0_o
-
Posts
194 -
Joined
-
Last visited
-
Days Won
4
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by 0_o
-
Sadly, in my case the cursor legend doesn't have a reference/property node since LV8 and writing my own worked a bit better yet still had lots of LV bugs to deal with and I just didn't want to keep on going and finding more and more bugs so I just left the splitter approach.
-
I saw this happening while working with cursor menu of graphs inside FP that was using splitters. It was very similar to what Cat wrote back in 2010 http://lavag.org/topic/12577-unintentional-cursor-tool-resizing/ When I reported it 4 years later I got the following reply: This is a rare bug few people reported. NI expects it to be solved by LV2014. I ended up writing my own cursor menu and still got LV bugs. I'm now at my 4th try with/o splitters waiting to see what LV comes up with next. I stopped counting how many projects I did failed because LV had bugs I couldn't bypass with the classes of LV2011 being the worst. Good luck.
-
Elijah Kerry leads the large app team at NI and he just published an update to his measurement utility: https://decibel.ni.com/content/docs/DOC-21441 that demonstrates how to use it with TestStand: https://decibel.ni.com/content/docs/DOC-33162
-

How to set the network device on multi LAN system
0_o replied to spaghetti_developer's topic in LabVIEW General
Make sure all the connections from one card don't use the same subnet as the connections being used from the other one and there is no router being used. Subnet is the 3rd part of the ip. Ask your IT to help. The rule is that if you use a router all connections should be through it and not p2p. Try a ping and see if it goes through from each direction. If the first ping doesn't go through or directed to the gateway or pings are blocked you'll start understanding what the problem is. However, if possible, I would switch from using two Lans to using one Lan and a router. -
Command design pattern and composition of functions
0_o replied to 0_o's topic in Object-Oriented Programming
Thanks for all the replies. I'm so sorry for the Houdini act from my own post. You deserve a more through reply, thus, I'll strip down a demo project of mine tonight and post it full for your inspection. For now, the example of the init process might not be the most perfect one. My basic question was: what is the best way to bring order to parallel processes making sure that one will start only once the other finished. I guess Actors have an answer for that question but I didn't dive into it enough yet. In the demo I'll post tonight the parallel vis are not Actors but I could, in theory, call them asynchronously. Please don't fixate to the init example there. I guess that if only I asked how Actors communicate and bring order between them I would have gotten my answer ages ago. -
Hey, I'm back. Sorry for the disappearance, I’ve been doing a SWOT analysis in a marathon of some management meetings. H-E-L-P-!-!-! First let me start with NI Week... how marvelous. My wish of being there was half complete once so many great talks were recorded. Thanks Mark Bella! I love you guys and wish to see you there next time. Now, Daklu, my reasoning is very simple: it is hard to impose a coding style on a large or even medium size group of programmers with different levels of OO experience and even between generations of programmers that come and go. Most places don't even have an architect. The result is layers of code that each do approximately the same stuff but a bit differently since the documentation is never enough and each has its own bugs and together it is a one big mess. The distance from there to a full spaghetti code is not that much. Aggregation and Adapters, though requires less coupling on the surface, down below requires a much deeper coupling. It is the coupling between the code and the programmer who wrote it which is very hard to handle. How can you measure such a thing in respect to decoupling a system? I know each of us would love to be permanent in a work place and coupling is a great way to achieve it but it is not a good BI approach. Oh, and if someone thinks that I say aggregation and adapters are evil, you got me totally wrong. They are much better than what you usually see around the best written code. I just said that for me it is too open and I like a code that makes it very hard for a programmer to deviate from the architecture.
