ShaunR
-
Posts
5,020 -
Joined
-
Days Won
312
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by ShaunR
-
Well. Sort of relevant.... I have an automatic HTML document generator for help files. I looked at the LV Report Generation Toolkit but it was awkward and I settled on a templated system and regex replacement (header, body footer templates etc). I found that writing HTML with a WISWIG HTML editor (so you know what it will look like) and running a script against it with keyword replacement was easier and more flexible than building a HTML document with the LV Report Generation Toolkit for that use case.
-
I have never used a NI USB 8452 but...... According to the manual it has on board pull up resistors that need to be enabled for Vref ≤ 1.8 V. Whats your Vref?
-

TCP Write works when it shouldn't
ShaunR replied to Cat's topic in Remote Control, Monitoring and the Internet
You need to use "GetIpAddrTable" and then look at wType to see if it is MIB_IPADDR_DISCONNECTED. This just reminded me........ I was making fun of my Linux fanatic friend. I said you can tell the difference between a Windows and Linux programmer by how they approach a task. If the task is to tell if you are connected to a network. The windows programmer will call an API function to find out the network card state. A Linux programmer will monitor the LED blinking on the network card with a webcam, pipe it to a file then regex the file to see if the LED is on He scowled. Thought about it and then said, with a smile,. "Nope. We'd get an intern to watch the LED and SMS us on the yacht when it changes" - Touche!. -
There is a lot of information on interpolation in LabVIEW including examples which you can find using the Example Finder.
-
Well. you have descrete increments that luckily correlate to the index. So if your user enters 110 you can just divide by 100 (quotient) and it will give you 1 which you can pass to the index array function to extract the row. The fun begins when you want to get to the closest higher or lower than the value input
-
Error 2: Memory is full - but it isn't
ShaunR replied to ThomasGutzler's topic in Object-Oriented Programming
Naah. You only want to replace your home-grown. memory/handle hungry, local object database. We all know of a self contained, blisteringly fast, serverless RDMS that would fit the bill nicely I don't understand folks that don't use it even if it's just for error logging. -
Error 2: Memory is full - but it isn't
ShaunR replied to ThomasGutzler's topic in Object-Oriented Programming
Perfect use-case (on the surface) for a relational database. -
What do you call a 1 element buffer?
ShaunR replied to Aristos Queue's topic in Application Design & Architecture
Change the word *is* in the current APIs docs to *consists of*. Job done and you can move on . -
What do you call a 1 element buffer?
ShaunR replied to Aristos Queue's topic in Application Design & Architecture
I disagree with this statement. You can only access elements in order, for a queue and only at the end (FIFO, LIFO etc). That is not a restriction for a buffer which is just a common usage term for a storage area that tends to be (but isn't required to be) an intermediate step in processing. Unlike a queue it can be accessed any way you choose including randomly or in parallel, in chunks or whatever you decide. A buffer has more in common with streams than queues as streams are effectively managed buffers. As an exercise in pedantry (I think maybe in tune withe Darin here) A Pipe is none of the above. It is a redirection. (Although for IPC it is usually realised with FIFOs). However. I think you are trying to distinguish between a continuous flow with endpoints (like sockets) and a global shared memory area that can be read and written to/from (like mmap). So. I suggest the terms are correct. - [shared] Buffer and Pipe (although I would call the latter "stream" because I'm not a Linux fanatic). Maybe all that's required is a mnemonic to remember which is which (although if you concentrate on how transfers happen rather than what is transferred, I think it is more obvious) -
Transport.lvlib, which this package depends on, has been updated. It uses a new installer which this one will also use so I will leave it a couple of days for people to check out and break it - then update Dispatcher.
-
Version 2.0.0.0 released. Now includes a proper installer and palettes.
-
LabVIEW, Websockets, and SVG
ShaunR replied to smarlow's topic in Remote Control, Monitoring and the Internet
Close frame? -
Communicating between Windows virtual memory and myRIO FPGA
ShaunR replied to Calorified's topic in Embedded
I just tried it with a Delphi program and it worked fine. Make sure you create the file as "Shared" so the LabVIEW application can open it. -
Should I change the stupid name of “Messenging"
ShaunR replied to drjdpowell's topic in LabVIEW General
first decide if it's a library, Framework or Toolkit (I would suggest it is a framework since you have to write custom messages) IPC Message Framework/Library/Toolkit? (boring but descriptive ) Graphein Framework/Library/Toolkit? (I like this one ) Tiezi Framework/Library/Toolkit? K̄h̀awsar Framework/Library/Toolkit? (and other non English transliterations of message) The Doctors Message Framework/Library/Toolkit? Powells Post Office Framework/Library/Toolkit? Personally, I would stick with what you used to be happy with if it wasn't a typo.I fight with NI all the time about the tools network and you can say "no thanks, I'm happy as it is"! -
Communicating between Windows virtual memory and myRIO FPGA
ShaunR replied to Calorified's topic in Embedded
