

drjdpowell
-
Posts
1,986 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by drjdpowell
-
-
Can you clarify? Are you saying carbon dioxide and nitrous oxide aren't greenhouse gases, or catalytic converters don't cause more of those gases to be released into the atmosphere?
The noxious gases that the catalytic converter works on are only a very small fraction of the gases produced, so it doesn’t make a meaningful difference. Also, the sun’s UV light will eventually complete the oxidation of the carbon in those gases to CO2. Too slowly to affect ground-level pollution, but fast on a timescale of climate change.
-
...we want to support multiple unrelated interfaces...
To be Devil’s advocate, isn’t the need to put the word “unrelated” in there a bit of a problem? I’m not familiar with OOP interfaces, but isn’t the idea that interfaces are different ways of treating the same object? Representing a single object as a collection of different objects with no connections between them might work sometimes, but the instant you have a relationship (say, Child2 needs to call a method on Child1 in order to execute “Child2Info.vi”) then you have a problem.
— James
Fuzzy Idea: How about a design in which QueryInterface, instead of returning a copy of Child2 from Child1, takes a Child1(containing Child2) and returns a Child2(containing Child1)? I.e. the collective object is always the same (and each child can access the other), but the apparent identity switches between different interfaces.
-
Minor point: catalytic converters don’t increase the amount of greenhouse gases, so this can’t be an example of “unintended consequences”.
-
Latest version, with a bit of the documentation filled in. It now also works under Mac OS X (it links to the standard copy of SQLite3 included as a part of OS X):
-
 2
2
-
-
How do I go about debugging if I can't probe stuff.
I usually set my programs with the ability switch between using the sub panel, and opening separate windows (this is very easy to do). Then I debug with separate windows.
-
Any further comments on this package? Or any comments on whether this is right for OpenG? I could alternately try and release it under “Team LAVA”.
I could also use the help of people who use LabVIEW for Macs or Linux to try and test it with SQLite compiled for those platforms. It should work quite easily. It would be a shame to have a Windows-only package.
— James
-
UFTP is interesting as a UDP-based file transfer system (with the interesting use case of a broadcast to multiple receivers over a satellite link). moralyan should have a look.
-
just look for more details about IEC and you will understand why we are insisting on UDP instead of TCP
Could you explain why in a short paragraph, please?
-
To me it looks like IEC61850 is not about transfering large files consistently over the network.
I googled it too and that was my conclusion. There were clearly tasks that cried out for UDP, broadcasting time-critical small pieces of information, but there was nothing suggesting one had to use UDP for sending large files.
-
Oh, I didn’t know your were talking about Panes. I’ve not done that; just User Menus from controls inside a sub panel, which work fine.
-
I usually save data as XY sets in a TDMS file, so different data sources can be at different rates and offsets. But if I wanted all data at the same time points, I would probably have a single queue to a “data logger” that all processes would send messages to (one queue, not many, with the source of the message as part of the message). Then the “Data logger” process could do any necessary resampling. This, IMO, has some advantages over using a Functional Global, though the advantages are pretty minor, at least for the typical use case of a steady data rate (where buffering is not needed).
— James
-
I’ve used User Menus in VIs in sub panels before without problem. Perhaps I’m misunderstanding the issue.
-
Hello,
I’m uploading the latest version of my framework, even though it isn’t polished, as I’m unlikely to have any time to polish it for months (baby on the way). It includes all the extra stuff since the last version, including the Actor Manager, and TCP-network versions of the Queue and User Event Messengers. It is in LabVIEW 2011.
— James
-
2
-
-
Tell me again why you're developing all your own stuff instead of joining LapDog?

Short answer: started (and had the first app using it) before I knew LapDog existed. Keep meaning to see if I can reformat the message part into a LapDog extension. Or make the messenger part interoperate with your "Message Queue”.
-
Thanks for the insight. I’m going to leave creating SQL functions for another day.
-
I've heard some cheap ones don't work with all hardware, but I haven't found any hardware my no name cheapo couldn't talk to yet.
Some don’t, some do. But the ones that don’t are cheap enough to throw in the trash and get a different brand.
-
-
I actually have a class laying around somewhere I prototyped a couple years ago specifically to send periodic messages to slaves. It's one of those things I've been meaning to add to LapDog....
I have a reusable “Actor” that does the same thing:
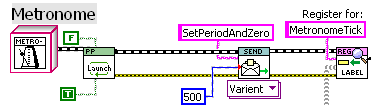
It’s one of the more useful things to have in the toolkit.
Anyway, the whole point of the exercise is that encapsulating the queue references allows me to store them in an array and I guess search it for a specific reference by trying to cast to the reference and handling errors, though there may be an even better way to do this taking advantage of inheritance.
Doesn’t sound that great to me. Personally, all my “Queues” (actually anything to which I can send a message, via queue, User Event, TCP server, notifier, etc.; my parent class is called “Send") use the same base “MSG” class, and I keep track of what is what by holding them in a cluster in shift register, and unbundling by name when I want to send something to one. I never put them in an array unless I mean to send the same message to everybody.
