

mje
-
Posts
1,068 -
Joined
-
Last visited
-
Days Won
48
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by mje
-
-
Are any of you familiar if I can apply xml transformations or stylesheets using LabVIEW's built in capabilities? I'm thinking it can't be done...
Have any of you used the xerces/xalan binaries before? They seem like they ought to be able to do the trick. Since I'm platform locked to Windows, .NET ought to work as well. Or maybe other recommendations?
-
Could it be possible to load pieces of a library without loading the rest? I ask because maybe it is something for the idea exchange. I don't want to post it yet because I don't know if it is a good idea or if it is even doable.
I doubt it is possible. As soon as something is a member of a library, loading that item will force the library to be read so that item scope (among other things) can be determined. But when you load a library, LabVIEW must make sure that the library isn't broken, which demands that every item get loaded to verify status.
As DrJD implied, I think this effect propagates for linked libraries too. Break a VI that is part of a dynamic dispatch for example, you'll notice every method of every class in the hierarchy becomes broken until the single VI is fixed, never mind any other VIs that use these classes, and their libraries, ad nauseam...
-
That is a misnomer (and a common one) since foreign sites are not bound by US laws.
Oh absolutely. Please don't take my post as an expression of my opinion, it was an expression of what I've been reading in the media. Regardless of where you land on the legality/morality of these foreign rogue sites, the authority of US laws on such websites is at best tenuous.
As you've already said though, the intellectual property and copyright issues are really just smokescreens. The real issue is the power grab.
Consider how you think this would have been spun if a country like Iran or China was trying to enact legislation like this. Do you really think media would be talking about copyright? Seriously? Corruption, nationalism, and censorship would be among the first words out of every talking head's mouth if you ask me.
-
The "even those in the U.S." is important, because one of the main arguments for the legislation is to prevent foreign "rogue" sites that are up to no good, at least as has been reported in plenty of the media I've seen. I have not read the bills, but apparently there is no actual distinction between domestic/foreign even though it is one of the very arguments used to support the bill, so the powers granted could be applied on domestic terms.
If this passes, it will obviously have implications outside of the U.S. as well. The ambition of this legislation is both impressive and disgusting. Politicians really need not look far as to why popular opinion of them is so low.
Its also interesting to note of how little information is available via popular media which is controlled by the very organizations lobbying for this bill, or if you do find some, how much misinformation you'll find. I read an article just this morning about how the anti SOPA/PIPA movement's lobbying effort today has proved to be a complete failure and how no important web-dependent companies are bothering with it since they don't consider it important. REALLY?
-
Now, if SOPA passes, LAVA would be screwed, so everyone call your reps and senators and tell them to stop that trainwreck. But assuming sanity prevails, it would only be the LAVA users who download the code and use it that would be open to lawsuit threat.
I for one, have absolute faith that insanity will prevail.
-
 1
1
-
-
Congratulations! I hope you enjoy your new job.
Also hope to still see you around, I have learned a lot from your contributions to LAVA over the years.
-
Oh man, I feel like a fool. Posted this before checking my rss feed and seeing Norm's earlier post.
Oh well...
-
Is there any reason we can't step into a property node when debugging? Or for that matter step over individual properties of a node then step into the one of interest? As it stands now, I have to find the accessor method by hand, open it up and drop a breakpoint if I want to continue single stepping.
Not a terrible inconvenience, but it can slow things down. Especially if reentrancy is involved.
Just thinking out loud here. Is there something that would make this impossible?
-
This is interesting because the JSON example is essentially the same as the problem I'm facing all serialization essentially boils down to the same thing when you think about it. I don't think it would be too difficult to implement via OOP. As AQ said, create a parent class which defines the interface for generating the data stream and any serializable object just overrides that method. Voila, stream generated. Going from stream to object on the other hand requires a factory pattern in the patent class: it would parse the stream for identifiers telling it which child class to use. Once the factory has chosen the right type, deserialization is just a matter of calling another dynamic dispatch which consumes as much of the stream as it requires. These functions would need to be recursable for many stream types, including JSON.
Or maybe I've missed the boat on this one? That's what I was going to do with my project when I get around to making my project work the "right" way.
-
Isn't there at least one better way to architect so that checking for such equivalence isn't needed?
Indeed: dynamic dispatches.
In my case though simply switching to dynamic dispatches wont work because of a more fundamental flaw in an underlying serialization scheme I invented for my application. I *will* fix the flaw, but it will take time which I can't afford now, so the right way of doing it is going to have to wait.
