mwebster
-
Posts
35 -
Joined
-
Last visited
-
Days Won
1
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by mwebster
-
Yep, I was thinking exactly that after I got it working, no need to wrap single statements.... Thanks for the links!
-
I think you're right. I was expecting it behave like RELEASE. ROLLBACK TO doesn't commit, you're still inside the SAVEPOINT transaction.
-
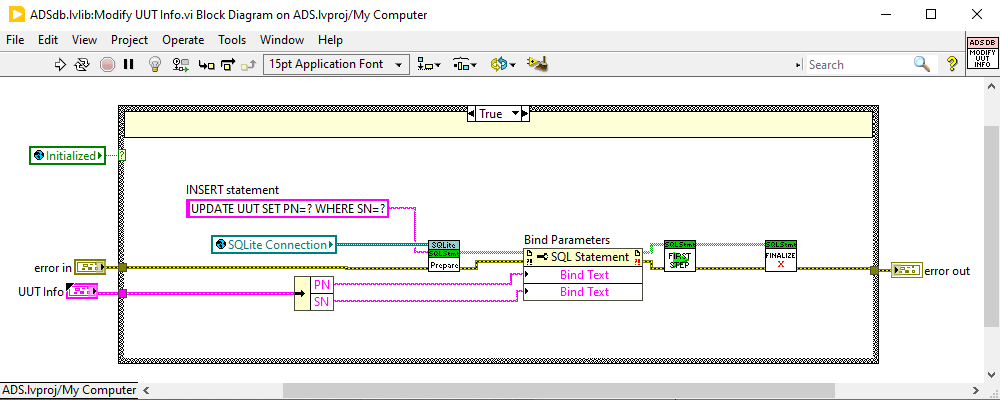
LabVIEW 2020. Example.vi I removed the savepoint hookups in the Modify UUT Info.vi to make the error come out explicitly. If you hook those up, it fails silent. I "fixed" it by removing the savepoint hookups in the Save UUT Info.vi so it just does a BEGIN IMMEDIATE/ROLLBACK. SQLite Transaction failure example.zip
-
I originally had it wrapped in a Begin/Commit as well but removed them to see if that was part of the problem. Same issue there, the in-memory copy had the update, but not saved to file. Thanks for the syntax check though, I didn't see an UPDATE in the example code, so wasn't completely sure about that. Okay, I found it. I was attempting an Insert originally and, if that failed, I was trying an Update. So, for whatever reason, the Insert transaction wasn't getting closed out properly on error. For a named transaction, when there's an error, it is doing SAVEPOINT X / ROLLBACK TO X, but this isn't closing the transaction. I didn't get an error on this until I tried an unnamed transaction for the update, which attempt to do BEGIN IMMEDIATE / (COMMIT or ROLLBACK depending on error state). When the update function tried to do BEGIN IMMEDIATE, the API threw an error saying you couldn't begin a transaction without closing the previous one. I then went back to the Insert and removed the names from that (so it does BEGIN IMMEDIATE / ROLLBACK when it hits an error) and then the subsequent UPDATE call works as intended. Not sure why ROLLBACK TO X didn't close the transaction, but that was the root cause. Thanks again for the help.... Mike
-
I've got a weird one that I can't seem to find the answer for. When I try to update a row in an existing table, it seems to work OK, subsequent queries show the updated data is there. However, after I close the connection and reopen it, the old data is still there. Is there some in-memory copy that's not getting flushed out with UPDATE? Insert's work fine... This is just a two-field table, SN primary unique string key and PN string. Creating them saves them almost instantly after finalize (checking with external viewer). Update doesn't save them where external viewer can see it, but doing a query in LabVIEW does see it until I restart the connection, as mentioned before. I've also tried it without binding using format into string where I just have the SQLite statement say UPDATE UUT SET PN='10029-201' WHERE SN=123 but the same thing happens. Am I missing something simple here?

