

mje
-
Posts
1,068 -
Joined
-
Last visited
-
Days Won
48
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by mje
-
-
I didn't kudos the idea because I don't like it. I don't see much use for having the symbols be available on the block diagram per se. I can't think of a use case where it would be proper to want to display that information or react to it at run-time in light of other available features. Now that we have inline VIs I believe they are much more suited to the task when you need to react to constant values outside of a conditional structure.
To me the purpose of symbols is to resolve issues before run-time. If you need to display a symbol on the front panel, or react to the "value" of a symbol at run-time, I'd suggest you'd be better served by reexamining what you're trying to do. Still, if you're determined to do it, there are existing constructs that can do as much.
However I do understand why someone would want this idea, it's similar to the use of #define vs static const in the C languages. I lean on the side of using the actual const because it comes along with type safety, debug info, scope, etc-- but I would be lying if I said I've never used a #define to hold actual values used at run-time.
That said there is some functionality sorely lacking as far as symbols go. Like Mikael has stated, the inability to define them at the build spec level is a particularly big oversight in my opinion.
-
No need for polling. There are many ways to tackle this depending on how much control you have over the server application.
I'd say the easiest way is to just register a callback on the browser object to notify you of a navigation complete event. Your job will be to check the URI of the navigation, and if it indicates a submission, then go ahead and query the server. For example (LV2011 SP1):
When you run submit example.vi, it will show you the lavag.org website and continue to run until you execute a search on the forum. Rather than returning, your application would have to do more sophisticated handling such as error handling, then go ahead and query the server, but this proves the basic premise.
I'd likely stick most of this logic in the callback VI instead of the event frame, but for the example I wanted most of the code in the same place.
-
 1
1
-
-
Can't say I have any suggestions. I've gone down this road before in an attempt to implement something similar to IDispatch. I've been wanting some sort of reflection pretty much since LabVIEW introduced OOP support, but haven't been able to get any further than you.
-
Interesting!
-
Hi Mikael,
Can you clarify something? Are you interfacing with an existing http based application? Are you looking to host the application's form and pull data from the form without sending it to the server, or were you wanting to let the form submit data to the server, then query the server for a result?
-
The stream API is not supported on the USB-8451 - I don't remember exactly where I read this, but I'll try and find it for documentation's sake.
The documentation they have on these devices and toolkit (NI-845x Hardware and Software Manual) is pretty meh - the hardware descriptions between the 8451 and 8452 are pretty inconsistent, for one (for example, the USB-8451 doesn't list a transfer size at all).
Yeah, the documentation is quite...well, let's just say unclear in some respects. I don't want to say it's bad, because it does have a lot of information. It's just also missing some important stuff. I don't think I ever did find any clue as to which of the devices formally support the different levels of the SPI API.
I did play with scripting as well, but in the end, none of the low level APIs worked simply because the device just seems inherently incapable of supporting the combination of timing and data frame size I had to deal with. Ultimately I have a really ugly solution using the high level API.
Basically I get a data-ready signal every ~5 ms or so, at which point I need to do my 96-bit data exchange on a 100 kHz clock. There are a few subtleties I won't go into, but that's the basic task and it ought to be very easy. I could probably bang out FPGA code to do this in no time at all, but I'm unfortunately stuck to a PC only environment.
Do you really want to hear this?
My solution (and I cringe at it even now) is basically a two-piece kludge. I have another NI device with DAQmx counter support. I put the data ready line on a counter, and that counter serves as a timing source for a timed loop with the highest level priority, placed in a VI with critical priority level which runs in a Windows PC. Every time the timed loop executes I just read my 96-bits from the SPI device using the high level API and hope the OS hasn't introduced enough jitter to make me have a reading frame error.
So yes, if you're following that's a software-based trigger with no hardware-based data buffer and is pretty much how you should never do data acquisition. However 5 ms is a very long time for a computer and it does work remarkably well considering there's no determinism built into any of it.
-
I was contacted via PM about this thread, so I'll post a follow-up here.
The short answer is I was never successful getting the stream API to work on the 8451. It does work though on the 8452, however wasn't of much use to me either since it's limited to something like 24 or 32-bit data lengths and I had a 96-bit data frame.
