mje
-
Posts
1,068 -
Joined
-
Last visited
-
Days Won
48
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by mje
-
 Playing devil's advocate here, what use would this be that couldn't be achieved through inserting step(s) in the inheritance tree? The only problem I see is to use inheritance you'd potentially have a chain of relatively simple, unrelated, and nonsensical classes where the only use is to restrict access to state data. Generally speaking I use object oriented design to take advantage of polymorphism, not for such esoteric shenanigans. Also let me be clear, I don't think using inheritance to solve this problem is a good design, I'm just asking if it would be a functional equivalent. Solving this issue with inheritance brings along quite a bit of baggage in my opinion.
Playing devil's advocate here, what use would this be that couldn't be achieved through inserting step(s) in the inheritance tree? The only problem I see is to use inheritance you'd potentially have a chain of relatively simple, unrelated, and nonsensical classes where the only use is to restrict access to state data. Generally speaking I use object oriented design to take advantage of polymorphism, not for such esoteric shenanigans. Also let me be clear, I don't think using inheritance to solve this problem is a good design, I'm just asking if it would be a functional equivalent. Solving this issue with inheritance brings along quite a bit of baggage in my opinion. -
I've done this, though there's always a pair of accessor VIs attached. I'm one of those people who litter my classes with accessors and never touch the cluster data except in said accessor VIs. It's just too darn convenient when you need to find where a field is used. That said, I'd be against the idea because now you can't get a good idea of what your state data is by looking at the class control-- it becomes scattered about in several places. Maybe I'd like it if somehow the field automagically also appeared in the state control, but somehow was greyed out and not selectable outside of the VI. Maybe. But then I imagine automatically placing such fields could make for absolute havoc if on unbundle nodes.
-
Wait till you see LabVIEW 2013. It's so ahead of it's time it's nostalgic. Lucky I hacked NI and stole a snapshot build so I can show you all:

-
Nice. It's too bad there doesn't seem to be enough events exposed to stay away from polling, but I'd take working over not any day
-
Darn, a quick test shows indeed, the native drag events interfere with mouse tracking. Hmm... context drag.zip
-
Is it the drag event that's mucking things up? I do this all the time for tracking movements on graphs, but admittedly there's no native drag event happening. During mouse movement I shuttle data (including position) off to async floating window tasks depending on contexts such as near data, out of bounds, or mouse button state. However admittedly I rolled my own drag logic because the native one didn't suit my needs- not even sure if the graph controls support it?
-
<sarcasm>What could possibly go wrong with this?</sarcasm>
-
[Ask LAVA] Must Override exists; could Must Implement?
mje replied to JackDunaway's topic in Object-Oriented Programming
"So, I think your question indicates you're still seeing Implemented methods like a Dynamic Dispatch override." No, I get it. You're looking for a statically resolved link. The possible paths code could take is completely resolved when things are compiled. Note: I'm going to use the word "interface" a lot in this post, and I mean it as a general point of interaction between pieces of code, not the abstract sense which comes up in some languages that use it as a keyword, or in several theoretical discussions we have had here on lava. I guess for me dynamic dispatch isn't fundamentally about just changing behavior via overrides or producing concrete implementation. Sure, that's the mechanics of it, but in isolation is of very little value. A class that has any dynamic methods defines a programming interface at one level that derivative classes can modify or must implement. The value in such a mechanism comes when the programmer writes code calling the dynamic methods from the superclass interface-- completely unaware of any derivative classes. This code can be part of the superclass itself or completely separate. The code that operates on the dynamic interface at the superclass level is essentially laying down a series of hooks, detailing the conditions when these methods will be called and has done so completely decoupled from any derivative classes which may exist at run-time. I suppose if I'm going to boil it down to one sentence it is this: just as important as the dynamic dispatch method itself is the contexts under which the method is called. (You can at this point hopefully imagine how important I feel documentation is for these methods. I die a little inside every time I see an undocumented dynamic dispatch.) So that's why I'm not sure I understand why a "must implement" could be useful. You're basically saying if you're going to have an "is a" relationship with me, you need to do something(). But an interface can't be provided so you can't provide the context in which something() will be called. No code that operates via the superclass interface can do anything with something() due to the lack of this interface. The code requires direct knowledge of the derivative class, which has completely defeated the purpose of defining something() at the superclass level. I will concede one point though, a "must implement" will indeed provide a good set of clues as to what derivative classes should be doing. However I feel the inability to enforce anything beyond the mere existence of something with a given name means these hints really don't belong in code in my opinion. -
SubVIs are separate files. If someone posts an example VI which uses SubVIs which aren't part of LabVIEW they ought to be distributing a collection of VIs instead of just one. Or instructions on where to get the other VIs. Alternatively maybe you're dealing with an example VI that uses a toolkit you haven't installed/purchased?