-
Second for Sorensen's. I've used their DLM600's on several projects using GPIB. Drivers on driver network have been fine for me. I'm not sure how fast you can sample back their IV though. Whenever I've needed that information faster than human monitor speed, I've tended to put in a couple of signal conditioners and a shunt so I can get DAQ sampled / aligned input. Oh, and only 1U high and half rack wide so you can pile in several in a small footprint. I also really like Acopian gold box power supplies. The programmable ones have been stable and linear enough in my experience that they can run open loop after calibrating (i.e. 1V AO = 5V supply, 10V AO = 80V supply, calculate scale and offset and you're off to the races). Again, you'd need DAQ hardware and signal conditioning to sample back voltage and current.
-
 Yeah, the tutorials were great. Maybe add an overview VI with one of each of the various widgets you've implemented so far? I still don't really know what a DoubleSpinBox or FontComboBox is ... Nothing in particular, I was thinking of how to extend the chart functionality with a right-click menu popup or something. Just thinking about what could be done. The chart you have looks like maybe a wrapper for QChart without all of the properties exposed? I also did a little playing around with the stylesheet property input and got some cool background gradient effects on the indicators. Neat stuff. It would be cool if we could access the full QML markup (like drop this QML markup string into this container layer) to do things like control animations, but I don't know how you'd go about accessing those declared controls programatically back in LabVIEW. Mike
Yeah, the tutorials were great. Maybe add an overview VI with one of each of the various widgets you've implemented so far? I still don't really know what a DoubleSpinBox or FontComboBox is ... Nothing in particular, I was thinking of how to extend the chart functionality with a right-click menu popup or something. Just thinking about what could be done. The chart you have looks like maybe a wrapper for QChart without all of the properties exposed? I also did a little playing around with the stylesheet property input and got some cool background gradient effects on the indicators. Neat stuff. It would be cool if we could access the full QML markup (like drop this QML markup string into this container layer) to do things like control animations, but I don't know how you'd go about accessing those declared controls programatically back in LabVIEW. Mike -
It was the one you actually mentioned in your documentation with the dynamic GUI composition, where selecting Tab Widget, Splitter, or MDI Area causes LabVIEW to freeze when transitioning back to edit mode. I do agree that the learning curve would be easier to absorb into a large scale project. I guess my problem is I work on too many medium scale (1 or 2 developer) projects. The intimidating thing to me was the thought of using this for the entirety of the project, I'm much more comfortable with using a piece of it to implement something LabVIEW can't do on its own. I was wondering though, can you get any events from the widgets besides the signals they emit (valueChanged, sliderPressed)? i.e. mouseover, mouse down with modifier keys, etc?
-
You're right, and I don't do entire projects with those either. You raise a good point though. I may find a way to use this like I do with the occasional ActiveX/.NET stuff, as a component of a project. I could see using it for a sort of dynamic data viewer (Select 1 to n channels from a group performing active acquisition, add and bind indicators / graphs to a container and poof).