So in the end, I fell back to the 8451 and use the higher level functions, reading 8-bits at a time. This introduced an irregular waveform in that I have a pause in my serial clock every 8-bits, but the device I was interfacing with was tolerant enough to not have a problem at the waveform.
Overall I'm not too impressed with the SPI devices, and would rather implement everything on an FPGA, but that wasn't an option for this project.
-
I like it. I've always liked the ability to dynamically query an object at run-time for a given interface as is done in COM.
For those who aren't familiar with COM and the trick that's getting played here, I've annotated the key thing that's happening with wire colors.
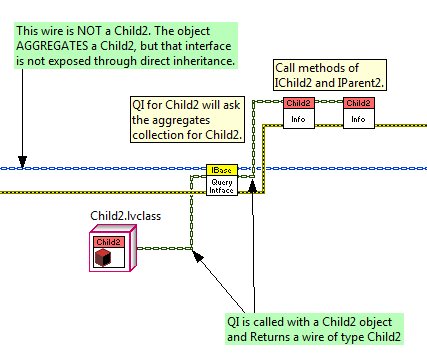
You can do some pretty cool things with the PRC primitive indeed.
Well done, candidus.
-
1
-
-
Hah, indeed.
-
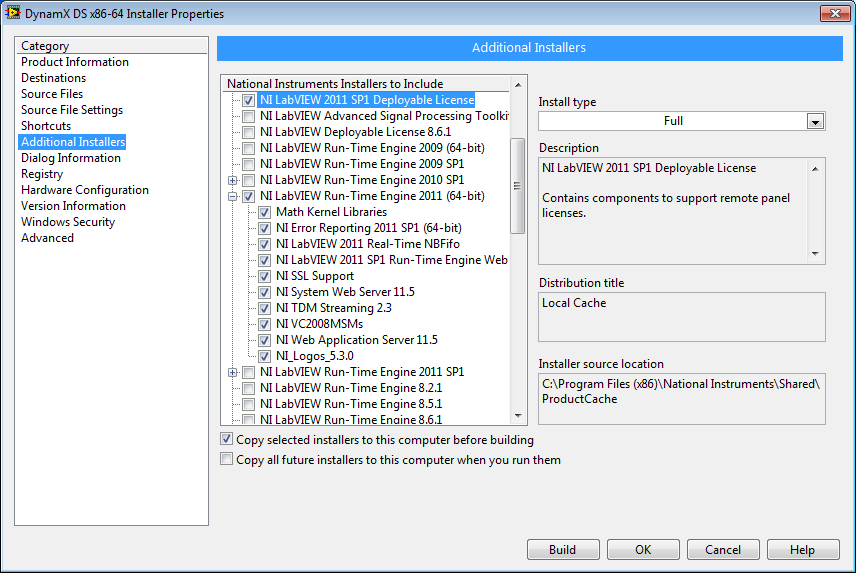
OK bingo. It's the Deployable License. There's a separate entry in the additional installers that is not part of the RTE.
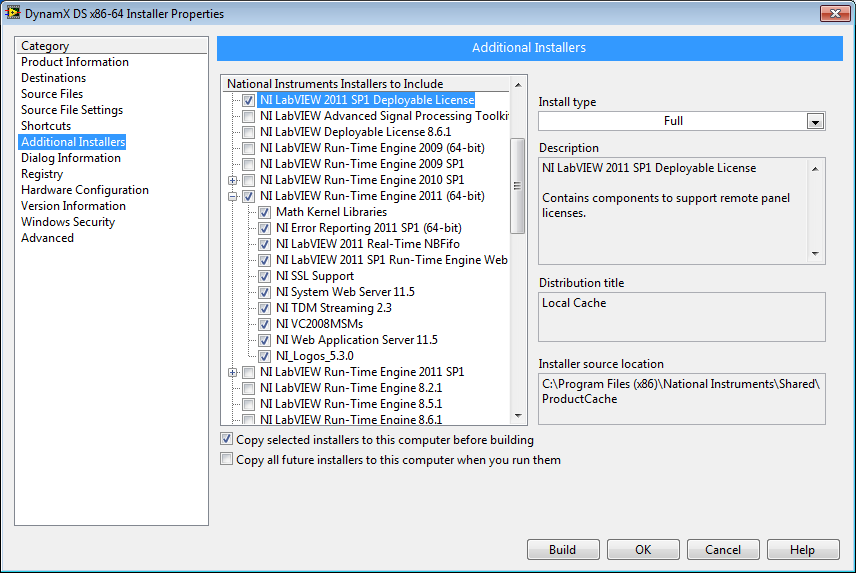
I have no idea why my 64-bit code requires the license but my 32-bit code does not. This is distressing, especially since I don't use remote panels. I'm now worried about our legal ability to distribute the code, having to distribute a license for an unknown reason doesn't leave me feeling particularly confident.
