

ShaunR
-
Posts
4,871 -
Joined
-
Days Won
296
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by ShaunR
-
-
Ok, so we were trying to compare apples to oranges. 'nuff said
Nope. It's software. It's comparing apples to apples.

That's not entirely true, but it's not entirely unture either. I think that some new softwares are expected to be buggy, possibly because they haven't gone through alphas or betas, and/or the market has forced an early release on a less-than-mature product. It's also one thing that makes software so awesome - changes (whether they're bug fixes or feature additions) can usually be made with a much faster turn around than hardware.
The expectation of bugs in software is exactly what I was saying about being "trained". There is no excuse for buggy software apart from that not enough time and resources have been spent on eliminating them. That is the reason why there are faster turnarounds in software, because people will accept defective software whereas they will not accept defective hardware.
That's not always the case, but if we're talking about product platforms here (which we're not
 ), then it's a great way to go- especially if you have more than one customer: you can weight feedback on feature requests and make strategic business decisions based on them, which can be super efficient during alpha and beta cycles, as opposed to waiting until full releases.
), then it's a great way to go- especially if you have more than one customer: you can weight feedback on feature requests and make strategic business decisions based on them, which can be super efficient during alpha and beta cycles, as opposed to waiting until full releases.Indeed. However, that can be in parallel with the development cycle where the customers frame of reference is a solid, stable release (rather than a half-arsed attempt at one). If you operate an iterative life-cycle (or Agile as the youngsters call it
) then that feedback is factored in at the appropriate stages. The "Alpha" and "Beta" are not cycles in this case, but stages within the iteration that are prerequisites for release gates. (RFQ, RFP et. al.)Again, apples and oranges. Image an iPhone user who wants an app that allows them to read their email: if you said to them "I've got an app that does 98% of what you want, but 1% of the time it'll take an extra 30 seconds to download attachments, so I'm not going to release it for another 3 years until it's perfect". The iPhone user goes and downloads another app.
Well. If it takes three years to fix something like that, then it's time for a career change! If you know there is a problem, then you can fix it. The problem is that it takes time/money to fix things and the culture that has grown up around software is that if they think they can get away with selling it (and it being accepted); then they will. If it wasn't acceptable they'd just fix it. I've never been an iPhone user (always had androids). However. If the apps are written by any script kiddy with a compiler and given away free, then, basically, you you get what you pay for.
Also, skyscrapers aren't ever perfect - they're good enough. And I'm pretty sure building owners are given tours of their buildings before they're completed
The phrase "Good enough" is exactly what I'm talking about. Good enough to get away with? Sky scrapers aren't perfect, but they are "fit for purpose", "obtain an level of quality", "comply with relevant standards", "fulfill the requirements" and don't fall down when you slam a door
 . The same cannot be said for a lot of software once released, let alone during alpha or beta testing.
. The same cannot be said for a lot of software once released, let alone during alpha or beta testing.As for the type of systems you build, I agree with you - and we make similar-sounding systems too. Such tings are decided at requirements gathering and design phases, and are usually locked down early. That said, we also have a suite of software products we use on these programmes, so it's a balance.
What's the difference? A balance between what? Between quality and less quality? Software is software. The only difference is how much time a company is willing to spend on it. Please don't get me wrong.
 I'm not commenting on your products. Just the general software mentality that, at times, makes me despair.
I'm not commenting on your products. Just the general software mentality that, at times, makes me despair.In summary, as Jeff Plotzke said during his 2010 NIWeek session: "Models can, and should, fit inside other models."
I've no idea what that means

That's an admirable goal, and works extrememly well in some industries. I sometimes find it useful to get feedback from end users during development, because, in the end, we want compliant systems, on time, on budget, that make our clients happy. That last item can be tricky if the first time they see it is the last time they see you
It's not a "goal".It is a "procedure" and the general plan works in all industries from food production to fighter jets. Why should software be any different? The "goal" is, in fact, that the first time they see it IS the last time they see me (with the exception of the restaurant or bar of course). That means the software works and I can move on to the next project.
Anyway, it depends onthe idustry, technology , and client. All I'm trying to say is that deriding alpha and beta programmes completely doesn't make sense to me - every tool has a place.
And I'm saying it doesn't matter what the industry or technology is. It matters very much who the client is and, by extension, what software companies can get away with supplying to the client. Public Alpha and Beta testing programmes (I'll make that discrimination for clarity in comparison with the aforementioned development cycles) are not a "tool" and are peculiar to software and software alone. They exist only to mitigate cost by exploiting free resource.
