

drjdpowell
-
Posts
1,986 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by drjdpowell
-
-
Hi Shaun,
Can you clarify the “fair use” of your database logger (and SQLite API)? I’d like to use it (or a modified version) as an error logger in custom software projects for clients.
— James
-
Could I put the downcast into the Command class Do.vi and then override it for all my child Do methods? I have trouble understanding the override in general vs. the Dynamic Dispatch.
You could make a new non-dynamic dispatch VI that takes a Message object, downcasts to Command, then calls the (dynamic-dispatch) Do method. Call this VI “Do Command”” or “Do if a Command”, or something. Note that it doesn’t need to be a member of “Message” class (or any class).
— James
BTW, you could also make the “Do if a Command” VI return the original message if it isn’t a “Command” (this output would return a null message if the command was executed). That would allow you to put it in front of your case structure, acting sort of as a filter for Command Messages.
-
Hi Alex,
One slightly annoying thing at first about LVOOP child classes is that they cannot directly access their own “parent” data via “unbundle”. All child objects have the parent private-data cluster, but methods of the child class need to access it via methods of the parent class. If you create VIs in the parent that return InputQ and OutputQ, then the child class VIs can use them instead of unbundle. Creating “accessor” VIs like this is automated, so it takes less than a minute to make several. One can even make them be usable in a Property Node structure to access several things at once.
The reason for this, I believe, is to allow the designer of the parent class to have a well-defined public interface, and thus he/she can change the internal private structure without breaking any children written by other developers.
-
James.
The CLA exams don't target code (you can use the same UML for both right?) and I'm not sure what you could take away from it. But sure, if you have an example, post it.
I’m afraid I’ve lost the code itself (computer failure and I never checked it in to my code repository), but I have an image:
This is the CLA practice exam, rather than CLD; those subVIs are mostly empty but for a single comment on what needs to be coded in them.
-
I am reminded of one of my first posts on NI.com:
I haven't done the CLD myself, but this conversation prompted me to look at the Traffic Light example exam, along with the NI-supplied sample solution. Although I'm sure it follows standard "style", IMHO it is a pretty poor attempt at the described problem, at least if this were to have any connection to a real-world problem of programing a traffic intersection.
1) Real-world intersections come in many different configurations, but the solution presented is inherently specific to only one very-specific configuration with no thought applied to producing software that can be customized. Every different intersection type would require a different version of the code. A fully general solution is too big for a four-hour test, but one could at least set the groundwork by having some "intersection configuration" constants feeding into a more generalized intersection state machine. It would be easy to write code that could be configured with an arbitrary number of lights and states by using arrays, for example, allowing easy generalization to a five-way intersection.
2) The solution ties together the implementation of the intersection state machine and the implementation of the specific type of light. If traffic engineers were to start using four-bulb lights (Red, Y, G, and Left Turn Arrow) then the entire intersection code would have to be modified. The code should be more "modular"; there is no reason why a programmer implementing a new type of light needs to delve into the details of the intersection, nor does the intersection programmer need to know which specific light bulb signals "Left Turn".
The clean coding and extensive documentation is nice, but useless if the code becomes obsolete the instant it confronts the first real-world complication. Admittedly, this is just a test question constructed from a predetermined answer, and the test-taker should be able to guess what the test makers really want in place of an actual scalable design.
This was pre-OOP for me, but you can see how LVOOP might help in points (1) and (2). Problem is, it’s an exam question; any kind of investment up front for pay off in future development is a waste of time because there is no future.
— James
BTW, what about CLA exams? I tried out the practice ATM exam for that and used LVOOP.
