

mje
-
Posts
1,068 -
Joined
-
Last visited
-
Days Won
48
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by mje
-
-
That's good to know. Thanks for the confirmation, Greg.
-m
-
I'm working with 2D pictures and trying to keep everything vector based since my images can get quite large. Am I missing something or is the only way to deal with EMFs to use a dummy picture control for operations?
For example, this bit of code copies an EMF to the clipboard by rendering the picture to a local control, resizing to fit the bounds of the picture, and then invoking the export method. The bitmap based methods have VIs to handle the conversion, but are we out of luck if we want to deal with EMFs?
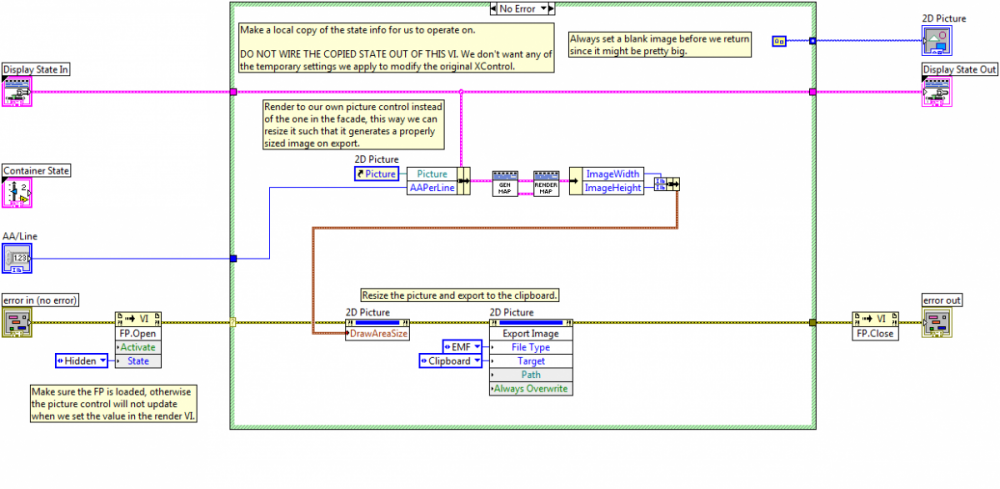
-
Thanks Yair. Interesting, I didn't recall that discussion. Definitely not ideal, mind you.
-
I can't seem to figure out how to capture scroll wheel events from a mouse. I have an X-Control that manually manages its v-scroll, and it seems counter-intuitive for the wheel not to work when hovering over top.
-
Also surprised it works at all, my guess is if you tried calling any methods on the refnum you'd see fireworks.
I take it these objects are unrelated, so you can't do proper dynamic casts via the to more specific primitive?
-
I need to have to run through release validation prior to August. So that means no 2012 for us until after current project releases. Second year in a row...

-
That's good news, hopefully with time it can get worked into release code

-
I'm wondering, other than a general ban on the use of property nodes in inline VIs, is there anything that would exclude a VI from being inlined if it uses OOP based pnodes and the logic were updated to differentiate between the classes of pnodes? I imagine functionally they have no relation to VI server pnodes (I hope?) so does it really make sense to have this restriction be applied blindly?
-
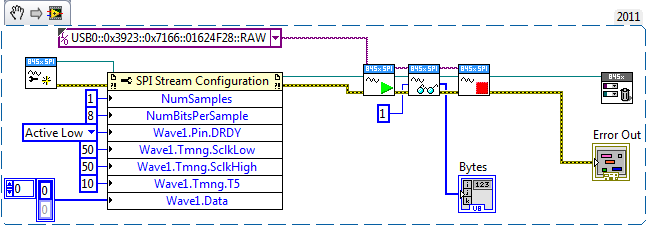
Has anyone had any luck using the NI-845x SPI Stream API? I've been spinning my wheels in the mud for two days now.
The example that NI ships appears to be specific to the 8452 device, or at least it doesn't appear to work on the 8451, which is what I have. Getting even the most simple exchanges to work fail miserably.