God help us the day we see the "Beta" kettle.
-
LOL.
I'm curious how people decide whether they are doing alpha or beta testing? I've always considered it alpha testing if there are large chunks of functionality that have not been implemented, UI is unfinished, etc. Beta testing is when the software is mostly (> ~80%) feature complete, UI is mostly in place, etc. I've had other tell me they don't consider the software to be in beta testing until it is feature complete and all you're looking for is bugs. Thoughts?
Alpha and beta testing (for me) is internal only. Alpha testing will be feature complete and given to other programmers/engineers to break it on an informal basis. For beta testing, it will be given to test engineers and quality engineers for qualification (RFQ). Sometimes it will also be given to field engineers for demos or troubleshooting clients equipment. Clients will never see the product until it is versioned and released.
-
I agree that you can't dump it in someone's lap totally unfinished, but I couldn't imagine dumping it my customer's laps without them having an opportunity to tool around with it before its officially released. What you're suggesting might work for systems that have few and very well defined features, but once you scale up even just a little, the possibilities of what your customers might do with it grow quickly. Look at LabVIEW: I'm glad they have betas, because, without infinite resources or infinitie time, they can't possibly imagine to test all of the combinations of awesome things we're going to try to make it do.
Maybe we're comparing apples to oranges, or I'm missing your point. It's a thread hijack anyway, so I'm going to split to t a separate thread.
Well. I deal with automation machines and if it doesn't work there are penalty clauses. The clients are only interested in what day it will go into production and plan infrastructure, production schedules and throughput based on them being 100% operational on day 1. Deficient software is something desktop users have gotten used to and have been trained to expect. Software is the only discipline where it is expected to be crap when new. Imagine if an architect said "here's your new skyscraper, There's bound to be structural defects, but live in it for a year with a hard-hat and we'll fix anything you find".
-
...and the opportunity for your potential customers to help shape the direction of your product by pushing it through use cases you hadn't thought of
How so? They can only put it through use cases if it works. Otherwise they are just trying to find workarounds to get it to work.
Alpha = Doesn't work.
Beta = Still doesn't work.

-
....... and here's my offering using queues for command and events for response. (not QSE I know, but we have talked about it-or maybe that was another thread
 )
) -
Or you could post it to this forum and let others tinker around with it too.
I'm just sayin'...
It'd end up full of classes then-no thanks...lol.
I only release stuff that works and looks clean. I also don't believe in alpha or beta testing (it's just an excuse lazy people/companies use for free resource so they don't have to test it themselves!).
I had the intention of doing something with it (I've been using it for over a year now), It was a weekends "playing" that did the job at the time.However, now I'm engrossed with with the SQLite API (only one platform left.....woohooo!). Too many homers what with that, websockets and dispatcher. They are all far more mature than this and consume a considerable amount of my spare time. I probably won't get much time to look at it this side of Xmas (but you never know).
But come on Daklu. You could knock up something very similar in a day or two yourself with JCarmodys code if you really wanted it that badly
All you need to do is to add a snazzy UI and a database (incidentally, it's not a total coincidence it happens to look very much like a database browser that you may have seen before  ). If you want something now, then JCarmodys is your best bet. Why not tinker with that and help him productionize it? With you and JCarmody on the case; I'm sure it will knock the socks off anything I can produce. Otherwise we'll just have to see what Santa brings.
). If you want something now, then JCarmodys is your best bet. Why not tinker with that and help him productionize it? With you and JCarmody on the case; I'm sure it will knock the socks off anything I can produce. Otherwise we'll just have to see what Santa brings.Meanwhile. Back at the ranch............
-
[As an aside, while the QSM Hector's unpredictability is what trips people up, it also intrigues me a bit. I have this nagging idea in the back of my head to try using it for some sort of machine learning applications.]
Well. I'm not sure that is such a good idea (I'm gonna call a hector a QSE from now on. People will think I've just mistyped it so it may permeate
). But it is suited to a parser so I could quite easily see a good use for it as an emulator. -
Another thing you can do is learn what real state machines are--not the horribly and incorrectly named Queued State Machine. (Or as I sometimes call it... Hector.) Try modelling your application's behavior as a state machine on paper before writing any code. If you can create the correct behavior on paper writing the code is easy.
Indeed. It is a Queue [based] Sequence Engine. Although I am also guilty of calling it a QSM.
