ShaunR
-
Posts
5,033 -
Joined
-
Days Won
313
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by ShaunR
-
J1939. Wow. That's going back a bit. OBDII has been the standard for at least 10 years now (1998?). In response to both of you though.......... Not really. As I think I mentioned. The hardware guys & gals mitigated hardware interfaces with cables (and hubs). There used to be a few teething issues with things like USB compatibility, but they have pretty much disappeared now. If a device doesn't use TCPIP (most offer it as an option, you just need to spec it) Just use one of the many hubs or cables (Ethernet<->USB/RS422/RS485/SERIAL). It s not unusual to use a 20 port USB or 485 hub dangling off of a Ethernet cable, for instance. You can even connect wirelessly if you like, Combine that with standardised string messages (SCPI) and the worse you need for the OCD programmer who cannot abide odd messages is a lookup table from a home grown SCPI hierarchy for the legacy device to whatever ASCII or byte representations the old instruments use. Just copy and paste from their manuals. And testing? Well. That's a whole other area of ease of use. Just throw all the commands into files and squirt them at the devices in whatever order you want with whatever instruments you want. Just one simple VI that loads the file with commands and expected responses. Send them to one device/service/module to do a full factorial message test or to different devices/services/modules to do system tests. Simples. The hardware guys really have solved it, even if small manufacturers are still doing what they did from 20 years ago. I wouldn't be surprised if over 95% of those on the Instrument Drivers Network were SCPI compliant for instance (haven't counted, just saying). PS. We don't care about the instrument side, that's the firmware developers problem
-
 Websockets
Websockets -
The thread seems to have run its course, so I will respond here as we are now way off topic and it shouldn't hurt Hardware abstraction (at least for devices) was solved years ago by hardware engineers. With the proliferation of boxed solutions, SCPI and robust comms converters, the purpose behind most peoples HALs was obsoleted. It reached critical mass about 6 years ago when to not be SCPI compliant became the exception rather than the rule, there was a large choice in comms-to-comms converters and all PCs came with high speed USB and TCPIP. VI drivers were designed to normalise instrument command interfaces. SCPI changed all that and things have moved on but still people write HALs around these (what I consider legacy) drivers instead of directly interfacing the devices to their messaging systems. If you don't use VI drivers, SCPI devices slot straight in to string based messaging systems and open up scripting and performance benefits. Even NI DAQ, Profibus and Modbus devices can be given a thin SCPI translation wrapper in a pinch if you have no control over device selection and laptops become viable test systems. Once you get that far, you suddenly realise that now the devices don't have to be in the same country, let alone hanging off the same computer, as hardware and device specifics have been completely removed from the software. The emphasis then becomes managing and routing the messages, security and scripting test harnesses - very little thought or indeed programming needs to go into how to talk to the hardware. So. The benefit of OOP for hardware abstraction is moot IMO and wasn't solved by OOP or even software, anyway. There seems to be a lot of trumpeting of LVPOOP for solving complex software problems that either don't exist or where created by using LVPOOP in the first place-singletons are a good example of the latter.However, I know what you mean about "vaguely implied benefits" and the evidence is never proffered. There is however evidence that the benefits are just marketing hype. spetep- printable.pdf
-
MCLB movable column separators and header click events.
ShaunR replied to John Lokanis's topic in User Interface
sort or not.vi Measuring column widths seems a bit overkill if you are not auto fitting. A point of reference. A single click to sort is not usually a desired operation especially for sorts that can take some time because it's just too easy to accidentally set it off. A double click to toggle is IMO more desirable. -
MCLB movable column separators and header click events.
ShaunR replied to John Lokanis's topic in User Interface
Handle the resizing in "Mouse Move" rather than mouse down and use the Point to Row Column property node to get whether you are in the header or not. -
If it's here (or on my site), it's alive. It just does everything I need (so no new versions) and has had no bug reports. You won't be able to use compression (windows only) and it is untested on VxWorks because I didn't have that hardware platform back then but everything should be fine. If you run into problems just shout.
-
Actor Framework - Too much coupling?