-
[Ask LAVA] Must Override exists; could Must Implement?
mje replied to JackDunaway's topic in Object-Oriented Programming
Hmm. Jack, please understand I'm not trying to be hostile, I just really don't understand how this could be used. So if a superclass deems MethodX must be implemented, but it can't call this method because no interface has been defined, how is the VI useful to the superclass or any other code that interacts with the superclass interface? Something similar would be the ability to overload methods: being able to define a new VI with the same name but different connector pane. This however is mostly syntactic sugar as in languages that allow it as no real functionality is introduced that couldn't be achieved by naming each method differently as we do in LabVIEW. In effect overloading is really an edit-time convenience. -
[Ask LAVA] Must Override exists; could Must Implement?
mje replied to JackDunaway's topic in Object-Oriented Programming
How would you ever wire up to the must implement method if you haven't defined the interface? For methods where I need to override but might conceivably require additional or different data, I personally would consider ditching the idea of specific arguments all together: have the connector pane with the usual dynamic dispatch and error I/O if required, plus an additional single/pair of terminals of some Object where descendant classes can cast if necessary? -
How to handle extra data in a queue?
mje replied to george seifert's topic in Application Design & Architecture
Notifiers are also event-like in that you can have a one to many broadcast: multiple tasks can be waiting on notification from the same refnum. -
"Closing References in LabVIEW": New documentation published
mje replied to Aristos Queue's topic in LabVIEW General
This is my general rule too, though there are exceptions where documentation clearly states references returned must be closed.There are also less clear cases-- the XML library is particularly finicky/inconsistent in my opinion, but this is likely due to the underlying third party binaries rather than LabVIEW. Jack's point is very good. The desktop execution trace toolkit is very valuable for tracking reference leaks. -
Except the two you mention are both sealed classes.
-
I love the solution if your code breaks its oaths and how the iterative nature of the cleaning implies "Several invocations may be required to fully excise all bugs from your code." Amusing.
-
the difference of FFT analysis with large data in labview
mje replied to hhtnwpu's topic in LabVIEW General
I'm also curious about this. Such large arrays could pose problems. A 10 M element DBL array is 80 MB, and 160 MB for the resulting complex data type. Do you actually expect to reliably be able to pull continuous chunks of memory larger than that, even on a 64-bit environment? I've done my share of working with large data sets and through experience learned never try to float around arrays like that. LabVIEW does not fail gracefully if it fails to allocate memory... -
Best practices for integrated help in your deployed EXE
mje replied to John Lokanis's topic in User Interface
...and unfortunately can't be easily disabled if you don't want it. I agree with Darin, it's too klunky and I don't think it has any place in most executables. -
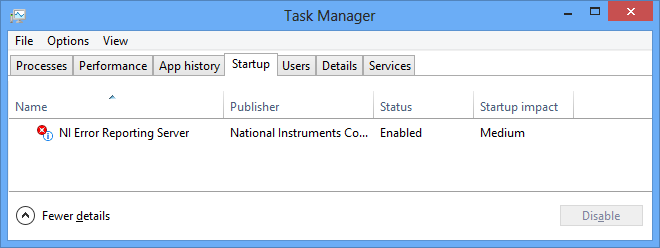
Thanks for looking into this James. I definitely haven't ever noticed the service doing anything from our applications, which is part of the reason I never even knew the RTE installed it until Windows 8 made it plain as day (at least for those of us who use task manager regularly). This however will be the first time we haven't used an NI-built installer so my experience with using a full RTE install is limited-- previous versions of our application used an NI-installer and excluded the NIER option. It was indeed a concern as one of our design requirements is the application have no footprint on the network as it can be called upon to handle some pretty sensitive intellectual property for customers who worry about such things. That document you linked though is very useful. Especially this quote: So it seems we're in the clear: data will not be sent over the network to NI.
-
So I was "playing" by installing our latest release candidate on Windows 8 even though we don't officially support it. This is a fresh OS I just installed with the following extras installed: Our application LabVIEW 2011 SP1f2 RTE* Microsoft .NET 3.5.1 Microsoft Visual Studio 2010 SP1 Redistributable We have 32-bit and 64-bit installers, each with the appropriate applications/run-times. Anyways, the first thing I notice in the task manager is this on our fresh Win8 64 OS after getting things up and running: Does this imply that the default RTE install activates the NI error reporting service which has the potential to send back data to NI? Under which conditions would the error reporting be triggered for a LabVIEW-built executable? -m *I'll note that due to a defect in the 64-bit LabVIEW application builder, we are forced to go third-party for the installer. Thus the RTE is installed via a silent install of the extracted downloadable RTE installer (that is we don't have an NI built installer). The installer is executed via: setup.exe /q /AcceptLicenses yes /r /disableNotificationCheck
-
Persistent class data or static data for all objects
mje replied to twols's topic in Object-Oriented Programming
I hadn't thought of that. Neat idea. -
Persistent class data or static data for all objects
mje replied to twols's topic in Object-Oriented Programming
You do this in LabVIEW with a functional global (alternatively called a LabVIEW 2 global). Just have the VI be a part of your class and you can control its scope as you would any other class member. -
Inheritance in this situation feels a bit icky...
mje replied to GregFreeman's topic in Object-Oriented Programming
Sounds to me like a classic example of serialization. The caveat being you might be forcing a hierarchy that is different (or possibly didn't exist) on the other end. Why not just extend the factory up through the various layers? It probably goes without saying, but I'll be explicit: the factory methods are static (not dynamic dispatchers, probably don't even have a class terminal). BaseMessage.Create() reads what it needs to in order to delegate to any of the TypeN.Create() methods. Similarly the TypeN.Create() method reads what it needs to, and delegates another level to the appropriate FinalSubclassN.Create() method. It's only however many levels deep into the Create() methods when the class is fully resolved that the appropriate type is determined and returned. Any dynamic dispatching happens after the create factory stack has sorted out the type. Err yeah, looks like PiDi had a similar recommendation. And for the record, when I said "probably don't even have a class terminal", I meant input terminal. -
Oh you are preaching to the choir with respect to wishing for a native poly terminal. True you'd still need to know the type for the variant function but at least you could decouple that bit from the accessor.
-
It also requires that you know the type ahead of time to drop the correct terminal. Which of course is the point of the "run time" preservation in the suggestion (yes I know there's nothing "run time" about it, but we are drawing an analogy).
-
I wish I could kudos that more than once.