-
If the above example is taken strictly as you explained, then yes, you are correct. However, if lets say user changes the target setpoint 2 or 3 times continuously, than "Dwell.vi" would continuously be executed as well.
The user cannot change anything at all after the vi is started so it will always execute as expected and the dwell times will always be as they are in the array..
Placing the functions of the three vi's in separate case structures (or the vi's itself), using the "QSM THINGY" I would have thought you have more control over what-is-executed-when. In this case you have control over the "Dwell" case where you wouldn't execute that until the user is finished with the target sp (this may not be the best example to show what I'm thinking).
So. You slap my 3 vis into cases. What do you do about getting them to execute in the right order with the right parameters?
My experience with labview comes from hardware control and operations. I tend to find it easier if I leave the basic operations in the front level and refer to them through macros along the way (as shown on my previous attachment).
You mean turn a graphical language into a scripting language? Maybe Luaview is of interest:)
Heh... nice..
You may laugh. But that is exactly what you will find is some of the examples using the JKI QSM on this very board.
The answer I was looking for is you cannot stop it (without pressing the Labview stop button) once it has started. But that is the only problem.
The point I was trying to make is why break up ordered and sequential things that can be defined by the language so that you have to write a load of code to do the same thing and make it difficult to understand and (as Daklu has pointed out) introduce race bugs?. Admittedly it was a contrived example, but it was to make the point. Daklu an I disagree on many things, but we agree on form over function where the choice is arbitrary.
Have you seen the event structure state machine?
-
Hi Daklu.
In your latest example, while your message handler implementation makes it easier to understand and cleaner, I somehow feel like its use is limited.
If for instance more than one mechanism/object/device needs to read the reactor temperature "ReadReactorTemp", with macros you can just fire the initial sequence of executions (where each device or mechanism would have their own sequences) where one of those sequences would include "ReadReactorTemp" and then go on to do other things. This however cannot be done that easy using your "atomic message handler" since using SubVIs you're mixing more functions into a single case. Whereas if each case structure would have a single function, you can then refer and call them or mix and match them however you want with macros.
The point (I think) that Daklu is trying to make is that some operation ARE atomic and, additionally, sequential - which is implied by the relegation of multiple functions to a single sub-vi.
Let's consider a very simple example of an environmental chamber where you want to step it through a temperature profile. You have to set the temperature you want, wait for the chamber to get to a obtain that temperature, wait for it to settle, then save the actual temperature to a file.And you continue like this until you have covered your profile. So we have atomic and sequential operations.
Here is the code.
Now do this with the QSM thingy without just copying my VIs into cases (don't forget to have cases for open, write and close file as well - after all. It is more "flexible"
)What is the problem with my code that the QSM thingy solves?
-
Dependency Management: For larger applications this is the most important requirement few people ever consider.
Why may I ask?
Outside of dynamically loaded VI's, I've never had to consider this. Surely this is a deployment aspect rather than a design consideration.
-
Can you explain what you mean by leftover messages?
Where the dequeue loop stops before the message has been processed so that when it starts up again, it processes the stale message.
So since any given component can receive both control messages and response messages, you implement two message receiving loops in them? Or do you use the "event structure inside the timeout case" technique?
Sometimes 3 (if it uses TCPIP) depending on what you call a "message receive" loop.
There is only 1 "receive" loop (i.e. that dequeues messages and acts upon them), but there maybe an event handler (UIs tend to have these by default) and/or a TCPIP handler. Both of these "receive" incoming messages via their respective channels and place them on the receive queue proper. So there are 3 ways that a message may get to be processed in the most complicated case.
1. By placing a message directly on the receive queue (normally only the sequencer will do this).
2. By sending the message to the TCPIP handler (which then places it on the receive queue)
3. By sending the message as an event (which then places it on the receive queue).
Although all modules can have all three. Usually No.3 is only used for monitoring purposes if there is no UI (since a UI is event driven-it's there already). It is much more common in non-ui subsystems to have no.s 1 and 2 except for, say, an error handler which (will be 1&3).
Since the "receive loops" for TCPIP and events are little more than forwarders (the intention being for within the subsystem only), this means they can be dropped into pretty much any subsytem that doesn't have a UI (well. the TCPIP one can be dropped into anything).
-
And how do I regain membership?
Come up with a way to force LabVIEW to be able to override a class method with a VI that has a different connector pane
-
Perhaps he means an autosterogram
-
Another thing I don't like is using user events for the primary communication transport between loops. Events are... quirky. Every so often a thread springs up with somebody having a weird issue with events not behaving how they expect.