-
So let me say at the outset, this is very impressive. It allows for dynamic runtime creation of well-behaved controls and indicators that resize beautifully and have tons of customization options (lots of work has obviously gone into Qt Widgets). I really like the way you can link objects together solely through the Qt framework or through events or through callbacks. I hope I can find an excuse to use it. However, I have absolutely no vision of how to use this on anything outside the smallest of projects. The overhead required to do manual, programmatic layout removes one of Labview's biggest advantages ((relatively) quick GUI development). And it's like the worst of both worlds, the complexity of text based GUI design with the interface of doing it through Labview. It reminds me of how when I do anything beyond the simplest math, I reach for the equation node. Oh, even more, it reminds me of the Labview TestStand OI. That thing makes me cross-eyed every time I delve down into it. So many callbacks and hooks. I'm sure given the time I could replicate what I'm normally doing in a standard GUI, but the learning curve seems very daunting. Other practical observations: Obviously the Labview crashing thing needs to be figured out. I really wish Labview played better with external code, I ran into a hard crash to desktop just last month trying to use an external C# .NET library if everything wasn't cleaned up just right (accidentally hit abort button from muscle memory? bye-bye labview). We should be able to rename event wires. I dove into this a bit on the interwebs and apparently it isn't possible at runtime (you can cast it to a different, fixed name with a typecast, but not to a dynamic name). I can see this being a real issue if you decide to use a bunch of events in your program. I guess we could always cast them just before event registration, just a little painful. You speak of possibly having a GUI editor in the far future. Something like the QT Creator IDE frontend that figures out how to use VI scripting to create the equivalent Labview calls? Unfortunately I feel like I would probably need something at that level before diving in headfirst. All of that said, I do plan to keep an eye on this. Some of the capabilities of QT are really cool looking, especially in regards to themes, graphs, and accelerated 3d visualizations. Best regards, Mike
-
Trying out examples: Lib path is hardcoded instead of relative. Must install to c:\LQWidgets or modify lib path VI. I will try to provide more feedback when I have a chance to play with this more, but I wanted to point this out ASAP so others don't give up on trying this out prematurely. I also want to say that from a just toe-wet perspective, I'm very impressed by the organization, documentation, and depth of the examples so far. Edit: And, obviously, you document this in the README file. Who reads README's?
-
If you're looking for a particular file with a known filename, I cannot recommend enough voidtools.com Everything search tool. I seriously don't know how I got along without it. It indexes every file on fixed disk locations (takes a minute or so on first startup) and after that, it winnows through the file list as fast as you can type. Works with wildcards as well. I have mine running on startup and bound to Win+A. It's really great for finding duplicate files, projects, different DLL versions. It doesn't look inside the file at all, but for many, many needs I haven't found anything else that can touch it.
