

drjdpowell
-
Posts
1,986 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by drjdpowell
-
-
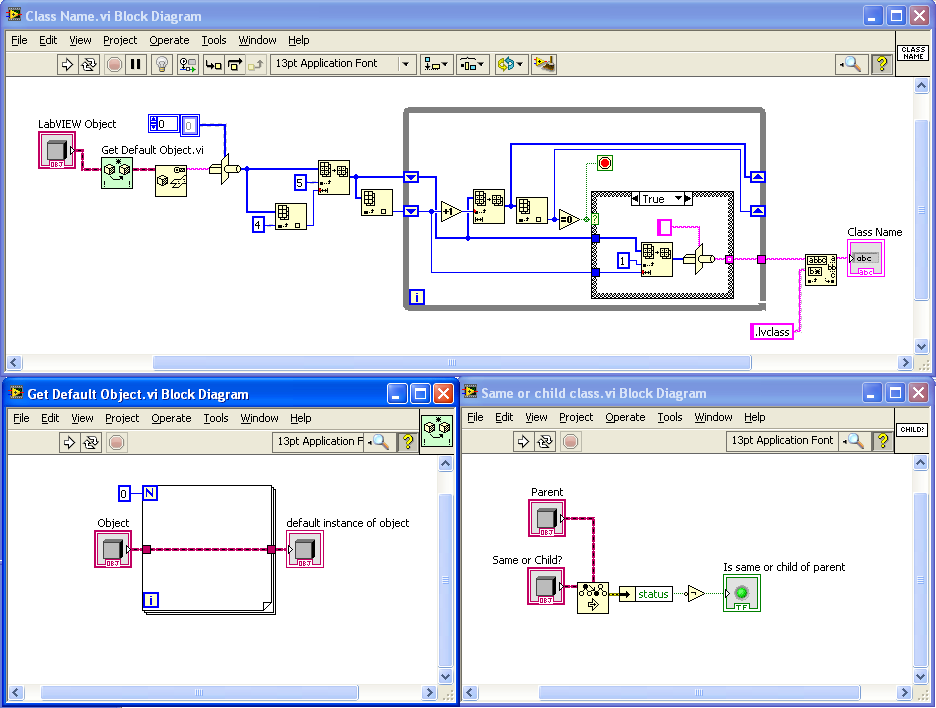
Here are the VIs after some work on icons and adding an additional function to return the fully-qualified class name. I’ve made the smaller VIs “inline”. I also changed “Get Default Object” to being based on “Preserve Runtime Class” as I found that the zero-iteration method sometimes didn’t work when in an inline VI (some detail of the complier that I don’t understand).
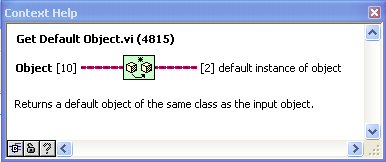
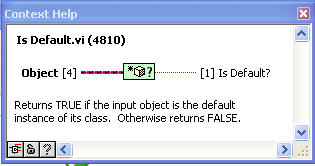
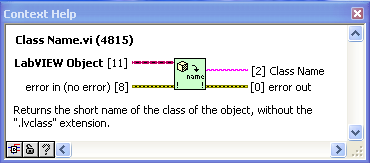
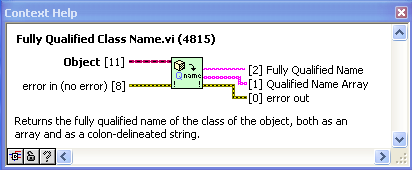
PS to jgcode> what is the next step in possibly getting these into OpenG?
-
 2
2
-
-
More reasons for me to finally upgrade from LabVIEW 8.6.
