

ShaunR
-
Posts
4,850 -
Joined
-
Days Won
292
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by ShaunR
-
-
QUOTE (crelf @ May 11 2009, 09:46 PM)
Well, your experience aside I'm not sure I'd have a purely Windows OS controlling anything that could lop of limbs. That said, I don't know your application or system, so I can't speak without ignorance on that.
I'm not sure I'd have a purely Windows OS controlling anything that could lop of limbs. That said, I don't know your application or system, so I can't speak without ignorance on that.Indeed....lol.
We don't rely on it, safety critical aspects are hardware enforced (like E-STOPS which will cut power and air at the supply), Like I said though. Windows is very robust as long as you don't have all the other crap that your IT dept would put on, disable all the unwanted services, don't use active X or .Net and only run your software.
-
QUOTE (Michael Malak @ May 11 2009, 10:08 PM)
http://lavag.org/old_files/monthly_05_2009/post-15232-1242078686.png' target="_blank">
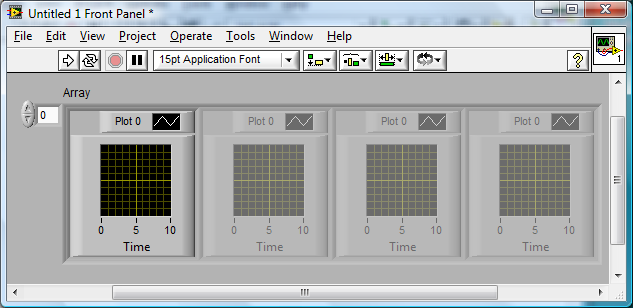
Put your graph into a cluster. Then put the cluster into an array.
-
QUOTE (crelf @ May 11 2009, 07:25 PM)
QUOTE (crelf @ May 11 2009, 07:25 PM)
If the user ignored a "improper shutdown, hard disk has errors, run scandisk" message and your software faults due to that, is that your fault too?Yes. The operators function is solely to load/unload the machine with parts, start the machine in the morning and stop the machine at the end of the shift. No more is expected. If an error is detected in the software, it sms's us with the error and we contact the customer to ensure that preventative action can take place on the next shift changeover.
QUOTE (crelf @ May 11 2009, 07:25 PM)
I'm not saying that you can't plan for these things, but you have to, well, plan for these things. If you know that you need to activate Windows in 30 days or it'll bomb out, then you activate Windows within 30 days so it's okay. You need to gain and apply that same level of product knowledge to all the components you apply to the system - including anything from NI or any other manufacturer. That said, if a user ignored an error for a month (whether that be from an activation issue or a hard fault) and then expected me to fix it immediately once it bombed out, I'd be having a stern talk to them.errrrm. I didn't think it was in question that the OP (or myself) hadn't originally activated Labview. He was talking about the fact he had activated it and after an update Labview required re-activation.
We have an OEM license for windows so activation isn't an issue (if we decide to use windows that is, we also use linux so activation would be irrelevant). Any (and I mean ANY with a capital E) errors must stop the machine and turn it into a paperweight, otherwise people can lose limbs. We have no issues with windows (it's remarkably stable, if you don't load it up with active X or usual rubbish you find on a desktop PC) and we have had only 2 windows failures in 4 years both due to malicious intent. Windows has never suddenly popped-up that it requires re-activation. Or refused to work because of licensing. However, as I pointed out, we have had 2 instances as of this year so far of Labview requiring re-activation.
-
a description of your problems would be helpfull. Perhaps some pictures of the code you have already?
-
QUOTE (rolfk @ May 10 2009, 10:59 AM)
Well, you do not get that error before you try to read PAST the end of the file. As such it is not really a pain in the ######. Reading up to and including the last Byte does not give this error at least here for me.Rolf Kalbermatter
It means you can't just "Read X Chars" until >= "file size" without getting an error. The choice is you either monitor the chunks in relation to the file size and at "file size -Read X Chars" change the "Read X Chars" accordingly, or ignore the error only on the last iteration. If you have another way, I'd be interested. But I liked the old way where you didn't have to do any of that.
-
While you can choose to wrap every function into class methods, that is not usually an abstraction method that works well. What you should do is consider what things you tend to do over and over again and create abstractions for those items.