-
Ben, small note:
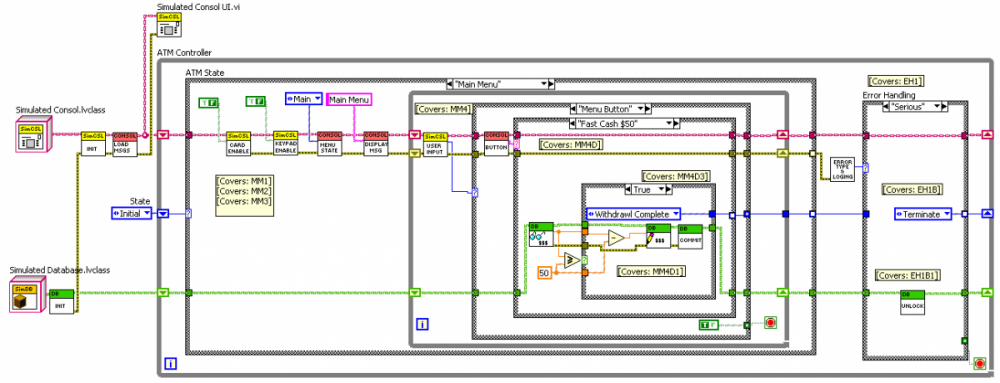
I see in one of your images that you index over your array of Instruments and individually configure an Observer to substitute a message and then register this Observer with the Metronome. You’ll have less overhead if you take the entire array of instruments, create a single Observer, configure it to substitute a message, and register it. Observers can hold any number of “Send” objects internally. To make your array into a single Observer, use what is now called “Create Observer (polymorphic)” but was then called something like “Make Observer” or “Add Observer”.
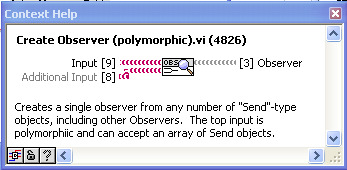
Another small note: There is a bug that is a problem for a feature that you might not be using but should know about. For Variant-type messages, one can not fill in the label and let the message use the variant data name as the label. But a bug in converting to variant sometimes doesn’t take the right name:
-
I found that I the default way of launching a parallel process using the path of the class did not always work for me. This is because I dynamically loaded a child class onto a parent class string.
The new version uses the VI qualified name, rather than the path. Hopefully, this will work better.
Also, when I noticed that you had this Specify Process.vi I started looking around more in your code and seen that there are a LOT of other very usefull VI's that are not indicated in your tree of vi’s.Some of those are experiments, since this framework kind of grew over time through trial and error, so be careful.
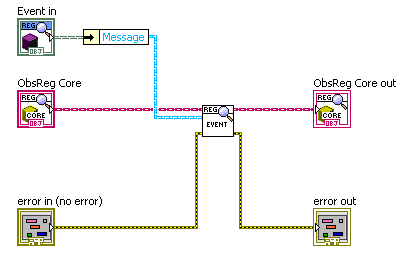
On another Note, I really haven't completely understood how to harness the power of your event registers, or should I say the ObserverRegistry. For example, I am not really getting why that you create Observer Registry in every parallel process and why you seem to notify every time a state executes in the parallel process. Or even what the difference is between Notify State and Notify Event.There are two ways that one can get information out of a launched Parallel Process: (1) having it respond to a message sent to it, or (2) “registering" with it to have “notification” messages sent whenever something happens (an “event”) or the state of the actor changes (“state”). These are separate methods; one could probably just use one or the other. My examples are perhaps overloaded with trying to do both, and that might be confusing. But then, a reusable component may be more useful if it can communicate in a variety of ways. I actually tend to rely on the Observer Registry stuff primarily, but having replies can still be useful, especially for synchronizing things (as you do in your application).
What I imagine the Notify to be used for is that if you send a message with a certain name, you can register other Observers to "catch" that message also.Exactly. Note, however that this is NOT a global thing like a named queue or global variable. To “register” to receive a notification one must send a registration message to the Parallel Process in question. You do this in your App when you register for “MetronomeTick” events.
An “Event” is, well, an event. ”Tell me when this happens”. “MetronomeTick” is an event.
If you look at the “Metronome” Block Diagram as an example, you’ll see that you can also register to receive Error Messages, and the “Shutdown” event which is the last thing sent when the Metronome shuts down.
A “State” Notification is slightly different. Here, you don’t want to be told when something happens in the future, but what something is right now, and to be notified of any changes. Metronome has a “MetronomePeriod” State notification. If you were to register to receive this notification, you would immediately be sent a message containing the current period (the Observer Register remembers the last state message so it can notify any new observers). You would also be sent a message any time the state changed.
