

drjdpowell
-
Posts
1,986 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by drjdpowell
-
-
It's all an issue of the lifetime of the original object. Forget there is even a DVR involved, this should not add anything to the mix. I would not expect this to change in future versions of LabVIEW as it would break too much code that relies on it (as this is not really a trick, it is an expected behaviour).
If you can guarantee the original object is still in memory then the DVR will still be valid. This is why I proposed trying to move the creation of this object (and thus the corresponding DVR) as high in the hierarchy as possible, somewhere that is always going to be in memory (so the top-level or one of its sub-VIs.). As soon as you have dynamically launched VIs this really does complicate things as the lifetime is now not well defined.
I could be wrong, but I do not think that there is a two way relationship between having an open DVR and the object itself. Although the DVR depends on the original object still being in memory, the converse is not true: keeping the DVR still alive (i.e. in memory) will not guarantee the original object is in memory, so it does not matter how you are storing your DVRs (on a wire, in a FGV etc).
Hi Neil, I don’t think that’s how it works. If you put a by-value object in a DVR, the data can’t disappear unless the DVR disappears. The DVR “owns” the object. Only if the DVR contains just a reference to something (another DVR, a queue, etc.) do you have to worry about its independent lifetime.
The DVR, like other references in LabVIEW, is itself “owned” by the top-level VI of the subVI that created it (I think this might be called a “VI hierarchy”), and will become invalid if that VI hierarchy goes idle. This only matters if you are sharing the reference between multiple VI hierarchies (such as by asynchronously-called VIs).
-
Check this conversation for info on the 2013 changes, and a subVI that can be used to fix the problem.
-
Hi,
I’m thinking of submitting my SQLite package in the CR to the tools network. Is “Team LAVA” still active?
— James
-
 1
1
-
-
Something stated in the white paper I referred to in my original post made me assume that I had to keep the object itself somewhere, such as an FGV, otherwise LabVIEW would remove it from memory. "A piece of data exists as long as it is needed and is gone when it is not needed any more. ... Copies on the wires exist until the next execution of that wire."
However it appears (from what I understand) that I should be storing ONLY an array of DVRs in my FGV because LabVIEW retains the actual objects somewhere else when I create the DVR.
Oh dear, I think that paper must be badly written, at least when interpreted from your background (and the “copies on the wires” part isn’t strictly true). The whole point of by-value dataflow is NOT worrying about object lifetime.
-
I was hoping readers would recognise that by saying "passing wires through the application" I was referring to a traditional LabVIEW programming methodology that had an increased likelihood of creating data copies when branching wires. The LabVIEW compiler is a very complicated beast and very few people would attempt to predict exactly when a data copy will or won't be made.
Yes, by-reference data allows one to be sure your not making copies. It can take a lot of experience before one starts to trust by-value data handling. Using in-place elements and always wiring straight through functions can give one confidence, even if those techniques are often unnecessary. But, a good by-value design can be at least as “copy-efficient”, if not more so, as a by-ref design even, while also having other advantages.
Some signals require data from others to properly analyse them. If the "ON" state has been defined as being relative to the battery voltage, then the analysis module reads the corresponding section of the battery voltage signal to compare it to the "ON" state. Some signals are "linked" to others such that they will appear on the same graph in the report. All of this means that I need access to more than one signal at a time. Again, I didn't want to delve too deeply into the complexity of my application.Still says “queue”. Queue the data to the central analyzer and have it retain whatever info it needs to interpret further data (like the last battery voltage).
— James
-
This is done in a separate low priority thread so the next test can be started without having to wait.
You can’t have your cake and eat it too. If you want a low priority process to wait till later then you have to retain the data it needs. If you want no copies, then everybody else has to wait for that low priority process to finish with the data before overwriting it.
In the example the measurement array is stored in a functional global to try and reduce copies instead of passing wires through the application.“Passing wires” doesn’t make copies. Even branching wires doesn’t always make copies.
It is built one measurement at a time to indicate how 15 different modules can all add items to the measurement array depending on what happened during the test.Your app says “queues” to me, not “FGV” or “DVR". Queue all the measurements to a central analyzer. Queues are asynchronous, so can’t stall your acquisition loops. Access to a FGV or DVR is synchronous, so to avoid blocking acquisition you are forced to make a copy for lengthy analysis.