-
Great work. Thanks jcarmody! I'm working on a version of mine (on my free time which is not a lot) and the JKI State Machine you implemented might make it a bit more elegant compering to the LVOOP I used. I promise to post here when done. I have a few suggestions for now: 1. Instead of writing [Covers xxxx] you could have a vi that reads through the requirements.txt and gives you out a ComboBox filled with the requirements and the structure of the message. All you'll need to do is concatenate the strings and thus avoiding spelling mistakes like writing covers (as you did in your post) instead of Covers as your pattern matching requires. 2. Your tool scans only the main vi while there should be a tree of requirements that are implemented inside any vi in the project on even in a parallel project of a plugin for example. Some requirements will be green without ever writing a label about them simply since all their sub tasks are done. 3. If you go and scan in this way via the vi server all the files in your projects you'll get into a very big problem: the vi server opens each vi in order to do a traverse! It will take you forever to scan everything. The proper way to do it is by adding a text message into the binary code of the vi since then you could simply search the binary code of each vi. The way I currently thought about implementing it is by creating an empty vi (stub - https://decibel.ni.c.../docs/DOC-22847) for each requirement in a separate project and adding this vi next to the label and the code that covers the requirement. Any vi appears as is inside the binary code of a vi. If there is something else that is added as a text into the binary code of a vi I would love it hear about it or if someone knows how to get label texts from the binary code of the vis by using zlib or what ever way it is encrypted by please do tell me. P.S. - this way instead of a requirements id we can use a name. 4. A requirement might be implemented in multiple locations. You might want to mark a list of vis and enforce them to implement a requirement and thus each vi will have a list/table of tasks and task status + time which is very important since you might want to compare between the time of update and the time of status change. 5. In theory, though I'm light years from it, the CI (continues Integration - automatic builds that are being done once the repository is changed) should run a requirements scan and give a report if any change is made or if a test shows that even though a requirement is marked as done the test failed or even run only tests for new finished requirements. Beside 5 the rest are feasible I think. I hope to see a more in depth demonstration and some free automation code to integrate with Jenkins and then I'll be happy to the roof.
-
Which SCC software between Git and Hg should I use?
0_o replied to honoka's topic in Source Code Control
I would like to have the next mechanism: 1. IC over all the projects in TSVN. 2. Run tests and report once a day with an option to compare logs. 3. Use the logic of flight rooting to manage task from office project dynamically, taking into account the test and requirements logs. The comparison to flight rooting is that a flight needs to reach a destination via some available roots with some stops on the way. Once reaching a stop on the way the root might change since there was an error or the optimized root changed or there was a new requirement. In order to reach the destination on the due date I need a tool that will know what state am I in and allow input from tests or user input along the way and thus creating a manageable task list with more predictable time tables while making it clear what caused each delay. A test could tell me if I reached the destination on time or not and even what resources/roots are available for me now. Once I have a log of the entire root I can calculate the price vs. profit of the entire flight schedule and better predict future profitability of each flight/product. However, this is off subject, I only wanted to know how Perforce is in comparison to TSVN and GIT while saying how frustrating it is to write everything myself with no end to end solution available. I don't care so much if it is this SCC or that SCC. They all use the same merge and have their own issues. The thing I miss the most is an infrastructure that analyzes all this data and knows how to integrate with each tool. As for excluding the text files, I already do it for some other files (xml/ini/aliases). Excluding lvproj or even manually merging them, as I do now, doesn't promise good integration. Lately I'm having internal warnings each time I close LV and I wonder how much of it is related to something I did... maybe in one of the project merges. -
Which SCC software between Git and Hg should I use?
0_o replied to honoka's topic in Source Code Control
I'm currently working with TSVN yet I think all the available tools are not good enough for me. There are many missing features but the top for me are: 1. Project files are text files. How can you merge them without potentially breaking the project. 2. There is no Continuos Integration built into them. 3. There is no automatic builder that will create different versions of exes from the same project in the SCC. 4. Requirements + bug tracking integration. 5. Statistics over commits, bugs and benchmark dead lines. I know this is not a tipical demand from a SCC but I end up always inventing the wheel while integrating different tools instead of having a central tool to handle all those close related subjects. Though crocket didn't ask about it, how does perforce compair to SVN/GIT/Rhodecode now that it is free for small to medium groups? -
How nice to here the combination of words: "official NIWeek 2012 youtube videos". Thanks. However, sadlly, non compares to what you did and it's a shame. The world disney effect of NIWeek is not what interests me.
-
It's 5.29 A.M., my eyes are red and I just finished Norm's video about the rebirth of state machines. IT IS A MUST SEE!!! There are so many good sessions that my head spins but for now I simply love this one.
-
Thank you Thank you Thank you Thank you Thank you Thank you Thank you I wish NI took care to record and upload the entire NI week including the the vis that were demonstrated.
-
A script that I wrote runs recursively over all the vis in a project and searches a string in the label/description etc. It works just fine but the script opens each vi while accessing its reference and thus running over >1000 big vis takes ages. However, the built in find option in LV searches text in an application and it only takes seconds thus I guess it searches the serialized vis and somehow knows how to highlight the relevant control. Besides looking at the flattened code from time to time I never tried anything like that. Is the search function open source and I just need to find it or is it a LV secret?
-
I know that the preserve run time option is ok. I just think that if possible it should be avoided by the way I described that doesn't do any deserialization of the class. However, I didn't go over the GXML tool so, again, I might be missing something.
-
I might be missing something here but if I understand correctly then the obj xml config should be a class and in its cluster you should have a xml control. Now, into the parser you pass the unbundled xml control from the class cluster and you do the same when you convert from variant to data. Finally you need to bundle this xml back into the class. This way the class should be fine going out back from the dynamic dispatch.