ShaunR replied to GeorgeG's topic in Object-Oriented Programming
Oooh. You are so close. Won't be long now until you're talking about services instead of actors -
Indeed. LVOOP is a bit like a religion - a dogmatic ideology that everybody seems to still accept, in spite of all the evidence. Well. That's a bit unfair. It's not just LabVIEW. I've been laughing my gonads off about the implementation of "namespaces" that were introduced in PHP 5.3. Another example of taking a perfectly usable language and making it worse to fit the doctrine.
-
No. It's simpler than that. It is state. With State-machines (as the name implies) they control and own system state State is implicit and encapsulated. With a message driven AE, state is external and the interface is basically an API for encapsulation of discrete functions it's a classical action Engine with a message interface rather than typedefs.. I'm sure there are better academic labels for what I am describing because it's nothing new It is a designers choice and pretty subjective so I'm not going to say "do this one". There are advantages and disadvantages over both. When it comes to RT, the crowbar method becomes much more attractive than in desktops as it has better performance generally and tends to have superior jitter since execution can easily be made constant,deterministic and predictable. With any messaging in the acquisition, then you may not be able to guarantee that and jitter will definitely no longer be constant or predictable and you may even lose determinism depending on what you do when you respond to a control message. However, you cannot configure the former easily "online" (whilst it is running). It is a Configure-Start-Acquire-Stop-Configure-Start-Acquire-Stop type of arrangement (offline). 403? You're IP address is probably banned....lol. Been visiting without a user agent? (PM me with your IP and I'll unban it). later........ Nope. You're not banned. Your Uni must be blocking you.
-
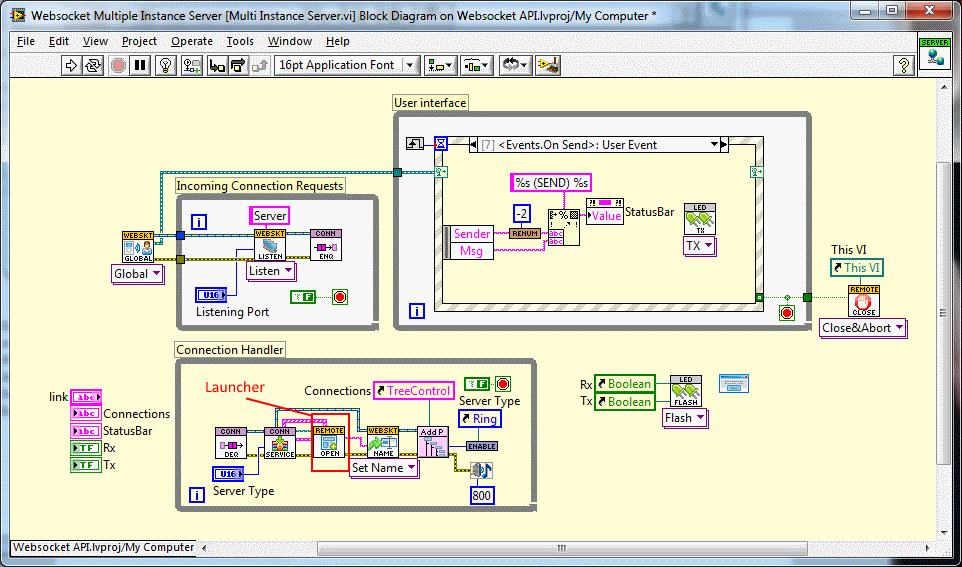
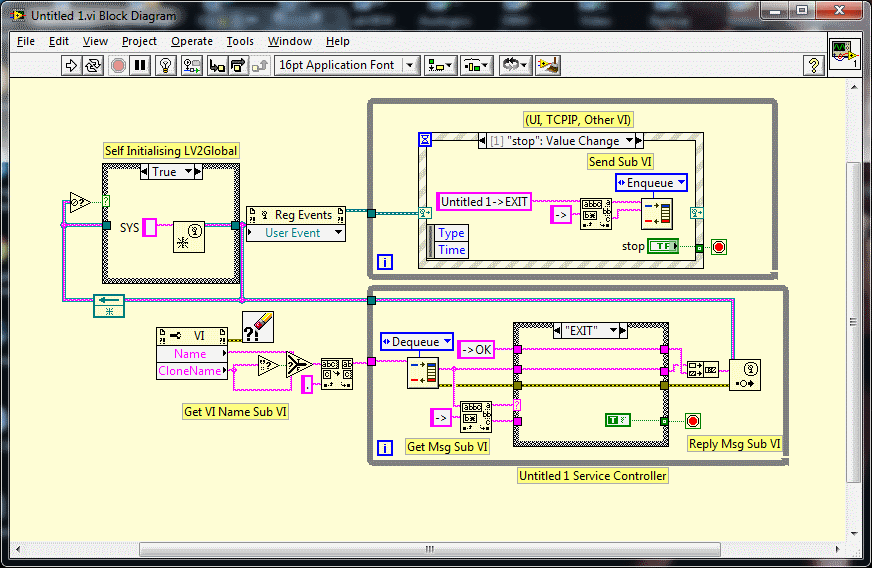
It depends. If it is a create/destroy type process then you don't need a queue at all (a service with no control interface). Just launch the service with a dynamic launcher and crowbar it (abort) externally using VI server. No queues, only the event broadcasting data and a while loop that you can stop dead in it;s tracks. If you need a bit more (Configure/Start/Stop/Shutdown) then untitled 1 contains a dynamic launcher itself and launches the acquisition when it receives Start, crowbars it when it receives Stop and complains when it gets configure whilst acquiring. So the acquisition is a sub-process of untitled 1 and untitled 1 is the acquisition "controller" that provides the system interface. If you cannot just crowbar it, then you must go the timeout route (zero on the queue timeout) and effectively untitled 1 is a state machine with message injection rather than a message driven action engine (it's an important distinction), There was a discussion on here a long time ago where we discussed these methods and Dalku and I compared notes with Lapdog. The only real difference was I used "->" as a message delimiter and case statements and Dalku used ":" and his Lapdog classes. The arcitectures were