From all your feedback it looks like I may not benefit significantly from moving to OOP. I'm not sure the added risk (me being unfamiliar with LVOOP) offsets the benefits gained at this stage.Your description of the wide variety of measurements that can be produced definitely suggests LVOOP. A low-risk path would be to just start using classes in place of whatever type-def clusters you are using for measurements. That will force you to use the encapsulation that will allow you to extend using inheritance later on.
Would the DVR point to the copy or the array element?To a copy. DVRs aren’t pointers; they have locking features that I don’t think could work for locks inside locks. Can you just use an array of DVRs to implement whatever it is your after?
-
Matze,
Can you probe to see what the pointer is when the error happens? The 1097 error happens if the pointer is zero.
-
Well, to prevent copies you must serialize access to the data. A DVR does that, but if you have already designed a structure that serializes access (Collect—>Analyze—>Graph—>Store) then you won’t gain anything by adding a DVR.
BTW, an easy way to reduce copies in your example code is to put the analysis logic inside the Functional Global (an “analyze" step rather than “get”). You can also serialize the graphing and saving.
A more major change is to not deal with all the data at once. Stream data to disk, and only read, analyze and present a subset at a time.
-
You don’t need the “Open VI Ref” dynamic-launch complexity; just use a static, strictly-typed ref (each one of which refers to a separate clone):
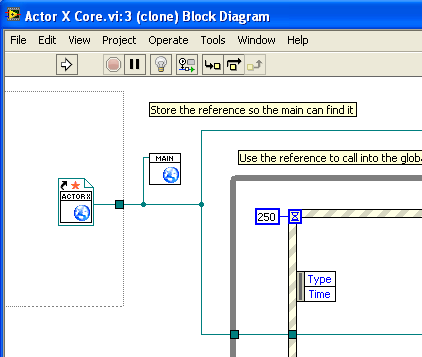
-
Google translation:
Error 1097 when Call Library node in SQLite.lvlib: pointer-to-C string to String.vi-> SQLite.lvlib: Connection.lvclass: Prepare.vi: 1 -> SQLite.lvlib: Connection.lvclass: Execute SQL.vi-> db_log_data.vi-> _Main.viSQL: "SELECT id FROM log_data ORDER BY id ASC LIMIT 1"Possible reasons: LabVIEW: There was an exception in the external code that is called by the node "Call Library." This exception may have caused errors in memory of LabVIEW. Save all projects to a new location and restart LabVIEW again.That error comes for the Call Library Node calling “MoveBlock” in “Pointer-to-C-String to String”. It’s writing into an array of bytes allocated by LabVIEW, so I can’t see how an error could occur. And I have not seen this error myself. Anyone else have this problem?
-
1
-
-
Which version of “Launch Actor” are you using? The newer version shouldn’t be closing the reference to “Actor.vi” at all (link).
-
How did they fix this? Given that the dynamic registration queues are independent of the static queues, how can events be ordered, other than by a timestamp of some kind?
-
Nicely done. I made a similar tool for my actor-like framework, and I experimented with something for the Actor Framework, but I couldn't see how to do it without changing Actor.lvclass (make a child class, of course!). Like the “ping” ability.
-
I am really leaning towards the DVR idea. Here is my reasons why:
I can allow multiple actors access to the database without them having to message a central DB actor. They can still serialize their execution using an inplace structure. I can perform error handing and retries within the DVR class and all actors can benefit from this (if I have to drop and reconnect the DB handle, when I release the DVR, the next actor gets the new handle because it is in the class data of the DVR wrapped class).
If at some point I do not want to do a DB operation inline, I can simply alter the class to launch a dynamic actor to process the call and then terminate when complete. Since the state data is in the DVR wrapped class, It will work the same.
Are you actually working on a DB actor or is this just academic? Because you are in danger of spending a lot of time on redundantly recreating features that the database software already handles (and probably handles better; for example, a DB will only serialize transactions that actually need to be serialized).
-
Here's my reasoning for why I think it is not.
