CharlesB
-
Posts
59 -
Joined
-
Last visited
CharlesB's Achievements
")
Newbie (1/14)
2
Reputation
-
-
-
-
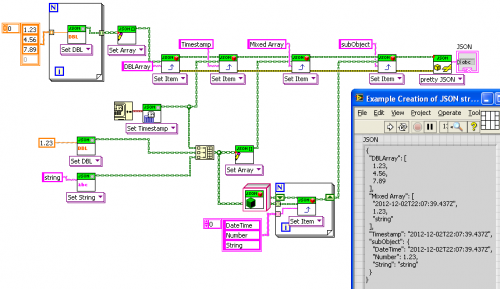
What I do in my implementation is to serialize the class type, and if present when reading it back I instantiate the real class, using LabVIEW's "Get LV Class Default Value By Name". It works neatly in my case. Serializing class type is an option given to the "Data to JSON" VI, so classes that don't have children don't get their type serialized. Serialized class looks like this: { "Timings": { "@type": "ChildTimings", "@value": { "Camera delay": 0, "Exp time": 0.001, "Another field": "3.14159" }, "Name": "Charles" } Attached my version of the package implementing this (don't pay attention to the version number, it was forked from 1.3.x version). Code is in JSON Object.lvclass:Set Class Instance.vi and JSON Object.lvclass:Get as class instance.vi Hope you won't find it ugly :-) lava_lib_json_api-1.4.0.26.vip
-
Here's what I've done for this in my implementation. I had the same need, big configurations with nested objects that needed to be serializable. I created a "JSON serializable" class that has "Data to JSON" and "JSON to data" that take JSON values as arguments. My classes inherit from it and de/serialize their private data by overriding these methods, with the option of outputting class name along with the data. JSON.lvlib is modified to handle these classes on get/set JSON. I used the @notation to output the class name, resulting in this kind of output "Timings": { "@type": "Timings", "@value": { "Exp time": 0.003, "Piezo": { "Modulation shape": "Square", "Nb steps": 4 } } } This is the code for deserializing and serializing:http://imgur.com/a/afaKj The drawback is that I need to modify JSON.lvlib, and I didn't take the time to update my fork to stay inline with the development of JSON library. Also it needs LabVIEW 2013, because of the need of "Get LV Class Default Value By Name". The advantage is that the class name is serialized, and loaded back at deserialization. It allows to save/load child classes of a serializable class, giving more flexibility to the configuration. If someone is interested I can work on updating the fork with last version of JSON.lvlib and publish it
-
Preserving run-time class with cluster of objects
CharlesB replied to CharlesB's topic in Object-Oriented Programming
Generics are maybe an solution to drjdpowell's request, but as for mine the compiler just needs to be a little smarter to guess what type of object is in my cluster. In this case it's just compile-time type determination. The fact that this type of request rises may be a good sign that LabVIEW users are now more mature and at ease with object-oriented programming, and thus more demanding -
Preserving run-time class with cluster of objects
CharlesB replied to CharlesB's topic in Object-Oriented Programming
I was expecting this type of answer... Keeping type for objects in arrays and clusters wouldn't be too hard, I guess! Thanks -
I love how useful is the "Preserve runtime class" node when I wire an object to a more generic subVI, and not having to downcast it after... (first snippet is the subVI, and second is how I use it) But how to make it work with cluster of objects? I tried this in the SubVI: But no success: unbundling after my subVI call gives me the base class, and I have to downcast it. Any thoughts on this problem?

-
Sounds correct, I don't really understand the case in which buffer size is computed, but it may be there for a reason. You don't have to worry about leakage in LabVIEW code, since memory is managed by the runtime.
