Jim Kring
-
Posts
3,905 -
Joined
-
Last visited
-
Days Won
34
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Jim Kring
-
Kudos!
-
I created a new topic, here, for this discussion -- it's going to be a hot one and should be separated from the discussion about whether to move OpenG into vi.lib.
-
Great! That's probably all of them. (Also, Darren Rocks!!!)
-
There must be a LabVIEW.ini key that let's you create these.
-
bug Reentrancy bug in Write Key (Variant) VI?
Jim Kring replied to Stobber's topic in OpenG General Discussions
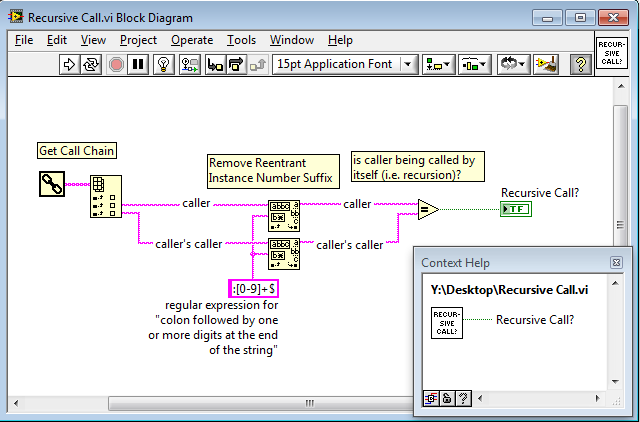
I think that "call stack" means the "call chain" -- if the caller's name is the same as the current VI's name, then it's recursion. I threw a small VI together that does this: Recursive Call.vi Perhaps this could be a useful OpenG VI. Note that it should probably be improved to test for A >> B >> [C >> [..]] A recursion (by checking for the callers name in any location in the call chain), rather than just A >> A recursion (by only comparing the caller with the caller's caller). My guess is that passing in a parameter indicating that it's a recursive call is probably a bit faster than programmatically inspecting the call chain.
-
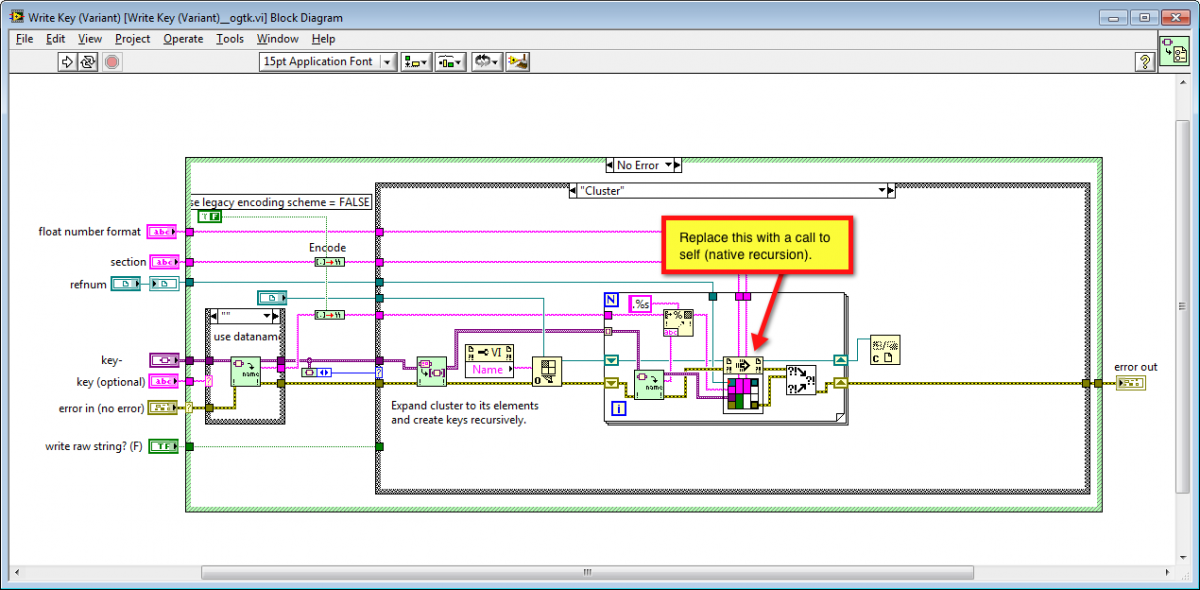
There are some OpenG VIs, like the Variant Configuration File IO VIs, that use the legacy form of recursion (VI Server Call By Reference to self), which is (I believe) much less efficient than using the native recursion feature introduced in LabVIEW 2009. I would recommend changing all VIs that use legacy recursion to use native recursion, provided that a performance improvement would be gained. Here's a screenshot, showing what I mean:
-
bug Reentrancy bug in Write Key (Variant) VI?