So I never search through an array of “Send” objects. In fact, the container I use for multiple “Send”s, called “Observer”, deliberately doesn’t provide the ability to access individual elements.
— James
-
Do you keep the timestamp of the last flush in an internal shift register? I assume Do.vi is a no-op if the queue timed out?
I keep the last timestamp in the object data. Yes, “Do.vi” is no-op for the parent message class.
-I believe the temporal separation of the dequeue timeout occurance and the next timeout being calculated will cause the absolute error to grow over time with Timeout Shifting. If you have something that has to execute every 5 seconds, it may start by executing at 0, 5, 10, etc., but after 10 minutes it may be executing at 1, 6, 11, etc.One can get around that by making the calculation like a metronome. Using the scheduled last time rather than the actual last execution time. Though in this application I didn’t, as true periodicity is not desired. Instead, I just need a minimal time between writes to disk, and doing it this way works better than a periodic heartbeat.
-I don't think Timeout Shifting will scale as well as a Heartbeat. To add multiple periodic task on different intervals to a slave using a Heartbeat, just drop another loop with the message and interval. To do it with Timeout Shifting requires more internal shift registers and logic to make sure only the task to execute next passes its time to the timeout terminal. More importantly, with each additional periodic task to perform, not only does that sub vi get called more frequently, but the percentage of wasted processing time with each execution increases, making the scheme less and less efficient. For practical purposes this may not matter.True. I’ve been meaning to think how to generalize this to multiple tasks. Perhaps an array of “tasks” that each output a timeout, with the minimum timeout being used, or an array of tasks sorted by next one scheduled, with only the first element actually checked.
— James
-
I do all coding on a single 15”-screen laptop. High res, though: 1680x1050. Don’t require things fit on the screen but they mostly do.
-
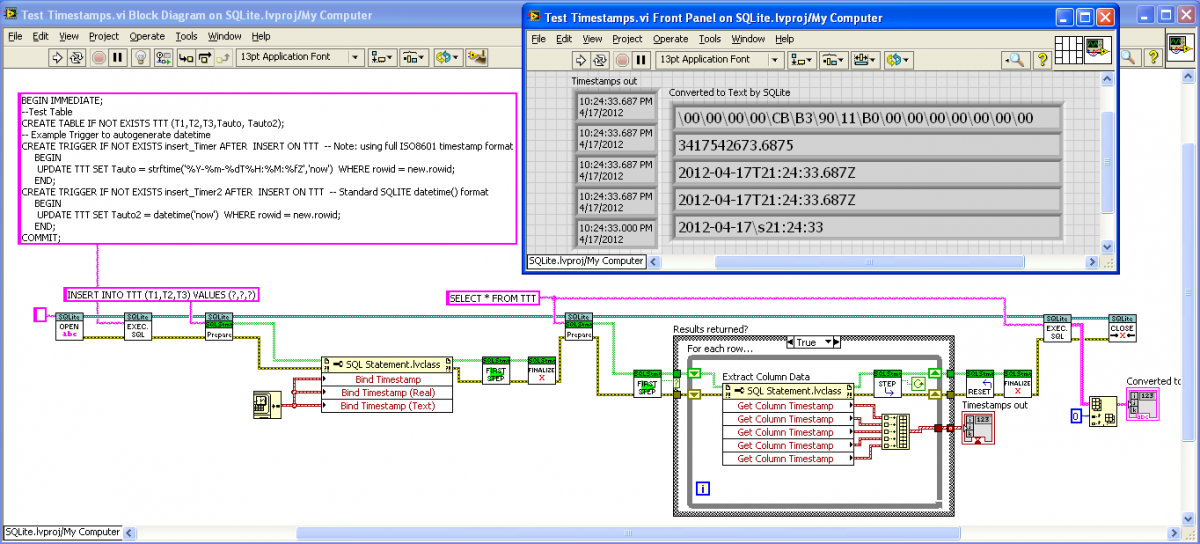
Here’s what I decided with the Timestamps. LabVIEW Timestamps saved as 128-bit BLOB or 8-byte DBL, or ISO8601 Timestring with “T” and “Z”. The “Get Column Timestring” property recognizes all these formats as well as the standard SQLite text format (sans “T” or “Z”). Shown is a “Test Timestamps" VI that records Timestamps in five ways, the three bindings and two autotimestamping Triggers (using strftime() to get the full ISO8601, and date time()):
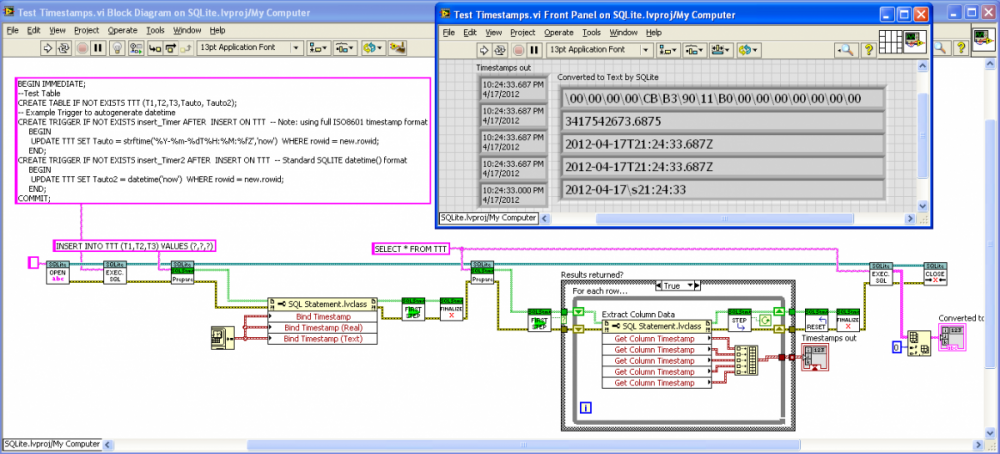
-
1
-
-
LabVIEW dll functions can be called from C, I’m pretty sure, but I can’t figure out how toy get a pointer to the function in LabVIEW.