-
Ah, thanks for the info on USI.
Debugging it would be good, except I'd expect any machine with the IDE has all the required components to run the executable so there would be no problem to debug! I'm definitely not using remote panels.
-
Has anyone had issues creating installers for their 64-bit builds of LabVIEW in 2011 SP1 f1? I've spent a few days on this and this is what I've managed to pin down.
My 32-bit builds work fine, as do their installers. Distributing the 64-bit RTE with my installer though doesn't seem to work as some components always seem to be missing. After distributing my application, my startup VI runs and attempts to dynamically load the main VI for the project, failing with an error:
LabVIEW: The VI is not executable. Most likely the VI is broken or one of its subVIs cannot be located. Select File>>Open to open the VI and then verify that you are able to run it.The same executable works on a system with the 64-bit IDE, or a system where I manually install the RTE. Here's the installer configuration.
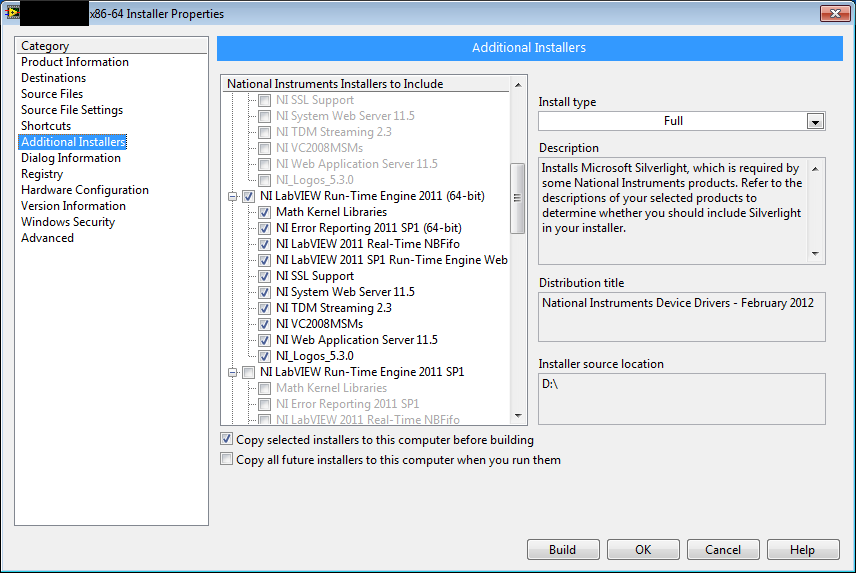
The interesting thing here is the RTE isn't labelled as SP1, despite me running the SP1f1 IDE.

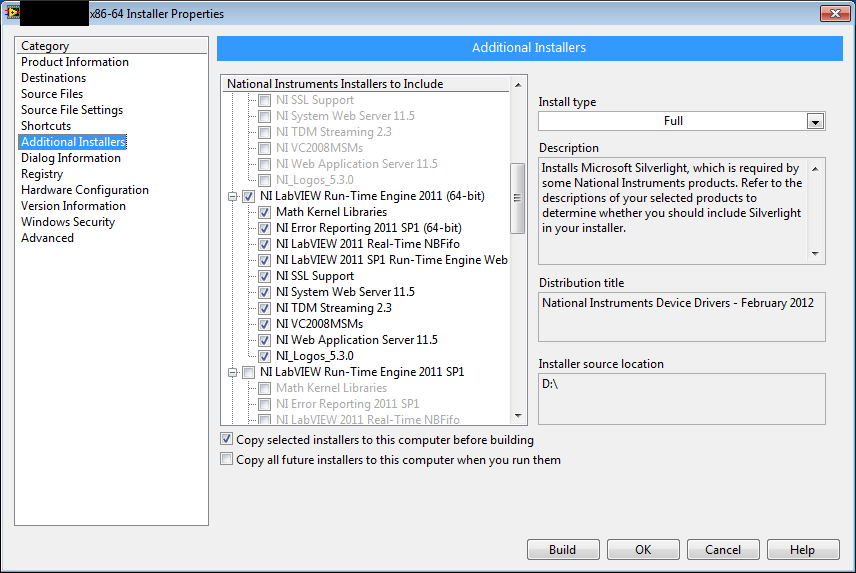
Interesting...
