LogMAN
-
Posts
720 -
Joined
-
Last visited
-
Days Won
81










LogMAN's Achievements
")





-
Welcome to the active side of LAVA! You may be happy to learn that perpetual licenses are back: https://www.ni.com/en/shop/labview/select-edition.html Binary files are always problematic when merging. Even LVMerge does not get it right all the time, especially when the differences are too large, which gives you the first clues: Whenever possible, avoid merges - no merge means no merge conflicts Establish a process to avoid merges - perhaps finish implementing the functional part first, then hand it off to the UX designer. Establish an environment of clear communication among developers - telling a colleague to wait 5 minutes for your work to finish so that they can base their work on yours is a very effective way to avoid conflicts in the first place. Merge changes in small, iterative cycles - this reduces the chances of merge conflicts and insane objects If more than one developer needs to touch the same code at the same time, review your architecture. Split large VIs into smaller SubVIs, build reusable components, separate concerns, etc... In my team we seldomly need to merge (perhaps once or twice in the past 10 years). We split the project into functional groups with clear boundaries. The lead developer is responsible for ensuring that the boundaries are maintained. When a team member needs to make changes that affect others, we first merge everyone's branches, then do the change, then continue with normal work. At least for us this has proven very effective. I can't say much about LV2021 because I'm still working with LV2019 but in general the SP1 version is more stable and reliable. Maybe take a look at the bug fixes and known issues to help you make a decision: https://www.ni.com/en/support/documentation/release-notes/product.labview.html?version=2021-sp1 For your merge issues, however, it will most likely make no difference. Since LV2024Q1, however, NI has made considerable changes under the hood, including new tooling for diff and merge: Improvements to Comparing VIs Changes to Compare VIs and Other LabVIEW Files Generate VI Comparison Reports with the LabVIEW Command Line Interface Perhaps more useful is the new feature that allows you to open a project without changing the save version, which means you can edit and save VIs in earlier versions (as far back as 2017) without having to go through any extra steps. This also means you could try to merge using LV2025Q3 and keep the merged files saved for LV2021. The chances are slim that the errors can be resolved in newer versions but it might be worth a try. And you don't need a license for that. You can evaluate LabVIEW for a couple of days (I believe up to 30 days). *cough* Community Edition *cough* - pardon me
-
Yes it is fixed. Thanks a lot!
-
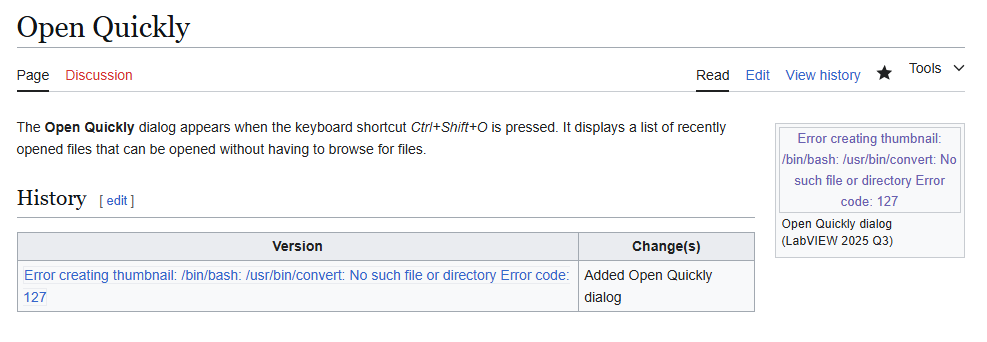
There appears to be an issue with thumbnail creation on the Wiki. Here is an example: Open Quickly - LabVIEW Wiki According to the information here and here, either ImageMagick is not installed or incorrectly configured. Perhaps a recent update broke it? @Michael Aivaliotis I believe you are the only one who can fix this

-
This works as expected in version 1.7.0.118 Tested with LV2019 SP1 (32-bit) {"status":false,"code":0,"source":""}
-

LabVIEW Installer Takes Over an Hour to Complete – What Could Be Wrong?