-
Objects are definitely passed by value, but the mechanism would have to be different than used for scalars. If I have a VI that expects a DBL, the compiler knows exactly the data space required for that DBL: 8 bytes. But the size of an object can't be determined until run-time because an Object wire must be able to also carry any class inheriting from the expected class. If you think about it, in order for LabVIEW to work efficiently with objects, it *must* use some method of indirection to avoid generating copies of objects for every call- not unlike what is done with arrays and other dynamically sized data.
I hadn't seen the document linked above previously, but the diagram showing the representation of classes makes sense. The indirection is handled through pointers.
I also agree that the lack of primitives to do fundamental operations on objects is annoying. Granted operations like this are rarely needed, and in general a sign of a fundamental problem with the design of a program. I acknowledge this, but it doesnt change the fact that I have to deliver something yesterday and adding this quick check can make my code robust right away (at the expense of extensibility), compared to spending a day re-engineering my class hierarchies and doing it the "right" way.
-
I smell a trick question, but would expect LabVIEW Object, or whatever highest level of common ancestor exists between the two classes.
-
I try to stay away from the path VIs as there's some overhead in them. Attached is a modified project containing the three methods deemed MJE, Yair, and Podsim as described above. All three methods are functionally equivalent and work as intended, proven by the three test VIs.
There's also a fourth test (Timing and Memory.vi) which involves creating an object with a fixed size payload, then running the comparison in a loop for a fixed amount of iterations.
0 MB size, 100 000 iterations:
MJE: 21 ms
Yair: 36 ms
Podsim: 3632 ms
The overhead in using the path methods is evident with the small payload. It's arguable if Yair's method is significantly slower at this point, but there might be some unwanted copies going on there causing the increase in time, or it might be noise.
10 MB size, 1000 iterations:
MJE: 0 ms
Yair: 4720 ms
Podsim: 2649 ms
Here the overhead in using the path VIs isn't as bad as what must be the overhead in generating large data copies. We see that indeed as I worried about with Yair's method: the likely cause of the slowdown is data copies (?).
Note the VIs are inlined, so memory profiling is not possible. If we remove inlining, the differences in timing vanish.
-
With regards to two distinct classes with the same data, I believe the OP ought to work as part of an object's value is what class its an instance of.
Regardless, I like Yair's suggestion better as there will be less on the diagram. I would need to test it to be sure LabVIEW wouldn't make extra copies of the inbound objects- if it does that could be expensive for objects with lots of data.
Either way, I will look into this soon.
-
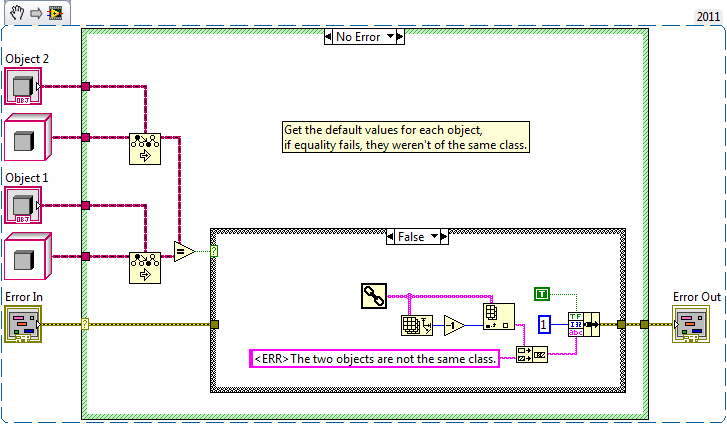
I have a use case where I should make sure two objects are of the same class. Not an instanceof test but one where I verify the final class of two objects are the same, like a typeof operation.*
So for example, even though a Class 1 inherits from LabVIEW Object, they are not the same because they are distinct classes despite the inheritance relationship.
For a generic method, I came up with this:
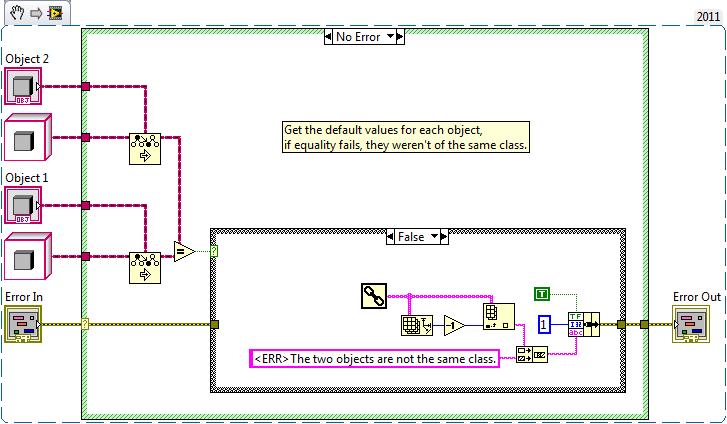
Am I missing something, there's no built in way to do this correct?