I don't need all of those options, but I'm desperately trying to convince LabVIEW to include an entire RTE. In the end though it doesn't. When I manually download the RTE and install it, I get this:
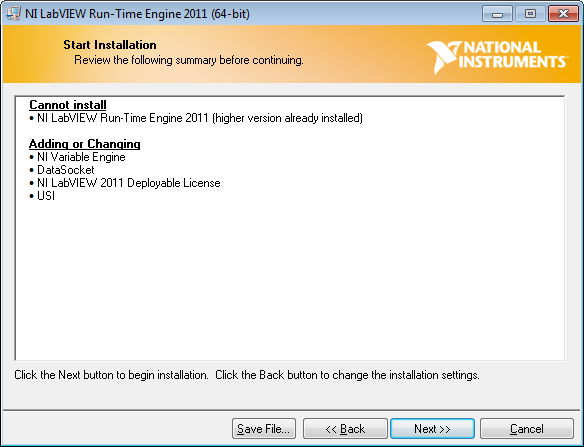
I don't know what USI is, and I don't think I use the variable engine or datasockets (but given how hard it is to trace dependencies in LabVIEW, who knows?). Sure enough though, running through the installer makes my executable work.
I've tried running the executable through depends.exe and can spot no differences in the dependency tree when loading it in a "broken" versus "good" state.
I opened a ticket on this a few weeks ago but it went unresolved, mostly due to my inability to fully investigate. I'll be reopening it soon, but in the meantime I'm wondering if any one else has seen issues with this?
-
I'm still curious if the behavior that is shown is by design or a fault. At best it seems peculiar to me...
-
I do this quite regularly. I have an application that fetches data from multiple devices each at different rates.
Each device has its own task running dumping data into a queue. Then there's a master task that at a regular rate grabs what's in the main input queues and generates output data and serializes as appropriate. The main task has to run at or slower than the slowest input rate.
What to do with data in the queues depends on your application. Mine simply flushes the queues grabbing whatever is there and runs it through a median filter to get the logged rate on par with the slowest component. I do this mostly because frequency aliasing and jitter means I won't always have the same number of elements waiting. Also has the benefit of improving the effective bit resolution on my measurements.
Correction, the median filter has no effect on resolution. Some of my tasks use mean filtering though, which does.
-
Very nice demo of the behavior.
-
There is a valid use case for creating a wrapper class that has a reduced set of methods that wraps an inner class. This is done a lot in various programming languages to create a read-only version of the class, so the wrapper class only has methods for reading values, not writing them. You would then hide the core class inside the packed project library (making it private to the library) and expose your wrapper class only.
To me a better approach would be to just support private inheritance.
/ducks
-
I doubt you could do that, I don't expect LabVIEW follows the C-style function interface. It would require you to compile a binary in a C language, make sure the proper calling convention is used for the function, and supply that function pointer. I think you're out of luck if you want to stick with LabVIEW only and have arbitrary VIs get called.
-
Heh, I was just working off the documentation which states there's a small amount of overhead in calling a VI.
When you call a subVI, there is a certain amount of overhead associated with the call. This overhead is fairly small (on the order of tens of microseconds)I don't believe it's constant though, likely involves how much stuff needs to be taken on and off the registers etc, but that's way out of the scope of my knowledge. Maybe that documentation was written in the days of the 486 and is a little out of date? Heh.
The code you posted above though doesn't call a VI, it's calling a primitive function. Slap the increment in a VI and you'll start to see the overhead come up. I just tried it and it's actually surprisingly low. I went from 30 ns per iteration when using the primitive to 100 ns per iteration when using a VI. I guess sub µs is easily done nowadays, forget about tens of µs as implied in the docs.
I'll note changing the VI to a subroutine gets execution down to 50 ns per iteration, almost par with the primitive but still a little overhead. Making the VI inline obviously gets rid of all overhead.
