- Popular Post


mje
-
Posts
1,068 -
Joined
-
Last visited
-
Days Won
48
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by mje
-
-
As for the User Event, asking for a new node that, given a User Event, outputs a "Registration-Only User Event" gives you something that could still be connected to a Register Event node.
That is a great idea. Other functionality, such as only allowing signalling to a user event can be encapsulated, so there should be no need to further extend this beyond reg-only refnums.
-
I can't say the issue has ever caused me any problems, but from a security stand point it's always caught me a little off guard*. You can always keep the write method of a class/library private, but when you need to expose a refnum to external code, the very act of making it readable exposes it to the potential of being closed without you knowing. Many times you can abstract out the refnum such that it is protected, but...
But what if you want the library to provide an event people can register for? You can't expose that as anything other than an event reference.
Exactly this. The problem is with things like user events. You have no other option than to expose the raw refnums.
If LV isn't already tracking which VI opened the reference (and I can't really find a compelling reason that it would have needed to before this feature) then I don't see an ideal solution for resolving where the reference was opened.
Indeed, it might not be easily done, but I expect somewhere LabVIEW is aware of where refnums are created, because you can always get bitten by refnums going invalid if the hierarchy that created the refnum returns, for example.
*Granted exposing a refnum which could be closed is not that fundamentally different from passing around pointers in C++, where calling code could maliciously perform a delete operation on a pointer to a location it never created. Then again, just because other languages do something, is not a reason for LabVIEW to do the same.
Part of me feels that if I lock down the ability of external code to write which refnum is being used, I feel I ought to be able to control who can also close that refnum, but ultimately I think enforcing such a mechanism is not the job of the language. I think it's really just a matter of contract, you only delete what you create. I'm not sure controlling the scope of matching create/delete operations is even possible, let alone a good idea.
But I've been back and forth on the issue many times over the years. Right now, I'm back in the camp of it's working as intended, though I definitely won't be surprised to see a solid consensus to the contrary.
-
It's the ctl that defines the private data cluster of the lvclass. Granted there is no actual ctl file, but it appears as so in the project explorer. I probably should have best described it as an item in the project explorer.
Editing the class outside of the larger project often works, but that's really avoiding the issue. For starters if the lvclass is part of a library, the entire library must be loaded to edit the class. Often when this issue creeps up, the class can't be removed from the library either, for if you try to do so, LabVIEW gets horribly confused.
I did manage to get all the functionality I needed added to the class. However I still can't delete legacy elements. Last night I left LabVIEW for 14 hours, and when I came back in the morning it was still chugging away after I tried deleting a DBL from the private data cluster. Oh well, I guess I can live with orphaned data. It's inelegant, but at least the functionality I need is there.
-
For what it's worth, if I add a save operation between step 4 and 5, I can get through adding the control now. It won't get back the previous hour and a half though...
-
Excuse me while I vent, but I can't be the only one in this situation.
Let's see if this sounds familiar to anyone, as an exercise we'll play a follow along game with how to add a control to an existing class:
- Open the class' .ctl file.
- Drop the new control in the private data cluster.
- Wait...
- Does LabVIEW recover? If no, kill LabVIEW.exe and start again at step 1.
- Rename the control so it has a proper name.
- Wait...
- Does LabVIEW recover? If no, kill LabVIEW.exe and start again at step 1.
- Save the .ctl file and move on.
This scenario has become all too familiar on a large project I work on, let's just say there better be a damned good reason for me to change any of those classes (and honestly, it's not that "big", it's just "LabVIEW big", maybe 1600 VIs). But I also have a much smaller project with maybe 18 classes (~250 VIs) and the inheritance hierarchy is at best, three levels deep. And now LabVIEW sees fit freeze indefinitely when I drop a new control on one of my classes.
Don't get me wrong, I love OOP in LabVIEW. Frankly, without OOP I would have relegated the language as a relic of the past and moved on long ago. But I'm getting a little tired of not talking about this dirty little secret. OOP is great, but it's not all sunshine and lollipops, there are some serious gremlins creeping around in there. I've been trying for over an hour to add a DBL to one of my classes and still no luck. Seriously? Come on now.
Mass recompiled my project? Check.
Flush my object cache? Check.
Surely this happens to others?
-
 1
1
- Open the class' .ctl file.