*I realize flat out that as soon as an OOP programmer needs to ask this, they're "doing it wrong". Work with me here though, sometimes timelines demand a short lived hack because redesigning the interface takes too long.
-
Once material is posted, unless it is specifically marked as protected in some way, it is de facto, no longer protected.
My understanding of copyright laws in most countries is in fact the opposite: the very act of publishing material automatically grants copyrights to the author or publisher depending on context. I'm pretty sure most countries recognize placing something online as a form of publishing. Therefore an explicit statement would be required to make example code (and posts) part of the public domain, or any license for that matter.
Should sites state that any "donated" code in forums (outside the CR) becomes public domain and they forfeit their copywrite claims or make it clear that the authors original rights are entirely preserved to clarify?
I'm unclear if enforcing any such statements have legal precedent, I suspect it lies under the same legal grey area as end-user license agreements.
-
1
-
-
Nice, I never knew you could do that.
-
And, (this'll surprise a few people) some of it is LVOOP.

No way, say it's ain't so. In other news, the sky is still blue. Well on Earth anyways, most of the time...
I'm still pumped about this topic. Granted I got to spend zero time on implementing something like this this year (still very disappointed about that), but 2012 will be different. Yeah, that's it, different. What can I say, there's still a bit of foolish youthful optimism in me.
-
2
-
-
Even with UI updates being deferred? I can't decide if that's possibly a bug or should be changed via a feature request...
Indeed, even with the UI updates deferred. Granted these are user reports, so minutes might need to be taken with a generous dose of salt, I've not been able to try these data sets out.
Part of the problem was my fault since I never bounded the size of the data set: the application was designed around small data sets where blindly updating everything was OK. There were far more important things on the priority list than eeking out a few extra ms of performance from a UI update. Move from a few hundred to a few hundred thousand rows though and things are a different story.
These controls (trees, mclb) seem to be implemented such that once you've applied formatting to cells, the control remembers that formatting data for every cell regardless of whether that cell has data in it. I'm not arguing this shouldn't be the case, but it becomes troublesome since there seems to be no means to clear the formatting data.
Once you've applied formatting to a large number of cells, operating on that data set becomes slow. Combine that with the fact that applying each facet of formatting requires an individual operation for each cell and the number of operations required can quickly multiply. Want to set font color, style, and justification? That's four operations per cell: cell selection, apply color, apply style, apply justification. If your format cache is big, each of those operations can be slower than if the cache is small, and if you're blindly applying those instructions on a 100000x8 data set, you better have some time on your hands.
Of course I'm not implying anyone should ever do that many operations on any of these controls, again this problem arose from using the program for something outside of it's original design. The right thing to do in this case is a virtual solution like I posted above.
-
Is a dynamic dispatch involved? Might be that methods at different levels of inheritance have different icons...
-
1
-
-
- Popular Post
- Popular Post
One of my UIs has a problem where it can chug down if you throw too much data at it. The underlying problem is formatting I'm applying to a native LabVIEW multicolumn listbox (MCLB). I'm not aware of any way to get events out of the MCLB when an item is scrolled into view, etc, so the application just blindly applies formatting to the entire list. Not a problem when I wrote the application because the data set was at most bounded to perhaps 1000 rows.
Being in R&D, we're never happy though and my colleagues who use the application started throwing data sets at it that can have something like 100 000 rows. Yeah, the UI bogs down for minutes at that point, even with UI updates being deferred etc. Simply performing hundreds of thousands of operations on the MCLB even with no UI updates takes patience.
Now ideally I'd like to have better support for the native MCLB, but for now I need to work with what I got so I figured I'd kludge together a pseudo virtual MCLB in native G-code. Here's a proof of principle:
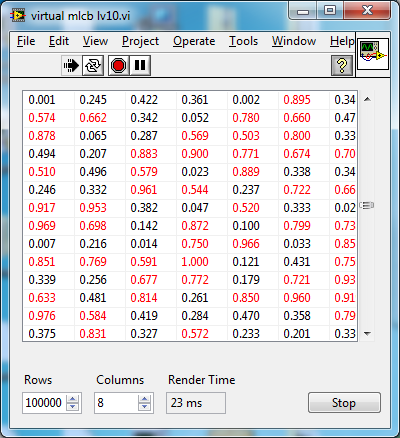
If you run the VI and generate some stupidly large data sets, say 100000x8, you'll see that the render time hopefully stays constant as you scroll through the data, and with a little luck is reasonably fast.