-
I just came across this last week. There's some nice stuff in there. Definitely some pieces that I may wind up using and extending for future projects. I especially liked the mouse wheel graph zoom function you wrote, very neat and modular. I had done roughly the same with modkeys as a proof of concept when they introduced mousewheel events, but it wasn't nearly as self-contained. Mike
-
What we have settled on doing is moving non-native libraries into our project directory (which is under source code control). I've just worked on too many legacy projects with missing dependencies. I had one recently where the original dev company was out of business and the company that wrote the library (for their hardware) was out of business. I wound up having to redo a communication module to a different piece of hardware over about 40 hours which should have been less than 2 to reinstall the source and compile for a new machine. More business for me, I guess, but there have been enough other occasions where I, or some other colleague, has cost me hours of dependency hunting that I find it's more than worth it to keep a project as encapsulated and portable as possible. And we don't even do that much multi-developer work, I imagine it would be even more important then. I would love to have a way to have a "project.lib" directory to support palette menus out of local directories, but at the end of the day it's not a great loss since I'm using quickdrop 95% of the time anyway. I tried using VM's a couple of years ago, especially for older legacy code from LV6 & 7, but the performance wound up getting so abysmal. Maybe it was my setup, but we had sprung for VMWare and had CPU's with the VT feature and had tons of ROM, but it was still just appallingly slow. This was before I had an SSD, so maybe that would have helped, maybe I'll revisit it if any of our old legacy projects wake back up soon. Oh, and OS licensing. My reading on it at the time lead me to believe that if you weren't a Microsoft Certified Partner (who get unlimited installs based on their license) you were technically supposed to pay for an OS license for each separate VM. It looks like that might have changed with Windows 10 "Software Assurance" licensing, but I haven't done any real research on that ... Mike
-
I was looking for 2013 SP1 and the google link took me to the "latest release" page which looks like it's just been updated with 2014. Looking through the release notes and the only great! feature I saw was the Reviewing and Updating Type Definition Instances. This one always frustrated me to no end. Now, it makes efforts to map automatically update default typedefs and if it can't decide how to do it, it puts the instance in an "unresolved" state and prompts you to manually update it. I really didn't see anything else of much note. Probably the lightest new feature bump I can ever recall... Mike
-
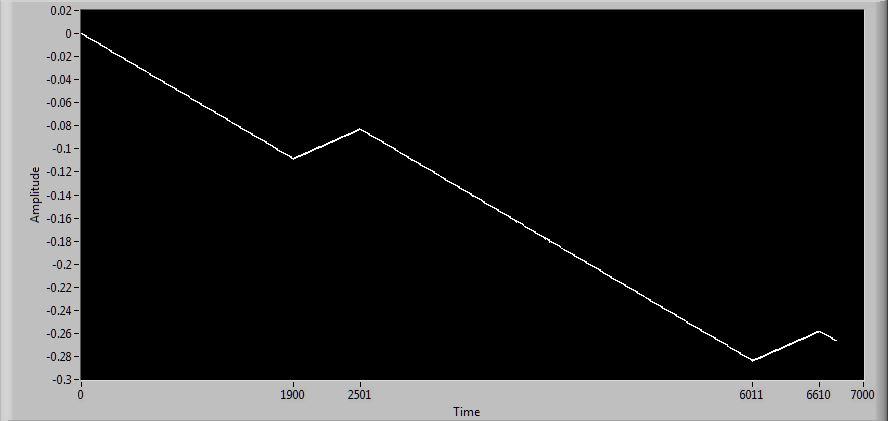
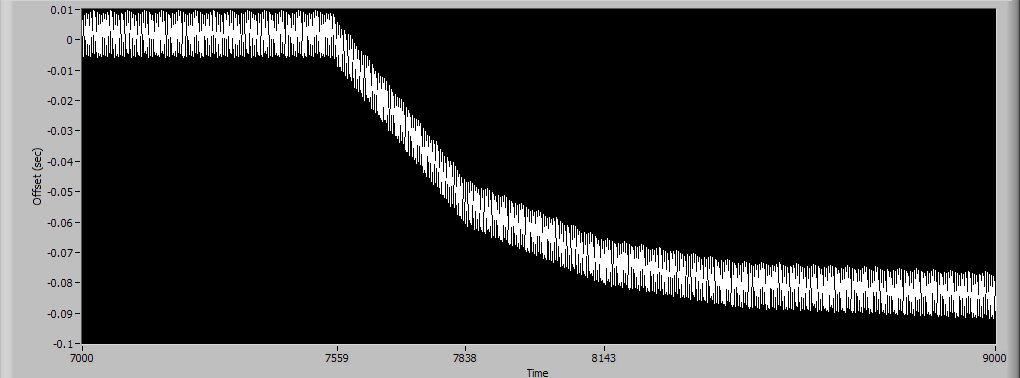
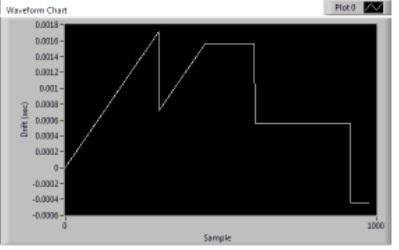
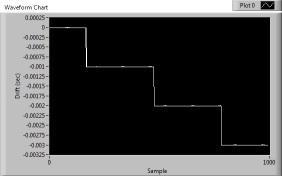