-
Yes, deferring works. We have an implementation that does this, defer, then iterate over each dataset, saving an image for each one, then finally restoring the panel. Works surprisingly well and fast.
-
I've grown an aversion to XML for serialization due to the size of the documents I'm creating. Also, let's face it: to the non programmer, XML is NOT readable.
However, I think the only way of really doing this is to have each class implement a common interface for serialization, whether it's XML, binary, or something in between. In the end, it means nothing you serialize will directly inherited from LABVIEW Object, but whatever your core serialization superclass is. Then each class implements their own ToXML, or whatever. Messy and cumbersome. If you support reading multiple versions, somewhere is a case structure monolith in each class too.
For the record, my methods usually involves dumping serial data into an anonymous cluster and writing it to disk (or whatever). Depending on the implementation the cluster might be proceeded by a version and class id of some type. Usually I do binary, but I do use XML from time to time if the data is small, say less than 50 MB.
-
2
-
-
Basically the ActiveX specific typestring description contains a 0x3110, 0x0, 0x4, <16 bytes for the ActiveX Class GUID>, 0x0, 0x1, <16 bytes for the Interface GUID>...
I do like the idea of pulling the GUID from the typestring, and might work in this situation (or not...I honestly don't know what a SequenceContext is) but I expect it wouldn't work as a general solution. If you're looking for an interface that could be implemented in any number of refnum classes, you'd need to maintain a list of all possible GUIDs to compare against, which might not be possible. Versioning also worries me.
-
The little dots that appear on the diagram when you use the Tools > Profile > Show Buffer Allocations... option.
Just be aware, that a buffer allocation doesn't mean that a copy will happen. It's ambiguous, I know, but it's all we got.
Thanks for the info, AQ.
-
Unless he knows the TMS node creates a copy when the cast fails, *and* knows that copy isn't created when the output terminal isn't wired, it looks like code that would show up on a "Look at what the dumb previous developer did" thread.
Agreed. I understand the code, but clarity of intent is far from good. This trick is neat, but just like the use of the PRT primitive to extract a default value (which you've also shown and I've grown to use), I will file this trick as one which will always require a decent dose of commenting to explain my intention lest I review the code a year later and not remember what I was thinking, let alone another programmer.
Proliferation of the palette be damned, the single most important part of code is communicating intent. There's a reason it wasn't Perl that made the web what it is today, and a lack of power definitely wasn't it...
I rarely pull out the Show Buffer Allocations tool. Generally speaking I don't find it very helpful in figuring out why memory is being allocated or where I should apply my efforts to get the most bang for my buck.
Also agreed. Though it helps, it's far too vague and I find it never really answers any questions. I'd much rather have a better rundown over where my copies are being created. After two years of code tweaking, one of my applications still winds up using about 1.5x the memory it should when I tally up all the data it's keeping track of. The fact that I've been using LabVIEW for over 15 years, consider myself a competent architect and I still can't seem to get control over my memory footprint says something for the state of memory management in the language in my opinion.
-
False is indeed correct*
That said, If you create a static property node for a control on the front panel, the front panel will always be loaded. This has actual value because when you build an application, the default behavior for most subVIs is to have their front panel removed and there are certain VIs where creating a property node is the easiest way to force LV to keep the FP.
(Emphasis added)
Indeed Yair is correct from what I've learned. Having a property node which operates on an arbitrary control refnum (that is where you explicitly wire the refnum into the node) does not force the front panel into memory because the refnum being operated on might not even be for a control in the same VI.
-
Good point, although keep in mind the allocation dots only say a buffer might be allocated. Of course I can't think of a single case where reversing a string would ever not be able to operate in place, so I expect that it tells the compiler it might allocate, in reality it always does...
-
Easy question: Are LabVIEW strings immutable?
If I'm working with large strings, and changing individual characters in the string, does each operation force a new string to be allocated? Or does the compiler internally operate on the string like an array if the operation does not force a frame shift, length change, or what have you?
-
One thing I didn't reply on the NI forums (also because of the wonkiness that crelf likely experienced) is it might be nice to have the second class have a different wire than the first, as to emphasize where the wire types mutate.
