

drjdpowell
-
Posts
1,986 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by drjdpowell
-
-
You are correct that if one of the Exited messages fails to arrive then the UI loop will never shut down. That's exactly what I want to happen. Putting a timeout in the UI loop permits a resource leak--Loop 1 can continue operating after the rest of the application has been shut down. By not using a timeout any errors in my shutdown logic are immediately apparent. Fail early, fail often. The hardest bugs to fix are those I don't know about.
Well, timing out would be an error, and one could handle that error in multiple ways: log error and shutdown anyway, display error to User and wait for input, trigger hardware emergency safe mode. My point is that one’s code may require awareness about something, that is supposed to happen, not happening in a reasonable time. It’s obvious how to do that with synchronous command-response, but not so clear if one is staying fully asynchronous.
I’m thinking of creating a “helper” VI for my framework that can be configured to wait for a message. If it receives the message within the designated time it just forwards the message to its caller and shuts down; otherwise it sends a "timed-out” message instead. That way the calling loop can send a command that it expects a reply to, and execute code to handle the case that the reply never comes, while remaining fully asynchronous and unblocked.
-
For this reason your messaging system either needs a long timeout...
Messaging systems don't need those features any more than a person without a car needs car insurance. The reason you need those features is because you are using a message protocol designed around synchronous query-response communication. If your protocol is designed around asynchronous event-announcements then the need for those features goes away.
Question: Doesn’t a fully asynchronous message system still need the concept of a timeout? In your shutdown example, the UI loop is at some point waiting to receive the “Exited” messages from Loops 1 and 2. If one of those messages fails to arrive, won’t it be waiting forever?
-
In the case of filtering, there's a fairly long thread on the AF forums about various ways to do this with the current AF, and general agreement that those are *good* ways, not hacks or workarounds to compensate for a hole in the AF.
Could you point me to that thread? I had a quick scan but couldn’t find it.
-
You must be making this statement in a context I'm not aware of. I can't figure out what you're trying to say.
I mean if you can’t service the queue as fast as elements are added, then you’ll eventually run out of memory.
— James
PS, if you recall this conversation we had, one can use a timeout in a way that is guaranteed to execute the desired code on time
-
 1
1
-
-
If the timeout code is critical to the proper operation of the actor and it doesn't get executed, the actor may not behave as expected.
mje was talking about using a “zero or calculated timeout”, a technique I’ve also used. If a zero timeout never executes your actor’s gonna fail anyway.
-
Well the act of delegating to a private subActor (or any private secondary asynchronous task) only hides the extra layer. The public Actor might indeed respond to the message on short order, but there's no getting around to the fact that actually acting on that message takes time. Ultimately if some sort of message filtering has to be done at any layer because it just doesn't make sense to process everything, you're back to the original argument. If I can't do stuff like this easily with an Actor and my Actors are just hollow shells for private non-Actor tasks, I might not see a benefit for even using the Actor Framework in these cases.
I was thinking more of the use of a message queue as a job queue for the actor, rather than what to do about filtering messages, but the general idea would be to have the actor’s message handler serve as supervisor or manager of a specialized process loop. The manager can do any filtering of messages, if needed, or it can manage an internal job queue. It can also handle aborting the specialized process by in-built means that can be more immediate than a priority message at the front of the queue (like an “abort” notifier, or directly engaging a physical safety device). It wouldn’t be a hollow shell.
-
This is typically only an issue when your message handling loop also does all the processing required when the message is received. Unfortunately the command pattern kind of encourages that type of design. I think you can get around it but it's a pain.
My designs use option 5,
5. Delegate longer tasks to worker loops, which may or may not be subactors, so the queue doesn't back up.
The need for a priority queues is a carryover from the QSM mindset of queueing up a bunch of future actions. I think that's a mistake. Design your actor in a way that anyone sending messages to it can safely assume it starts being processed instantly.
I particularly second this. Actors should endeavor to read their mail promptly, and the message queue should not double as a job queue.
-
2
-
-
Hi Ben,
The launch technique is stolen from mje’s “message pump” package. It’s used by the Actor Framework, also.
The Actor Manager installs in a different location, and should be available under the Tools menu:
Please note that the Actor Manager is badly in need of rewriting. It’s not pretty.
What’s your use case for TCP? I have TCP Messengers in the package (which use TCP actors to run the client/server) that are intended to seamlessly substitute for other messengers (handling replies and observer registrations). At some point I will write the code to launch an actor sitting behind one of these servers. Do you want a TCP actor to talk to external non-LabVIEW code?
BTW, I’m in the midst of writing a talk on this package that I’m going to present at the European CLA Summit. Of course, this has made me relook at lots of things I did and want to change them
 . I’m going to upload a new version before that summit in April.
