mje
-
Posts
1,068 -
Joined
-
Last visited
-
Days Won
48
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by mje
-
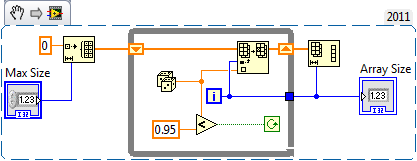
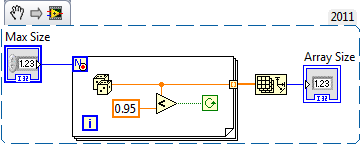
Consider this fairly typical scenario: You need to create an array of data. You know an upper bounds of how large that array can get. It's computationally expensive to determine the exact size you'll need before hand. Usually getting this done is just a matter of initializing an array to the boundary size, filling it in a loop, then truncating the array when I'm done my calculations and know the exact size. However, that's a fair amount of code, things can get a little messy when real calculations are being performed. I'm wondering if we use a conditional for loop, does the compiler produce pretty much the same operations? That is since the for loop is bounded by a Max Size, will the compiler initially allocate an array of that size, then truncate at the end? Or will the operation be analogous to indexing an output on a while loop where the array keeps growing as it needs resizing? Oops, I forgot to add bounds checking to the while loop snippet...you get the idea. Just imagine the conditional terminal had an additional AND operation in there to check the index, and the resize operation took into account whether the last iteration was successful or not.

-
 You need the preserve runtime class is needed to do exactly what the name implies: ensure the class of the value going along the in/out wire is preserved at run-time. To do dynamic dispatching, you need to fulfill a contract that the type of value riding on the wire does not change as it goes from input to output. Also remember that potentially any class can ride along a given class wire so long as the value derives from whatever wire type you're working with. When you use the Variant To Data primitive (or the similar To More Specific Class), you're deciding what class you want to test for based on the wire type in your block diagram. This decision is made when you edit your code and the VI compiles, it is a static test. Compare this with the Preserve Run-Time Class primitive which evaluates at run-time what the value type is riding on the wire. The run-time test is dynamic: the wire type in your block diagram hasn't changed, but the type of the value riding on that wire may have. If I supply a child class along a parent's wire, the run-time check will be aware of the difference and test accordingly. How about an example? What happens if I have an XHTML Config class which inherits from your XML Config class, and I pass it to the VI you showed? By using the Variant To Data, you've only guaranteed that the value you're returning is definitely an XML Config value. But I supplied a more specific XHTML Config value to your VI, it's not until you perform the dynamic run-time check with the Preserve Run-Time Class that you can be sure your XML Config wire has preserved the type across the entire VI. Does that clear things up?
You need the preserve runtime class is needed to do exactly what the name implies: ensure the class of the value going along the in/out wire is preserved at run-time. To do dynamic dispatching, you need to fulfill a contract that the type of value riding on the wire does not change as it goes from input to output. Also remember that potentially any class can ride along a given class wire so long as the value derives from whatever wire type you're working with. When you use the Variant To Data primitive (or the similar To More Specific Class), you're deciding what class you want to test for based on the wire type in your block diagram. This decision is made when you edit your code and the VI compiles, it is a static test. Compare this with the Preserve Run-Time Class primitive which evaluates at run-time what the value type is riding on the wire. The run-time test is dynamic: the wire type in your block diagram hasn't changed, but the type of the value riding on that wire may have. If I supply a child class along a parent's wire, the run-time check will be aware of the difference and test accordingly. How about an example? What happens if I have an XHTML Config class which inherits from your XML Config class, and I pass it to the VI you showed? By using the Variant To Data, you've only guaranteed that the value you're returning is definitely an XML Config value. But I supplied a more specific XHTML Config value to your VI, it's not until you perform the dynamic run-time check with the Preserve Run-Time Class that you can be sure your XML Config wire has preserved the type across the entire VI. Does that clear things up? -
The motivation for this thread was purely academic. Hooovahh covered most of the things I was thinking about. What happens if by landing in a regulatory environment I suddenly need to have an ISO certified way of dealing with authentication? I'm not convinced this is even possible to implement this entirely in LabVIEW, though to be honest, I've not even read the relevant standards. It's general good practice which makes me curious about this. What if I have an application that runs third party code, maybe plugins. I want to be sure that when it comes time to run that unknown code I have a clean memory footprint such that a malicious bit of code can't scrape an old data from memory when run from the context of my application. Or maybe the best idea is to run this code from an entirely different context-- a sandbox. This could go so many different ways and in the end you still need to worry about once that code gets executed, how can you be sure a new keylogger hasn't been spun up? If my plugins are written in native LabVIEW, there's probably nothing I can do about it, but if I have some form of scripted environment where I provide an API to work with, maybe this concern can be managed. I don't have answers to questions like this, which is why I really wanted to start this discussion. I'm not trying to argue someone like me should roll their own solution, I'm way too naive about these matters to do so. What I'm really after is if it's even possible for anyone to create a library that properly manages authentication purely in a LabVIEW environment? If so, what are some of the challenges/considerations that are brought up due to LabVIEW? This is just a topic that I keep coming back to every other year or two, and I've never come to a satisfactory end of discussion other than "I doubt it's possible in pure LabVIEW." I thought I'd see if anyone else has ideas. I believe that any authentication would have to be handled by external code, such that my LabVIEW code doesn't even get access to the password. Really all my code needs to know is who the user is, and their granted permission level if any.
