Leaderboard



Popular Content
Showing content with the highest reputation on 07/16/2018 in all areas
-
I few other methods for you to consider: 1) a separate "helper loop": in this, the main loop of the template is a "manager", with a separate loop inside the actor doing the work. The "worker" can be controlled by non-actorish ways (such as an Abort Notifier) by the Manager, which is always capable of handling new messages coming in. This encapsulates the non-actor communication, keeping it local (and understandable). I likely addition to this is a "job queue", to hold the list of actions that the manager queues up for the worker. Here is where one can have job priority, or cancelable jobs. Note that this is different from the "action stack" (what you called a "state machine"). These are different things that are too often combined. 2) Have a "Sequence actor" that does the long actions, which can't itself be aborted, but which acts on hardware via short-to-execute synchronous Request-Reply messages to separate hardware actors. Send the "abort" messages to the hardware actors, putting them into a safe-mode state where they reply to action requests with errors. The first such error message causes the "Sequence actor" to end it's sequence (using standard error-chaining logic). Note that if your stop really is an emergency then this bypassing of your complex higher-level logic to talk directly to low-level hardware actors is actually a lot safer and more easily testable. 3) An asynchronous version of (2), where the "Sequence actor" uses Async Request-Reply for interaction with the Hardware actors. Less flexible than (2), but more properly actorish, in that the Sequence actor is always able to handle messages. I actually don't mind your abort notifier triggered from outside the actor. This is, as you say, bending the rules for a limited and clear purpose, and for the special case of aborting. Unfortunately, though, you're dealing with the problem of "state" (true "state", not the actions of a so-called "QSM") and that isn't ever easy.1 point
-
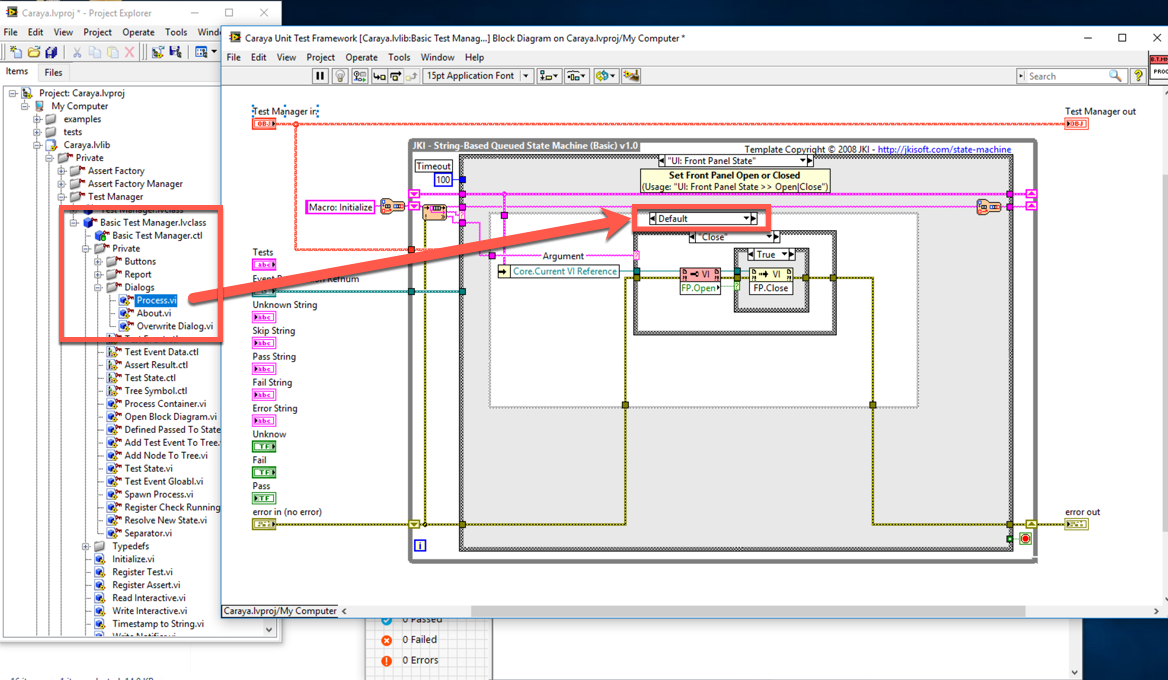
The core process skips showing the UI when on RT. You can modify this in the Basic Test Manager's process by removing the conditional disable structure. However, you should probably make a request on the open source project (https://github.com/JKISoftware/Caraya) or fork the original repo. Modifying this in vi.lib will not make it persistent and is a bad idea... It might be that the logic could be smarter in that if the RT target does not have a UI, it would skip it, but not assume that all RT targets don't allow UIs. There might also be the possibility to modify the test suite setup to inject your own override code, for which you could simply change the behavior of the basic test manager.
 1 point
1 point -
I can't say I support the use of the Write DVR Value. The point of using a DVR is to protect critical sections of code (ie avoid race conditions). If you are just randomly writing a value to a DVR without doing the Read-Modify-Write protection, you might as well use a Global Variable and get better performance.1 point