Leaderboard




Popular Content
Showing content with the highest reputation on 08/22/2018 in all areas
-
Purely cosmetic. That being said I do have a preference. Inputs go in on the left, and outputs on the right, not from the bottom unless the terminal is on the bottom. I think it is easier to read this way, but don't get hung up on it.1 point
-
A good use case is when you encapsulate code in a case structure based on error/no error. Common in SubVIs. The error case will usually have the error wire running straight through, while the non-error case may have many VIs that *do stuff* and don't necessarily align error wires together. I don't usually drop the line back down to the base reference in between VIs, but there are times that I'll put a few in a row, drop back down, and then come back up for another batch. It's purely cosmetic.1 point
-
Yes, that's the basic JSONtext use case: working with JSON: Working to/from LabVIEW data types is also a use case, and there is the (more complicated) ability to intermix JSON and LabVIEW Types in clusters using the <JSON>-tag method smithd describes, but a basic motivation of JSONtext is to be able to work simply with JSON-formatted strings directly.
 1 point
1 point -
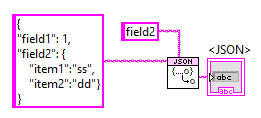
if I understand you correctly you want to name the field in your cluster <JSON>field2. That is you start with a cluster on your block diagram: {field1:dbl=1.0,<JSON>field2:string="{"item1":"ss", "item2":"dd"}"} When you call flatten to json you get: " {"field1": 1,"field2": { "item1":"ss", "item2":"dd"}} " because the library automatically pulls off the <JSON> prefix and interprets that whole string as JSON. When you unflatten the reverse happens,1 point