Windows 7 long run: When zoomed in, the increasing areas are the sawtooth pattern, decreasing areas are stairstep. The x-axis is in seconds with the x-axis markers at approximately the inflection points. Windows XP on the other hand, holds steady for much longer periods and then has relatively sudden deviations: Data prior to 7000 seconds was identical to first section of graph. Data was still descending slightly approaching 9000 seconds and then became rock solid again for another 3500 seconds where I ended the run. Eh, what the heck, zoomed out view:
-
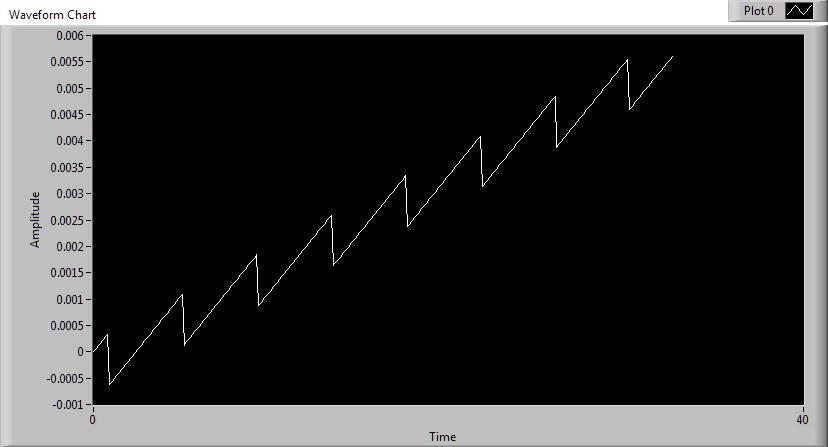
Those steps are 1ms tall on my box and they'll keep diverging ever further apart without resyncing. However, you did remind me that the XP get date/time function only has 16.67ms resolution which accounts for the "noise" I see on the XP box. In fact, all the noise on the XP system probably hides this divergence until a enough time has passed to make the "DC" component apparent since the AC part is going to be around +- 8ms. On my Windows 7 laptop, it takes ~15 seconds for one of those 1ms steps to occur, so you might need to let it run a little while to see the behavior. Weird ... The last two or three times I've run this, I'm getting results that are consistently like this: This is an 8-core CPU, so maybe it has to do with how the CPU cores are assigned? But if you look at my first post it's apparent that it can shift from one type to the other. In fact, this most recent change happened while running. It was initially the flat stair steps then, after a couple of minutes went over to the sawtooth pattern. Edit again: And now it's back to stairsteps again...
-
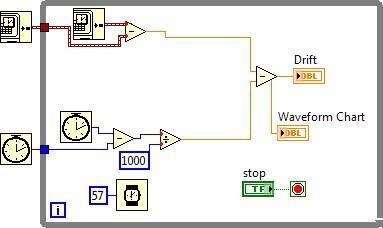
I can't seem to find a definitive source delineating the difference between Get Date/Time in Seconds and the ms Timer. I was thinking that maybe the get date/time checked the RTC at startup and kept track maybe with occasional corrections. But there is definitely some difference between Windows 7 and XP. I've attached a test VI and below are a couple of pictures showing the results between my two systems. Windows 7 (normal result) Windows 7 (only happened once out of a few dozen trials) Windows XP Now, Windows XP does drift eventually. Left overnight, it got up to ~800ms. For Windows 7, the stairstep repeats over time and the drift rate is quite a bit higher even though the "noise" amplitude is not present like in XP. A second Windows 7 system results look almost identical to mine and a secondary Windows XP VM looked very much like the XP desktop I tested on. Anyway, if anyone could enlighten me I'd appreciate it. Thanks, Mike Timer Drift Tester.vi
-
Thanks Jim, This looks like a good solution for those individual situations where you have a mega-case structure. However, I am having trouble getting the code to run reliably. I'm getting Error 1026 at a property node in caseselect.vi Possible reason: VI reference is invalid. It seems like if I leave the errored out instance open AND I open up QD_CaseSelect.vi it will work. When I close one or the other it sometimes works. ... Alright, I dug down into the code and saw you had a 1ms pause in Dynamic Launch CaseSelect.vi between Run VI and FP.Open. I bumped that up to 10ms and it seems to be working now. Go figure. ... Hey, it even detected my dummy cases and let's me tree-collapse them. Very nice. As to the architecture, this is one of those fun projects that has grown incrementally over the years. The initial version was quite manageable, but we've been through a dozen add-on functions since then and it's gotten ever more unwieldy.