Jim Kring replied to Stobber's topic in OpenG General Discussions
I would definitely call this a bug. How I typically deal with such things is to create an argument called "in recursive call?" and warn the user to leave it unwired, but wire up a TRUE whenever calling it recursively. If this input needs to be hidden (which is probably a good idea), then the actual recursive VI can be moved into a private subVI with the public VI being a thin wrapper around the private, recursive subVI that only passes through all the inputs/outputs (except for the private "in recursive call?" input).
-
What are the use cases for choosing random elements in an array? Personally, I've only had to do this once, and it was in an NIWeek coding challenge about 6 years ago Just thinking.... could this be further generalized to a function that chooses a random integer between two ranges (for example an array element index between 0 and Length - 1)? Maybe it would be good to add such general purpose functionality to the OpenG Random Number within Range (adding the ability to work with integers), as opposed to the more specific use case of choosing random elements in an array.
-
Well, technically, it doesn't need to be "donated" to OpenG, it just needs to be released under a BSD license, so that OpenG can distribute it -- that's the (semantic) difference between ownership (copyright) and rights (license)?
-
proposal Should OpenG Move to vi.lib?
Jim Kring replied to jgcode's topic in OpenG General Discussions
AQ, Great points. Windows/OS permissions are a very important consideration. My thoughts are that OpenG should probably follow suite with the official standard, since I believe that both NI and JKI will be working hard to solve this problem for everyone. For example, stuff that is installed by VIPM could be done so with special permissions (signature) granted by NI. -
I'm really in favor of creating OpenG functions for Create GUID and Is a GUID. Enrique Vargas contributed the MD5 code to OpenG, which was part of the CryptoG library -- I know that there's a function in there for creating a GUID with a pseudo-random generator via SHA functions. -Jim
-
Playing devil's advocate: What are the common scenarios for testing whether the length of two strings are equal?
-
closed review String To Character Array (String Package)
Jim Kring replied to Wouter's topic in OpenG Developers
This looks like an interesting idea. Playing devil's advocate: Are there any examples of similar functions in other programming languages/libraries? (if there are a lot of other languages that have a similar function, then it's probably indicative of it having a lot of use cases) What are some common use cases for such a function? -
proposal Should OpenG Move to vi.lib?
Jim Kring replied to jgcode's topic in OpenG General Discussions
Hi All, I'm very friendly to moving OpenG into vi.lib in order to conform with NI's new standards for add-ons (and I don't see any obvious show stoppers). There are various reasons to do this (in terms of how LabVIEW gives vi.lib some special treatment not given to user.lib), in addition to the fact that it's a standard (which are probably the reasons for the standard). That said, we should consider all the possible negative impacts of the move to vi.lib and figure out their significance and ways to mitigate the problems. One possible negative impact I can think of is: any VIs that might have a hard-coded path to call these VIs by reference (low probability). Regarding adding tools into the existing palette categories, this is an idea that JKI is currently (in the early stages of) discussing with NI, since it will involve the adoption of some new standards. The JKI team has some ideas that need to be put down onto (electronic) paper as a functional spec proposal. I'm just mentioning this, since I think that OpenG (and others like SAPHIR) would benefit from this, so I want you all to bug me/JKI about it later/often -
I think that the update of this information could very easily be automated during the build process. What if there were a special package that OpenG Developers had installed that included a dialog for editing these tags and performing other, similar/related activities?
-
What are the use cases for removing non-printable characters? How do non-printable characters get into a string? Why would one want them removed? Is this common in string operations, or is it more focused to a specific problem/application domain?