similar, it was the implementation that differed. You could also use the Actor Framework but then you are really getting complicated just to start/stop a VI (in fact, the AF always strikes me as complicated regardless of the size of task). If you think about it, you are asking for the same features as an Multiple Document Interface which is just a sub module launcher with event feedback which is what you have above if you include a launcher. Another example of the launch and crowbar approach can be seen in the Websocket server. When a connection comes in, the sub process is launched and runs asynchronously whilst the server listens for more connections and launches other services. If the server is closed, it just goes through the list of running services and crowbars them (abort then close FP). Each sub process is a service as described in my previous post but doesn't launch anything dynamically. So once launched, the client/user talks directly with the service (launched process) through a defined string API using their web browser. .

-
I've been using the following topology for a long, long time now and haven't found anything better that suits my needs. It's just the next level up to your "cartoons" but gives you a complete message based service architecture (that transcends networks ). Mine is a little more complicated but not much - just deeper message decomposition and only replies if there is a question mark after a command ala SCPI. You can replace queues with events if you prefer. It's simple, easy to understand and scales better than any other generic framework in LabVIEW. When you hear me talking about "modules", I'm talking about the bottom half of that diagram. The only thing it's missing is a dynamic launcher for the service. You can also bastardise it with classes instead of the case statement if there aren't enough VIs for you All the comments are just saying that whats on the diagram is normally inside sub VIs but the guts are displayed for understanding. PS: You'll find the Queue VI used here in Dispatcher but it's nothing special - just a self initialising queue wrapper for strings that I use in everything!!.
-
Or you can try to use the NI-IMAQ for USB Cameras which was obsoleted by IMAQdx
-
It's an old (very, very old) joke that relies on making an assumption about the first persons statement with regards to his perception of the problem. My mums dog won't bark at strangers. Your mum doesn't have a dog.
-
I don't really know that much about it (it's not in 2009 which I'm using here). I do know that this is the method they now employ for all other DAQ such as. FPGA for high throughput applications. I would guess that it is very efficient as they can do DMA transfers directly from acquired memory to application memory without having to go through the OS. Reading out of the DVR would be the bottleneck rather than from acquired memory (system memory as they call it) to LabVIEW memory which is the case with painfully slow IMAQ to Array and Array to IMAQ, for example. Until IMAQ ImageToEDVR that was really the only way when you wanted to stream frames to files. With the EDVR coupled with the asynchronous TDMS (which just so happens to take a DVR) I can see huge speed benefits to file streaming at the very least.