-
Maybe it's related to using the UI thread in the DLL call?
-
Brilliant, yes that will work very well.
Cheers!
-
I have a UI element which is largely based off a picture rendered with the LabVIEW 2D picture VIs. I've run into a problem with Draw Text at Point.vi clipping text if rendered in italics. For example, pay attention to the P, D, Q, K, I, and V characters at the top of this image.
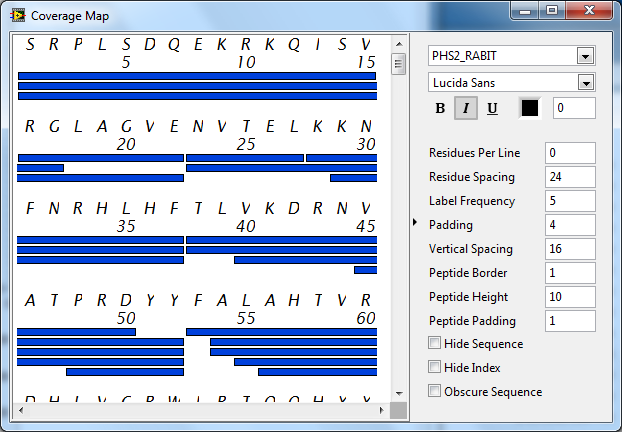
A simple snippet to play with that does shows the problem:
If you look at what makes Draw Text at Point.vi tick, it's just serial calls to Get Text Rect.vi and Draw Text in Rect.vi. It doesn't take much work to determine the real problem is that Get Text Rect.vi does not appear to properly calculate the text size when using italics.
Now if I switch to using Draw Text in Rect.vi directly and provide ample room to draw the text, I don't get clipping. But I need to know how big my text is to position it properly, map out mouse locations, etc...
Anyone worked around this before? I can't see what's going on under the hood of Get Text Rect.vi since it's password protected (not that those opcodes make much sense to me anyways).
-m
Quick note, I've tried generating a proper snippet a few times and for some reason the image never works. The metadata is intact though, if you drop it in a diagram everything is there.
-
Yeah, I'm late to the game on this one.
<meme>I don't always use feedback nodes, but when I do, it's only when I don't need the output outside the scope of a loop.</meme>
No seriously, I don't see what feedback nodes bring to the table versus shift registers when you need to use the output outside of a loop. I would consider it if altenbach's idea made it in, but I still don't like them as much as shift registers because they break data flow insomuch as the initializer terminal (and would be final value terminal) isn't visibly linked to the actual feedback node. I find this can lead to confusion in all but the smallest loops.
I use them all the time on the top level of a VI for static data, but if it's in a loop, more often than not I use SRs.
-
Serverless. It's just a library that you distribute with your application. No other processes, installers, etc.
-
Well, I'm definitely not the resident expert, but we do use SQLite for our biggest LabVIEW application. Typing can be tricky since columns don't have a fixed type, it's the individual values that are typed. That said, SQLite pretty much interconverts as necessary, so doesn't really care about types in most cases.
1) Non-issue really. If you see a LabVIEW string, you'll always have to check for null characters anyways to decide if you're going to bind text/blob. Unless you store all text as blobs, but then you need to throw collation out the window (I think?) and searching becomes interesting.
2) U64s will store just fine as text, though searching might bet a bit weird. Keep in mind SQLite decides how to store something, not you. Even if you bind the string "123" as text, there's a good chance SQLite will store it as an I8 instead (though column affinities might come into play, not sure).
3) Eek, I wasn't aware of the NaN issue. Not a big deal though since null is meaningless to a DBL. If the user is requesting a DBL, do a type check: if you see a DBL, retrieve the data, if you see a null, return NaN.
4) For timestamps, I like the ISO8601 strings ("YYYY-MM-DD HH:MM:SS.SSS") values. They're easy to read, easy to parse, easy to generate.
I'd stay away from variants, due to performance hits. If you're set on them, leave them on a top level palette with lower level access.
-
1
-


Interface provider inspired by COM
in Object-Oriented Programming
Posted
By value will work fine so long as you don't expect any modifications you make to the returned interface to affect the original object. This is perfectly valid in some cases, but not in others...