Now if I could make a virtual tree view...
-
7
-
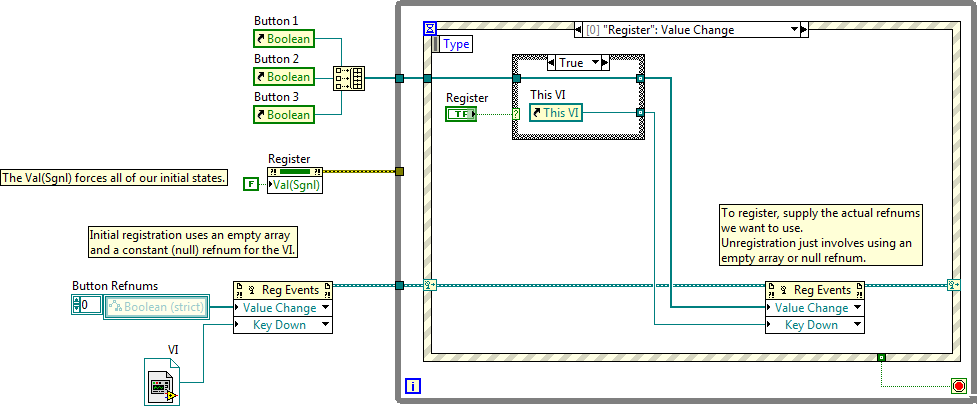
The UI lock is indeed weird.
After you unregister an event registration refnum, I'm not sure if you're supposed to be able to reuse it. I'm under the impression the way one usually handles dynamically registering/unregistering events is by using null refnums for unregistration:
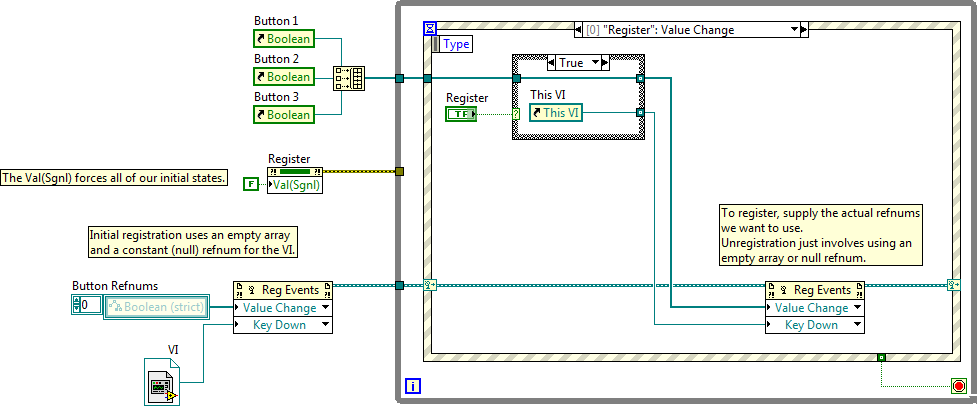
-
2
-
-
Due to recent experiences, I've sworn off using classes in lvlibs. I appreciate what lvlibs bring to the table, and I would like to use them, but from a practical stand point, I don't want to wind up in that situation again.
I have a far bigger project that combines the use of lvlibs and lvclasses, which has also become neigh uneditable, and frankly, I'm afraid of January when that project pushes to the top of my priority list. Last time I tried removing the association with the lvlib, things didn't go so well...
-
As Jarrod confirmed, the attribute operations always generate a copy. I'll refer to an old idea exchange post of mine which I would still love to see implemented though. For reasons I've never gotten around to posting, I doubt that this would be doable with objects, but I expect it should be possible for any static sized piece of data.
It may not be the best way, depending on what you're trying to do, but I've stored an index to an array in a variant instead of the data. This wound up being efficient for me as I needed to store all instances of a piece of data, but only needed to access the latest until end of test.
If you do this, just be sure your array is relatively static. Otherwise be aware any time you hope to gain via associative look-ups can easily be lost by having to operate on the array: reallocation of the entire data space as the array size changes, frameshifting the array when removing elements, etc. Basically you need to weigh the cost of manipulating the entire array when the size of the data set changes versus the cost of copying single elements.
Unless your array barely ever changes, I think you'd be better off with the plain old variant and living with a single copy on each operation. DVRs might help, but keep in mind the synchronization overhead involved with the DVR isn't necessarily free so I wouldn't bother with them unless you can prove to yourself your data copies are costing you.
XML Transformations/Stylesheets
in LabVIEW General
Posted
I wasn't aware LabVIEW actually had xalan...
Anyways .NET looks easy as pie. Seems the winner to me.
Thanks both of you.