

drjdpowell
-
Posts
1,986 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by drjdpowell
-
-
bsvingen, are you using “singleton” in the same meaning as in OOP; something of which there can only very be one instance of? Because I don’t see how that is useful in something like a PID controller, which one might easily want multiple of. Do you perhaps use “singleton” to mean any by-reference thing?
-
thanks ,but can you post a version before labview2011?[/center]
As ShaunR’s SQLite package in 2009 was not satisfactory for you then I assume you need before 2009. In which case, “no”, as I use features of 2009 or more recent. You should be able to back save Shaun’s stuff, though.
-
Is there a link to the wiki from LAVA? Perhaps there should be a prominent one. I always forget the LabVIEW wiki exists, and had to Google it to find it.
-
Well. Decoding an N dim array is not that hard (a 1d array of values with offsets). But I'm not sure how you envisage representing it internally .
If you can give me a 1d array, and the dimensions to calculate the offsets, it will be easy to recursively convert to nested JSON arrays inside of JSON arrays (and it will work for any number of dimensions).
— James
BTW> One other issue that occurs to me is “ragged” arrays, arrays of other arrays of varying size. In LabVIEW, I would make a ragged array from an array of clusters containing arrays; in JSON, it would be just an array of arrays of varying length. I would probably try and add support for conversion between these types, too, if we’re going to support multi-D arrays.
-
It looks like it can be done with a little OpenG gymnastics (though not trivial). But this is making more work for you if you want to avoid an OpenG dependancy. How do you want to proceed with that?
-
I had not considered multi-dimentional arrays. JSON doesn’t have a multi-dimentional array type, but we could just have arrays of arrays. I will look into supporting it. Thanks.
-
Most of the patterns used in OOP design are build around the very principle of references. References to objects. How do you make a singleton without using some kind of reference?
Can you list some other examples? “Singleton” is the most obvious one, but Singleton is far more “by ref” than it is “object oriented”. Any non-reentrant VI is a singleton.
-
You appear to be able to use a global variable in the same way in a class, it doesn't create directly under the class but you can add it and set the scope to private.
I’ve used that recently. Though a private global isn’t really “global".
-
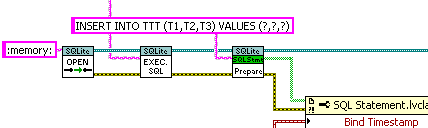
I like the idea of SQLite as well, ..., I think this can just operate in memory though
You can use SQLite entirely in memory by using “:memory:” as the filename. Also note that SQLite uses a caching mechanism that makes it effectively in-memory as far as reading goes, as long as the database is smaller than the cache size (2 MB by default).
-
 2
2
-
-
Property nodes are notoriously slow. There’s an advanced technique called “Defer Panel Updates” that can be used to speed things up.
-
2
-
-
You could consider a hierarchal structure of nested LVOOP objects similar to the one we used in the JSON package.
Another thought would be SQLite, though I have never done a hierarchal structure in it so it might be more complicated. But you would have the advantage of fast lookup on URLs and just about anything else you wanted fast lookup of.
-
I assume you have no control over the format of the message? Objects are best flattened/unflattened upwards from child to parent, which means the child information should precede parent information in the message. Your messages are the opposite. I suspect you can still parse it without “downcasting”. You’d have to generate a “type” object to call a parse method, but rather than set the private data of the parent type, the parse method would call further parse methods on the remaining bytes to actually return the subclass. So the parse method called on the “type” object would actually return a different object of the final subclass. Does that make sense? It’s a bit like the onion skin of recursion; instead of calling methods one after the other, you call them one inside the other, going all the way down to the final subclass, and then rising back up through the inheritance hierarchy setting the private data of each level.
— James
-
I need to install the latest LabVIEW version to look at your code, but some of what you describe sounds very similar to what I’ve done. My Transports are called “Messengers”, and I have “Actor” objects that contain a Messenger that is the method to send messages to a process running in parallel. But other stuff mystifies me. It sounds like you have message classes as the children of your Process classes; but aren’t messages and processes entirely different things.