What happens when you have a lot of notifiers in the code, but nothing ever listens for the notifications? What happens when you send messages, but nothing recieves them?Nothing happens. Neither “Notify Observers” nor “Reply” throws any errors if no one is listening. If you launch an actor and don’t subscribe to its published notifications or bother to listen to its replies that is not the responsibility of that actor. It is the job of the code launching the actor to decide who should receive messages from it. This is a deliberate design choice; actors are reusable components that are not coupled to the code that launches them. They don’t demand anything and only provide services. If you don’t use all the services… whatever.
In your code, for example, “Metronome” attempted to reply to your “SetPeriod” message, but you attached no return address. It also published its period and a shutdown message, but no one asked to be notified of them. No problem, “Metronome” doesn’t mind. It stands ready to provide these messages, should the code that launched it want them. You could, for example, register your UI to receive “MetronomePeriod” state updates so you could display the period. Or you could change your “SetPeriod” message from a “Send” to a “Query” (that waits for a reply) to check that Metronome did what you asked (if you try to set the period less than 10 ms, for example it will comeback saying 10, because that is the lower limit). Queries are good for making sure something has happened before continuing; if you sent a “SetPeiod” message by accident, the reply would be the Error Message “Unhandled: “SetPeiod””, code 52. This message would also be published to anyone registered to receive error messages.
Is it good programming practice to when there is a reply message in the parallel loop, should there always be a NOTIFY attached to the message?Not necessarily. My simple examples mostly involve commands that change the actor’s important state (“SetPeriod”, etc.), so they naturally involve a Notify. But one could have commands that don’t change state, or the state can change for some reason other than a command. And it is OK to have actors that don’t have an Observer Registry at all, if that isn’t really needed.
— James
-
 1
1
-
-
Hi Ben,
It’s late where I am, but I’ll try and reply tomorrow, particularly with a better description of what the Observer Register is for. Your code looks good.
— James
-
I must need an AF-Lite...something that allows you to launch an actor, get the queue from it, and then send it messages to tell it what to do. That's it, something a Hard Drive, Air Conditioner, and Fire Suppression can all do: message = start fan, message = increase speed...
I understand having a dynamic dispatch for different types of fans but why does Fan need one for different types of fan callers? I'm missing something fundamental here aren't I?
I too didn’t like that “Low Coupling Solution”. I spent some idle time trying to think of a way to make the “Zero Coupling Solution” simple enough that one wouldn’t ever need to consider the “Low Coupling Solution”. After I while I realized: it already is simpler! Not trivial to see at first. So I think it would be better if the documentation never mentioned the “Low Coupling Solution”, and instead concentrated more on demonstrating how to do zero coupling, and presented it as the standard way to use the Actor Framework. In fact, with a simple guideline, one could write “High Coupled” actors in such a way that they could later be easily upgraded to zero-coupled actors. I’ll try and get this suggestion, with more detail, in the 2012 beta forum (once I’ve figured out how to download the beta software
 ).
).— James
-
Two words: Job Security.
Need to get me some of that some day.
-
From my understanding, LVClass refnums could not possibly work in run-time environment. A LVClass refnum is a reference to a ProjectItem. The project doesn't exist in run-time so how could this possibly work. Help clearly states for LVClass.Open invoke method 'Available in the LabVIEW Run-Time Engine: No'.
Therefore, the basic information needed to grow our own XML Serialization routine is unavailable in run-time. I think sufficient information would be class version and parent class name. These are available through the flatten-to-string (or xml) methods ONLY if the object is not of default value. I've attempted what drjdpowell suggests above: 'one could make a VI that flattens an object, and then fills in the missing default pieces', but I can't find a way to assemble missing pieces without these vital bits of information.
That’s what I thought, but AQ stated:
You must be using an old version of LabVIEW. They started working in RunTime in LV 2010. I would NOT recommend using them -- they are VERY slow, because they aren't meant to be used in production code (they instantiate entire projects behind the scenes because they assume you're getting one of these references in order to do manipulation of VIs into or out of libraries or to query about project layout stuff). They should be used for scripting and tools work, not for the actual work of your application. The only reason that they're in the runtime engine is someone wanted to be able to do reflection of projects from TestStand without needing the full development environment.