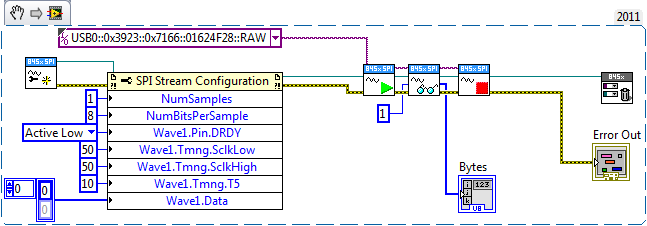
"Error -301713 occurred at NI-845x SPI Stream Start.vi. Possible reason(s): NI-845x: An input parameter, or combination of parameters, is invalid."
Awesome, thanks for the info.
Does anyone have a functional example I can learn off of? I know this is a long shot, but I thought I'd try here first before heading over to the dark side. I've called NI support, and about all I got out of it is it "should" work. Well, I agree, but reality seems to be getting in the way of theory...
Note I can get the higher level APIs to work, but they won't work for my application. I need finer control over timing delays than the other API provides.
-
Try a png instead. Bitmaps are ridiculously inefficient, my guess is the forums don't allow them for bandwidth reasons.
-
Being a chemist rather than an engineer, I can't say I really know the finer details of what differentiates a k-d from a red-black or a spruce, but those are all very good tips which can take years of experience to learn. They are valuable to know in any context where performance matters.
I for one never thought of the ramifications of using the timed loop. Interesting.
-
Yup. Bonus points for setting event handlers for arrow/tab keys for navigation.
-
The CR/LF constant in labview is platform dependent. It also depends on which browser you are viewing in (some are happy with only one EOL char, others require both). You should use a constant string with "\r\n" which will work on all platforms and browsers.
Haven't downloaded any of the recent code, but if I recall the HTTP 1.1 Specification explicitly requires CRLF sequences in the response status and headers, including the header terminator (empty line). See section 6 and other sections referenced therein. Granted many browsers don't care, but if you're designing something from the ground up, I'd say it would be best to stick with the specification and not have to rely on quirks that might be implemented in whatever your favorite browser is.
As Shaun implied, the line terminator constant in LabVIEW is platform dependent, I'd stick with strings containing "\r\n".
-
Very nice, John. I like it.
-
- Popular Post
- Popular Post
I think you're thinking of vi.lib\platform\fileVersionInfo.llb\FileVersionInfo.vi
That's the one! Of course the VI just makes a call to a bunch of system DLLs, so I don't think it would work on Linux/Mac/Etc. Ultimately you're really not gaining anything over .NET other than you don't need to deal with it directly.
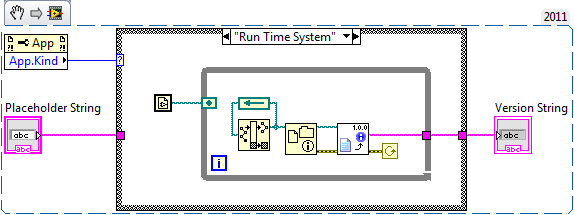
The snippet above probably doesn't require the file/directory info primitive, but I've always used it as such and not found with any trouble. I'd love to play with some scripting or use j's code to have version info in the IDE, but that's so low on the priority list since ultimately the application is always distributed in built form.
-
 7
7
-
I regularly put version numbers in splash screens etc, especially for things like nightly test builds where it is imperitive the tester know exactly which version they are running.
There is a vi in vi.lib that will natively return the version of an executable, there is no need to bust out the .NET. Sorry, no LabVIEW on my phone so I can't comment where it is or what it's called.
The problem of course is it requires an exe, so you can't get the number until you've built. For now I just wrap the call, and when debugging my version call returns a dummy string "IDE Version".
I agree it should be way easier to get this info so one could statically link that info into a VI.
-
As I see it there are a few bits of information that need to be shared for successful serialization of a data structure.
The Shared Schema
This is the most fundamental part, it is the contract that defines how to interpret what is being transmitted or stored. I'm not even being XML specific here, I mean schema in the most abstract sense-- some shared grammar that must be understood by both the code doing the serialization and that doing the deserialization. Maybe a schema is a literal XML schema, maybe it's a database schema, or maybe it's some obscure binary format.