. I’m going to upload a new version before that summit in April. — James
-
In the framework I’ve developed, I get a lot of use out of subclassing the central enqueuer-like class (called, perhaps too simply, “Send”). Below is the class hierarchy. But “assertions of correctness”, what’s that? Breaking down some walls will certainly lose something to what AQ is trying to do. Personally, I think the tradeoff in flexibility would be worth it, but it would mean that that flexibility would be used to build some problematic code.
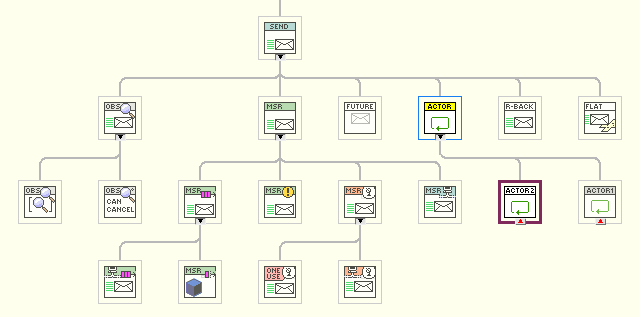
-
A related conversation I started was “Suggestion: A different class structure for Queues”.
-
1
-
-
I tend to agree; Send.vi is an invocation of the message transport mechanism -- Messenger.lvclass -- and Construct.vi (i prefer this terminology to Write.vi) is a member of a concrete instance of Message.lvclass -- something I realized a while back after naïvely convolving the message with the messenger.
This aside, i still want to impose 'Must Implement' on Construct.vi for Message.lvclass, yet it clearly cannot be 'Must Override' because message construction has a unique ConPane for each concrete message type.
It sounds like the overzealous parent class designer you describe is taking contracts to an extreme, and has crossed the line of "strategically-placed contracts to make the class easy to use correctly and hard to use incorrectly".But aren’t you in danger of being the overzealous designer, Jack.
You want to impose “Must Implement” of a “Construct.vi” on “Message”, a class that I don’t believe even has a constructor at the moment. And at least initially, you imagined this required constructor to be “Send”. What requirements could you have made at that point that were not, in hindsight, either blindingly obvious (“we need to construct our objects”), or overzealous (“must be called Send or Constructor”, "must have an Enqueuer input”)? You can’t enforce “must actually use this function”, so any error in requirements will just lead to unused “husk” methods made only to satisfy the requirements. — James
BTW: There is an example of this very thing in the Alpha/Beta Task example in 2012, where “Alpha Task Message” has two independent constructors: a “Send Alpha Task”, following the standard pattern (not enforced, of course), and then a “Write Data” constructor written when it became necessary to write a message without sending it.
-
Consider for Actor Framework, if Message.lvclass were to define 'Must Implement' on Send.vi (as it already specifies 'Must Override' on Do.vi). Do you agree this as a good use of the contract to make subclass creation more robust and even simpler? Does this example better explain my sentiment for wanting 'Must Implement'?
A good example, because “Send” being a method of Message has always looked wrong to me. Messages are written; sending is an action of a communication channel. The act of sending should be independent of the message type. I don’t want to implement Send.vi; I want to implement Write.vi. How will “Must Implement Send.vi” feel about that?
Also, what about messages that have no data, and thus don’t need a creation method of any kind? They don’t need to implement Send or Write.
-
I don’t know why that caused you problems, but always try and use the Default Data Directory for saved files, since you can rely on having write access even in an executable.
-
I do have an example of a parent-class restriction that I wish I could make. I have an abstract “address” object that defines a method for sending a message. The framework that uses this parent assumes that “Send.vi” is non-blocking (and reasonably fast). But there is nothing stopping a child-class being implemented with a blocking enqueue on a size-limited queue, other than documentation.
-
I am curious why you used the In Place Element Structure for accessing the sqlite3.dll?
One of the topics in the thread following this post by MattW is a possible reduction in performance due to LabVIEW needing to check if the dll path input has changed between calls. In this later post by me I explained why I switched to using an in-place structure:
"I found through testing that some of my subVIs ran considerably slower than others, and eventually identified that it was do to details of how the class wire (from which the library path is unbundled) is treated. Basically, a subVI in parallel to the CLN node (i.e., not forced by dataflow to occur after it) would cause the slowdown. I suspect some magic in the compiler allows it to identify that the path has not changed as it was passed through several class methods and back through a shift register, and this magic was disturbed by the parallel call.
This being a subtle effect, which future modifiers may not be aware off, I’ve rewritten the package to use In-Place-Elements to access the library, thus discouraging parallel use."
In the Execute Prepared SQL (string results).vi you didn't wire the EI/EO terminals on the Get Column Count.vi. I assume that was an oversight?Opps!
