ShaunR
-
Posts
5,034 -
Joined
-
Days Won
313
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by ShaunR
-
Well. As this is cropping up again I might as well come clean and admit I've been doing a lot of text programming recently I've been using a package called Codetyphon which is a bundle consisting of a heavily modified Lazarus (Freepascal Visual RAD IDE), shedloads of components/examples and, very importantly, cross-toolchains for a huge range of platforms that you don't have to solve Cicada to install.
-
Use this IP?
-
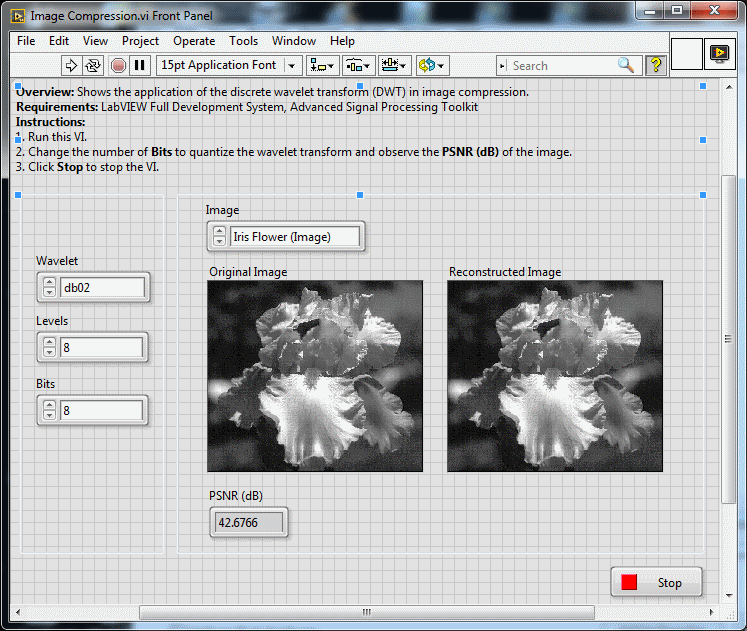
There is an example of image compression (using wavelets) in the Advanced Signal Processing toolkit. As it's a no brainer it wouldn't matter if you are being "misguided".

-
I don't know what you are talking about
-
 Cookies are set by the server. You are just telling the labview client where to store it so whatever you put in there will be overwritten at some point. The data is probably being cached and you are getting the cached values. Try adding the folloing headers. Cache-Control : no-cache, must-revalidate, max-age=0 Pragma : no-cache
Cookies are set by the server. You are just telling the labview client where to store it so whatever you put in there will be overwritten at some point. The data is probably being cached and you are getting the cached values. Try adding the folloing headers. Cache-Control : no-cache, must-revalidate, max-age=0 Pragma : no-cache -
Well. Ignoring my extreme dislike for Java. It should have one huge advantage over LabVIEW in that you should be able create custom controls and, perhaps more importantly, dynamically create them on a FP. If they wrote it in something else I'd be really sold on it and have downloaded it already Nice little find there. I will be keeping my eye closely on it.
-
Preserving cluster version among different LabVIEW versions
ShaunR replied to vivante's topic in LabVIEW General
Let me know if you come across a crystal ball.vi to compliment it that tells us what LabVIEW version the VI reading our data is. -
Preserving cluster version among different LabVIEW versions
ShaunR replied to vivante's topic in LabVIEW General
The official advice is to use some arbitrary primitive hidden in the utilities directory (VariantFlattenExp.vi) that takes a version number . I wonder what potion they were drinking when they came up with that gem? -
I'm a bit confused here. On the one hand you say this ActiveX thing doesn't cause the control to generate a value changed event and then you say you want to detect a value changed event ("last time a control ref had an event fired"). How exactly does this activeX control change the value? If any sort of event is fired, then you can hook that event (that will get you the user changing a control), but I'm struggling to understand what this activeX component is actually doing. Do you have an example?
-
Wire the string "%.;%.5f" (without quotes) to the format terminal. That will change the localisation for the read function to a decimal point regardless of the OS setting (it will truncate the first two entries because they are commas and the rest are decimal point). Read From Spreadsheet File VI doesn't read Excel files, only text files.
-
You maybe right, but several decades ago I think only Alan Turin was into computers. So what are the responsibilities of a Release Manager in your experience?