-
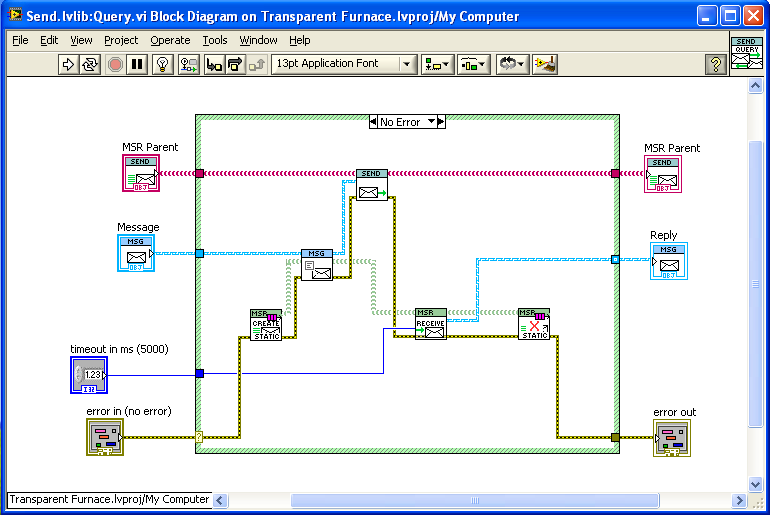
You should look into something known as a “callback”, though I just think of them as a “return address”. You make a method of replying to the message part of the message, rather than sending replies to a dedicated command queue. The process making the request can always attach its own command queue if it wants replies to return in sequence with all other commands; but it also has the option of creating and attaching a temporary response queue and waiting for the reply on that queue (destroying it afterwards). Thus you can use a callback asynchronously OR synchronously as needed. So you could Start module A, wait for it to reply “Done”, then Start module B.
Here’s what a subVI that does an synchronous send-and-wait-for-reply looks like in the messaging system I use:
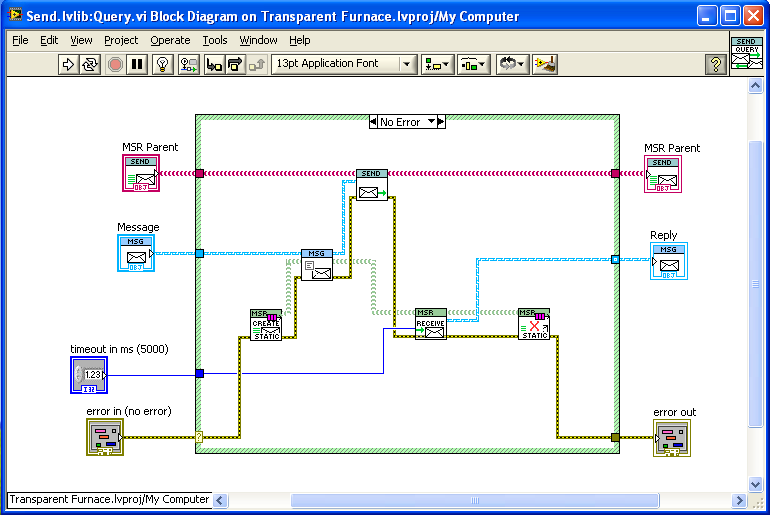
It creates a new queue, attaches it to the message, sends the message, and waits (with timeout) for a reply, before destroying the queue.