In the Actor Model (AM) actors don't send messages to other actors; they send them to addresses. An address is an abstraction of the list of all actors who will receive messages sent to that address--an alias of sorts. Nothing I've seen in the AM indicates the list of actors the address refers to must be static. Actors can be added to or removed from the list during run time, but it's not necessary to send messages to every actor that currently has the address to let them know the list has changed. The change is handled automatically, sometime behind the scenes (such as registering for user events) and sometimes in code (such as a subscription manager actor.)
I disagree, if you mean you can update these lists of actors non-locally. For example, if Actor A launches Actor B, then only A has the address of B, and A cannot add B to any list of Actors held by any third actor, C, except via sending the address in a message. Having by-reference updatable lists shared between Actors is a definite violation of the Actor Model; the lists have to be by-value.
Note that you can build structure on top of actors that do subscriptions or channel-like message routing, but these must all be built on top of messages. No by-ref data sharing. My “Observer Registry” Actor, for example, in my actor-like framework, holds by-value lists of addresses, and everything is done by messages.
I say “my actor-like framework” because I can’t claim I don’t break the Actor Model rules, but I do try and know why I should be wary about breaking them.
Saying named queues aren't allowed in the actor model oversimplifies things. I could use a named queue and pass around the name instead of the reference itself, and that wouldn't violate the AM. The important thing is the actor doesn't know about it before it's supposed to know about it.That isn’t using the names as a global link, so that is fine.
If your Planet Killer missile system is designed so every actor needs to always know the address of the Self-Destruct subsystem, then I don't see anything in the AM that says you can't use a global address implemented in whatever way you want.Nothing wrong with not using the Actor Model for everything, but personally, I’d rather my missile not be mistakenly destroyed because of a bug is some forgotten unimportant subsystem that misspelled a queue name. If everyone needs to know it, then explicitly pass it to everyone.
-
Daklu wrote (about my mentioning “no global addresses”):
2b. That's an implementation detail and actually not a property of the actor model. It's a convention I strictly adhere to and I believe it makes code easier to read, but I can't claim it's a necessary part of AOD.
Actually, I think it is a property of the Actor Model (though descriptions of it are not very clear so I may be wrong); it’s part of something referred to as “locality", which I would restate as "instantaneous changes are local, and are transmitted through the system only via messages”. Being able to launch an actor and then have any other actor be immediately able to address it is a violation of locality.
Another important characteristic of the Actor model is locality.Locality means that in processing a message an Actor can send messages only to addresses that it receives in the message, addresses that it already had before it received the message and addresses for Actors that it creates while processing the message. (But see Synthesizing Addresses of Actors.)
Also locality means that there is no simultaneous change in multiple locations.
Unfortunately, “addresses that it already had” is too vague to definitively interpret.
-
BTW, a Database is not a good example to use for considering “actors”; a database is already well-designed for handling concurrent access, so someone reading may not see much value in introducing actors. Instead, how about a piece of hardware that can only do one thing at once, but may be needed by multiple concurrent processes. A part-handling robot, for example. An actor that handles all interaction with the robot can rewritten to mediate concurrent requests, perhaps through some kind of “transaction” system. Eg:
ProcessA —> Robot: “Request robot transaction"
Robot—>A “Transaction Started"
ProcessB —> Robot: “Request robot transaction"
Robot—>B “Busy; you are in job queue"
ProcessA—>”Do action 1"
<robot working>
ProcessC —> Robot: “Request robot transaction"
Robot—>C “Busy; you are in job queue"
<robot working>
Robot—>A “Action 1 Finished"
ProcessA —> Robot: “End transaction"
Robot—>B “Transaction Started"
etc.The Robot Actor would either refuse any “Do action” requests from a Process that doesn’t have an open transaction, or consider such a request as implicitly being equivalent to a combined “Request transaction; Do action; End transaction”.-
1
-
-
I am thinking it might be better design for Actor B to send the data to Actor A along with the next step it should do. That way Actor A only knows two things: How to ask for data and how to process data when received.
I would have Actor A attach some kind of token to its request to Actor B, that Actor B would send back attached to the requested data. This token would contain the next step for A to do. This way the code for A is all contained in A, and B can be more generic and service requests from multiple actors.