-
I'll chime in, since I spearheaded an OpenG license transition process once before I like the current (new BSD) license used by OpenG. Also, it's pretty tough to change to a new license since it (most of the time) requires the consent of all the original authors. Regarding how we document the licensing information, I think that the following might work: - Each VI could clearly state which package it belongs to and how it is licensed (e.g. "This VI is a member of the OpenG Array Tools 4.1 package and is licensed under the BSD license. Please see the VI description and VI Package description for more information."). This gives the average user some kind of breadcrumb that they can use to figure out the license details. - The package itself could contain details about the license, authors, etc. - The VI could create, in tags, a list of authors. Consideration: - It's helpful to have the VI name in the license agreement somewhere, to give the user an indication of where the VI came from, if it's name is changed in order to make a derivative work. For example, sometimes I'll rename an OpenG VI and make some tweaks to it. It's helpful to be able to see the original VI name and version information, so that if I want to contribute my changes back into OpenG (or pull new changes from OpenG into my derivative work), then I can.
-
closed review Trim Whitespace (String Package)
Jim Kring replied to jgcode's topic in OpenG Developers
That's some nice looking code! -
Reviewing the OpenG Trim Whitespace performance optimizations on LAVA: http://lavag.org/topic/14776-trim-whitespace-string-package-review/
-
@Jon: This is a great plan. I think that breaking things out into separate review threads/topics for each proposed change will let people contribute as they have time. Also, if people make a significant contribution, we should be sure to include them in the copyright notice, so they receive credit for helping. Another thought is that it would be helpful if the original post gets updated with status and decisions, so that people know what stage in the process things are at. For example, after the review process is over, it should be obvious that that review/comments period for a given proposal has ended.
-
closed review Trim Whitespace (String Package)
Jim Kring replied to jgcode's topic in OpenG Developers
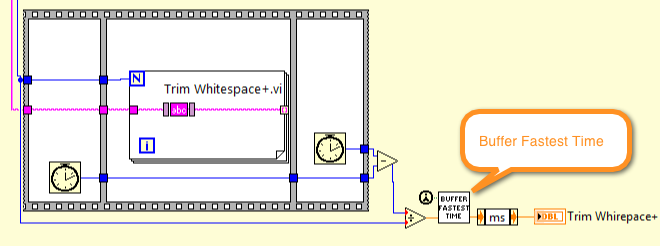
A few thoughts on performance benchmarking (which is a pretty tricky thing): 1) In addition to performing a short operation thousands of times and averaging, I like to keep track of the fastest time over some period (run continuously and then stop when I see the time settle) -- the fastest time is more representative of it's true performance capabilities. Trim Test - Fastest.zip 2) Care should also be taken to use appropriate test vectors and compare performance for each class of vector. For example: Small strings vs. Large strings Mixed whitespace vs most common whitespace I think it's important that the code be optimized for the most common scenarios (a few space "\s" characters at the head and tail, and probably some EOLs at the tail). So, if there are design choices that affect performance (like the order of characters in the whitespace array being searched), then we should lean toward those. Regards, -Jim
-
closed review Trim Whitespace (String Package)
Jim Kring replied to jgcode's topic in OpenG Developers
Hey Jon, Thanks for posting this design change for review. A couple questions: A) Do users often need to "Remove non-printable characters (False)" -- is this a common use case? B) Does it add much value to couple the removal of non-printable characters to the trimming of leading/trailing whitespace? (For example, do users often need to perform these operations together?) It seems to me that if the answers to these questions aren't an overwhelming "YES" (in all caps , then removal of non-printable characters should be decoupled from Trim Whitespace, since decoupling orthogonal functionality tends to make the software more maintainable, understandable, testable, etc. If the decision is to decouple them, then maybe it makes sense to add a new function called Remove Non-printable Characters. Regards, -Jim -
I love the new site -- simple and clean design. More LAVA, less blabla.
-
Good job @jgcode >> OpenG 4.0 release available for download: http://cot.ag/mmQRnB /via @openg_org
-
I think I have a workaround for that - VIPM does not allow you to specific a relationship with incompatible packages in that direction: However, we could make the value of the dependency packages comparison operator to be equal: Which forces an upgrade - if this is what we want to do? (ignore portio in screenshot, I snapped this before I had finished): I will ping you offline to discuss further. I think my statement was wrong -- the problem was that the OpenG Toolkit package didn't declare a dependency on OpenG LabVIEW Data Tools. Changing the dependency comparitor from ">=" to "=" created new problems (like the fact that newer versions of the dependencies won't be compatible, anymore -- we need it to be ">=")