-
Could you explain your use case? I’m having a hard time grasping what you are trying to do, so I can’t help.
-
Didn’t really follow the description of the problem (you’re sending message classes over a CAN bus?) but the fact that you have a reference (the CAN bus) that is needed by multiple processes (the zones) suggested there should be one dedicated process to encapsulate that reference. It shouldn’t be the Zone Manager because that has a well-defined job (managing zones) that is independent of CAN bus. So you need a “CAN bus actor/active process/whatever” that is the gatekeeper of the CAN bus and forwards all the messages.
-
[whatever]MQ is a great solution if you need to open communications with another programming language. But why take your messages out-and-back-in to LabVIEW environment if you don't need to? Sure, RabbitMQ was easy to install and configure for you... but what about the end user? Complex deployment = more difficult maintenance.
By “easy” I meant dead easy. Google instructions, run two installers, run LabbitMQ examples. Now, configuring a cross-machine, robust-against-failure message broker would be a whole higher level of complexity, but then John’s N-client, M-server system with the requirement of robustness is going to be complex regardless.
I couldn't agree more. Publish-subscribe messaging is an essential feature of many types of today's applications, and to do publish-subscribe messaging without events (or the equivalent) is pointless.
Can one do it the poor man’s way; have a reentrant subVI that waits on a Shard Variable and forwards message to a User Event?
Polling is definitely the right name here, and this kind of scheme proved to be quite messy for me as requirements evolved. I initially thought the only challenge would be dynamically adding and removing connections from the polling loop and efficiently servicing the existing connections. Before long, I had dozens of connections, some required servicing small amounts of data at rapid rates (streaming, essentially), while others were large chunks published infrequently. While the polling loop was busy waiting-then-timing-out for non-critical items, some critical items would experience buffer overflow or weren't being replied to fast enough (my fault for architecting a synchronous system). So I incorporated dynamically configured connection prioritization to scale the time-out value based on assigned priority level. I also modified the algorithm to exclusively service, for brief-periods, connections flagged as potential data-streams when any data would initially arrive from these connections.
This quickly became the most complex single piece of software I had ever written.
I wrote a TCP server the other way, using dynamically-launched processes, and it actually came together quite well, and seems scalable (though I have yet to had the use case to really test it). There is a “TCP Listener Actor” that waits for connections and launches a “TCP Connection Actor” to handle each one. The Connection Actors forward incoming messages to a local queue (or User Event). As each actor only has one thing to deal with, they are conceptually simple, and don’t need to poll anything (this is in my “Messenging” package in the CR if your interested).
An advantage of making your own TCP server is that you can customize things; my server is designed to seamlessly support my messages, which carry reply addressed (callbacks) and have a publish-subscribe mechanism. Supporting both with Shared Variables would (I suspect) be just a complex in the end as going straight to TCP.
— James
-
Well, that idea didn’t last very long...
-
We use networked shared variables and also ActiveMQ (an implementation of Java Message Service) -- via a custom LabVIEW interface -- for messaging much as John describes. ... John, you might want to look at the publish-subscribe approach. Isn't publish-subscribe communication really what you are after? That seems to me to be more or less what you are describing.
I played around with RabbitMQ a bit yesterday. Getting a RabbitMQ broker installed and running was quite fast and easy. LabbitMQ needs polishing and is lacking in documentation, but seems pretty solid. RabbitMQ should do publish-subsribe very cleanly, especially with its “topic” exchange type where one can specify the messages one wants by pattern. And at least according to the documentation, one can cluster multiple computers into a single message broker, providing redundancy against single-point failure (though with the possibility on failure of some messages being delivered twice).
— James
-
Thanks DRJDPOWELL for posting the notifier example. How would I correctly stop this VI? I tried adding a "stop" event case and I think only the producer loop stopped. I also tried adding a "release notifier" outside the same while loop, resulting in an error 1.