I'm not a fan of the JKI thingy either, but I would argue that classes are far more prone to this than events (or anything else for that matter).
The topology I've now adopted for inter-process comms is a queue for the control, and events for response. This gives a Many-To-One for control (great for controlling via UI and TCPIP) and a One-to-Many for the response. A queue for the response has inherent problems with leftover messages and difficulties with permeating the messages to other processes. However, with Events you can easily add monitors to the response and dynamically register other subsytems to the messages (errors for example).
-
Put me down as another member who would love to see this tool.
You are welcome to do as you please, but why even post an image of this tool, if you are unable, or unwilling to share it?
Because, whilst it is OK for me to use as I know how to get around its foibles, it needs quite a bit of work to make it "prime-time". But the main part (the scan engine) is not dissimilar to JCarmodys. To get something similar, you could just spend a day or so writing it yourself since JCarmody has done most of the work for you
 .
. -
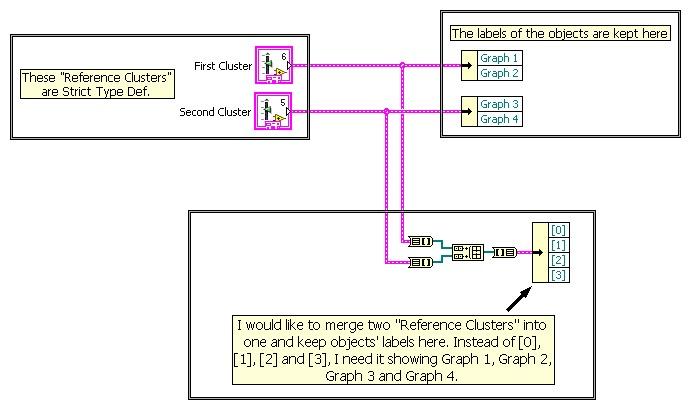
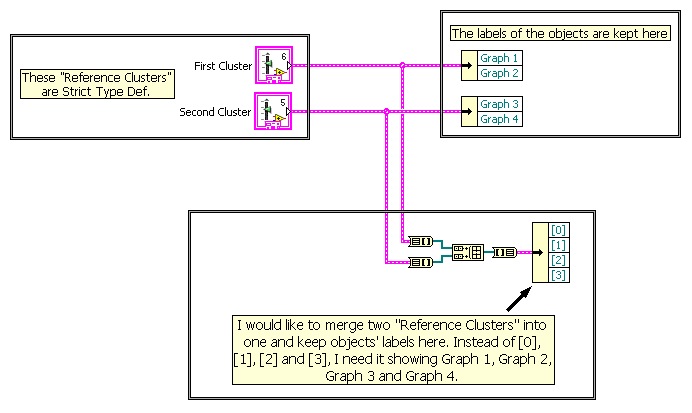
Hello,
I have two reference clusters that are strict type def. and I need to merge them into one but keeping the Labels of the objects. This is just an example because I have a larger code with several objects and I need to merge references clusters into one, since many SubVIs have unbundle by name functions already setted. It is a long story. LOL
I don't need to have it happening on run time, it can be done before allowing me to create one single reference cluster that I will feed to my unbundle functions into the SubVIs.
Find below a picture showing what I want to achieve.
Thanks.
Dan07
Don't build an array. Build a cluster.
-
 2
2
-
-
Yup, and I can get that where?
Right click. Save As
-
By reading the manual and trying it out. At least until you can come up with a more specific question.
Lol.
-
Is there any reason you cannot use the TARGET_BITNESS of a conditional disable structure?
-
"Can you think of anything that would be good to include in this?" Well if you don't mind me addressing the question you asked 3+ years ago, I don't have a need for anything like Requirements Gateway, but I have often wished for a tool I could use to review all the developer notes I've dropped on block diagrams. I'll typically use braces around a keyword, like {ToDo}, {Refactor}, {Magic Number}, or {Fugly Hack}, then fill in the rest of the note with an explanation. The problem is I never remember what keywords I used and hitting Ctl-G until I find the note I'm looking for is a pain. I realize it's not quite within the scope of what you're doing... Would you object to me poking around and possibly forking your code?
You want one of these then
-
Thanks for the clarification. I guess what I'm getting it is for, say, the add method in the base class TList, to make it generic and act similar to an "array of variants" like you suggest, do you just make the input a "LabVIEW object" so it can accept any class you wire to it? If I'm still off, would you mind posting a small example with just one method so I can hopefully understand correctly.