-
That was Michaels comment. I don't have any preference for small and often or big and rare. That mentality is sales driven. Release when ready and as few as possible is my view but that's a whole other subject on what ready means.
-
-
Hmm. Not sure you quoted the right bit by the context of your response, but I will assume it is the correct quote. No it doesn't. A manager requiring a passionate argument from a subordinate to make a decision is a test of belief and has nothing to do with the software or hardware. It's about one party convincing another about their conviction irrespective of fact. This is why I don't agree with the technique as a valid decision making process.. Sure but would a release manager have prevented it? (assuming they don't have one). I don't think so. From experience, those sort of foobars are usually attributable to a business decision to release in the face of opposition from the technical expertise. May not be the case in that instance but since the knew it was about to happen I bet it was. On many occasions I have been that technical expertise that said "I told you so"
-
Yeah. But a release manager isn't going to address that, is he? The way to stop that is via testing so its a case of "OK, you've found a fix where're the documents?" However, a Principle Engineer, at the very least, is much more likely to error guess or spot implications than a Release Manger. The Release Manager is really just a checklist that you drink coffee with. Here's the risk assessments, here's the test results, here's the bug fixes, now sign. The only thing he or she brings to the table is somewhere to apportion blame. Well. That's the Project Managers job Even is you think in terms of gates (RFQ, RFT, RFP etc) a Release Manager doesn't bring anything more than a signature to say "We really, really think it works now and here are all the documents written by others that say it too". Replace him or her with one of these
-
Yeah. I don't agree with this management technique. It's basically mistrust of your engineers and lack of technical understanding by the manager. It's actually a negotiation tactic which has been ported across to exert control and, in extreme cases, abuse. It's predicated on the requesting engineer having some sort of vested interest in gaining acceptance of an opinion from the superior rather than technical facts It tends to fall to pieces with East Asian engineers that just say OK as superiors' opinions are considered absolute regardless of the outcome.
-