-
Note to Darin on in his Champion’s profile picture: I recognize that hardware! Axions! Or search therefore. Did a very little bit on it as a Post Doc long ago. I’m very, very least author on an axion Phys Rev Lett from 1998 (I see from my CV that you're second author). Found those things yet?
— James
-
Yes, I spent a lot of time trying to use the references to work with XML even back in 2009, but they don't give you what you need, at least not in the run-time environment.
I was under the impression (from a post somewhere by AQ) that lvclass references work in run-time as of 2010.
-
Oh good! Having to put those terminals in was annoying. I second the suggestion to go without the terminals. Though we might want a temporary note in the VI descriptions and/or on the block diagrams explaining this issue.
— James
-
You can also do this with subVIs
Oh, man… The number of times I’ve double clicked on a subVI, double clicked on its icon to bring up the editor, made a copy, closed the editor, opened another VI’s editor, pasted. What a waste of time!
-
1
-
-
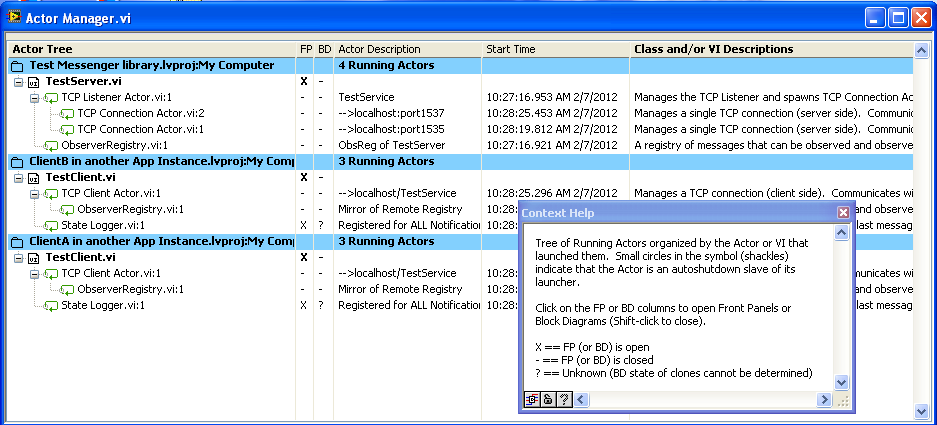
Oh, the new version will also contain the “Actor Manager” (I’ve started to call my “Parallel Process” things “actors”, it’s a lot shorter and is an established computer science term) which makes knowing what’s running, and accessing the Front Panels or Block Diagrams, much easier.
Below is a tree of actors running TCP communication tests (same computer, but three different projects):
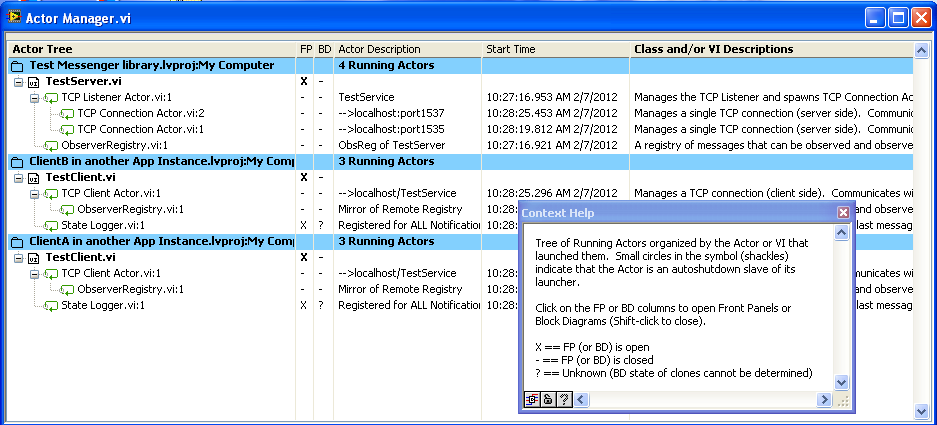
If one tries something complicated, with umpteen copies of “Observer Register” or “Metronome” used in different ways, this really helps diagnostics. As does being able to quickly open the Block Diagram of any actor and place the “MessageTable” probe to observe the incoming message stream.