Release the Notifier in your “stop” event case in the top loop; that will cause an error in the “wait on notification" in the bottom loop, causing it to shutdown (since the error is wired to the stop of the loop).
I personally would remove this and the inner loop completely unless you really want that loop inside the consumer to execute as long as the switch is on.That was the use case of the original post; to start and stop listening on FIFO for incoming data. I use secondary loops like this for things I have to wait on, such as a TCP connection. If instead you want a second loop to execute commands from the primary loop, then you are better off using a queue. But you can still use the destruction of the queue in the primary loop to trigger shutdown of the secondary.
-
1
-
-
See this discussion, where I suggested the Actor Framework adopt mje’s mitigation of the issue (which he referred to above).
Wait, sorry. You mean for using VI Server for messaging, rather than dynamic launching of VIs. I don’t know what to do about that.
-
I still think this is a "half" solution. With variants, we should just be able to wire an output to an indicator and it should just do it without explicit conversion.
Well, currently they do let wiring to an indicator define the data type. Unfortunately it has to be directly wired, with no other structure in between, which limits its usefulness:
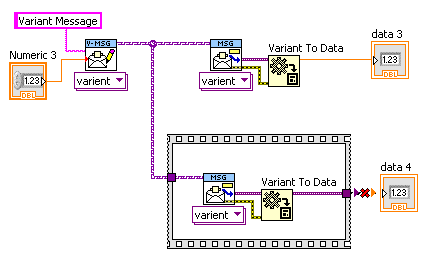
And you still need the “Variant to Type” primitive. But where would type-conversion errors go otherwise?
Also, the first thing I would do, if my idea was implemented, would be to make a “Variant to Numeric with Units” VI that would enforce matching units between the Variant and the supplied type. Your idea wouldn’t help with that.
-
I sure wish this worked with Variants. In fact, I may post that as an idea on the Idea Exchange; a “Preserve Run-Time Type” function for Variants.
-
That just creates a single point of failure. Something I cannot do in this system as the cost of it failing is expensive. I can live with one server going down or one client, but not something central to everything.
One thing to possibly look into is LabbitMQ, a LabVIEW wrapper of RabbitMQ, a message broker system. An already developed message system might have addressed many of your issues. Haven’t tried it myself (has anyone used LabbitMQ?) so I can’t tell how much effort it would be to set up.
— James
-
How so? I thought you can avoid the root loop when spawning as long as you hold a refnum to build clones off of for the lifetime of an application? Of course that implies at some point you need to open the initial target refnum, but if done at start-up, no root access should be required whenever you need to spin off a new process.
I was going to go into that, but bailed with a “…"
The end goal is a system where there are N servers and N clients. Each client can connect to N servers at the same time. Servers support N connections from clients simultaneously Servers 'push' data changes to the clients. Clients send commands to servers to control them.Maybe you should use a central message “broker”, with all servers and clients connecting via the broker. Then there is only one connection per process. I think Shaun’s Dispatcher works this way, if I recall right.
Is LabVIEW Object Oriented or Actor Oriented?
in Object-Oriented Programming
Posted
Yes, that’s how I (and many or most others) would do. I would have dynamically-launched VIs as “components”, which I think of as “parallel processes” or “actors”. I use LVOOP for the inter-process communication (“messages” and “addresses”), with each parallel process being represented by-reference to its LVOOP address object. The address is effectively by-reference because it wraps some communication reference like a queue, user event, or TCP client.
Note that an “actor” is effectively like a by-reference, asynchronously-accessed, active object, which is not the same as standard OOP objects in text languages, which are by-reference, synchronously-accessed, non-active objects. One can create the latter using a DVR in LabVIEW, but whenever I’ve considered using one I’ve always decided that stepping up to an actor is better (one concern, though, would be speed; straight DVR access will be fast compared with a request-reply exchange of messages via queues).