At the very least, you probably want a schema to be version aware. If your data structure changes from a SGL to a DBL, between version 1.0 and 1.1, that's important to know. The schema might wish to carry along version history as well, but I wouldn't say this is a requirement.
In native code, you can think of each .lvclass as the schema for that class, though it doesn't really serve that purpose in the general sense since it doesn't express that information very well to anything other than LabVIEW.
The Class Identifier and Version
The object identifier is the fundamental unit that identifies what is being serialized. It could be anything so long as any given identifier resolves to a single type. Similarly most objects are going to want to be version aware to allow a given type to evolve over time. The native mechanism I believe uses the qualified class name and a four word (4 x U16) version number.
The Object Data
This is the actual value of what is being transmitted. As has been pointed out, simply saying "default" usually doesn't cut it. Strictly speaking though, if your schema maintains a whole version history and defines the default for each version, it is sufficient, but I find it far easier to always serialize all data simply because maintaining a version history in the schema is hard. LabVIEW can handle the "default" problem because the lvclass file holds the version history, all be it in an obfuscated binary format.
Designing a Serialization API
Let's start with deserialization. What are the fundamental steps in deserialization?
At it's heart, we're going to have some stream of data, and our job is to figure out what that data represents, create an instance of some representative object in our application, then properly transfer all or parts of the serialized data to that instance.
So let's define a base class, serializable.lvclass. In our schema, all objects which are serialized inherit from this class. What do we need to know to be able to create a proper instance of this type when we deserialize it?
Whatever our implementation is, at some level we're going to have to examine this data stream and figure out what to actually instantiate. If you're familiar with design patterns, this is should be a big flashing sign for a factory. The factory's job is to take an identifier in, create a concrete instance of whatever type we have to represent that identifier's schema, and return it as a serializable object.
Once the factory has returned us an instance of a serializable object, we can then call that object's dynamic deserialize.vi method, passing to it the remaining data in the stream. This method's job will be to consume as much of the stream as required by our schema. Internally, you can imagine the next piece of information deserialize will require is a version number, followed by any version specific data. It can then pass the data stream to its parent implementation, which will in turn consume what's required from the stream until the end of the line is reached and the base serializable.lvclass:deserialize.vi implementation.
Meanwhile a similar serializable.lvclass:serialize.vi dynamic method exists. It will write its version number, all data for the class, then pass the stream up the inheritance chain so each level in the hierarchy can get a crack at it. This method shouldn't serialize the class identifier, because that is handled at a scope outside of the serialize/deserialize methods. Recall deserialize.vi is not called until after our logic has consumed the identifier from the stream, so similarly we can expect the class identifier has already been committed to the stream before serialize.vi has been called.
There are some subtleties here I won't get into that really are best exposed in an example, which I definitely can't produce tonight. Quickly though:
- A dynamic method serializable.lvclass:identifier.vi exists which must be overridden. The responsibility of this method is to return the unique class identifier for a concrete implementation.
- A static serializeObject.vi method exists which takes a stream, and a serializable object as input. This method will first commit the value returned from identifier.vi to the stream, then pass the stream onto the object's serialize.vi method.
- Similarly a static deserializeObject.vi method exists which consumes a class identifier from the stream, calls a factory method to get an instance of the appropriate serializable object, then passes the remaining stream onto the object's deserialize.vi method.
- Since the serialize/deserialize methods are only intended to be called from within the scope of a class hierarchy, or by a static wrapper, I propose the static wrappers be member of serializable.lvclass and the dynamic methods be protected.
This all implies that class identifiers for ancestor classes are never serialized. That is the inheritance of a class is defined in the schema, and becomes hard-coded into a class implementation.
Also implied is versioning is delegated the class implementations as well. Versions can be absent entirely, or partially implemented. For example most of my applications can read most any version for which a schema was defined, but can only write the most recent schema for which the application is aware.
This is a lot of text, but fundamentally quite simple. There's only a single class and a handful of methods. The reason I haven't implemented a clear example so far is there are two "feats" that I think need to be overcome to change this from what's really a design pattern to something with a real utility as a re-use class.
