

mje
-
Posts
1,068 -
Joined
-
Last visited
-
Days Won
48
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by mje
-
-
I don't know about this one. In most situations my state is maintained separate from the actual dequeued element: state is a calculation based off history, and rarely defined exclusively from a single element. So during a timeout I use the calculated state and the previous element is likely irrelevant.
-
 1
1
-
-
Changes you make to the ini file will not be written until you call Close Config Data.vi.
-
The master/slave pattern is useful for rendering behaviors. Put a non negative timeout on the wait primitive and let it spin independently. All it cares about is the last supplied value, and if it misses values between frames, it doesn't matter.
-
(Sorry guys, had a post where I confused the master-slave pattern with another pattern. Redacted.)
-
-
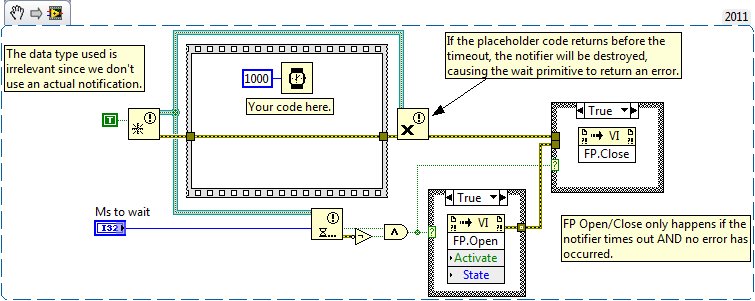
Alright, I'm too tired to code this up, but basically you don't even need to ever send the notification. When the placeholder code returns, just destroy the notifier. Meanwhile the FP will only be opened on the condition of a timeout AND no error returning from the wait primitive. Should satisfy the problem of the dialog flashing if the placeholder executes too fast for whatever reason (error or not). And of course make sure the invoke nodes have no error in terminals wired.
-
Yes, a dirty little secret of mine is still even after 15 years, I find bugs in my code relating to "blindly" wiring error clusters through without thinking about it. Seems many of us are guilty of that in this thread. I find one of the most overlooked things when designing an application framework, no matter how simple the application, is at what level(s) the errors are handled.
I never thought of looking to see if the notifier was destroyed or not to check between a real timeout versus a notifier being destroyed. Alternatively, you could use the error status to signal the boolean (and also force execution order).
Edit: Withdrew a snippet I posted, problem with it.
-
1
-
-
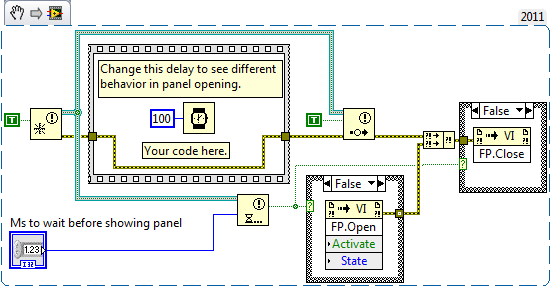
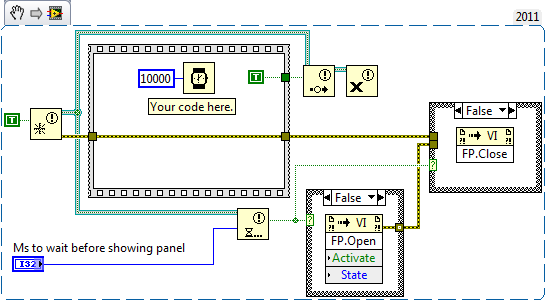
Getting back to the topic at hand, upon closer examination I noticed problems with the original code relating to error propagation.
If whatever code you replace the placeholder with returns an error, the notifier will not signal, meaning when an error occurs the VI will always wait the delay before returning even if the error occurs immediately. Consider wiring either the notifier refnum or the boolean from the sequence frame to force execution order instead of the error cluster. Similarly you probably always want the FP to be closed, so the error should not propagate to the invoke node:
-
2
-
-
You just wanted to say "poop" multiple times, didn't you?