Agreed. There are certain people,however, I know who would disagree (purists who prescribe to the infinite decomposition approach). My problem is that complex function is what I do over and over again (measure pk-pk waveform, rise time etc, etc) but the hardware is always changing. Not only in the devices that are used to acheive the result, but in the number of different devices (might require just a spectrum analyser on one project, but a motor, a spectrum analyser and digital IO on on another).
For example, let's say you want to create a DMM class that supports Agilent and NI DMMs in your application. Both of these DMMs have completely different drivers required for configuring a voltage measurement, but essentially, they both perform the same operations. You can create a DMM.Configure Measurement method with an Agilent (Agilent.Configure Measurement) and NI (NI.Configure Measurement) implementation (and Simulator, and future hardware you haven't yet purchased, etc). What's nice is that you separate your application logic from your instrument specific drivers that 'implement' that logic.This is what object-orientation is all about -- irrespective of Daklu's 'Extraction Architecture'.
This I get. And for something like the "message pump", which has a pre-determined superset base of immutable functions is perfect. But for hardware it seems very hard to justify the overhead when drivers are supplied by the manufacturer (and can be used directly), "to make it fit". Yes the Agilent has a "Voltmeter" function, but it also has the maths functions which the others don't have so that needs to be added. Also. Just because I have abstracted the Voltmeter" function doesn't mean I can plug-in any old voltmeter without writing a lot of code to support it. If it added (lets say) a frequency measurement. Then my application would need to be modified also anyway.
Daklu's architecture is trying to go one step further -- so that if you have other instruments that have overlapping functionality, you can implement an interface (exterface) that both of the instrument classes would implement (feel free to correct me if I'm wrong). I'm not sure how succesful his implementation is, I briefly looked at it but did not look long enough to fully understand it.I get this too, And don't want to turn this thread in to OOP vs traditional, that's not fair on Daklu.
I added an exterface for the Agilent 34401 to illustrate how I would implement it using that particular IVoltmeter interface definition. Check the readme for notes on it. Remember that interfaces definitions are determined on the project level--I don't anticipate them being distributed as part of reusable code modules. I designed the IVoltmeter interface based on the needs of my fictional top-level application. Your top-level application may require a different interface definition. Also, I don't think there is any value in implementing the exterface unless you know you'll be swapping out the 34401 with different instruments in this application.Let me know if you have any more questions.
The value I see in your interface approach is that it seems to make more of the code re-usable across projects, intended or otherwise
 The interface definition needs to be a superset of the project definitions, but that is easy for me since the higher functions are repetitive from project to project (as I explained to Omar). The intermediary "translation" could work well for me but the prohibitive aspect is still the overhead of writing driver wrappers which prevents me from taking advantage.
The interface definition needs to be a superset of the project definitions, but that is easy for me since the higher functions are repetitive from project to project (as I explained to Omar). The intermediary "translation" could work well for me but the prohibitive aspect is still the overhead of writing driver wrappers which prevents me from taking advantage.I have one question though. Why do you have to "Link" to a device? Presumably you would have to know that the device driver is resident before hand for this. Can it not be transparent? Devices are (generally) denoted by addresses on the same bus (e.g RS485) or their interface or both. Can the "Exterface" not detect whether an instance already exists and attach to it, or create it if it doesn't?
Also, where do I download the example with the Agilent included (I tried from the original post but it is the same as before)
<p>
-
QUOTE (Daklu @ May 9 2009, 06:20 PM)
The JKI vis are part of JKI's VI Tester toolkit. You can download it from http://forums.jkisoft.com/index.php?showtopic=985' rel='nofollow' target="_blank">here. Use VIPM to install it. Or you could just remove them from the project... you don't need them for the example.I like the abstraction (I always like the abstraction....lol). And I see where your going with this and like it (in principle). But the main issue for me (and is one big reason I don't use classes) is that we are still not addressing the big issue, which is the drivers.
My applications are hardware heavy and include motors, measurement devices (not necessarily standardized DVM's and could be RS485/422, IP. analogue etc), air valves and proprietary hardware....well you get the picture. The hardware I use also tends to change from project to project. And (from what I can tell) to use the class abstraction, I need to wrap every function that is already supplied by the manufacturer just so I can use it for that project. Take the Agilent 34401 example in the examples directory for instance. If I want to use that in your Architecture, do I have to wrap every function in a class to use it rather than just plonk the pre-supplied vi's into my app which is pretty much job done? The drivers tend to use a seemingly class oriented structure (private and public functions etc), but there just doesn't seem any way of reconciling that with classes (perhaps we are just missing an import or conversion function or perhaps it exists but I haven't come across it).