-
A recent topic on the idea exchange (Allow "Password" Data Type for Prompt User for Input Express VI) got me thinking about security in LabVIEW. Specifically how do you secure a user interface in LabVIEW which is entering sensitive information such as a password? No, simply obscuring a password is not the answer. Some things come to mind that would worry me about having to handle authentication in LabVIEW. Need to make sure any temporary copies of password strings that are generated get properly "cleaned" so the data doesn't stick around in memory. Keep the password out of any control/indicator such that other tasks can't use VI Server to get a refnum and generate copies of the password, register for value change events, etc. There are likely other issues, I'm about as far from an expert in security as you can get. I've never had to create an application that requires any form of authentication but I've wondered about it for a while now as I find myself using LabVIEW for more and more as a platform where I wouldn't have previously considered it. In principle, #1 seems easy because values are mutable. The caveat being you need to have a solid handle on what buffer allocations are "real" when you look at your code such that if you end up having to copy a password, you can be sure you're going to overwrite it. This of course assumes that any primitives you use are secure. On the surface #2 seems as simple as storing the current password string as local state information which is not accessible via any control/indicator to keep VI Server snoops from just grabbing the current value. However as soon as you want a portable solution- one that leaves authentication to the calling VI and doesn't do authentication at the same level the password was entered- you're talking about returning a string to the calling VI which by definition must pass through an indicator because you had a UI loaded. OK, fine, maybe we can set up some fancy stuff with an anonymous synchronization primitive: I send the password dialog an empty single element queue, the dialog fills in a value, I retrieve the value from the queue and destroy it. Now I've gotten my password text without passing it through an indicator, but I have no idea how secure these queues are, they're a black (yellow?) box. I can watch them get created in the trace execution toolkit, are their values safe? Beats me. For that matter, is it possible to lock a VI down such that you can't snoop around in VI server at all? I realize this is borderline pedantic for LabVIEW, especially how we're pretty much trained from day one to just let the compiler take care of memory. For the most part that's fine, but when we're talking about security, I think this discussion is warranted. Or is perhaps doing something like this just not really the realm of what one should seriously consider tackling in LabVIEW? Who knows, I'm breaking my do not post after 10 PM rule, so maybe this is just all crazy talk. Anyone have opinions? Has anyone tackled this before, even outside of a LabVIEW context? What are some of the other issues one might need consider?
-
Thanks everyone. Some very good insight in there. For what it's worth we're just getting our feet wet as far as formally tracking requirements. We're on our second release cycle of our first product we've had that has had any formal requirements at all. I'm trying to figure out a better way of doing things. We're a DOORS workplace, but personally I have had very little exposure and training to it. I hesitate to say this in case the wrong people read it and take it out of context, but I find our existing requirements system to be a bit of a burden to development mostly due to the disparate nature of the various tools that we use: no tool we use plays well with any other from a LabVIEW context. I still think we're better off with a requirements system than without, I just know that the system should be doing way more for us than it's capable in the current form. There's really no way for me to quantify code coverage, what requirements are missing, what code we need to review if we find a requirement isn't being satisfied, etc, short of doing things manually. I'm really hoping to get some level of automation into this the next release cycle and was trying to determine if NIRG can get us down that road. The concerns about the dated interface worry me somewhat, but in all honesty, if it's functional I'll gladly use it, regardless of how quirky it is. Some of the DOORS/Change interfaces I've used are pretty much the same: very functional, though looking at it from a developer perspective it's hard not to view them as kludgy and I'm left wondering how fragile the system really is. As an aside, the demo NI & IBM showed with integration into doors/change at one of the keynotes and booths seemed like a very solid start. I'm excited to see what happens with that over the next few years.