-
1
-
-
Oh yes, the code indeed works as expected: a value of 55.1 produces the expected output in your code of 165.3. I was only pointing out the existence of the little red coercion dot on the fractional index input. No matter which representation I choose, the value is always apparently coerced. If the coercion is real, I'm not sure what the primitive is expecting for data. Right clicking on the terminal and creating a control/constant still produces a coercion.
-
So does that mean that comms primitives (TCPIP, Serial, Bluetooth etc) are all going to be changed to arrays of U8?
Strings/data....it's symantics. If it's not broke...don't fix it.
I would argue it is broke. Not being able to natively handle some of the more modern encodings at best leaves LabVIEW's string processing capabilities as a quaint relic of its history. Multi-byte encodings such as UTF-8 are becoming very common. I know I've processed plenty of XML "blindly" hoping there are no multi-byte characters in there for my LabVIEW code to mangle...
Strings are not simple byte arrays. In their simplest form, they might be bytes, but still have an encoding attached to them.
I completely agree with making the distinction between arbitrary byte arrays and strings. In the case of communication primitives, I'd say they should be polymorphic, allowing either.
While I don't expect LabVIEW to overhaul it's string capabilties overnight, I do expect it will happen eventually, and a requisite to this would be making sure the distinction between string and byte data is consistent in the existing language.
-
1
-
-
When using the Interpolate 1D Array with an array of integers, I can't seem to keep the index terminal from coercing:
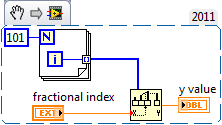
The coercion persists regardless of what floating type is presented. I see this behavior if the array is any integer type.
Is this intended?
-
Oh, that does look promising! Thank you, ned.
-
I'm starting to evaluate my options for an embedded application I'll be writing in a few months that will require an API to be exposed via HTTP. I'm specifically not looking for remote panels, rather XML based responses. That is something does say a GET /daq/data.vi/foo request, which would say return the latest bit of data on the foo channel (think ajax).
I've spent a few hours playing with the G Web Server, and it seems to allow me to do exactly what I want via the internet toolkit when I use the VIs in the CGI palette.
Then there's the (non G) Web Server, that is the one that is configured via the LabVIEW options. Correct me if I'm wrong, but this option seems dedicated to remote panel access?
Any of you have experience exposing an API through HTTP in LabVIEW? I suppose I'm looking to evaluate my options here. As I see it I'm seeing a few options.
- G Web Server: Already have proof of principle down, but not sure if it's portable to an embedded platform, or how light weight it is.
- Web Server: Doesn't seem to be an option since it appears to be centered around remote panels?
- Roll my own HTTP server in native G-code: A basic HTTP server shouldn't be that hard to write given the limited subset of the standard I'd need to use, but I'd also rather not re-invent the wheel.
Any other options?
- G Web Server: Already have proof of principle down, but not sure if it's portable to an embedded platform, or how light weight it is.
-
Occurrences do have a timeout.
The main reason occurrences behave differently than the other sync objects is because occurrence refnums are static. The refnum is created when the VI that contains the Generate Occurence function is loaded, not when it is executed. That means that a VI which is reused, say in a loop, the Generate primitive will return the same occurrence on each invocation. This is often counter-intuitive to those that don't understand the mechanics of how occurrences are created and can lead to some serious bugs due to previous values being in the occurrence.
The fact that they're created on load is also the reason there is no need for a destroy primitive. Memory leaks don't happen because repeated calls to Generate Occurrence in the same VI always return a reference to the same instance.
The behavior is very useful if the primitive behaviors are understood though. They just work completely different from all the other synchronization primitives.
-
I've done this a few ways. The easiest way is to use a graph's built in cursors to display the information when you pin the cursors to a plot (right click a graph, visible items: cursor legend).
Adding a layer of complexity, if the built in display isn't appropriate for your UI, you could still use the cursors but keep the UI hidden, and use the mouse move events to extract the appropriate information via property nodes and display it in your own indicators.
Even more complex, you can roll your own so to speak:
- Have a tooltip VI running in the background which can receive data from the VI that has the graph.
- Use a mouse move event to calculate the nearest point to the cursor. The graph has a method to transform screen coordinates to the coordinate space of the graph (or vice versa) to help with this.