I know you have shown some example instruments, which strikes me as fine as long as you are developing your own drivers. But could you show me how to integrate the Agilent example into your architecture so I can see how to incorporate existing drivers? After that hurdle is crossed, I can see great benefits from your architecture.
-
I read you document and (on the first) pass it all made sense. And I have downloaded the example, but I'm missing a load of JKI vi's (presumably in the Open G toolkit somewhere). I'm looking for them now.
Just thought I'd say "something" since your eager for comments
Just a little patience. Not everyone is in your time-zone and it is the weekend after all. -
QUOTE (Ton @ May 9 2009, 03:06 PM)
Why should this be a bad thing?If you create a good reusable VI for such a specific action I have no reason why this is a bad technique.
If it only is a bad thing if the only thing contained inside the subVI is a property method.
Ton
Personal preference.
For me. I like to see controls/indicators and their associated property nodes at the same level so I can see whats going on and apply probes without delving into sub-vi's. I had one bug in someone elses application that I needed to fix where on certain occasions a particular control would change its decimal places and others their colour when they shouldn't. The culprit was 5 levels down the hierarchy from the vi's affected and was a property node that changed the DP (amongst other things) dependent on a limit test supplied from another parts of the code (they didn't include the upper limit).
-
QUOTE (postformac @ May 9 2009, 01:24 PM)
Thanks for the reply, I have never seen that before, is that a "register for events" box? I'm not sure what I would need to do with it to have it affect a control, do I need to somehow connect it to the two controls?Oh ok, its a property node, I found it and got it to work thanks.
Is it possible to put that function inside a sub-VI and still have it affect the controls on the front panel of my main VI?
It is if you pass the refnum to the sub vi. If you just select the property node and select "Create Subvi" from the Edit menu you will see what I mean.
I don't consider it as good coding practice since it hides what you are doing. I would prefer to see a vi that returns the new values to the property node in the same vi as the control appears.
-
QUOTE (Yair @ May 7 2009, 05:52 PM)
References for queues and notifiers are NOT created automatically. You have to explicitly request them. Even then, LV will clean them up automatically if the queue goes out of scope. LV actually got better in recent versions in dealing with references which are created automatically (like control references), so that you don't have to close them.Lets hope it goes out of scope before you run out of memory then.
QUOTE (Yair @ May 7 2009, 05:52 PM)
In any case, no one is forcing you to use these (or even a new version ofLV). You can go back to an old version, but I still don't see why you say that you have to worry about memory, etc. in the newer versions.Tetchy
-
-
QUOTE (crelf @ May 8 2009, 07:25 PM)
Are you sure there wasn't a nag warning screen that the operators just ignored for 30 days until it locked?That's kind of irrelevant.
A customer will blame you (the supplier) not NI for stopping production by a fault in your software. Generally you will get a phone call and they will demand you come on-site to fix it. At best, it costs you (as in your company) 1 engineer on a field trip. But we also have a suppliers that we guarantee minimum down time and incur penalties for lost production. So far this year, we have had 2 occurrences similar to this, luckily not with a supplier we guarantee, but it still cost an engineer a day off each time from projects he should have been on (and car rental, etc).
We have been using Labview and Labwindows for donkeys years, But there have been murmurs recently from the upper echelons in our company, that Labview is "too risky" and although it may be better in the short term because of the short development cycle, in the long term it may cost too much especially as the sales guys have just gone and sold 2 more guaranteed down-time contracts. In the current climate we have loads of c++ programmers looking for projects and the "powers that be" are looking for excuses to utilize the spare resource. I'm fighting like hell at the moment to get the SSP paid this month. And this sort of thing isn't helping me fight my corner.
-
Such a simple request yet not as trivial as it first seems.
Nevilles idea will most certainly work if you trust whoever is drawing the triangles. Hopefully you can go with that. But if you want a programmatic method, more complicated, but less demanding on the user you might try the following.....
1. "Threshold" the image (I'm looking at your blue icons) to get it in black and white.
3. "Fill holes" so that the center part of your triangle is fully blocked (i.e. you have a solid triangle). This is your major mask.