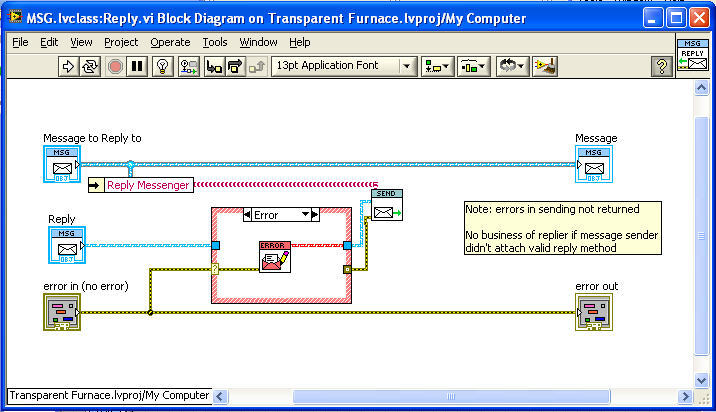
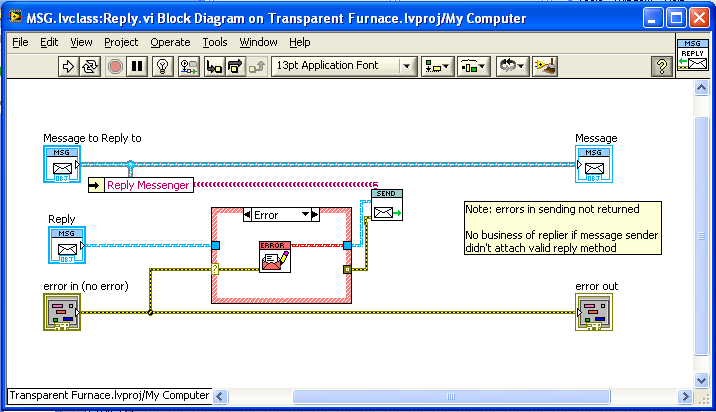
The process at the receiving end of the message calls the “Reply” method on the message in order to send a response back along the temporary queue (unless there is an error, in which case it replies with an error message instead):
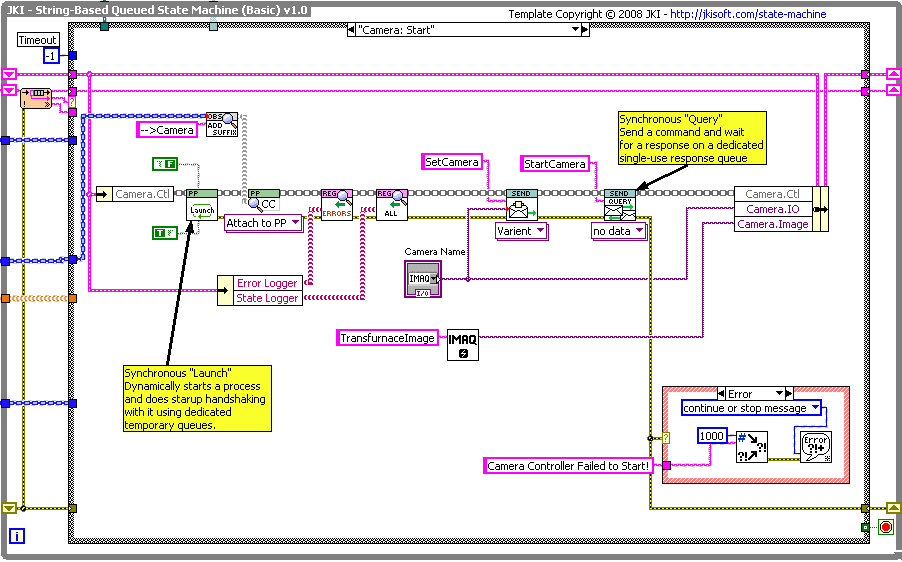
I use this when I start up modules; I send a series of initializing messages, with the last one being sent as a Query, where I wait for a repines from the module. For example, here is a startup of a “Camera” module:
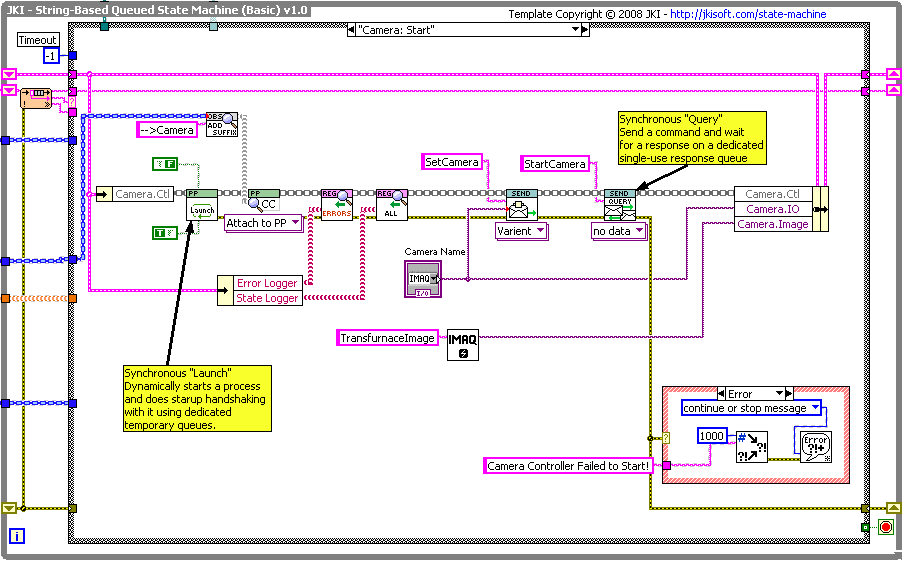
Ignore the details, but you can see a series of messages sent, with the last message being sent as a Query. I don’t even care what the response is, other than if it is an error (which is automatically sent out the error terminal).