- Pass whatever information you need to your tooltip VI.
- The tooltip VI receives the data and shows itself at the proper location, usually as a floating window.
- When the mouse leaves the graph, don't forget to notify the tooltip VI so it knows to hide itself.
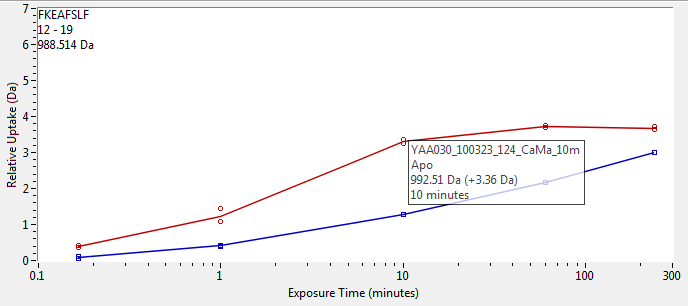
Doing it this way means your tooltip can literally be anything, as the appearance is defined entirely by another VI. Here's an example of a tooltip that appears in an application of mine when you hover over a data point:
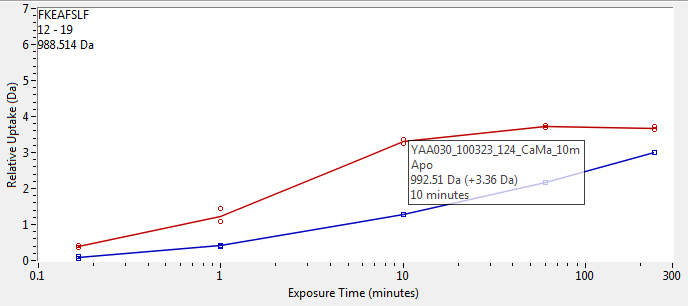
- Have a tooltip VI running in the background which can receive data from the VI that has the graph.
-
Some of the details still escape me though... For example, a trait provides a set of methods that implement a behavior and requires a set of methods the class (or another trait, or perhaps a child class?) needs to implement. (page 7) Can these methods be overridden in child classes? My guess is provided methods cannot be overridden but required methods can. I'd like to play around with a language that implements them and see how they work.
From reading the paper, I believe provided methods can be overridden; in fact they sometimes have to be, when there is a "conflict" between identically names methods provided by multiple traits (section 3.5, page 11).
My understanding is that's where the "glue" comes in. Two traits might both require a method ReadCenter, but it's the class that decides what concrete method actually provides that interface, to the point where either trait's interface could map to a different implementations. If I read correctly, the implementation doesn't even need to be named ReadCenter, it could be anything: when composing a class of a trait, the class defines what methods implement the required methods of that trait.
In my mind picturing function pointers in C++, but in LabVIEW land this would be the same as defining a connector pane for ReadCenter. The job then of the class, is to map which member VI (with the same connector pane) of the composing class implements the interface, but because a class might be a composition of multiple traits, the method need not be named ReadCenter. Note the implementing method might even have been introduced via another trait, but since traits likely won't know about one another, it is still the responsibility of the class to provide that glue and either implicitly or explicitly map out the relationship between implementation and interface.
With regards to overriding implementations which are provided by a trait, don't forget there are also precedence rules, a method defined in the class proper always takes precedence over an implementation defined by the trait (if I recall?).
Aliasing is a related topic that I found interesting, though honestly I find it rather inelegant.
All in, I need to read that paper a second time. There's a lot in there, and it is light on some details, though there are references to check as well.
-
Interesting indeed. I like the idea how you can define both an interface and implementation- not too different from virtual classes- but it is all stateless at the trait level. The paradigm shift would seem to be the "glue" as they call it: how a class essentially becomes a means of connecting the state to the trait(s). Also like how the class becomes focused on state creation (instantiation), whereas the traits become the main means of defining behaviors/interface.
Having not thought about it too much, I do question though if inheritance is even required in a system which allows traits.
-
Yes, thanks Doug!