4. Scale your mask down by a factor (say 5%). And invert. This is your minor mask.
5. Combine both masks.
6. Apply the mask to your original image.
You should now just have the white triangle without drawing anything.
-
Yes. The callbacks were also saved in 8.6.1.
I've attempted to save back to 8.0 and took them out of the LLB. Hopefully converted them all, but labview was very insistant on saving them in its current version.
Try these anyway and let me know.
-
This may help (Hint: Polygons)
-
Everything you need is in
\examples\instrsmplserl.llb\Advanced Serial Write and Read.vi
-
QUOTE (Aristos Queue @ May 5 2009, 12:06 AM)
When it needs a copy, it makes a copy. When it does not it does not. An easy example -- if you unbundle data from one object and bundle it into another object, clearly a copy is made along the way. If you unbundle using the Inplace Element Structure, modify the value and then put the value right back into the object using the bundle node on the other side of the structure, no copy is made.Thats more like it does unless you tell it not too. But I can see where you are coming from.
I was more talking about if I called method A and passed that data to method B and then on to C. Do I now have 3 copies of that data just because I invoked those methods (and labview has loaded but not released the VI's)?. Or is it just pointer arithmetic (as it would be in other languages ) and there is only 1 data structure and only a pointer is copied?
QUOTE
he workaround I mentionned is indeed the use of the vi request deallocation which just seems wrong to me for such simple task in an environment that handles memory automatically.This is one of the aspects I really don't like about the "new" labview (far more I do like though). One of the reasons Labview was much faster in developing applications was because (unlike other languages) you didn't have to worry about memory management. As such, you could get on and code for function and didn't necessarily need an in-depth knowledge of how Labview operated under the hood. There used to be no such thing as a memory leak in Labview applications! Now you have to really make sure you close all references and are aware of when references are automatically created (like in queues, notifiers etc). It's good news for C++ converts because they like that sort of nitty gritty. But for new recruits and programming lamen (which was really where Labview made its ground) the learning curve is getting steeper and development times are getting longer.
-
It's a bit like the Error thrown on end of file in file functions. Technically correct, , but counter-intuitive and a pain in the proverbial.
-
-
QUOTE (sachsm @ May 4 2009, 10:04 PM)
Ta very muchly. But I was more interested in how it works.
-
So does invoking a property or method cause Labview to copy the data in an object? Or is it all pointer arithmatic.
-
QUOTE (sachsm @ May 4 2009, 02:53 PM)
Yes, all the methods mentioned do indeed work with cRIO targets. In my system I have 2 9074 targets each with 9144 extension chassis. I am using the scan engine IO Variables which I can read programaticallyusing Data Socket (DS) and then filter and scale then transfer to my version of the Current Value Table (Fancy shift register based storage) and from there the data is written to a proper NSV library which has a binding to a 'mirror' library on the windows side. From there I cannot via the DSC toolkit to my citadel database.
Is there a write up somewhere on the "mirror" library approach?
-
QUOTE (Jarimatti Valkonen @ May 4 2009, 08:33 AM)
Hey! Why didn't I think of this before? Looks very nice and simple.I'm actually considering using this or similar approach for my next UI. In previous project I used the "references inside cluster" approach and it didn't feel like data flow.
 I made a separate VI with the cluster of references as a pass-through value to update the indicator values and some control properties. When the UI needed an update, I simply placed the VI in the block diagram.
I made a separate VI with the cluster of references as a pass-through value to update the indicator values and some control properties. When the UI needed an update, I simply placed the VI in the block diagram.I'm having this strange idea of Model-View-Controller paradigm: keep the state (model) as a single cluster in a shift register and unbundle after every state to indicators (view). Something quite like presented here, but with additional "hidden variables" inside the model cluster.
If your going with a model-view architecture the (very) old method of using a data pool works well.
If you put all your data in a global vi or variable and get your controller to update the global, you can bolt on different UI's for different views.

Load Only FP into memory
in Object-Oriented Programming
Posted
QUOTE (Ton @ May 12 2009, 05:58 PM)
This seems a bit bizarre. My whole application (a couple of thousand vi's) only takes a few seconds to load (via an open ref then run from a splash-loader). Why does it take yours a few minutes to load a vi? Does it have to search for sub-vi's?