- The factory. There are many ways to go about doing this, I haven't settled on how I wish to make it extensible. I have ideas, but I'm tired at this point and this post is already way too long.
- The stream. I really want to avoid writing yet another serialization scheme which is hard-coded for a file stream, a TCP/IP stream, a string, or a byte array. I really want to develop an abstraction layer that is fast, such that what the stream is becomes completely transparent to each class being serialized.
-
1
- A dynamic method serializable.lvclass:identifier.vi exists which must be overridden. The responsibility of this method is to return the unique class identifier for a concrete implementation.
-
I just ran into this issue with some code I wrote in LV10 and then tried to run in LV11. This thread proved most useful as MJE's solution worked exactly as advertised, so a big thanks and kudos! But I have to ask, the idea of NOT using a function called unregister for events and instead using null refs to ... you guessed it ... unregister for events seems like some pretty arcane knowledge. Where did you get this tidbit of information?
I'm glad the example proved useful. Not sure where I got that trick to be honest. Probably stems from my use of events in other languages.
The way I see it, the Unregister For Events operates on all dynamic events that are used by the event structure. True, for the simple case I posed above, using the unregister primitive can work if you start using shift registers, but only because every dynamic event handled by the structure is related to the example.
Consider extending the example: I want to receive notification from user event as well, all the time. To unregister for the two events posted in the above example but not unregister for the user event, I have to use null registration. If I call the unregister primitive, I'll end up unregistering for my user event as well. Similarly using the global unregister primitive doesn't work if you have different dynamic events with different lifetimes. Maybe you want one of your event registrations to last indefinitely, but another one times out or cancels itself if a certain piece of data is received?
I'm not saying the unregister primitive doesn't have it's place. There's still exactly one unregister primitive for each registration primitive I use in my code, it's just that the unregistration is usually left for a shutdown sequence.
-
Oh man. Paul, the timing of your post is ridiculously relevant for me. A few months back I had discovered a critical flaw in the serialization strategy I've been using for the past few years and have had to rethink things.
We need to handle the general case where we may implement one or more of the components ... in some other development environment. ... The critical problem is that if an object contains default data the flattened XML indicates that the data is default, which is only useful if the reader has access to the original class (in this case in LabVIEW).
In my opinion, this is one of the two fundamental problems with the native serialization mechanism. The other being the lack of extensibility.
With regards to your second roadblock:
Access to type information (especially to build an object from XML data). In the thread mentioned above, I sought the default value of the class. This is actually not sufficient (at least not in the form we have it). What we need is access to the class data cluster (i.e., be able to assemble a cluster of the proper type and values)--and then be able to write the cluster value to the object. I don’t think this is currently possible.What you're referring to usually comes along for the ride in a language which has some means of type-reflection. I've mentioned before how I'd love to have it, but I don't think it's necessary for serialization.
I started writing a really long reply to this, but it's late here on the east coast and I've run out of gas. Hopefully I can get the time this weekend to compose what I've pieced together over the last few months if you're interested in my opinion. I haven't gotten around to implementing any of it, so it might be useful to sound off on it.
-
I still haven't looked into the JKI solution, but here's what I got for a .NET wrapper:
There's a class in there with 4 methods.
Apply Xslt.vi: This is a high level static VI. You don't need to know anything about classes or refnums to use it. Just point it to an XML document, an XSLT document, and give it a local file path to save the output to and go.
Create.vi, Transform.vi, Destroy.vi: This is the lower level set of VIs that encompass the traditional create, reuse, destroy paradigm. If you plan on applying the same transform to multiple source documents, this is what you want to use since you only need to compile the XSL once using this method. Transform.vi is also thread safe, so you can have multiple processes spinning each sharing the same compiled xslt.
That said, I'm not a fan of the .NET 2.0 XML implementation at all. This was a quick wrapper that was easy to implement, but produces rather ugly output compared to more modern tools. I continue to look for other libraries to use, currently examining Saxon. I really like the output the Altova tools I use produces, I have no idea what they use under the hood.