LogMAN replied to odw's topic in LabVIEW General
Also make sure you don't have thousands of files in the installation directory - it slows down the verification process at the end of an installation. -
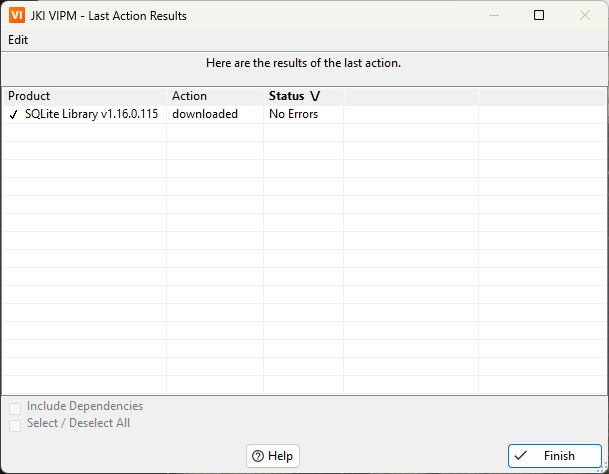
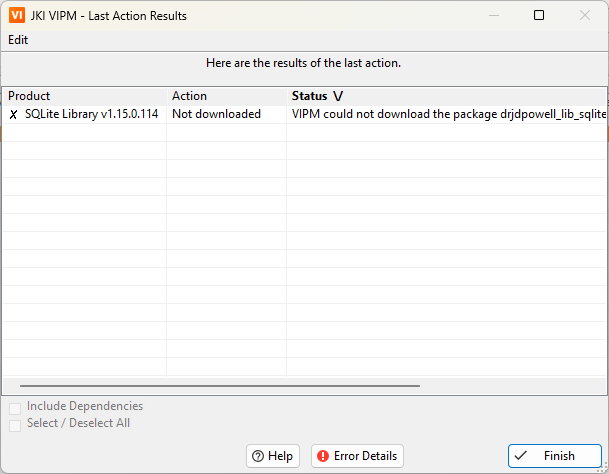
Yes this could be the same issue. In my case, however, the issue is with SQLite Library (JDP Common Utilities installs normally). Strangely, the reported package URL works in the browser. Only VIPM is not able to download the file. That said, I just tested it again and now it works for version 1.16.0 but not for 1.15.0. Again, there is no issue downloading the file with the reported URL: http://download.ni.com/evaluation/labview/lvtn/vipm/packages/drjdpowell_lib_sqlite_labview/drjdpowell_lib_sqlite_labview-1.15.0.114.vip
-
Cross-post: Unable to download certain packages through VIPM - VI Package Manager (VIPM) - VIPM Community Does anyone else have trouble downloading certain packages through VIPM? For example, I'm unable to download SQLite Library 1.16.0 because "VIPM could not download the package ... from the remote server." I checked the error details and was able to locate the package on the server: https://download.ni.com/#evaluation/labview/lvtn/vipm/packages/drjdpowell_lib_sqlite_labview/ I tried different versions of VIPM, including 2019 and 2025.1 (build 2772) with no avail. Other packages do not appear to be affected. Can someone confirm? I'm able to download the package directly from the server with no issues so the problem is with VIPM.
-
LabVIEW 2025 installation on Ubuntu
LogMAN replied to Sam Dexter's topic in LabVIEW Community Edition
Just installed it on my Ubuntu 22.04 machine, no problem. Did you actually install LabVIEW according to the instructions @Bryan posted? Your logs only show the package feed being added to apt. Make sure to follow the instructions from step 5 onwards. In particular, "sudo apt install ni-labview-2025-community". -
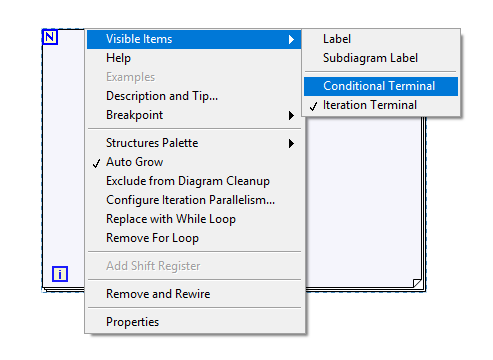
Where'd the conditional terminal go?