— James
-
Works now. Great work! I must have a hundred times though “Why can’t I just right-click a child class?"
Suggestions off the top off my head (no idea how hard any of it is to do):
1) Automatically open the Properties window of the new child (as that’s always the next step).
2) On the popup that asks for the child’s name, have checkbox options for:
— copy parent class icon to child
— copy parent private data control icon to child
Usually the child needs icons that are modifications of the parents icons, so this would save a lot of cut-and-paste.
— James
-
1
-
-
I successfully installed it with VI Package Manager (no error), but I can’t find it, either right-clicking or under Tools>>LAVA.
Looking for the files, I seem to be missing a \resource\Framework\Providers\CreateChildClass directory. Other files seem to have installed.
-
1
-
-
Another possibility; seeing if the object is the default value for it’s class:
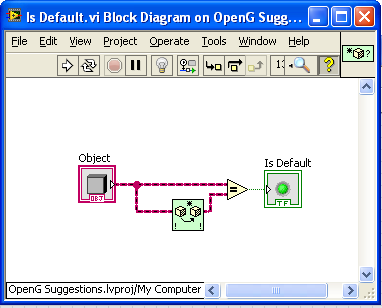
Maybe that’s too trivial. But the issue is code clarity; whether the icon is an advantage.
-
OpenG does contain 'simple' functions where people sometimes argue that it is easier to just code the nodes each time.
I am feeling the same with the proposed Get Default Object function as any time you are not using the LabVIEW Object you would have to drop the VI and cast back to the Object (to e.g. use method VIs).
No, it preserves the wire type, so no need to "cast back”:
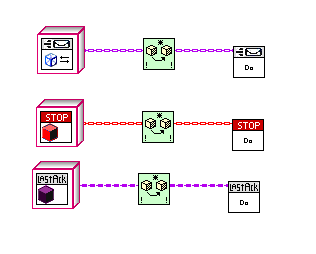 Unsure if I feel the same as above about Same or Child Class.
Unsure if I feel the same as above about Same or Child Class.Also thinking whether mje's Same Class test would be useful too?
There are stronger arguments against “Same Class” than “Same or Child”. Also, with the above suggested OpenG VIs, one can build “Same Class” functionality in a clearer way (Is the default type of each object the same? —> Same class, for example).
— James
BTW, what do people think about error terminals on any of these VIs? I’ve left them off.
-
1
-
-
Mike,
It returns the name of the class of the child object on the wire (in contrast to the “GetLVClassInfo.vi” that comes in vi.lib\Utility\VariantDataType, which returns the name of the class of the wire datatype, rather than the actual object on the wire).
-
- Popular Post
- Popular Post
This OpenG Review is closed. See Summary Post here. Please start a new thread to discuss new changes to this VI.
Read this post for start of review.