-
Also, if you're slave process should be continuous except when handling messages, do you utilise a timeout method, or do you separate the behaviours within the slave by adding another layer via a separate message handler?
There are two ways I've dealt with "continuous process" slaves in the past: Heartbeats and DVRs.
I had a similar issue recently that I tried a different way with. A fourth option to consider with Timeouts, Heartbeats and DVRs (never thought of the last one).
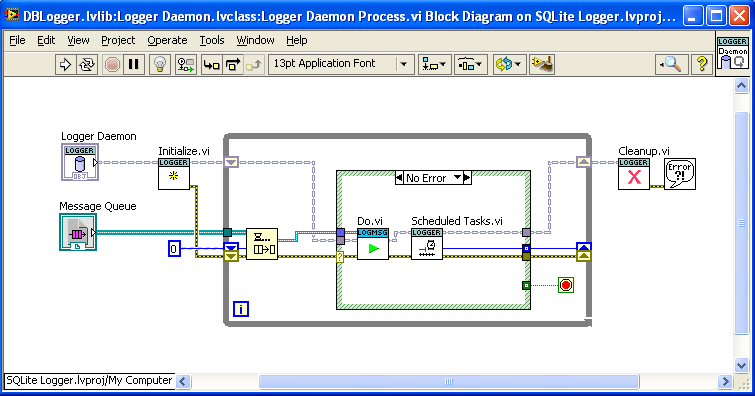
I was writing software to log to an SQLite database; each individual SQLite transaction to disk takes a large amount of time, so it is best to store up log messages and save them as a batch periodically. I solved it with a “Scheduled Tasks” VI shown below (in a background process in the “Command Pattern” OOP style):
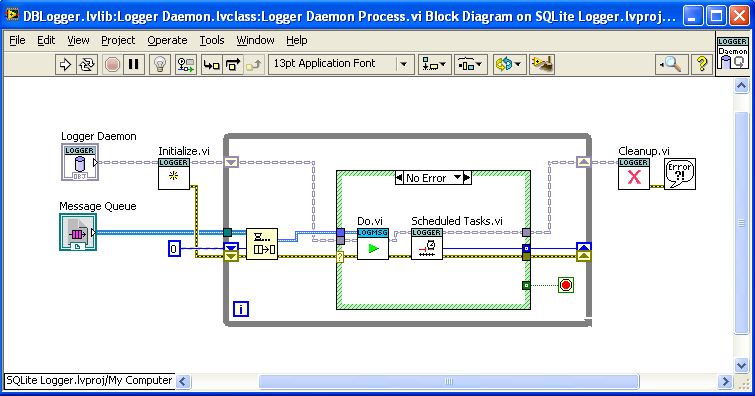
“Scheduled Tasks” is called after each message and outputs a timeout that feeds back into the dequeue. Internally, “Scheduled Tasks” checks to see if it is time to write the accumulated log messages to disk, and if not, calculates the remaining milliseconds, which is output. Thus, the task always gets done on time, regardless of how many messages are incoming. A disadvantage is that the timeout calculation has to be done after each message, but it isn’t a big calculation. An advantage is that “Scheduled Tasks” outputs −1 (no timeout) after it flushes all waiting messages to disk; thus if log messages arrive very rarely, this loop is spending most of its time just waiting.
It worked out quite well in this application, so I thought I’d mention it.
— James
-
On a side note, does anyone know how one might implement this using LabVIEW? It would allow creation of new SQL functions (such as ones that can handle LabVIEW timestamps). It requires the passing of a function pointer to the SQLite dll function. I have no real experience in such things, but I would have thought one could make a VI into a dll, and somehow pass a pointer to it to SQLite. But Google says no.
Interface provider inspired by COM
in Object-Oriented Programming
Posted
An experimental modification:
Run “Example B.vi"
Interface B.zip