LogMAN replied to ShaunR's topic in Development Environment (IDE)
Apparently they moved it under Visible Items Edit: This also affects other types of structures.
-
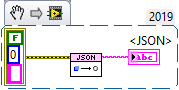
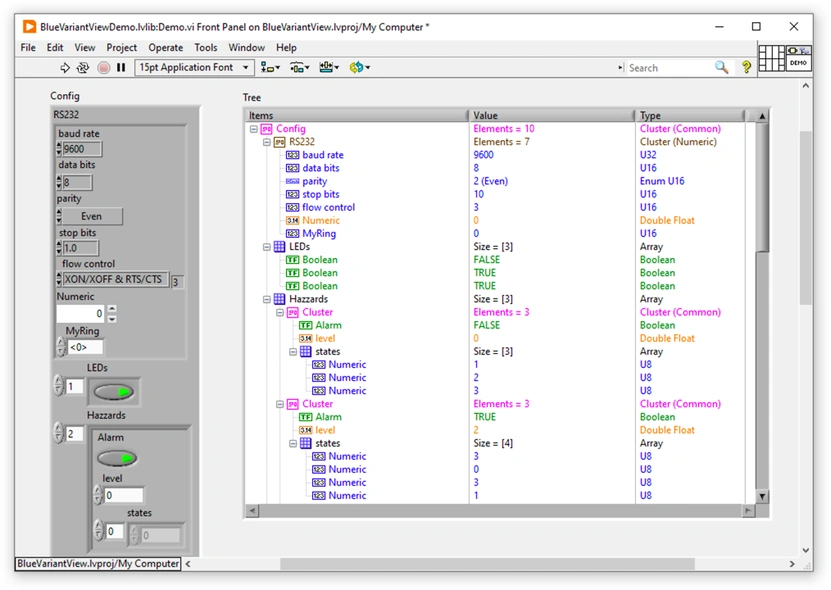
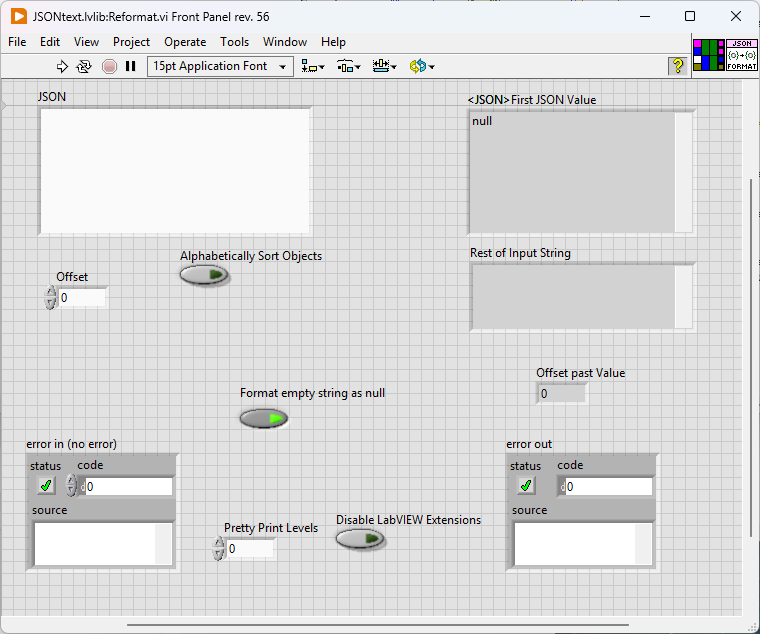
Yes this has been done before. I believe BlueVariantView is what you are looking for. It creates a recursive tree of any data type: JSONtext on the other hand illustrates how to turn your data back into a data type.
-
In the context of this VI, "empty string" refers to the JSON terminal. If you don't provide any input, it will return null. Otherwise, it returns an error.