-
Along the lines of what Ben suggested, I believe you can simply add a second plot with x=0 for all y values and simply use that plot as the fill baseline for the first plot. I'd do the similar thing for the horizontal rendering (y=0 for all x) so you do not have to futz with the fill baseline via property nodes and can always fill to plot 1.
Can't believe I never thought of that. Thanks, Darin.
-
Yes, both those options are doable, I just wanted to survey for a pre-canned solution before I go about possibly re-inventing the wheel.
-
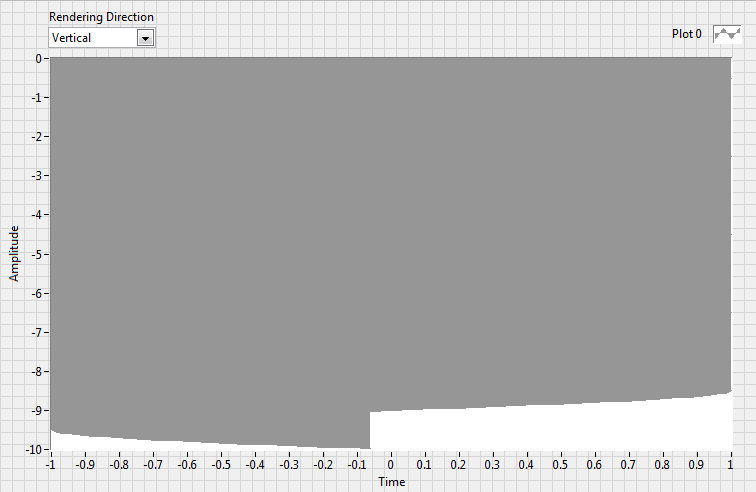
Please see the attached VI:
If you execute the VI with the "Render Direction" set to Horizontal, you get a plot like so:
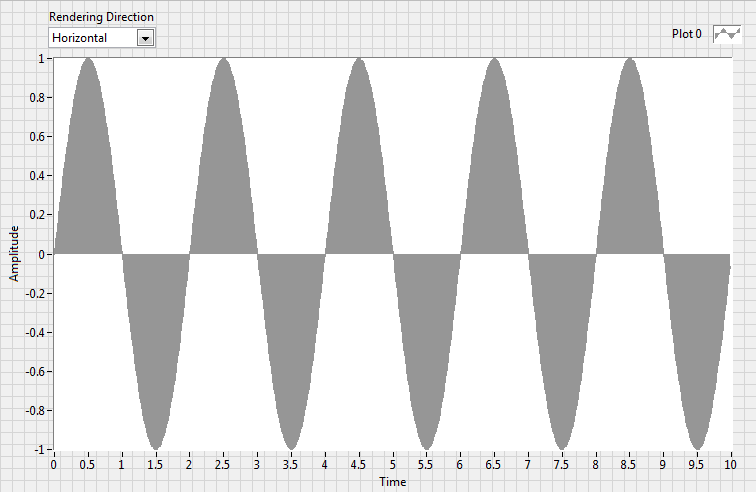
What we have here is a plot set to fill to zero. Works exactly as I'd like.
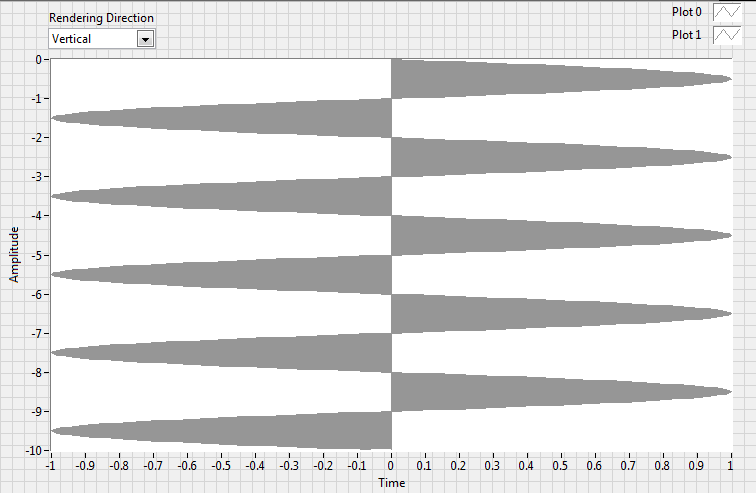
The problem is my application also requires that the plot be able to be rendered Vertical. So my application applies a simple transform to the data such that the axes get swapped, as shown in the VI. But when rendering data in this mode, the fill operation of course still fills vertically:
Correct me if I'm wrong, but there's no way to set the fill direction, is there?