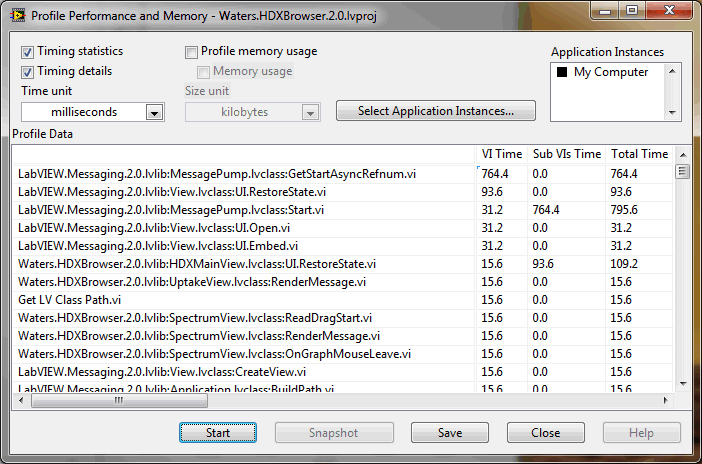
No harm in showing the VI names I suppose, many of them are library VIs I've published here before:
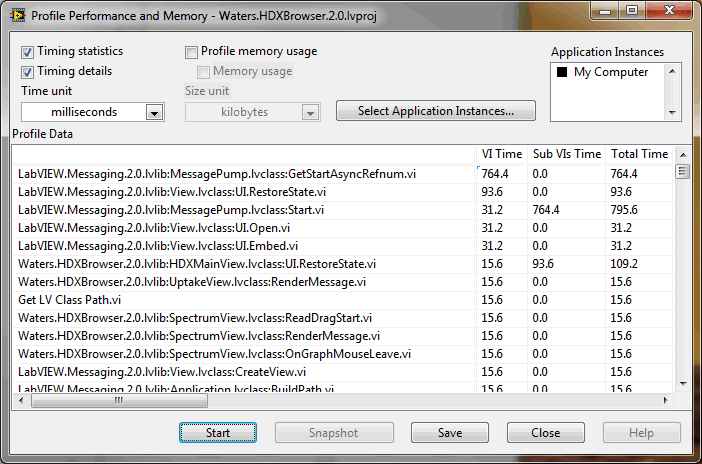
As most of their names imply, the ones with any real VI time fall into one of two categories: either they're involved with launching a new async process; or they involve some aspect of the user interface. So all in, the numbers are exactly as expected!
Good to see a fix is coming, hopefully we won't have to wait too long for it!
-m
-
1
-
-
2011.
-
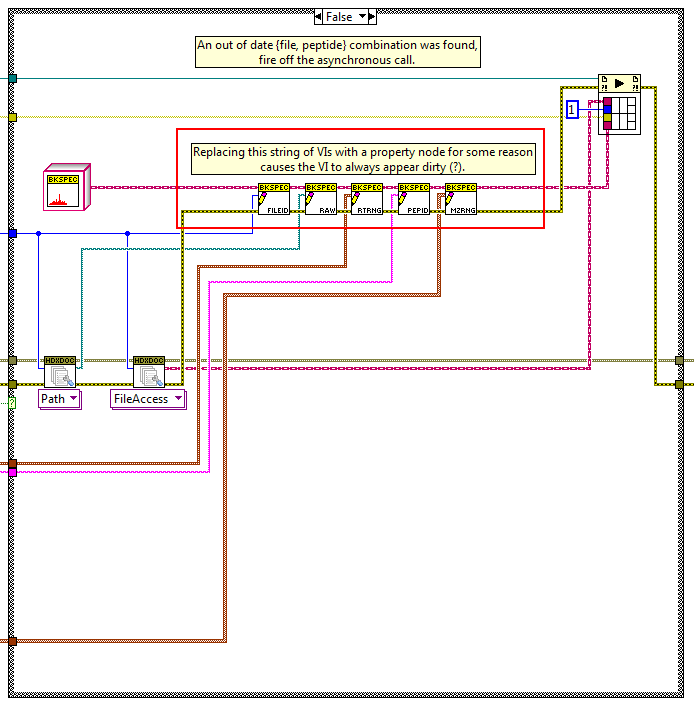
Well this is fun. The relevant section of code:
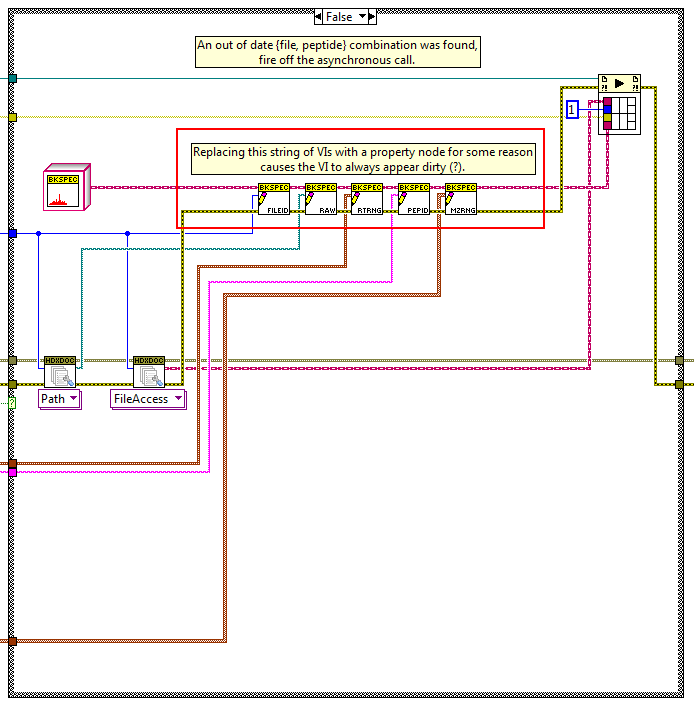
The above code works and doesn't cause the VI to be dirty when loaded. The original code had a property node in place of the string of five accessor methods I highlighted in red. Even now, if I delete the accessor VIs and drop a property node instead, I'll get the dirty dot problem. Even though the two pieces of code should be equivalent according to everything NI has said with respect to classes and property nodes.
Thank you very much for all the clues. The bit about in-placeness clued me in to looking at the subVIs more closely, and eventually I homed in to the property node using some creative sleuthing with the diagram disabled structure.
Fun fact: even having the property node on the diagram in a disabled case causes the dirty dot to appear when the VI is loaded. Weird.
-
1
-
-
So, I have this VI that always has a "dirty dot" on it. The second it's opened, it appears dirty with the little asterisk in the window title bar, and I'm forever being prompted to save changes to it every time I close out my project. Even if I don't open it, only load it by virtue of it being in the project, it becomes dirty and when I close the project, I'm prompted for a save.