I’d like to suggest these three VIs (or similar) as possible LVOOP-object additions to the OpenG Toolkit:
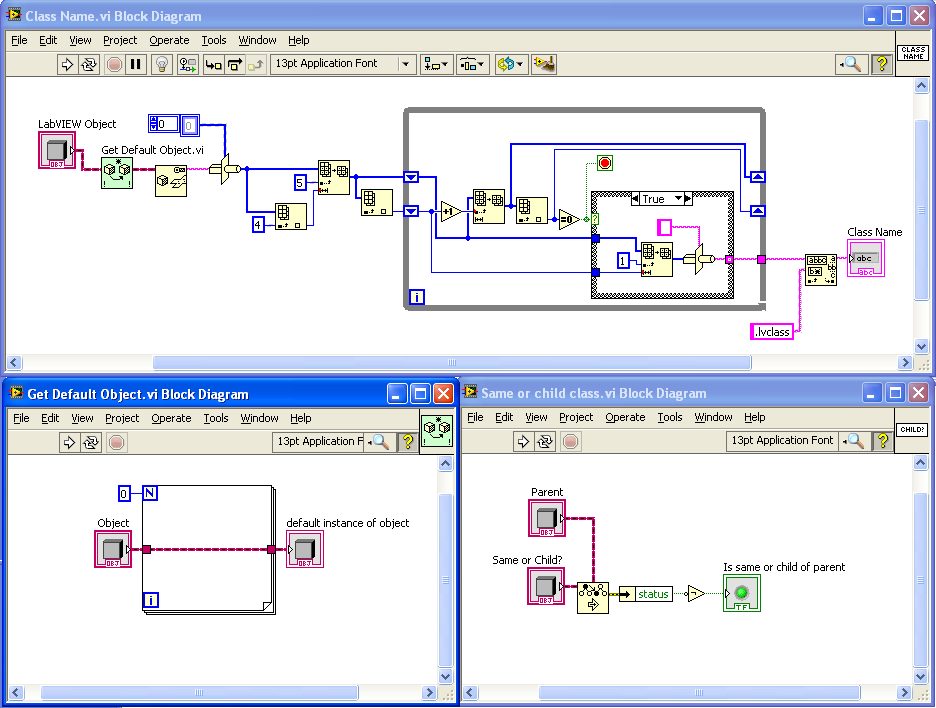
“Get Class Name” is a modification of “Get Name of Class of Object” posted by AQ. Here it just returns the basic class name (which I use often in custom probes and the like).
"Get Default Object” is inspired by this discussion and uses AQ’s zero-iteration loop method. This is a very simple VI, but using it instead of the raw code is much clearer to the reader.
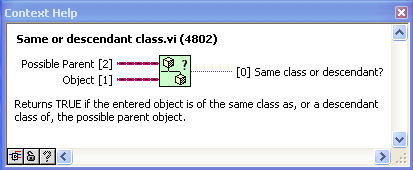
“Same or child class” just uses “Preserve Runtime Class” as a tester. Again, the advantage here is code readability (or it will be, as soon as someone comes up with a good icon for it).
Thoughts?
— James
-
3
-
I think going away from “one incoming message queue per message loop” would be a mistake. If your having problems on ordering shutdown, perhaps those can be solved a different way. How do you shutdown your processes? If you use a technique that tells all processes to shutdown at the same time (like a common global, say), than a better technique is to shutdown processes individually by sending individual “shutdown” messages to them. Send the shutdown messages in the order needed, and if necessary, wait for each process to acknowledge shutdown before ordering another to shutdown.
-
You've missed guentermueller's link.

Only skimmed it, but I didn’t think the connection between that link, and the problem of ignoring elements other than the first, is all that obvious (though it can be extrapolated). After all, it’s called “Sort 1D array of clusters by the second element”, the opposite of what the OP wants. Nor is it obvious how to adapt it to using a Variant to hold the set. But add a “creation index” as second element and one can use variant attributes as shown in the Maila nugget, which are faster than linear sorting.
-
How about making your second element of the cluster be an index that increments by one for each cluster added. Then your sort will never change the order except as required by the first cluster element; all other elements will be ignored..