-
You probably mean https://labviewwiki.org/wiki/User_Groups. I saw your suggestion on the talk page and was going to split it between List of LabVIEW user groups - LabVIEW Wiki and User group - LabVIEW Wiki. Apparently "user groups" is okay, but "user group" is not 🤷♂️
-
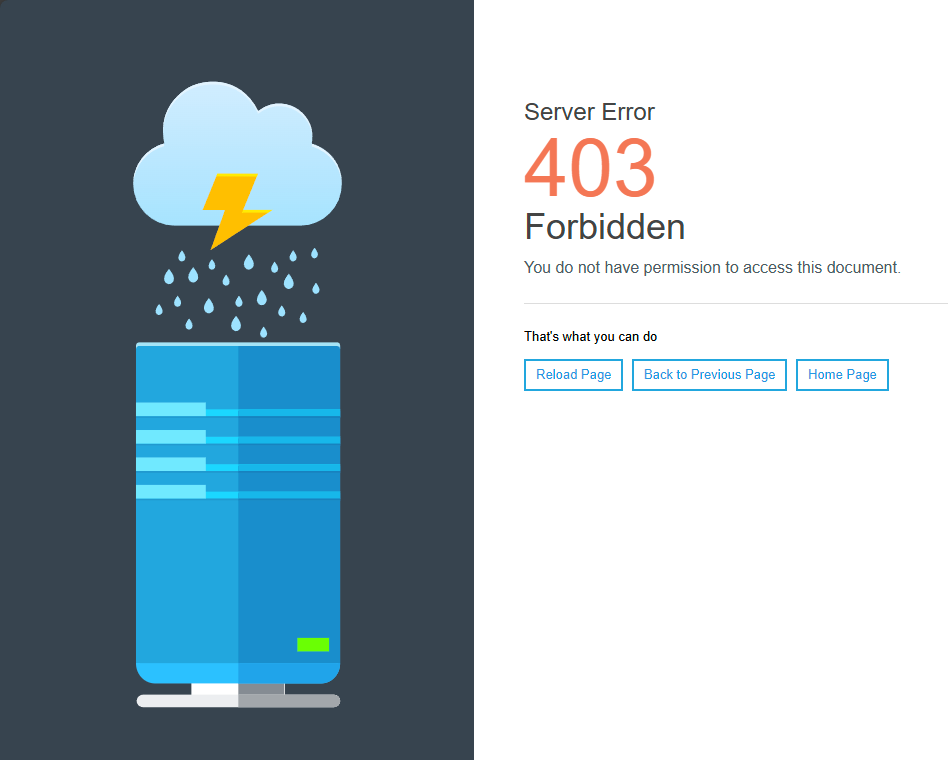
Thanks! Second that! The new wiki is also much more responsive, so editing has become a much more enjoyable experience That said, here is another issue I stumbled upon: When attempting to edit https://labviewwiki.org/wiki/User_group (or the associated talk page), the server responds with "Server Error 403 Forbidden" and blocks the IP.
-
There are quite a few pages affected. Find below a complete list of the ones found with a quick script. Affected conferences are: Americas CLA Summit 2019 GLA Summit 2020 NIWeek 2019 NIWeek 2020 If the channel cannot be restored, it would be great to have the videos for upload to a new channel that is not linked to the domain if anyone still got them. Just ping me and I'll upload them if you don't want to put them on your own channel. Otherwise, feel free to update the pages with the new video IDs. https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Architecting_for_Your_Customers https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Automating_IDE_Setup https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Building_Distributed_Systems_with_LabVIEW_and_ZeroMQ https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Complex_AF_-_Avoid_the_Pitfalls_of_Bad_Asynchronous_Programming https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Composed_Event_Logger_-_How_integrating_a_SOLID_Event_Logger_into_your_Applications_Reduces_Time_Spent_Debugging_Problems https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Decoupling_LabVIEW_and_Continuous_Integration https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Design_for_Research_(A_Case_Study_of_Building_a_Research_Metal_3D_Printer) https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Encapsulating_and_Reusing_your_UI_Code https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Expert_Panel:_Overcoming_Performance_Challenges https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Future_Proofing_Begins_With_Your_People_-_Lessons_Learned_from_My_Life_on_the_Outside https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Futureproofing_Software_with_Clean_Architecture https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/G_Interfaces https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/GCentral:_Removing_Barriers_to_a_Collaborative_Community https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Help!_I'm_out_of_letters_in_Quick_Drop! https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/High-Throughput_Video_Processing_to_Score_Heart_Rate_Responses_to_Xenobiotics_in_Wild-type_Embryonic_Zebrafish https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/How_YOU_can_design_amazing_looking_UIs https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Imperative_to_Functional_Programming https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Introduction_to_the_LabVIEW_Wiki https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Item_Manager_Framework_-_Future_Proofing_with_Dependency_Injection https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Keynote:_How_to_Leave_a_Legacy_Without_Leaving_Legacy_Software