-
Do any of you have experience with the Requirements Gateway offered by NI? I first heard about this at the recent NI Week and it seems very promising. After getting home I downloaded it, started my trial period, and quickly realized I'm in way over my head. I'll probably need days worth of time to play with it before I can make any real judgement with regards to it's utility in our work environment. For now I don't have that kind of time so I'm shelving the idea and putting it on the list of things to look into after our current release cycle. For those who have used it, I'm curious how well it helps tracking requirements and how much "overhead" it adds to your workload. Do you find it overall beneficial or is the effort involved not worth what you get back out of it? What other solutions have you tried?
-
Hmm, quick and dirty test attached (LV 2011 SP1). Reload.zip It seems regardless of a VI being in a class or not, it is actually loaded and unloaded on each call when in the RTE. If you look at the attachment there's an exectuable, re-build it from the included project if you don't trust it. When running the executable, each time you click the "Dynamic Class Call", the application will make a call to a class method set to load and unload each time. Ditto for the other button, but the called VI is not part of a class. When you click one of the buttons, the corresponding method will initialize an array of bytes to the size you specify and store it locally in a feedback node, returning the number of bytes that were previously stored. Each time you click either button, the array size that was previously stored will always return zero, indicating the VI is successfully being unloaded each time. Checking the windows task manager confirms, the memory required stays low, though the peak memory goes up. This all goes out the window if you have a static call to the VI somewhere in the code. Follow up, nevermind. I didn't realize LabVIEW would be smart enough to discard the entire class library if it is no longer needed. Throw some instance of the class on the test.vi diagram somewhere and the class method always sticks around.
-
So if I have a VI call configured to "Reload for each call" via the VI Call Configuration dialog, does it actually do any load/unload if the VI is part of a class? The VI is part of a library which means its already loaded, correct? Is there any actual loading and unloading going on?
-
Neat. Those are both very interesting, which proves to me it should be doable. I was looking for a UI that allows me to edit the palette and manually curate the VIs rather than having an auto-created one. Basically I'd like to have a GUI editor that doesn't involve me editing my actual IDE palette. Cheers though, either ought to be a good tool in the interim.
-
Quick question: Is there an easy way to create/edit stand-alone palettes? That is other than mucking about with my main IDE palette set? What I'd really like to is from the project explorer, open a context menu for a class and be able to create a new palette. Similarly I'd like to be able to open a context menu on an existing palette and edit it. I find that nearly all of my classes don't have a default palette set because its such a nuisance to create/maintain them. Bonus points of a class palette editor automatically includes parent class palettes as a sub-palette. Is there a tool that makes this easy? If not I might head over to the idea exchange to make a suggestion...
-
Namespacing objects in a build makes them "different"
mje replied to crelf's topic in Application Design & Architecture
Indeed, however with DLLs you can't use any classes in the exported function terminals I believe? -
Namespacing objects in a build makes them "different"
mje replied to crelf's topic in Application Design & Architecture
I've fallen behind on this topic and don't anticipate being able to keep up with it, but I'll point out a reply I made to Paul in another thread some time ago. It includes some sample code, but I can't quite recall how relevant it would be to this discussion (and don't have access to LabVIEW to check up on it). If you can look at the example abstractly, this is the type of mechanism I'd use if I had to expose a class which external VIs need to be able to use which an executable will load (and have serendipitously used in the past). At some point the class/classes that are required need to be exported as some sort of distribution. As stated in the other thread, and has been said here, there are many ways to do this (just supply copies of the relevant source code, make a proper source distribution, make a packed library). Ultimately the distribution does not have to ride along external to your distributed executable-- you just need to make sure the distribution is available to plugin authors to use somehow. Think about a "toolkit" that might be a supplemental item distinct from your core application. Most people won't ever need the toolkit, it can be a separate download, SKU, whatever. If your executable automatically includes all the relevant classes from the toolkit within the executable it is fully functional. Plugin authors just need access to the distribution so they can code up their plugins, but when it comes time to distribute the plugin, they exclude the toolkit files from their distributions because there's no need to distribute them a second time since the executable already has them. More to the point, attempting to include the toolkit classes in a plugin will generate name conflicts as you've seen, so any code which loads plugins ought to do some proper error handling. -
Namespacing objects in a build makes them "different"
mje replied to crelf's topic in Application Design & Architecture
Well I might not be interpreting your situation correctly. Unfortunately won't be able to look at your example for a while either. But it would seem to me you need some kind of third component. I'm interpreting the situation as you have two executables which you want to operate independent of one another, but want to be able to move (non-serialized, that is native LabVIEW) data between them? That to me implies some sort of common intermediary is needed which contains those types. As for packed libraries, all I can say is twice I've tried to use them in a large project of mine, and twice I've had to revert because the IDE became simply unusable (slow and unstable). My thought was this third component could in theory be a PPL. -
Namespacing objects in a build makes them "different"
mje replied to crelf's topic in Application Design & Architecture
Sounds to me like this is the sort of thing source distributions were made for. If I recall you can still strip diagrams despite them being called "source" if that's a concern. Put whatever classes are used in the exposed APIs into the distribution and exclude the types from each of your application build specifications. Packed libraries in theory would work too, but uhh, I'm personally not even close to trusting them given the headaches they've caused me the few times I tried using them. -
Thanks James! Even a negative answer is better than not knowing.