-
Suggestion: Shouldn’t the “Get Name of Class of Object” VI get a default value of the object before flattening it? Since you don’t need the actual data flattened and it could take a long time if the object data is very large.
-
1
-
-
Three months later...
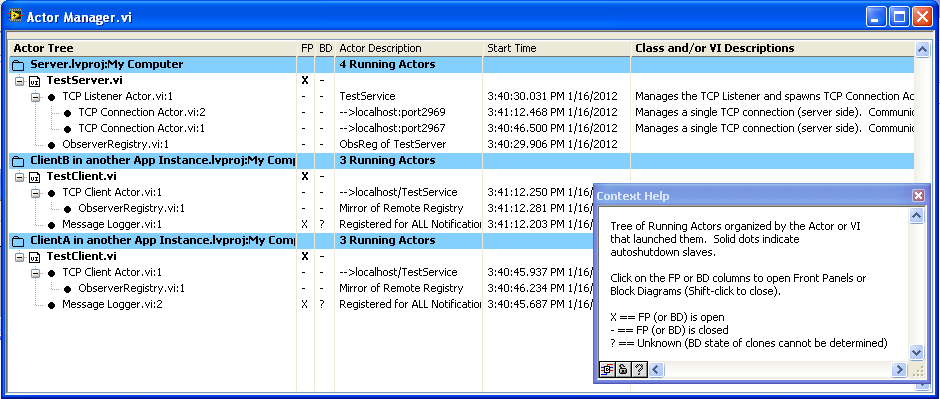
Thought I’d post on something I developed from Ravi’s Task Manager. I found I had difficulty using the Task Manager, not because there is anything wrong with it, but because the LVOOP-heavy framework I use has a ridiculously large number of subVIs loaded at any one time. The actual VIs that I’m really interested in are very few and are hard to pick out from the noise. And the massive amount of VI Server calls looking for all the potential clones of all these subVIs took forever. So in the end, I rewrote almost all of it to make it a very narrowly specialized tool that lists only the VIs I most need. These VIs are the core of what I call “Actors”, dynamically-launched VIs that communicate only through exchanging messages (here’s a post on an earlier version), so it’s called the “Actor Manager”. Here’s a screenshot where the Manager is observing three open projects, one running a TCP Server and two others as TCP clients (an earlier post on the TCP stuff is here).
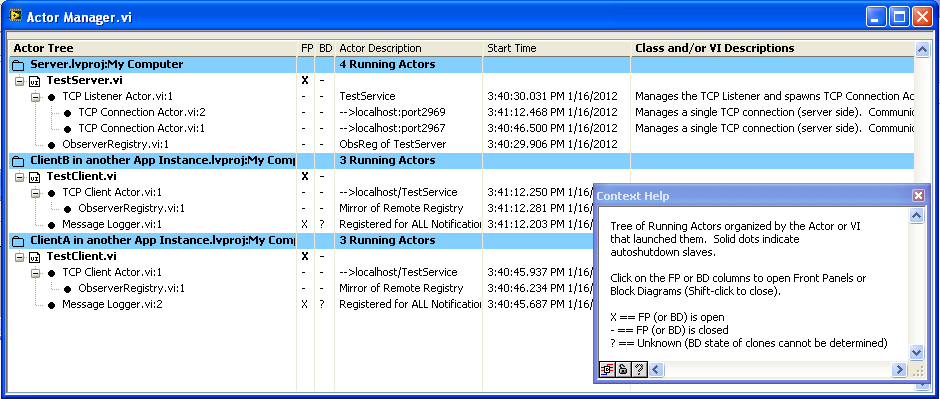
All the items with black dots are Actors, arranged in a tree according to who launched who. In the common launch code for actors, information about it, including what VI launched it and an optional short description of the new actor, is posted in a named notifier (name based on a clone name of a preallocated subVI used in the launch process, so that it is unique). The notifier remains in existence while the actor is running. The Actor Manager uses VI server to run a “Find Actors” VI on each open project; this VI searches through all possible notifier names. The search by notifier name is very fast, so I can search for clone names up to 10,000 on each application instance without taking much time.