I'm told by LabVIEW that "Name or location of VIs in the file system changed", with more details being provided as "The VI's name was changed outside of LabVIEW, or one of its subVIs was found in a different directory." Well thanks for nothing. Not only is that a lie, it's completely unhelpful. The VI in question has only a handful of subVIs,
I've rebuilt the entire VI from scratch being careful to manually drop each subVI directly from the project explorer onto the diagram so as not to accidentally grab the wrong version of something.
I've deleted my compiled object cache, and performed a mass recompile of the entire project hierarchy. Twice.
I've also tried generating an export from SVN, thinking that somehow a VI was being picked up from the cache maintained by SCC, no luck.
All of this and that damned dirty dot just keeps popping up.
Since LabVIEW seems convinced something has moved, it would be really helpful if it actually told me what moved. I've tried to no avail by incrementally blocking smaller and smaller portions of code out with diagram disabled structures to identify the culprit, but the results are at best inconsistent: about the only thing I can reliably do is disable all the code to have the VI become stable.
Any ideas?
-
Interesting, thanks for finding that.
-
Thanks both of you.
Doug, I'll assemble something for you soon. It's a fairly complex application (last count put it over 1800 VIs), so without a little direction I fear you will not get anywhere. I will contact you directly via email as the source code for this application can't be released.
Dequeue Element Timeout State Control
in LabVIEW General
Posted
That's one way of handling scheduled tasks. I've usually opted to instead calculate the timeout on the fly, then execute whatever scheduled task is pending when the timeout occurs.