconds to write all data to disk and 250ms to read it back into memory. Now if I reduce the file size to 4MB it takes 12ms to write and 2ms to read. Notice that the VI takes more time if the file already exists on disk (as it has to be deleted first). Also notice: I'm working with an SSD, so good old HDDs will obviously take more time.
 1 point
1 point -
I can only speak for myself, but I do find the GIT workflow not really very easy. I'm sure there are some tools nowadays that make it quite a bit easier to use, but the impressions I got when comparing SVN to GIT several years ago, was that SVN was simply there to use while with GIT you had to learn a whole bunch of magic incantations and remember arcane commands and specific sequences or you ended up with a bigger mess in your project than when using the simple old ZIP-it-all-up source code control system. That all said, if there are people who really want to use GIT and are eager to revive the OpenG initiative if it is moved to a GIT based site, they shouldn't be blocked from it. I don't have much to say about that as my current submission rate to OpenG is just very slightly above 0 and hardly can drop much even if I should decide to not like the new workflow.1 point