So, this is sort of the same as the “Task Manager”, but also totally opposite, in that it is a completely specialized tool, useless outside of the framework it’s designed for, rather than being a generally applicable tool. But that narrow focus also allows it to do its specialized task very well (being able to clearly see the tree of who launched who is very important to me). For anyone else with a similar framework (“Actor Framework”, for example, or MJE’s “MessagePump”) I can recommend making a similar tool. It took me more time to do that it should have, because at first I was trying to maintain the generality of Ravi’s Task Manager while adding specialized features too it, but that proved too difficult. So I recommend a separate tool (and also use Ravi’s excellent Manager when a general tool is needed).
— James
-
1
-
-
JG,
Can you add a probe to a running VI, also? What about a clone VI? (I have a use case that would be valuable, and perhaps I’ll dive in to scripting.)
— James
-
Thanks for your replies, but I am unsure how to use this to solve the OP:
Sorry, I had mistakenly thought you were making custom probes, rather than wanting scripting access to the data retained on a wire.
I’ve never tried scripting, but just a thought: can one use scripting to connect a probe to the wire? I see from your last image that there is a probe reference that you may be able to set. If so, you could connect a custom probe and have the probe send (via a queue or whatever) the retained object on the wire back to the VI doing the scripting. Then you could use AQs code on it.
— James
-
2
-
-
I searched and found this prior conversation.
-
I don’t have enough experience to really comment, but…, this sounds overly complicated. References to ProjectItems already exist in labview as Refnums. True, they aren’t LVOOP objects, but one could easily do a simple wrapper (Library object contains a Library Refnum, etc.), allowing dynamic dispatch of new functionality. Projects and Libraries can be simple by-value collections of Project items. So what are these DVRs for? Why does a Project item need references to it’s callers? And why can’t it just have a by-value collection of its subitems?
I understand the need to not duplicate things like HTML pages, but that functionality can be hidden down deep rather than complicating the higher structure. Just have “Generate HTML page” look to see if the page for this item already exists and only generate a new one if it doesn’t.
Anyway, I may not understand what you are doing, but it does sound complicated.
— James
-
- Store the owned object directly in the owning class. When I unbundle the owned object, compare against its default value to see whether it's actually there. There are problems with this, though. If I change defaults in the class definition, they aren't reflected in any constants I've placed on the block diagrams of calling methods. I may also need to use the defaults as a valid configuration for the owned object.
Do this one. The default object will always update to reflect the class definition (I’m pretty sure, please correct me if I’m wrong) as default objects don’t save values, they just point to the class definition. To get around the second problem, always have a parent class that is “virtual”, meaning that only child objects are ever actually created and used. Then you can use the default parent object as “null”. Having a virtual parent class is very useful for lots of other reasons, so it is usually good to put it in regardless.
— James
PS, here is your example, modified to make “Config” a virtual parent, overridden by a ConcreteConfig class, and eliminating the DVR:
-
2
-
Strangely, I couldn’t get it to work again with reentrant settings. But I did get it to work if I changed the Read FP Controls and Read Signaling Property VIs from Dynamic dispatch to Static. But I don’t understand why that would be. I’m afraid I mostly use LabVIEW 8.6 and have minimal experience with DVRs and Class Property nodes. So it’s just trial and error. Try making you accessors static dispatch.