The code I posted above is a VERY thin wrapper around .NET code. I make no claim to it, anyone is free to do with it as they see fit.
-m
-
1
-
-
Interesting, thanks for pointing that out, I'll have to look into it. I expect supplying a stylesheet URL might simply insert a processing instruction into the prolog of the document?
<?xml-stylesheet type="text/xsl" href="path.xsl"?> [/CODE]
I'll have to download Easy XML to check it out I suppose.
-
Oh. And as an after-thought (an after I can edit, thought
). The reason for posting wasn't to provide a "faster" version of the NI one (thats more by accident since I didn't benchmark it). Just a version that you could see the diagram - Jims request, Feel free to change the calls to UI if it makes you happier because with this offering you can 
LOL. I would. And I understood the example as how to check for classes, not an attempt at proving speed. But in all seriousness, thank you for posting that example, I've never even tried making calls directly to LabVIEW from the CLFN node. I always wondered how to do it in such a way that it automatically worked both in the IDE and RTE. I take it by referencing the library simply as "LabVIEW", that everything sorts itself out when compiled?
However, thread safety is usually defined on a per dll (or in this case per exe) basis. So if the LabVIEW.exe wasn't thread-safe. I think we would all be in trouble. Anecdotally, I have never run into any problems assuming it is.
While I don't doubt that entire libraries or executables can be declared thread safe, it's not an automatic type of thing. Just because one call is thread safe does not make another. Any code which accesses dynamic shared memory (values that can change) in an unprotected manner can (not will, but can) lead to potential problems. Shared memory can be globals, static* memory within a function, or perhaps be related to hardware access. The problem, and reason multithreading programming is "hard" is that these accesses can be buried so deep in the function stack that they can be invisible to anyone using a given API. It's even worse that offending code can appear stable until that one time threads collide in just the wrong time, of course in an unpredictable and non-reproducible way.
LabVIEW of course makes most of this completely moot when you stick to an entirely by-value architecture, but I don't need to mention there are many things in LabVIEW which aren't by-value.
Saying that. Calls to the labVIEW.exe that involve the user interface I do not make re-entrant on the assumption that it is a call within the UI thread.
Agreed, there's no point in making the VI re-entrant if the clones would need to wait for access to the same thread.
*Static is a term that is somewhat foreign to LabVIEW, but think of things like shift registers, feedback nodes, or LV2 globals, etc.
-
...and that Shaun configures the CLFN to use any thread, perhaps the LV one uses the UI thread and this takes its toll (pesky default behavior).
That would be enough to make me nervous. I consider it best practice to leave all DLL calls in the UI thread unless the call you're making has explicit documentation stating it is "thread safe". Otherwise, correct me if I'm wrong, nothing is stopping LabVIEW from making parallel calls to the DLL which might stomp on some static memory. Maybe that's just a legacy of my C days and I'm being a curmudgeon, but my understanding is that's why the UI thread is the default for CLFN nodes?
Now I do trust Shaun quite a bit, but he's not NI so I doubt he knows exactly what's going on under the hood of that call...
-
Indeed, JKI's tool is useful for getting XML data in/out of LabVIEW. We don't use it, but do have a very similar re-use library I had developed before Easy XML came to be (or at least before we were aware of it). However I'm not looking to get data in and out of LabVIEW, only to manipulate XML data which already exists.
I have code which generates an XML export of my LabVIEW data model, and now I want to be able to pull in arbitrary stylesheets to apply a transformation to that XML to generate different reports in html, docx, etc. The idea here is I don't want to write arbitrary LabVIEW code for each supported report style. I don't even want the application to be aware of the details of the potentially unbounded number of reports that might be able to be generated. I'll have a single branch of LabVIEW code that creates XML according to a well defined schema, and report generation gets offloaded entirely from LabVIEW: once the XML is created, the application will just grab some stylesheet the user has picked (XSLT), apply the transformation to the XML, and save the output to disk.
Capturing Scroll Wheel Events
in User Interface
Posted
Thanks, hooovahh. Using a hook ought to work, I was just hoping not to have to bust out the kernel calls. This would ultimately still require a worker task due to the xcontrol, although it would not be a polling, so that's good.