Edit: I'm basically trying to avoid overriding add and delete etc if I don't have to because the base classes implementation will be fine. But, you can't put a TList in its own private data. I keep trying to relate to c++ templates, but with those you can specify the type, and I don't quite see how to do that here. I'm banging my head trying to get this haha. A quick example would probably be the fastest way to clear this up for me, just knowing the way I learn.
Yup. This is where I was talking about type checking which has to be done in the child.
-
1
-
-
Thanks James. We actually have something like this internally, and I agree it's a really nice way to do configuration. I also agree X Controls can be a huge pain and I have battled with them on multiple occasions. Somehow they always end up working, but are often messier than I'd like. Maybe I will convert it so the information is dumped out into classes, rather than csv files or super clusters.
With regards to what Shaun said, would there be a TTestItem class that held an array of test items in its private data? Or would it be something different? If this is how it would be configured, excuse my ignorance but I am a bit confused how TList would handle all the adding and removing of items in a the private data of a child class? It seems I would have to provide a protected accessor method to get the array of items for every child class I make, so that no matter the items I use the TList may call the accessor, get the array of private data, and manipulate it. Is this correct, or am I overlooking something?
Well. TTestItem would contain your test info (upper limit, lower limit, measurement etc). If you think about it. What you are asking for is, in fact, a TList of TTestItem. You could, for example, create a TTestItems (note the plural) which would inherit from TList and this could be fed into TTests (which would also inherit from TList). So you would end up with a List, of a List of Testitems. This is how it would work in any other language and it sort of works in LabVIEW
The point is. TList doesn't care what is in the list. It just provides the methods to manipulate a "List". The purists would (as I am describing) do all the inheritance then override where necessary in each child class (like with GetItemByName). I'm lazy though (and don't want hundreds of VIs). I just create TLists instances and add objects to them just as if it was an array of variants.That is the point where I stop using LVPOOP and use classic LabVIEW since all I'm interested in is using it instead of an Action Engine.
-
You can do as Shaun suggested, and instead of passing an array of objects into the Listbox class pass a Map (or Dictionary, or TListItem...) object.
I think you misunderstood. You don't pass an array of objects into the the List (although you could with a TList.Init). The List IS an array of objects and you add the item using the "AddItem" method. So it is already exactly as you describe.
Why do people alpha or beta test?
in LabVIEW General
Posted
Well. "Agile development" is more of a state of mind than a process. In the same respect as TQM, it encompasses many "methods". However. Lets not get bogged down on semantics. I stated I use an iterative method which, simply put, consists of short cycles of requirements, development, test and release-to-quality which runs in parallel with another another iterative cycle (verification, test, release-to-customer/production). There's more to it than that. But that's the meat of it. The release to customer/production are phased releases so whilst all planned features are fully functional and tested. They are not the entire feature set. I will also add that "release-to-customer/production" doesn't necessarily mean that he gets the code. Only that it is available to inspect/test/review at those milestones if they so choose.
With this in mind. When I talk about alpha and beta testing. They are the two "tests" in each of these iterative processes. So the customer (who may or may not be internal e.g. another department) gets every opportunity to provide feedback throughout the lifecycle. Just at points where we know it works. We don't rely on them to find bugs for us.
Feedback from customers is that they are very happy with the process. The .release-to-customer/production appear on their waterfall charts (they love M$ project ) as milestones so they can easily track progress and have defined visit dates when either we go to them or they come to us. They also have clearly defined and demonstrable features for those dates.
) as milestones so they can easily track progress and have defined visit dates when either we go to them or they come to us. They also have clearly defined and demonstrable features for those dates.
With this analogy. The alpha would be a PSU on a breadboard and the beta the first batch PCB that had been soldered a hundred times with no chassis. That's what prototypes in the real world are and that's exactly the same for software. The first production run would be where a customer might get a play.
That's what prototypes in the real world are and that's exactly the same for software. The first production run would be where a customer might get a play.
More semantics. When a customer asks you "what can you make for me" he is asking for product.
I think actually we agree. I don't propose to just drop it in their lap 6 months after they asked for it. Just that when the job is done. It is done to the extent that he doesn't need to come back to me. Doesn't need to phone, send emails, texts or carrier pigeons except to offer me another project because the last one went so well.
Just don't put water in it or you may find it an electrifying experience
Not always written. A lot of the time it is just meetings and I have to write the requirements then get them to agree to them. Amazing some of the u-turns people make when they see what they've asked for in black and white. Or, more specifically, what that glib request will cost them