— James
-
Another suggestion:
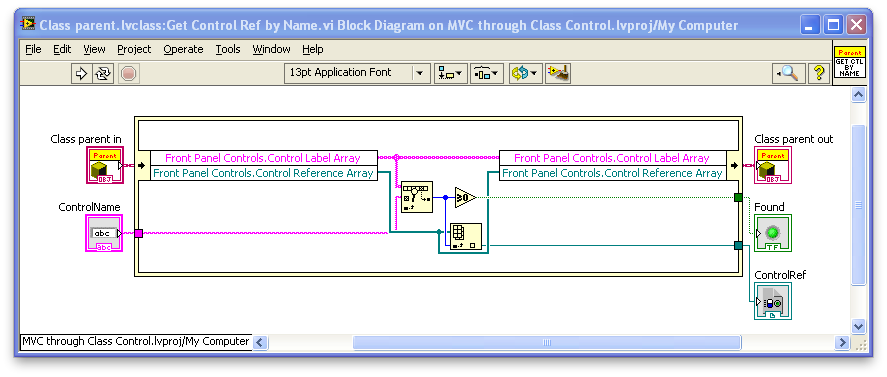
Your current accessors use some repeated code that should be in subVIs. Also, you want to make all these VIs as fast as possible. Consider using a method like this:
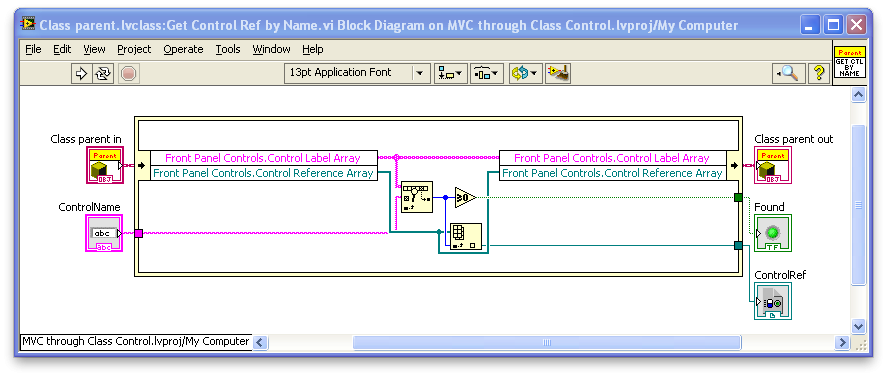
This looks up the control reference by name without making a copy of (potentially quite large) arrays. Your current method of reading the arrays by property node makes a copy. Also, having the code in a subVI will allow you to eventually upgrade from a linear search to a binary search method that would be much faster for large arrays (a good reference if you want to do this).
Oh, and make methods like this static dispatch, rather than dynamic, if they don’t need to be overridden (less overhead and you can consider making them “inline”).
— James
-
My fault, I should have tried 7z instead of whatever Windows XP uses as default.
Had a quick look. Only useful comment yet is that all your property VIs are non-reentrant. Using "reentrant, share clones” setting on your property VIs may solve your “recursive call” problem. I switched Child1 Write Power to reentrant, share clones, and ran its “Main” UI without error.
— James
-
I’m afraid I got a “The compressed (zipped) folder is invalid or corrupted” error when I tried to unzip your attachment; could you try again?
-
Well, first, I’m assuming this is a learning project, rather than having motor control as the main purpose (if not, say so, because there are much better ways to control a stepper motor).
I can’t run the code because I don’t have the 2011 DAQ stuff installed, but looking at you VI I see that you have cut-and-paste the complete code from a DAQ example several times into the outer timed loop 16 times. Because this example itself has a continuously-running loop in it, and doesn’t stop running until you hit its STOP button , the outer timed loop never finishes its first iteration, because the code inside it never finishes.
You would be better off making a copy of a DAQ example VI and then try to modify it to suit your needs. There is probably an example that controls N lines for N samples at a specified rate; that one might be the best. Avoid loop-inside-loop until you have more experience, and learn to create a subVI as an alternative to multiple cut-and-paste.
Hope this helps,
— James
BTW, these types of questions might be better posted on the NI.com LabVIEW board; many more potential respondents.
Master/Slave with Event Structure and Notifiers
in LabVIEW General
Posted
My first thought is that you have a race condition due to the two parallel loops both writing to the same lossy communication channel (notifier). If you want multiple writers you need a non-lossy method, like a queue.
The way I usually prevent the User pressing multiple commands is to lock the UI out while a command is executing, either just by the “Busy” cursor, or by disabling all invalid controls.
— James