— James
-
Hi monzue, thanks so much for your highly positive feedback! Gives me the impetus to push forward and get a new version in the Code Repository.
I wasn’t aware of anyone using this, and I apologize in advance as updating your code to use the new version will involve a couple of tedious hours tracking down and replacing VI’s that have moved/been renamed/put in a different library. I’ve done a lot of reorganization. It looks scary the first time you open a VI that can’t find some of its classes, since all the class methods show up as question marks, but it is usually easier than it looks to fix by just replace the missing class constant, with all the methods magically reappearing. I promise to make the next version more finalized so you don’t have to do it again.
Alternately, feel free to take the previously posted version and build on it to make it your own. The new version will have the TCP Messengers shown above, though, which is a major new feature if one has a distributed application (unfortunately, I don’t have a distributed application at the moment to really test it on). It will also have the above "Asynchronous Dialog box” and Futures.
BTW, what LabVIEW version are you using? I have recently upgraded from 8.6 to 2011, and I was going to use the new “Async Call by Ref” node of 2011 in place of the “Run” method for launching VIs (this has very important performance advantages), but I could try and keep a separate 8.6 version available. It’s more (unpaid) work for me, so I need to know if there’s a need.
Thanks again,
— James
BTW on the Actor Framework: My Messenger library is the work of a lone programmer who’s interested in easy use of dynamic VIs talking to each other. The Actor Framework comes from a very different perspective, that of a framework for a diverse team of programmers working on a large project, where restrictions are needed to prevent hard-to-see flaws compounding into severe problems. I don’t have the multi-programmer experience to analyze my Messenger library from that perspective.
-
Lastly, JAMES, I have enjoyed your hassling with Stephen on the Actor Framework forum
 I love the idea of the AF and he must be quite a scientist to have created it. However, it seems on the verge of too much "safety" at the cost of usability, especially when introducing it into existing code. I hope the discussions there result in some small modifications to lower the entry barrier before it gets plopped into the <vi.lib> for eternity. LabView will always be a coding toolbox for the engineer and the tool sets need to be somewhat flexible. IMNO (newbie).
I love the idea of the AF and he must be quite a scientist to have created it. However, it seems on the verge of too much "safety" at the cost of usability, especially when introducing it into existing code. I hope the discussions there result in some small modifications to lower the entry barrier before it gets plopped into the <vi.lib> for eternity. LabView will always be a coding toolbox for the engineer and the tool sets need to be somewhat flexible. IMNO (newbie).Not trying to hassle AQ. OK, a hopefully constructive hassle. One problem with complex designs is that people rarely take the effort of digging into them enough to make a constructive criticism of them. I was lamenting that fact one day (since I have complex design posted here myself) and I thought I really should make an effort. I’d be happy for AQ to point out the security flaws in my own, made by lone developer with an eye only for flexibility, designs. Or of other worthy ActorFramework-like targets, like mje’s “MessagePump".
— James
-
Is what I am doing below considered the Command Pattern?
Ah yes, this makes a lot more sense. It does appear to be the command pattern. Call your “execution” class “Command for <name of class command is for>” and your “children” “Command A”, etc. Your dynamic VI dispatches off of the Command child class, but the actual work is done with methods of the class the command is for. Here is a command-pattern execute method of mine, looking very similar to yours:
Note, btw, that one can put needed parameters inside the command object, such as the “Message” in my example.
— James
-
I want to select a dynamic VI to execute and modify the parent data based on an index value.
Still not understanding. The dynamic VI to execute is determined by the class of the object passed along the wire. It almost looks like you are trying to change the class of the object coming in through the “Parent.lvclass” control terminal. Or that you want to be able to call the VI for ClassA on an object of Parent Class. One can’t do either off those things.
-
The difference between objects and wire data types, and the different possible meanings of “coercion”, can be rather confusing.
-
Hopefully the image explains my question pretty well.
Not really, I’m afraid.