That's what risk assessments are for. Fire the manager and distribute a spreadsheet.
-
That gets covered in
-
Not necessarily. If you wire through and LabVIEW can tell the data won't change, then that "tunnel" may get replaced with a constant by the compiler. If you have dynamic data then shift regsiters can sometimes tell LabVIEW enough about the data to kick in some extra optimisations, but it's not a clear cut as shift regsters good, tunnels bad. I only have an intuitive workflow for using shift regsiteres vs tunnels based on experience, but I'm sure a NI guru can tell you specifically what optimisations can and cannot be enabled with shift regsiters and tunnels. Glad you got it sorted, though.
-
DLL connect in LabView to control Signal Measure Unit
ShaunR replied to grba121's topic in Calling External Code
Don't let their familiars fool you. You can spot them by their lack of certification but insistence that with an object oriented framework you can cure all software ailments and even reanimate dead projects. -
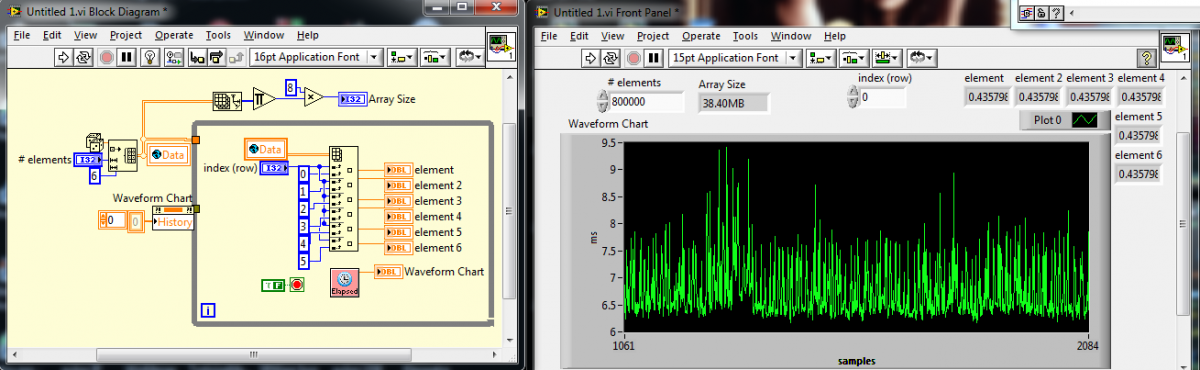
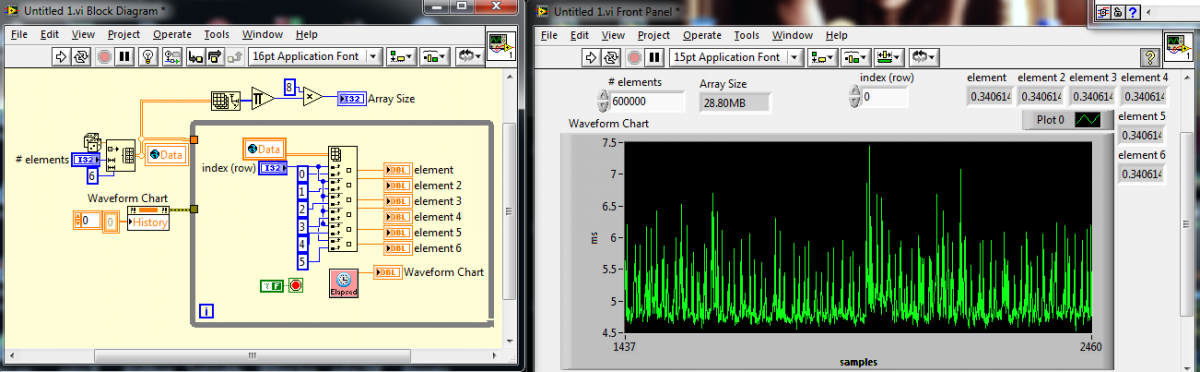
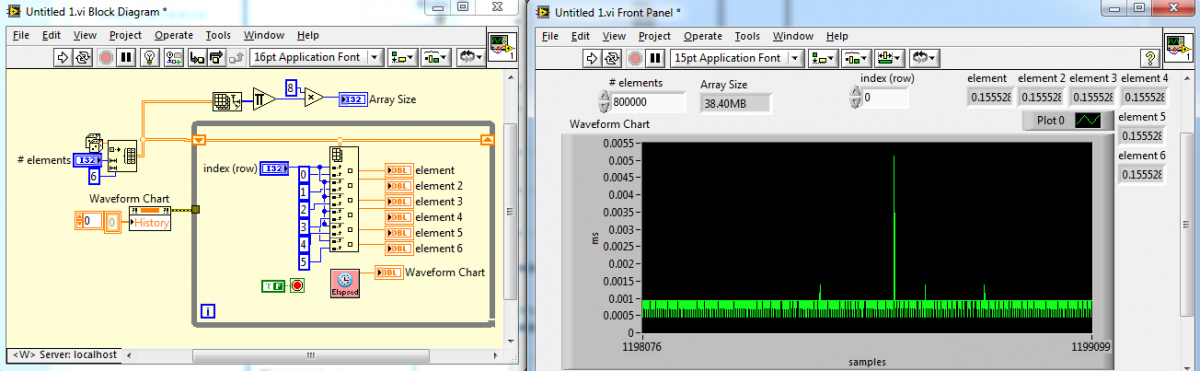
Ok. first off. Windows is not a real time OS so it isn't deterministic. I know that, you know that but your project manager probably doesn't so that was for him. Second. I bet you are so close, that if we can just optimise what we already have a little better, we will be home and dry. Sure. Then in 6 months the spec changes to every 7 ms and the project manager says "you did it before, now do it again - it's only 1ms". So. What is the problem? Ahh. Just poking over the 8 ms in places. Lets see if its what all the girls say that size does matter and bigger is better. Ah yes. No problem with under 8ms. The girls are half wrong and half right. Size does matter but smaller is better. (In fact it is linear. 400,000 will yeild about 3 ms, 200,000 about 1.5 ms etc). Easy answer 1. Reduce the data size in the global. But why so slow? Is it the array disassembling? Is it the reading from the global? Does it need more coffee? Oooh. Microseconds. My spidy sense tells me its the global. Easy answer 2: Don't use a global for big arrays if you're time constrained. That about wraps it up for reading. In the next issue we will cover: Oh my god. It all falls to crap when I write data.
-
Can't build 64 bit apps with 32 bit LabVIEW. We moved away from CLI with windows XP over 14 years ago. Us point and clicky people will drag you secretarial typists with eidetic memories kicking and screaming into the 21 century Begone to Linux