-
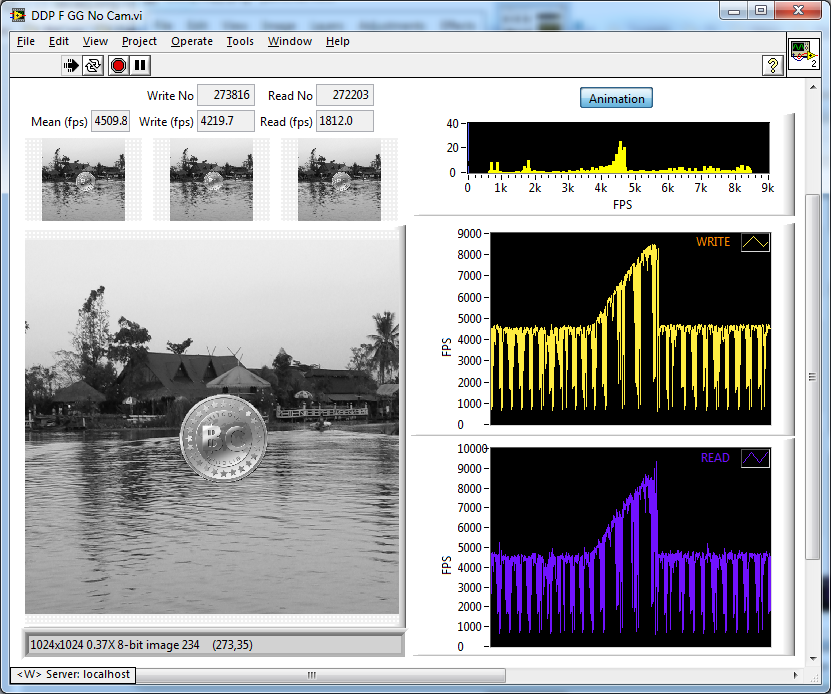
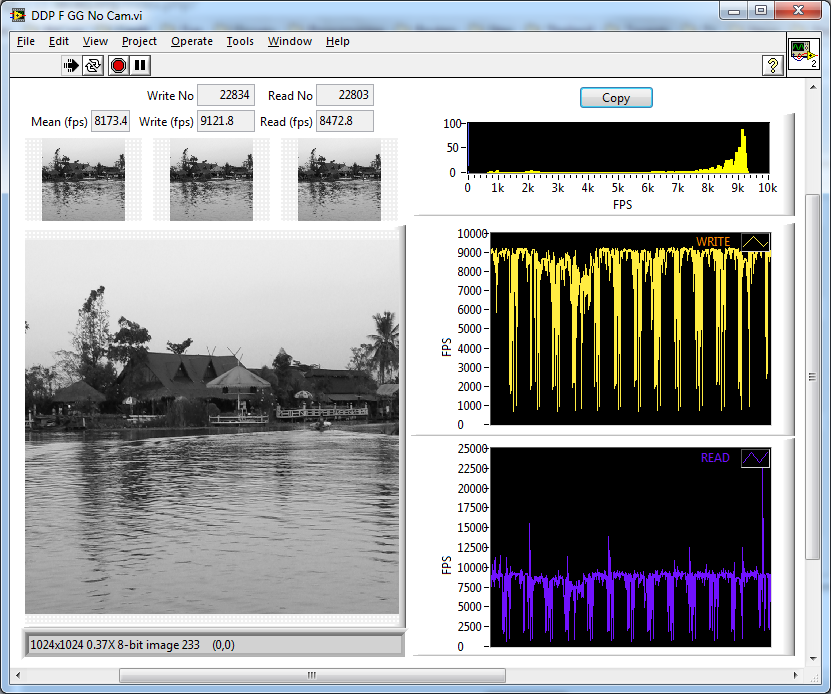
IMAQ GetImagePixelPtr? That only retrieves a pointer. Are you then using IMAQ SetPixelValue to write individual pixels to an IMAQ ref? Not IMAQ functions. IMAQ references. This maybe explains my confusion about corruption, Yes. IMAQ handles resource locking transparently (same as global variables, local variables, and any other shared resource we use in LabVIEW) so we never have to worry about data corruption (unless we cock up the IMAQ names. of course) Once you have an image inside an IMAQ ref. Never, never manipulate it outside of IMAQ (use only the IMAQ functions like copy, extract etc). Going across the IMAQ boundary (either direction) causes huge performance hits. As AQs signature states "we write C++ so you don't have to". If you are pixel bashing singly into an IMAQ reference pretending it is just an array of bytes in memory somewhere using IMAQ SetPixelValue, then you will never achieve performance. Get it in with one block copy inside the DLL and never take the data out into values or arrays. Use the IMAQ functions to manipulate and display the data . This will cure any corruption as you will only receive complete frames via your DLL. If you want, you can implement your triple buffering inside the DLL. Will it be fast enough? Maybe. This is where using NI products have the advantage as the answer would be a resounding "easily". Anecdotally with yours and my methods I can easily get 400 FPS using a 1024x1024 U8 greyscal image in multiple viewers. I'm actually simulating acquisition with an animation on a cruddy ol' laptop running all sorts of crap in the background. If I don;t do the animation and just a straight buffer copy from one image to another, I get a thousands of frames/sec. However, I'm not trying to put it into an IMAQ ref a pixel at a time. Animation Buffer copy.