-
Name: Triple buffer Submitter: CharlesB Submitted: 21 Oct 2014 Category: *Uncertified* LabVIEW Version: 2011 License Type: BSD (Most common) (initial discussion, with other implementations here) In the need for displaying large images at a high performance, I wanted to use triple buffering in my program. This type of acquisition allows to acquire large data in buffers, and have it used without copying images back and forth between producer and consumer. This way consumer thread doesn't wait if a buffer is ready, and producer works at max speed because it never waits or copy any data. If the consumer makes the request when a buffer is ready, it is atomically turned into a "lock" state. If a buffer isn't ready, it waits for it, atomically lock it when it is ready. This class allows to have a producer loop running at its own rate, independently from the consumer. It is useful in the case of a fast producer faster than the consumer, where the consumer doesn't need to process all the data (like a display). How to use Buffers are provided at initialization, through refnums. They can be DVRs, or IMAQ refnums, or any pointer to some memory area. Once initialized, consumer gets the refnums with "get latest or wait". The refnum given is locked and guaranteed to stay uncorrupted from the producer loop. If new data has been produced between two consumer calls, the call doesn't wait for new data, and returns the latest one. If not, it waits for the next data. At each producer iteration, producer starts with a "reserve data", which returns the refnum in which to fill. Once data is ready, it calls "reserved data is ready". These two calls never wait, so producer is always running at a fastest pace. Implementation details A condition variable is shared between producer and consumer. This variable is a cluster holding indexes "locked", "grabbing", and "ready". The condition variable has a mechanism that allows to acquire mutex access to the cluster, and atomically release it and wait. When the variable is signaled by the producer, the mutex is re-acquired by the consumer. This guarantees that the consumer that the variable isn't accessed by producer between end of consumer wait and lock by consumer. Reference for CV implementation: "Implementing Condition Variables with Semaphores ", Andrew D. Birrell, Microsoft Research Click here to download this file
-
How to implement triple buffering
CharlesB replied to CharlesB's topic in Machine Vision and Imaging
No, I pass the pixel pointer to the DLL function, which can than read or write the raw pixels. This is what gives the best performance. For making sure of this, I converted my program to LV2014, replacing my DLL calls with native G array operations and the new ImageToEDVR along with an IPE, performance goes down by 50%! This apparent "global lock" was solved by some DLL functions that were left calling inside UI thread. I have no performance issue with manipulating IMAQ data outside IMAQ functions, so I would say instead that when done correctly, it can solve performance issue without going into Vision runtime licence costs. I concede that it has the drawback of more complexity, as it adds DLL calls, and need to have maintainers that know both LabVIEW and C++. I haven't tested the IMAQ functions for manipulating image pixels, because at design time a few years ago I didn't want to pay for the Vision runtime license on each deployment. But they probably have similar or better performance. As of your benchmark, I'm certainly doing more stuff than just buffer copy, so it's hard to compare. -
How to implement triple buffering
CharlesB replied to CharlesB's topic in Machine Vision and Imaging
Yes, it also works, and the benchmarking gives the same results as two other solutions -
How to implement triple buffering
CharlesB replied to CharlesB's topic in Machine Vision and Imaging
Ooh thanks! I had some processing CLFN that were specified to run in the UI thread! Now producer loop frequency is more independent of display loop. -
How to implement triple buffering
CharlesB replied to CharlesB's topic in Machine Vision and Imaging
I'm not sure to understand how it would help here? Yes, perfectly sure. Buffers are allocated with different names everywhere, and filled in DLL functions, using IMAQ GetImagePixelPtr. I have made some some benchmarks, measuring both consumer and producer frequency, and had the 3 solutions. Display is now faster, now that I have dumped my XControl used to embed IMAQ control, which I believe was causing corruption. Trivial solution: 1-element queue, enqueued by producer. Consumer previews queue, displays, and empty the queue, blocking producer during display 2 queues solution (by bbean) Condition variable (mine) All three solutions have similar performance in all my scenarios, except when I limit consumer loop to a 25 Hz, in this case producer in 1. is also limited at 25 Hz. Trivial solution shows image corruption in some cases. Except this case, I never see producer loop being faster than consumer, they both stay at roughly 80 Hz, while it has some margin: when I hide display window, producer goes up at its max speed (200 Hz in this benchmark). When CPU is doing other things, the rates go down to the same values at the same time, as if both loops were synchronized. This is quite strange, because in both 2. and 3. producer loop rate should be independent from consumer. Consumer really does only display, so there's no reason it would slow down the producer like this... Everything looks like there's a global lock on IMAQ functions? Everything is shared reentrant. Producer is part of an actor, execution system set to "data acquisition" and consumer is in the main VI. -
How to implement triple buffering
CharlesB replied to CharlesB's topic in Machine Vision and Imaging
It may be a bit overkill, but DVR and semaphore are here to protect against race condition. I actually just translated the code shown in the paper from MS research. It's important that the operation "unlock then wait then re-lock" is atomic, so that the producer don't read data in between, and if so you have inconsistent operation... Yes, the 2 queue approach is simpler, and it also works, but it's also interesting to have a G implementation of the condition variable, as this pattern may be helpful in some cases. I agree it's not aligned with the usual paradigm in LabVIEW, but overall it was a good exercise Also I have a small performance gain with the CV version of triple buffer. Maybe you can implement condition variable using fewer synchronization mecanism, I'd have to think about it Thanks, I didn't know about the synchronous display stuff. The producer is actually doing other processing tasks with the frames, and needs to spend as less time as possible on the display, which is secondary compared to the overall acquisition rate, so I need display-related stuff to be wait-free in the producer.