-
That would be good to confirm if it is the case.
-
Disclaimer: I have zero RT experience. James's point is valid. A 20 ms time implies you won't be able to keep up with I/O at 100 Hz. The 20 ms time also makes sense given the strategy you've been taking. Most hard disks have average seek times on the order of 10 ms. Even with server class disks, I think their seek times still measure in the 1-5 ms. Most vendors stopped specifying seek times a long time ago though because the numbers are so bloody awful and haven't changed much in the last two decades. Solid state drives do get you into the sub millisecond domain though. That said, I think having one file per image might not be the best way to do it. A pre-allocated larger file might allow you better throughput. Modern drives are capable of impressive throughput as long as you're operating on continuous segments and don't need to do seek operations. Maintaining disk layout here will also be key, think defragmented data. I don't think you can do this in LabVIEW so you might need to invoke a third party library. Also, if you start mucking about with the frequency of incoming data do you still see the spikes every 40 files? I'm wondering if perhaps something else is accessing the disk?
-
"Get LV Class Default Value" from memory, not from disk
mje replied to Stobber's topic in Object-Oriented Programming
Yup -
To remove compiled code or not, that is the question.
mje replied to MikaelH's topic in Development Environment (IDE)
Mikael, I owe you big time. I just added a value to an enumeration typedef for one of my state machines, and all of a sudden every instance of the typedef reset to the default (0) value. I shut everything down, cleared the cache, and all was well. Cheers! -
"Get LV Class Default Value" from memory, not from disk
mje replied to Stobber's topic in Object-Oriented Programming
That works. I'm curious, does the default value VI do some level of caching so it does not need to go to disk on each call if the same class is requested multiple times? -
"Get LV Class Default Value" from memory, not from disk
mje replied to Stobber's topic in Object-Oriented Programming
I've run up against this too. What I wouldn't give for a more complete implementation of LabVIEW Object. There's only one way around this as far as I know: build your own look-up table. If your aware of all of the possible object types this is easy, you just need to translate an identifier to a value. If you don't have control over all the serialized types prior to distribution, you're likely going to have to roll a far more involved solution where you can register a type with a given identifier, provide a mechanism for dynamic type registration, and a factory method that spits out values for a given identifier. I keep using the generic term identifier instead of qualified name because even though a qualified name is one of the most fundamental properties of a class, we don't even have access to that, save for some hacks that are performance killers. AQ, maybe I misunderstood the question, but I think Stober needs a means of translating a qname to a value, which isn't covered in that post? Those VIs only work if you already have a value (or path)... -
To remove compiled code or not, that is the question.
mje replied to MikaelH's topic in Development Environment (IDE)
Yes, but I've never been able to track them down. Sometimes after editing enum typedefs for my state machines my constants will change values. It doesn't happen all the time, but when it does it tends to break things in rather spectacular fashion. Very annoying. I don't include compiled code in my LabVIEW VIs. -
FYI, I've tracked down a bug in the code I posted earlier. All was working well for me until I tried to use it off a fresh boot. I think it's related to the DCB structure that is get/set as part of the open operation. Anyways, symptoms for me are if I open the port before hand in hyperterminal, close it, then use the library, everything works. However if I use my library right after a boot before any other application has "properly" used the port, then I'm out of luck. I've been playing with the DCB cluster trying to make things work by removing padding bytes, properly setting the DCBLength field, etc, but no luck yet. I know a lot of these settings (if not all) persist on the COM port outside the scope of any application, which is why proper practice is to get the port state before you modify it, and restore it when you're done. I'll post more info if I track the solution down. For now our procedure is just to make sure you initialize the port with hyperterminal before you use our application.
-
Hahaha. I was being civil. Frustrating indeed, especially when you're dealing with multiple levels of reentrancy. Don't get me going though on dynamically allocated clones, the feds ought to give up waterboarding and just have detainees attempt to debug those applications...
-
That other thread is interesting, but I was looking for a native UI option. Thanks AQ. No big deal, clones can easily be found by digging through a few layers of VIs and opening them from the block diagrams.