https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Keynote:_Practical_Methods_for_Software_Engineering_Idealism https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/LabVIEW_Performance_Tuning_Twenty_Years_Later https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Making_Modern_UIs_with_LabVIEW https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/NI_Presents:_Reusable_Add-on_Libraries https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/NI_Presents:_WebVIs https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/One_Library_To_Rule_Them_All https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Party_in_Front,_Business_in_Back:_Programming_The_Reverse_Mullet https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/PPLs_and_a_Better_Office_Experience https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Quick!_Drop_Your_VI_Execution_Time! https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Re-sizable_UI_and_Pane_Relief https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Scripting_in_LabVIEW_NXG https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Scripting_to_Save_Time https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Separation_Anxiety:_Designing_for_Change https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Sharing_LabVIEW_Code:_What_tools_are_good_for_what%3f https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Test_Driven_Development_in_Actor_Framework https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/The_Little_Things_in_LabVIEW_2020 https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/The_Stacked_Sequence_is_Dead._Long_Live_the_Stacked_Sequence https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/UI/UX_Considerations_when_there_is_No_Keyboard_or_Mouse https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Unit_Testing_at_Mock_Speed https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/What's_New_in_GPM https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Why_You_Should_(Not%3f)_Write_Your_Own_Framework https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Zero_to_RF_in_420_Seconds https://labviewwiki.org/wiki/GLA_Summit_2020/TestStand_goes_Agile https://labviewwiki.org/wiki/NIWeek_2019/Achieve_Better_UIs_With_a_Dynamic_Sizing_Library_and_Object-Oriented_UI_Panels https://labviewwiki.org/wiki/NIWeek_2019/Achieve_Success_With_an_Intermodular_Communications_Framework https://labviewwiki.org/wiki/NIWeek_2019/Another_Kind_of_Actor_Model_with_LV_NXG https://labviewwiki.org/wiki/NIWeek_2019/Best_Practices_for_Building_and_Distributing_Componentized_LabVIEW_Applications https://labviewwiki.org/wiki/NIWeek_2019/Better,_Faster,_Stronger:_It's_Not_All_Technical https://labviewwiki.org/wiki/NIWeek_2019/By-Reference_Architectures_for_More_Flexible_Software_Design https://labviewwiki.org/wiki/NIWeek_2019/Code_Trafficking:_Smuggling_Your_Best_Software https://labviewwiki.org/wiki/NIWeek_2019/Creating_Powerful_Web_Apps_With_the_LabVIEW_NXG_Web_Module https://labviewwiki.org/wiki/NIWeek_2019/Customizing_Your_WebVIs https://labviewwiki.org/wiki/NIWeek_2019/Decoupling_LabVIEW_Object-Oriented_Programming_Classes_via_Abstraction https://labviewwiki.org/wiki/NIWeek_2019/Design_Patterns_for_Decoupled_UIs_in_LabVIEW:_Theory_and_Practice https://labviewwiki.org/wiki/NIWeek_2019/Designing_Advanced_LabVIEW-Based_HALs_and_Frameworks_for_Mindful_Extension