-
Compiled with different optimiser settings? One in LVx32 the other in x64? The girl in the next cubical had a headache? It's a bit of a "my mums dog won't bark at strangers". There is a performance monitor (Tools>>Profle>>Performance And Memory). Inspection of that while running may identify the VIs that are working harder than usual and may provide a hint at what is different.
-
This has been really bugging me in that if you have the image in an IMAQ ref (and your 3buff seems to imply you do), how are you able to write a partial frame to get corruption? Are you absolutely, super-duper, positively sure that you don't have two IMAQ images that are inadvertently identically named? That would cause corruption and may not be apparent until higher speeds.
-
Do you have 2012 or later as an option? If so, the IMAQ ImageToEDVR VI will be available.
-
Oooooh. LabVIEW streaming server on NAS?
-
I haven't played with this yet, but from reading everything about this acquisition method it strikes me that it doesn't fit with an asynchronous buffering producer consumer architecture. It seems to be a synchronous method targeted at efficient memory management and high throughput.. It states in the docs: "You must delete this external data value reference before the driver can write new data to the specified portion of the buffer." I read that as you must destroy the ref in order for the acquisition to acquire the next block of data. i.e. if you stick it on a queue/fifo you won't get another acquire until you've popped it off the queue and destroyed it which defeats the object.
-
Built Application Occasionally Freezes on Windows Open/Save Dialog
ShaunR replied to mje's topic in LabVIEW General
Patches only fix the known issues but I've found they have never fixed my issues...lol 2011 was renowned for funnies. I had one code base that would compile fine in 64 bit but not in 32 bit. - the IDE just disappeared. On a couple of machines, the debug highlighting wouldn't highlight unless you set one of the VIs on the diagram to "Suspend When Called" and one of my colleagues reported that his LabVIEW ini file kept on getting wiped out. Is this a mature product? Are you still using 2011 for new projects? If you have moved on and it only happens in 2011, then I would suggest just calling the windows dialogue directly with API calls and put a note in the documentation. Even if you found a reproducible way of showing NI, it is unlikely they will address it and the best you could probably hope for is one of the perpetual CARs.to go with those from 8.x. Not very helpful but maybe solace in shared misery with the "Stability and Performance" release that was neither -
Built Application Occasionally Freezes on Windows Open/Save Dialog
ShaunR replied to mje's topic in LabVIEW General
Still no good advice as to what to look out for. (You haven't said what version and bitness you are seeing this behaviour in). One of the first things I do when I get peculiar behavior like this is load it up and do a mass compile in the other bitness and/or do a save for previous version. Sometimes extra problems pop out like complaints about a corrupted VI (happened last week to me), a conflict that wasn't being raised before (happened about 3 months ago) or it will go off hunting for a VI it suddenly decides it needs which you removed during the last ice age. Long shot, I know, but it has caught some things in the past.. -
And the stage is set! In the blue corner, we have the "Triple Buffering Triceratops from Timbuktoo". , In the red corner we have the Quick Queue Quisling from Quebec and, at the last minute. In the green corner we have the old geezers' favourite - the Dreaded Data Pool From Global Grange. Dreaded Data-pool From Global Grange.llb Tune in next week to see the results.
-
Obviously you don't. Looking forward to your triple buffering and bench-marking it Maybe put it in the CR?
-
Are you currently using IMAQ Extract Buffer VI and finding it is not adequate?