-
LOL
-
Are the dongles like http://www.smart-lock.com/ much safer? A few years ago we had the best protection available: spaghetti code... the worst kind! Our SW was so unreadable that no one could have used it. Seriously, we know of a big company in China that tried copying the logic of our source code that they stole and they simply gave up trying. However, now that I'm upgrading the code to LVOOP I'm afraid it won't be that hard anymore. This is the only bad thing I have to say about OO
-
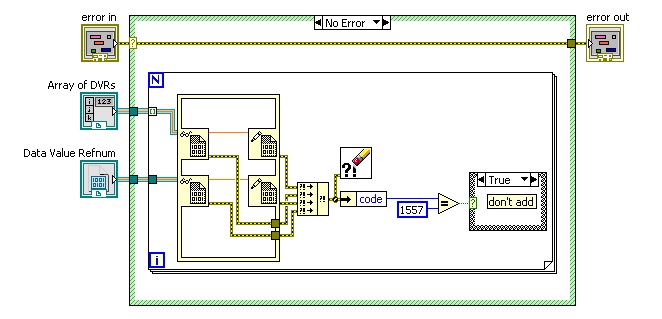
Variant Hash Table for Aggregate Objects: DVRs by Name
0_o replied to klessm1's topic in Object-Oriented Programming
Instead of using the name which is possibly not unique you can flatten the dvr to string and use it as a unique identifier. In order to prevent duplicated refs or different refs that point to the same data you can add a dup check while building your lookup: Before adding a ref iterate over the existing dvrs and try to inset the new dvr and the current dvr from your lookup into an in place structure. If the two dvrs refer to the same data LV will give you error 1557. Catch it and if it was caught don't add the dvr into the lookup. Since you might have two different dvrs referring to the same data, searching for a dvr in the array might still require the 1557 error testing and thus reduce the theoretical performance. Beside that, watch out of the dvr life span. DVRs live as long as the application that created them live. You might get a lookup table with invalid dvrs. Moreover, you might want to add a privacy mechanism since you don't want everyone to access any dvr. It is true that a dvr can be opened only by vis from the class that it was created from yet I don't want someone to iterate over the dvrs array calling some execute.vi for example if I don't want it to (a use case might be a different operation method for advanced user and basic user). P.S. - this lookup is not a hash table. The Variant implements the red/black tree and not a hashing algorithm.
-
Simulate the car's differential that drives the wheels: Differential frequency clock for each wheel: The clock triggers each wheel's rotation but the frequency and power depends on the state of the other wheel. Moreover, it doesn't matter if the wheel got the trigger if it doesn't have the resources. Each wheel is an actor driven in parallel over the same resources with its own conditions. If they both get the same resources one wheel might drift when it can't keep up in turns or when it has to deal with more friction. If one wheel will get all the resources we might get into a lock condition or with a car that drives pointlessly around and around. 1. 2 wheels = 2 hardware 2. They can work at the same time but not independently. Coupling is the more general case I think. 3. If one wheel is blocked the available resources for the other wheel are changed. Besides that, with the car differential turned off (truck with one wheel digging into the sand) the wheels can't move independently. The benefit of such a simulation is that you could easily detect problems by observing that your car has some jigger and can't handle some terrain. This might also be practical for electric cars.