https://labviewwiki.org/wiki/NIWeek_2019/Designing_Software_Like_LEGO®_Sets https://labviewwiki.org/wiki/NIWeek_2019/Effectively_Using_Packed_Project_Libraries https://labviewwiki.org/wiki/NIWeek_2019/Everything_a_Software_Engineer_Needs_to_Know_Outside_Software_Engineering https://labviewwiki.org/wiki/NIWeek_2019/From_Variant_Attributes_to_Sets_and_Maps_(New_in_2019) https://labviewwiki.org/wiki/NIWeek_2019/Get_Team_Buy-In:_Running_Process_Improvement_Workshops https://labviewwiki.org/wiki/NIWeek_2019/Good_Component_Design_for_LabVIEW_NXG https://labviewwiki.org/wiki/NIWeek_2019/How_to_Be_Ultra_Productive_With_OOP_in_LabVIEW_NXG_Using_UML https://labviewwiki.org/wiki/NIWeek_2019/I_Find_Your_Lack_of_LabVIEW_Programming_Speed_Disturbing https://labviewwiki.org/wiki/NIWeek_2019/Introduction_to_Migrating_LabVIEW_Code_to_LabVIEW_NXG https://labviewwiki.org/wiki/NIWeek_2019/LabVIEW_NXG:_Advisory_Lightning_Rounds https://labviewwiki.org/wiki/NIWeek_2019/LabVIEW_Reuse_and_Package_Management https://labviewwiki.org/wiki/NIWeek_2019/LabVIEW_Unit_Testing:_Outlook_&_Tutorial https://labviewwiki.org/wiki/NIWeek_2019/Lean_LabVIEW https://labviewwiki.org/wiki/NIWeek_2019/Malleable_VIs:_More_Flexible_Code https://labviewwiki.org/wiki/NIWeek_2019/Message_Exchange_Patterns_and_Tools_for_Distributed_Systems https://labviewwiki.org/wiki/NIWeek_2019/My_Continuously_Evolving_Practice_of_Software_Engineering https://labviewwiki.org/wiki/NIWeek_2019/On_Refactoring:_Real-World_Approaches_for_Improving_Code https://labviewwiki.org/wiki/NIWeek_2019/Prof_Watts'_Theory_on_Why_Programming_in_LabVIEW_is_Fun! https://labviewwiki.org/wiki/NIWeek_2019/Sharing_LabVIEW_Code:_What_Tools_Are_Good_For_What%3f https://labviewwiki.org/wiki/NIWeek_2019/Software_Engineering_in_LabVIEW:_A_Look_at_Tools_and_Processes https://labviewwiki.org/wiki/NIWeek_2019/These_Innovative_Tricks_for_ProjectRequirements_Will_Change_Your_Life https://labviewwiki.org/wiki/NIWeek_2019/Using_and_Abusing_Channel_Wires:_An_Exercise_in_Flexibility https://labviewwiki.org/wiki/NIWeek_2019/VI_Analyzer:_The_Unsung_Hero_of_Software_Quality_Control https://labviewwiki.org/wiki/NIWeek_2019/What's_New_on_LabVIEW_2019_and_NXG https://labviewwiki.org/wiki/NIWeek_2019/Who_Are_You_Developing_Your_HAL/MAL_For%3f_You_Or_The_Test_Engineer https://labviewwiki.org/wiki/VIWeek_2020/8_Reasons_for_encapsulating_your_next_device_driver_inside_a_DQMH_module https://labviewwiki.org/wiki/VIWeek_2020/CEF_(configuration_editor_framework) https://labviewwiki.org/wiki/VIWeek_2020/Confessions_of_a_Retired_Superhero https://labviewwiki.org/wiki/VIWeek_2020/Fast_and_Simple_Unit_Testing_with_Caraya_1.0 https://labviewwiki.org/wiki/VIWeek_2020/Mock_Object_Framework https://labviewwiki.org/wiki/VIWeek_2020/Philosophy_of_Coding_-_How_to_be_a_CraftsPerson https://labviewwiki.org/wiki/VIWeek_2020/The_Core_Framework https://labviewwiki.org/wiki/VIWeek_2020/Using_a_Message_Broker_with_DQMH_Actors_for_High_Speed/Throughput_Data_logging https://labviewwiki.org/wiki/VIWeek_2020/VIWeek_–_Open_Your_Instruments_With_A_G_Interfaces_HAL_In_LV2020_(No_Lever_Tool_Required!!)
-
I did a quick test in a private MediaWiki instance and got it to work using the fix available on GitHub: Switch jquery.cookie to mediawiki.cookie by paladox · Pull Request #1 · debtcompliance/TreeAndMenu · GitHub