I noticed in the Pointer-to-C-String to String.vi you added 1 to the Length before the MoveBlock call, but elsewhere you used the MoveBlock directly the converted to a string. Additionally in the Pointer-to-C-String to String.vi you preallocate the U8 array, but not elsewhere. This is an inconstancy that's not explained. Could you elaborate on this?I really should document more. This was only my second “wrap a C dll” job, and the first time I’ve used “MoveBlock”. The issue is the fact that C strings have an extra 00 byte at the end and thus are one byte longer than their LabVIEW string length. I’m not sure I’m doing it correctly, but in “Pointer-to-C-string to String” I’m walking along the string to find the 00 byte, while in the other MoveBlock uses I’m getting the exact string length from sqlite.
Hm I'm very sorry. I made a demonstration project and there all works fine.Strange, I'll analyse my VIs.
Check that you are “reseting” any statements when finished (or you’ll be holding a Read lock on the database file), and that you aren’t holding an SQL transaction open (a Write lock).
— James
-
When inserting data into the database through producer consumer loops, the producer loop gets paused during the calling of the sqlite execution VI.
Could you post some code illustrating the problem? Or images of your producer and consumer code? I can only guess that your holding a lock on the database open somehow.
-
I wonder if anyone has ever saved Timestamps needing better than millisecond precision in a config file. That would be the potential issue with this suggestion.
-
AQ,
Good arguments for “Must Override”, but does that have anything to do with “Must Implement”? A child must still respect the requirements of parent code, but “Must Implement” tries to define what can be done for child-type static methods that are independent of parent code.
-
Hi,
You have a call to a missing xnode: "Minimum Array Size.xnode" in your “Toolbar.xctl:Set Toolbar Images.vi"
-
Then you're totally with the consensus on this thread.
So does this mean you don't use the 'Must Implement' flag? Or if you do, is it just strictly in the context of ensuring run-time polymorphism won't encounter an unimplemented method? (these questions are open to all, not just drjdpowell)
I assume you meant “Must Override”; I don’t use that much, but I’ve never had experience with writing parent classes for other designers to make children of, so I can’t really comment on that.
As far as “Must Implement”, I can’t really think of a good use. Child classes can be used for purposes that are different from what the designer of the parent class envisioned, so adding restrictions at that stage seems inappropriate. Especially ones that can be easily broken by adding a not-to-be-used extra methods (what icon glyph should we have on VIs never meant to be called but needed to satisfy misguided restrictions?).
-
Not to hijack the thread, but are you referring to the IPE structure here? I still use that a lot to minimize copies when manipulating large structures.
More than that. The IPE makes explicit what the compiler tries to do anyway: minimize copies. In fact, the IPE’s real benefit is as a guide to the programmer in writing code that can be done in place, rather than actually allowing in-placeness.
-
-
Thanks, it’s working fine now.
-
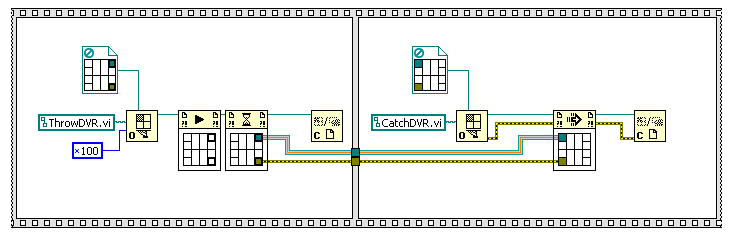
References deallocate when their owning VI hierarchy goes idle. When calling by reference synchronously, as your doing, the dynamic VI is running under the hierarchy of its caller. When one uses the asynchronous methods (“Run VI” or ACBR Fire-and-Forget) then that creates a new VI hierarchy.
Added later: using ACBR Call-and-Collect also creates a new hierarchy (I’ve not used it before); the following mod causes the reference to deallocate.
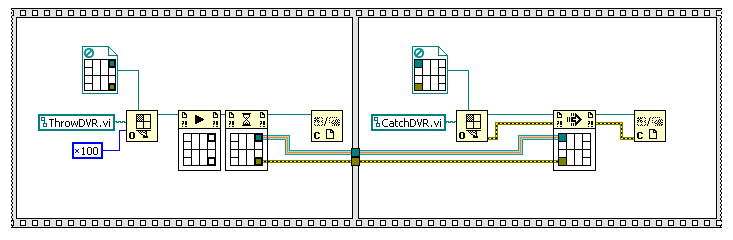
You can figure out what hierarchy a VI is running under by using “Call Chain”. With the original version, the call chain of “ThrowDVR.vi” showed it to be running as a subVI of the calling VI.
Error Handling in messaging systems
in Application Design & Architecture
Posted
I made one yesterday. Here is the only public API method, “Send Message with Reply Timeout”, which is identical to my regular “Send Message” method but with a timeout input and an optional input for the Timeout message to send:
Works by an asynchronous call of a small “watchdog” that waits on the reply and returns either that reply or a timeout message. It then shutsdown.
I should add that this only works for a system where the address to send replies to can be attached to the original request message. Hard to define a “reply timeout” without a defined reply.
— James