In the framework I use, which like Lapdog uses text identifiers on messages, I usually do this by configuring A’s request to relabel the reply from B:
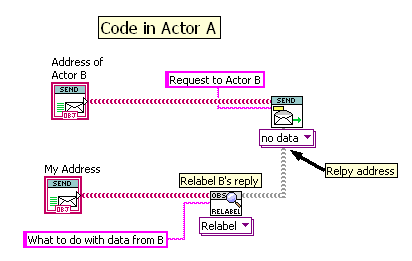
Here, A will receive back a message containing B’s data, but with the label specified by A (overwriting the label set by B).
-
Query: Isn’t it the DVR (or SEQ or other similar reference) that is an alternative to the Action Engine’s uninitialized shift register, rather than LVOOP? LVOOP is by-value, and you need something by-reference to stand in place of an action engine. The DVR is by-ref and can be shared among VIs with different con panes, in contrast to the shift register that is constrained to one VI.
-
1
-
-
For example, here's a screenshot from the 2012 QSM project template.
The thing that strikes me about that picture is, first, the fact that the queue has two writing processes, and second, that subactions of handling a message are treated as new messages for the queue. I agree with you about the problems of this, but don’t think that this is best communicated by arguing about how to define the differences between two very similar acronyms. I feel the same way about the “Action Engine”/FGV thing; it’s not really very productive.
I think it would be better to identify and talk more directly about the issues of message ordering and perhaps introduce more illuminating terminology, for example the concept of a “critical section”, or the database-transaction concepts of “consistency” and “isolation”. The “Initialize” transaction is a critical section, and because it isn’t protected as such it isn’t isolated from other transactions. Adding a different (non-FIFO) transport, that may switch the order of the two subactions, would also prevent it being consistent.
Note, btw, that a Get-then-Set transaction on a FGV/AE is also a critical section, and because it isn’t protected as such it isn’t isolated from other transactions. Thus, these concepts are more widely useful than the definitions of QMH/MHL.
— James
-
Rather than argue the difference between a queued message handler (built from from loop) and a message-handling loop (sitting behind a queue), would it be better to focus on the difference between a message queue with only a single enqueuing process, versus one with multiple writers in parallel that could lead to race conditions?
-
I still believe QMH is a poor name. It identifies the message transport's implementation--a queue. The transport's implementation is irrelevant to your definition of what a QMH is. Furthermore, I believe the transport's implementation is irrelevant to any well-written message handling loop.
A “queue” is different than a specific implementation of a queue, such as the LabVIEW in-built Queue. User Events also involve a queue, as do things like TCP or Network Streams and the like. In contrast, things like Notifiers do not. So, “QMH” does not specify the transport implementation.
Re QSM/QMH/MHL: I note that “queued-message handler” is ordinary English, while "message-handling loop” only makes sense if one understands the programming-specific use of the word “loop” to mean repeated code. “Queued state machine” only makes sense if one uses "state” in a very strange way that doesn’t have anything to do the state of anything. So I like “queued-message handler”.
BTW, one can make a QMH that is composed of a pool of MHL “workers”, so those two terms are not necessarily interchangeable.
-
Thoughts on just watching it:
1) More pictures; fewer words.
2) I suggest starting with the Message-Handling Loop or QMH (that people will be familiar with) and talk about what restrictions would make this an Actor:
— communicates with other code/actors ONLY via messages to this SINGLE loop. No by-ref data sharing or other communication methods.
— no global addressing (eg. no “named” queues)
3) mention “high cohesion and loose coupling”; an actor is a cohesive unit that is loosely coupled to other actors.
-
Thanks for the replies guys. drdjpowell, is my attachment correct? Reason I ask is it seems the tunnel went to "use default if unwired" automatically and I did not have to select it but usually I do.
Yes, that’s right.
LVOOP with DVRs to reduce memory copies - sanity check
in Object-Oriented Programming
Posted
It’s not a matter of “can be released”; all references owned by a top-level VI are required to be released as part of the process of going idle. This is a little-known but standard way LabVIEW treats all references. Changing this would break or introduce memory leaks into all sorts of old code. I use asynchronously launched VIs extensively and I actually find this feature very useful, though also quite complicating.