-
I was poking through some old code on Friday that had a case structure of 100+ cases and it became really annoying to be working in a case, flip to another one to check what it was doing, then going back to the original case. I would love to have a return to previous case function (How about ctrl+shift mousewheel to flip between the two most recent cases?) I looked in the VI Scripting nodes, but it looks like CaseSel only holds the current visible case and doesn't track previous ones. I gave about 90 seconds of brainpower to thinking about writing some sort of tracker that runs in parallel, but I'm not at all experienced with VI Scripting and it made my brain hurt to try to track each and every case in every open VI. If anyone knows a way to do this easily, let me know. If not, maybe I'll petition the Labview Gods to add a previousVisibleCase property to CaseSel objects. With something like that, I think it would be pretty simple to write an RCF plugin or a ctrl+space shortcut. Mike
-
On Win7, I get ~1ms. Also, for (very) closely spaced time stamps, you can subtract them directly and get the ~50 zeptoseconds. For further spaced ones your method would be preferable if you wanted the maximum resolution as the raw subtractions casts the result to a double. I don't know why I didn't think to try a direct typecast. I completely forgot that primitive existed (almost every cast I do is when converting from variant or flattened string). Asbo: The full resolution is retained if you cast to a timestamp using the reverse method. The formatting is just a control/indicator property. You can set the number of displayed decimal places out to 20 to get the full range. Of course, now I'm concerned about the year 292 billion problem...
-
That High Resolution Relative Seconds looks like it could be just what the doctor ordered, but the whole number value appears to be linked, at least on my system, to the millisecond timer. I wonder what it's behavior is at rollover (I'm trying to move away from a millisecond timer based circular buffer now right now because of the headache in handling rollovers).
-
Greetings, I've been playing around with the timestamp recently and I'd like to throw out some of my findings to see if they're expected behavior or not. One issue is that if you call Get Date/Time in Seconds, the minimum interval is ~1ms. Now this is much better than ~2009 where the minimum interval was ~14ms, if I recall correctly. Meaning, even if you call Get Date/Time in Seconds a million times in a second, you only get ~1000 updates. The other oddities involve converting to double or extended and from double/extended back to timestamp. It seems that when converting to double, at least with a current day timestamp, your resolution is cut off at ~5e-7 (0.5us). This is expected given that you only have so many signficant digits in a double and a lot of them are eaten up by the ~3.4 billion seconds that have elapsed since 7:00PM 12-31-1903 (any story behind that start date, btw?) However, when you convert to extended, you get that same double-level truncation, no extra resolution is gained. Now, when you convert from a double to a timestamp, you have that same 0.5us step size. When you convert an extended to a timestamp, you get an improved resolution of 2e-10 (0.2ns). However, the internal representation of the timestamp (which, as far as I know, is a 128-bit floating point) allows down to ~5E-20 (this is all modern era with 3.4 billion to the left of the decimal). One other oddity, if you convert a timestamp to a date-time record instead of an extended number (which gets treated like a double as noted above), you once again get the 2e-10 step size in the fractional second field. I've tried a few different things to "crack the nut" on a timestamp like flattening to string or changing to variant and back to extended, but I've been unable to figure out how to access the full resolution except via the control face itself. Attached is one of my experimentation VI's. You can vary the increment size and see where the arrays actually start recording changes. Ah, one final thing I decided to try, if I take the difference of two time stamps, the resulting double will resolve a difference all the way down to 5e-20, which is about the step size I figured the internal representation would hold. I would like to be able to uncover the full resolution of the timestamp for various timing functions and circular buffer lookups, but I would like to be able to resolve the math down to, say 100MHz or 1e-8. I guess I can work around this using the fractional part of the date-time record, but it would be nice to be able to just use the timestamps directly without a bunch of intermediary functions. Time Tester.vi
-
Yeah, I wound up taking the guts of their core decimation algorithm it and making it compatible with my own circular buffer implementation. One of the neater things about it is that you can give it start time / zoom factor when you request a decimated array for display. I may have wound up making some edits in there though, I think the default feature was in percentages rather than absolute numbers.
-
Not directly related to your graphing woes, but NI does have a decimation library that I've used before to good effect: http://www.ni.com/white-paper/3625/en giga_labview.llb at the bottom is the relevant bit. It will change the dt dynamically depending on the decimation factor applied which may help alleviate some of your trouble here. Mike