The “too more specific class” function only affects the wire types. Your saying “stuff the object on this parent wire into this child wire, if possible”. But though your selector returns a child object, that’s at runtime, not edit time, where the wire type out of the index array can only be the parent wire. So “too more specific class” isn’t doing anything here.
Does that help? I can’t actually tell what you want to happen. Actually, what are you using to get the name of the class in your subVI? Is that what isn’t working?
— James
-
We have inevitably run into two road blocks.
- The “default” issue mentioned above. There is no reasonable way, to my knowledge, to deal with this issue.
- Access to type information (especially to build an object from XML data). In the thread mentioned above, I sought the default value of the class. This is actually not sufficient (at least not in the form we have it). What we need is access to the class data cluster (i.e., be able to assemble a cluster of the proper type and values)--and then be able to write the cluster value to the object. I don’t think this is currently possible.
What about using the LVClass references (like here) to determine the default object’s data clusters? AQ says that LVClass references are very slow, but, one could keep a look-up table of the needed information inside the Flattening VI (i.e. each object type needs to have its default info determined only once). I was looking into this stuff a few weeks ago, and it seemed to me that one could get around the “default” issue this way. Then one could make a VI that flattens an object, and then fills in the missing default pieces. One could also make VIs that alter the cluster values this way (I was actually thinking of making a VI that could take objects of different types, such as parent/child, and copy from one the the other all the common levels of cluster data).
I never did any actual tests, so there may be a roadblock, but I think LVClass references can give one the information one needs.
— James
- The “default” issue mentioned above. There is no reasonable way, to my knowledge, to deal with this issue.
-
I'm glad to hear the messaging system can be so fast if done properly.
Who you calling fast? That’s the first time I measured it and I thought it was slow. Something built for speed would be much faster. But Property Nodes, and anything that runs in the UI thread, are REALLY slow.
Do you place each data value into a waveform to attach the timestamp? I was using waveforms in the last revision but it seemed to use up too much space. A file with only 30-40 data points per minute would be megabytes in size after a couple of days. I don't know why, it was in .tdms format and every time I took x readings I would average them, convert the result to waveform data, and append it to the file. Since it was not streaming data I didn't know of any better way. Now I just store a double value in the .tdms file which takes much less space than the waveform. I would love to store a timestamp for each value so if you have a good compact method let me know please. I need my data file to be tens of kilobytes, not megabytes.Using a waveform for individual reading does NOT seem like a good idea. Why not just store two channels: “Measurement” and “Measurement_Time”? That’s what I do.
Can either of you comment on the sub-panel vs. opening/closing GUI's question?I’ve never noticed a problem with subpanels, but I’ve never looked into the speed.
Also, any suggestions on a better way to customize controls/indicators on the GUI at runtime. Right now I have to store all the captions, limits, marker spacing, etc...in a file/cluster and load them in using property nodes for each control.I’ve never done anything like that. Usually, I have most of the detail of an instrument in it’s own Front Panel, with only the key summary on a main screen of the whole application. So, for example, if I have a temperature controller, the main app might just show the temperature, the set point and some other summary info (like “ramping”). Clicking on the temperature indicator (or selecting from a menu or whatever) would bring up the “Temperature Controller Window” (could be in a subpanel) with a full set of controls (PID settings, maximum temperature, alarms) and indicators (chart of last ten minutes temperature and heating). The secondary window would be specific to that controller, so it doesn’t need adjusting, while the main app window would have only the general info that doesn’t need to be changed if you use a different controller.
Another technique is to realize that most simple indicators are really just text, or can easily be represented by text, and thus one can do a lot with a multicolumn listbox or tree control to display the state of your instruments.
— James

Database Error Logging
in Database and File IO
Posted
Sorry, I know little about the terminology of licensing. At a consulting firm I’m doing some work for, they would like a reusable error/debug logger for use in their many projects. I suggested your logger. But, if I read it right, the SQLite API has to be licensed for each project (each “product”), which isn’t going to fly. My other options are a non-database solution, using Saphir’s SmartSQLVIEW, or calling the SQLite all directly with SQL statements. I actually prefer the last option (even though it will be much more limited and less polished than your stuff) as I can then use it as a logger in my message/actor framework without inheriting any licensing issues. Need to polish up my SQL, anyway.