-
I'd like to see NI provide more of a base class library as well, but I don't think LVOOP is quite ready for it. It needs a solution to the strict single inheritance paradigm first. Add a way to aggregate behaviors across the inheritance tree (interfaces, mixins, traits, etc.,) then a base class library will have a better foundation to build on.
Agreed.
-
When designing the flattened data format of LV classes, I really didn't give any consideration to someone deliberately mucking about with the string.
Wise in my opinion. After all, it's no different than doing the following in C++:
void foo(SomeObject obj) { // Operates directly on the object data, regardless of access scope to the underlying data *((char *) &obj) |= 0xff; } [/CODE]Honestly, I made a big mistake in making the Flatten To String and Flatten to XML primitives work on objects by default. The other major programming languages of the world all require classes to opt-in to such abilities. They are not serializable (meaning "can go to/from string") by default. The only ones that are serializable are the ones that programmers declare that way deliberately, and then they have code in the unserialize method to check for tampering, if the class has critical internal data relationships that must be maintained. We lack any such hooks in LabVIEW. It's one of the few areas of LV classes that I wish I could retroactively redesign.
Such functionality could be introduced (at the expense of backwards compatibility) by extending the core LabVIEW object to include dynamic dispatch methods that handle serialization, among other things. As it stands, LabVIEW Object as a class doesn't really serve any purpose to the programmer other than being the superclass of all objects, it has no public or protected interface.
-
LOL.
Yeah, that's exactly what I was thinking about. For the first time I'm noticing it's "deprecated" not "depreciated". I suppose that's why my google-fu failed me. Well, that and the fact that it's impossible to do unless you know the ways of the NI Engineer.
-
Posted to the idea exchange.
-
Cool, thanks for the quick reply.
Hmm... would you ever want to deprecate only the read or only the write half of a property? If that's a use case, it might be better to be on the VIs themselves.
Currently yes, I'm only depreciating only the write operation, though I'm not convinced this is wise. Due to a change in my data model, the write operation can become brutally inefficient, but the read is still pretty straight forward.
I was thinking of it being applied via the "Item Settings" category of the class properties, though I'm undecided on where best to apply it. If it becomes a settable flag of the Property Folder itself, I imagine differentiating read/write becomes impossible. Maybe the flag would only be settable at the VI level, but only for VIs which are part of a property folder, is that possible?
-
I have an application I'm updating and it looks like I must deprecate a property in a complex class I've created. When dealing with normal VIs (be they class methods or just plain VIs) I usually color the icon differently to give a visual cue to say something to the effect of, "Hey, I'm different, you had better look at the documentation if you plan on using me."
However when dealing with class properties, you don't exactly see the icon. I know internally LabVIEW will color code property/invoke nodes if they call "super-secret" or deprecated interfaces, is this functionality exported in any way that we can take advantage of it in classes?
-
My dislike of the icons I think mostly stems from that they never existed for the longest time, so their size is just so off-putting.
In theory I think icons are good for object heavy code, as I hate having several different "OBJ" terminals which I can only distinguish by color/wire ("Was the "Foo" widget brown with hashed wires or blue with dotted wires?"). In practice I still can't bring myself to use icons though, they just feel so...wrong.

Editing an existing class
in Object-Oriented Programming
Posted
Well, I've tracked this down to an issue being brought on to using classes within a LabVIEW library. The two kinds of libraries (.lvlib and .lvclass) just plain do not work together.
My little project's classes became plain uneditable, they were contained in an lvlib. In a fit of frustration, I dragged the entire lvlib hierarchy out of the library scope, and magically everything just works as intended. This is a shame, for lvlibs offered a lot of control and namespacing which really helps with code reuse. Please to any at NI who are reading this thread, fix this.
Well, it's a good thing I got this working. I'm literally down to the last hours, about to be gone for two weeks and this code has to work by end of day. Meanwhile, I just lost two hours trying to add a simple primitive to one of my classes.
Since there's no way I'm going to drop my use of .lvclass objects, I'm done with lvlibs for now.