Yes. I think you will be a little surprised when you come to do this as it probably isn't doing what you think it is (as Ned is trying to explain). Yes. It creates and then writes because you need something to read otherwise it would be an empty string or error (there is no CreateOrOpen equivalent). ...And Yes. "Open" is equivalent to OpenExisting(string mapName) in C#. Similarly, "Create File Map" is equivalent to CreateFromFile(String, FileMode, String, Int64) - I think they term it "persistent" mapping. Likewise, Create Memory Map equates to CreateNew(String, Int64, MemoryMappedFileAccess) which I think they term Non-Persistent mapping . I think that's right at least. The VIs use the windows API rather than .NET so the call names are bit different. So you'll create your file map in your C# probably using "CreateNew" with READ/WRITE permissions and a certain mapName (it doesn't have to be persistent and on disk) and then you'll "Open" it in LabVIEW (with READ permission) with whatever "mapName" string you gave it in the C# CreateNew method. Error -80002 just means it couldn't open a mapping either because a map with that name doesn't exist or because it doesn't have the permission to open it. -
Communicating between Windows virtual memory and myRIO FPGA
ShaunR replied to Calorified's topic in Embedded
Events (or listeners) don't have constructors. It's a bit of a shame you have invested so much in C#. You could have just used this which probably does a lot of what you want. At least it could show you how to interface to it as a kind of tutorial. Ultimately you are going to hit a brick wall, though. .NET doesn't run on myRIO (Linux Real Time) -
Communicating between Windows virtual memory and myRIO FPGA
ShaunR replied to Calorified's topic in Embedded
I'm going to go out on a limb here and make a wild assumption. You are trying to use the skeleton face tracking, right? So, because there is a C# example, you coded that up and got it working. Now you have some C# code that gets data from the SDK API, but want to get it into LabVIEW somehow. Am I close? Well. I think you have made things a little bit hard for yourself because you used C#. LabVIEW can interface directly with the API and you can use the callback function (.NET callback) to get the data into LabVIEW directly without jumping through hoops. The issue is you have isolated the data in your own monolithic program and now have to use some tricks that are quite advanced to get from there into LabVIEW. So you either write some C# code to re-transmit the events through your code to LabVIEW (which we have talked about, but isn't trivial) or just access the events directly and not bother with the C#. The SDK has the event KinectSensor.AllFramesReadyEvent. You should be able to hook that directly with the .NET callback and therefore you don't need to write your own events or messages in C# for LabVIEW (there are examples shipped with LabVIEW for demonstrating the callback - NET Event Callback for Calendar Control VI in \examples\comm\dotnet\Events.llb and NET Event Callback for DataWatcher VI in labview\examples\comm\dotnet\Events.llb). -
Short progress update...... Having a bit of a problem with installers but hopefully will be uploaded next week.
-
Couldn't resist
-
Communicating between Windows virtual memory and myRIO FPGA
ShaunR replied to Calorified's topic in Embedded
Don't go sending nasty text stuff to me (I can only read pictures) There are examples of how to use the VIs for the two modes of operation (memory and files) and some details in the "context help". That's it for the docs . The secret ingredient you may need is PostLVUserEvent to address signaling from your C# module. I know little about C# apart from it's basically .NET (which I vehemently avoid as much as much as ActiveX) so you may be able to use a .NET callback instead if you compile it as an assembly. However, if you are going to do that then why bother with memory mapped files? -
Communicating between Windows virtual memory and myRIO FPGA
ShaunR replied to Calorified's topic in Embedded
Ah. This is a completely different beast to DMA (Host to Target). Here is a LV version of memory mapped files (for windows) which will enable you to speak with your C# MMF in LV. You will be no closer to getting it into a myRIO, although you could replace the OS calls with those for the linux mmap if it's supported.. -
I don't think many will realise what a great Xmas present this is but I do and thank you for the change.
- 1 reply
-
- 1
-

-
What a bizarre workflow. Are many people doing this? I leave code at - what could you call them? micro checkpoints?. Points in the day to day development that you can draw a line under and say "that bit is working". Maybe not enough of a leap forward to warrant a commit or tick off a milestone. Maybe even a test to "see if it flies" sort of thing, but a meaningful juncture in the development. If it means I have to go and have a coffee or chat with other developers for 1/2 an hour before the end of day-so be it. If it means an extra hour or so after the end of day, so be it. I suppose if you are a militant clock watcher, then I guess you just drop your tools when the bell rings regardless of the state of the code. I don't have any issues remembering where I am in the code on a day-to-day or week-to-week basis but for commits and at the end end of day, the code is never broken and the recently used lists usually has the last VIs and projects I was fiddling with.. It reminds me of an argument I had once about the trunk in SVN. A colleague said that it was ok for the trunk to be broken and waved some kind of book in my face that apparently was the word of god on the subject. My position was that he he was nuts and should stay away from my repositories but I fell short of telling him what I would do with the book if he broke any of my repository trunks
-
Python?
-
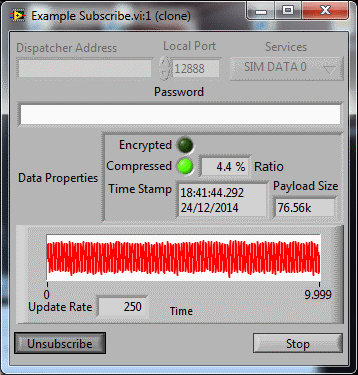
Ah Yes. Sorry. Kind of slipped off the radar what with Xmas and everything. Yes, yes, yes. I actually have a later version which updates Transport.lvlib shipped with the latest version (for Version 1.1). That gives dispatcher the compression (zlib) and compression/timestamp information like so. The Get Subscribers was removed as it was not intended for Users (more for internal use - which it never was) and just leaks information that could be exploited. There were a few more tweaks and bug fixes (including the one reported) so there will be an update. I'm just umming and arring about an installer (e.g. putting into a VIPM package) ATM. I've been burned badly by VIPM so am tempted to use my wizard instead. So once the grog has worn of and the hangovers have subsided; I'll upload (just after Xmas but before the new year).