-
Command design pattern and composition of functions
0_o replied to 0_o's topic in Object-Oriented Programming
drjdpowell, this is just a basic example and not the actual feature I'm trying to implement. True, it is possible to remove the init in my example and leave only the member access vi or join them two together. Yet, even in this example there are reasons to have a separate init which is dynamically dispatched: 1. The init might establish communication and load configuration files while the command has other parameters that the user has to set. You don’t want to have a big init vi that does a hundred things at once. You might not have even enough connectors to do that. 2. You might want to get an instance of the command, run it with one set of parameters and run it again without initializing but with a different set of parameters. 3. Moreover, you might want to override this command to behave a bit differently which is why you want it to be dynamic. You might also want to iterate over some commands and add a common vi just to this group. If the init is different for each command you might not be able to do that. 4. As for having one big vi that both initializes and gets all the parameters at once and maybe parse some input strings, I don't like this style since it leaves a lot of room for manual mistakes. Having a data member vi that can only get a specific input enforces style on the developer. ned, I'm trying to create a function composition without sub vis or synchronous calls and the first step is having parallel vis wait one to the other and give each other input/output: Given f(x) = 2x + 3 and g(x) = –x2 + 5, find ( f o g)(x) The command design pattern is just a test case. As for the breaking of OO, besides the fact that you deal with a particular instance instead of the general array of objects, I really hate searching for an index in the array. What will happen if you add a command to the beginning of the array? You add here a lot of manual coupling. Any assumption I have on the array which is not part of the hierarchy such as instance index or identifier/flag for some type of objects is, from my point of view, regular code that just happens to be next to OO code. Never mind why I want to implement it, my question is what is the best way to signal the other vi to start working with as little cpu usage and mess. Notifiers? Queues? Events?... -
Command design pattern and composition of functions
0_o replied to 0_o's topic in Object-Oriented Programming
ned, I tend to talk too much. Hopefully the code example will explain itself. ShaunR, this is exactly how I felt during this OO design I attached a code that demonstrates the problem and a solution that looks a bit like the picture you posted. It contains a command class and 3 main vis: "main - old style" shows a particular problem. "main - concept" shows a solution. "main - new style" implements the solution. However, this solution is a bit complex and it spends cpu time. Is there a more elegant way to solve this and get the same effect but with no cpu time and with less code? I thought of some other solutions but I'm not happy with any of them beside a generic param input which I try to avoid. The project is saved in LV 2011. Tell me if you want it in another version. test command.zip -
Hi, I would like to run a vi and check in it if I want to continue executing it or to pass it down the flow to another vi that will run it with the same inputs that he had before. This will allow for a basic function of function implementation or function composition. Never mind the general concept, here is a study case that I want to solve: I have a command design pattern (classes) that contains 3 vis: init, set specific param and execute. The init and the execute is the same override vi for all the commands, however, the member access vi "set specific param" is different for each command. I could pass the params to the init or to the execute through a generic input but for this example I don't want to. The result will be a common init and execute that can iterate through the array of commands but the "set specific param" can't be iterated since it is different and regards a specific command from the array. The problem is that we need to use "set specific param" only after the init and before the execute, thus, breaking the OO design. My solution was to add a Boolean "is initialized" to the commands class cluster and set it to true in the init vi. Inside the "set specific param" I check the status of "is initialized" and if it is false (init wasn't called yet) I will send the vi and the connector pane inputs to the init vi queue. The init vi will open the queue of vis to run before closing. This will allow me to "set specific param" on an uninitialized instance of the command instance before I go and iterate on the array of the commands. Obviously this is not perfect in the case of a calculation being written and read but only for param setting (the complete calculation could also be generalized into this concept by creating a tree of functions of functions instead of a vi queue). What do you think about this concept? Is there a more trivial way to do it? Since we can't run the vis reference again from the vi server I had to recall the vi. I might also pause it via a notifier (while the class input is turned into a DVR) and have the init release it and wait for it to finish before going to the next vi in the loop. Did anyone try this concept before? Thanks in advance.
-
Sorry for the late reply. I wish I was a bit less busy and had time to go to NI Week too you bastards Yeehaa Will there be a recording of all the sessions for the common people this time? As for the topic, I’m using FPGA via VHDL, thus, I don’t have enough experience with abstracting FPGA directly through LV. For me abstracting the FPGA includes abstracting the communication (TCP/IP) and the string commands (Command design pattern (low+high) + DB + testing + plugin). The way I think the general question should be tackled is: List the hardware and protocols being used from your computer from the nearest to the farthest. The closer or the more instruments depends on the device/protocol the more fundamental it is and thus lower in the HAL. Ask yourself what might change sooner and multiply this list with the list from (1). The more (fundamental * changeable) the device/protocol is the more you need to abstract it. In MichaelH’s UML the communication protocol is the most fundamental block that might change from RS232 to TCP/IP or to a DAQ card. All the instruments need to read/write to one of those blocks and you want to be able to change it easily without touching the rest of the code. A DAQ card might have a driver update with new LV building blocks even while the card is still the same. It will be nearly impossible to change all the methods that use those fundamental functions. In my opinion even file access should be in this HAL low layer since this is a method you are using to access your HD. I have an abstraction layer that contains advanced/basic TDMS + basic file access + TCP/IP + RS232 along the DAQ to abstract all my read and write. I allow slow OO design but I take care that once I get to the direct read and write to the IO it will work as fast as possible. This way you solve the communication protocol once and have lots of code reuse while never spending time on reinventing the wheel. Inheritance between HAL classes should be added in one of two cases: a) Most of the vis in it are the same. b) You want to impose a style and structure for your team in order to make the code readable and maintainable for future changes (you could easily add tests or any other function to a well thought hierarchy. In Daklu’s case it will take shorter time to design but the code will be much less configurable and if one day he will need a new common function it will be much harder to have some code reuse. Since no one knows the exact future functionality I find OO to be a good choice (it is like planning for a bad weather, however, not everyone agrees that it is wise to buy an umbrella in the summer even though it is much cheaper). Personally I find the task of enforcing a clear architecture on a team that will be maintained for years to come even when team members are changed to be a very important task and the hardest to achieve. Though Daklu might disapprove, I think aggregation and adapter design patterns make the code less decoupled and not more decoupled. Each instrument should be associated with a DB Class and all the DB classes should be maintained by the main up. A DB Class will contain, among other basic states, configuration parameters for basic cases and state enum so that initialize will start immediately most of the time without manual changes once you loaded the instrument’s DB. I prefer this upon requesting the data through messaging since the DB DVR allows for better locking and prevents more race cases and deadlocks IMO while allowing for a much more flexible classification of DBs. Higher level instruments that depend on the lower level instruments must use the abstraction layer and never a direct access to the low level functions. And they are actually part of the Application Abstraction Layer and they contain a list of commands with no drivers or communication protocols. A general rule of thumb: the more fundamental an instrument is the less classes it should contain. Code reuse between unrelated instruments should be handled by the framework (MVC+UI Framework for example) and not by the HAL. Once you decide on a design the first step is to test the most general case with communication and DB sharing between the instruments + testing + trying to change a fundamental instrument. Once verified document the design, give examples/templates and start praying that your design doesn’t lack any issue like the singleton behavior of dependent resources or any time constraints or some parallelism issues. Just remember, as long as all the problems you have are in implementing the design and not in changing it you should be thankful! This OO design will protect you from breaking it and you could easily see that each deviation results in a broken arrow. Instead of being angry that you run into a wall each second be grateful that you have a home to live in and open your eyes. In the case of the 7951R FPGA and the Area Scan Camera, I interpret the FPGA as a DAQ I use to control several instruments. If you apply the logic I described above you’ll see that the FPGA is more fundamental and changeable. What will happen if a year from now you will have to replace this FPGA with a new version while keeping the same camera. What will happen if you’ll need to change to a different communication/control that is not FPGA? What will happen if you’ll plug a different camera to this FPGA? When I ask what will happen I’m not talking about the camera functions which you could easily rewrite but rather to your main code that calls those functions. If this FPGA serves only your camera you can see them both as a single instrument, even though the FPGA is more fundamental, and you should just abstract the FPGA calls to the camera. It is a game of give and take. The main issues with abstraction layers is readability and design time so you shouldn’t abstract if you are sure this is a risk you can take. If you ask what the main risk is, well, it is a business logic issue. Any product must change its instruments (like the camera) every 3-4 years since there are better instruments that cost less and your instrument is out of stock. The more time it will take you to release an upgrade the slower you could react to your competition. However, the more time it will take you to design the more money you need to jumpstart your product before you run out of money. Good luck and happy NI Week. P.S. – If it wasn’t clear by now… I’m SOOOoooooo jealous of the NI Week participants.
-
AlexA, did you solve your problems already? Post a new UML if there are still some design problems. As for the video crelf posted about, they show an encapsulation of access to a DMM driver while adding an emulation version. It is the basic idea but it is not a HAL example since the DMM itself is not a type of a generic HW and there is no clear separation between ASL and HAL. Thus, IMO, it is a bit confusing for anyone that wants to implement a HAL for the first time. I would refer you to the official HAL 2.0 document and examples at NI yet I both think you tried it already and I think it is also lacking some information about the ASL level and the MAL+plugin integration. Moreover, most of the examples are written for NI HW and not for a generic digital/analog input/output and a FPGA combo that implement some virtual instruments. Good luck.
-
You are abstracting the application layer (ASL) instead of the hardware layer (HAL). The drivers that give you digital/analog input/output or even the protocols of communication are the HAL IMO. The different instruments that use those channels are applications. I would start with a HW class and input+output children and have the rest inherit from them (if a channel is used in several ways have a child for each use case). I think NI's example is confusing and lacking explanations from the ASL side. The way I implemented it is by having the ASL contain LVOOP Command classes for each application. The each command calls a combination of vis from the application's plugin. Once loaded the command initializes with the relevant HW from the HAL while the application's class from the plugin is initialized with a DB that shares data between the application's plugin and the state of the system. This way the plugin app can be developed no matter what HW you are using and the commands can log input and output of actions relative to GUI actions and thus be used also as a recorder of user actions and as a simulation (playback actions and replay/simulate the responses from the HW) method (stub/mock). This is obviously not the only way to go and the hardest part is not the architecture you are designing, since all it requires is some trial and error, but rather having a team understand the design and maintain it.