Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-
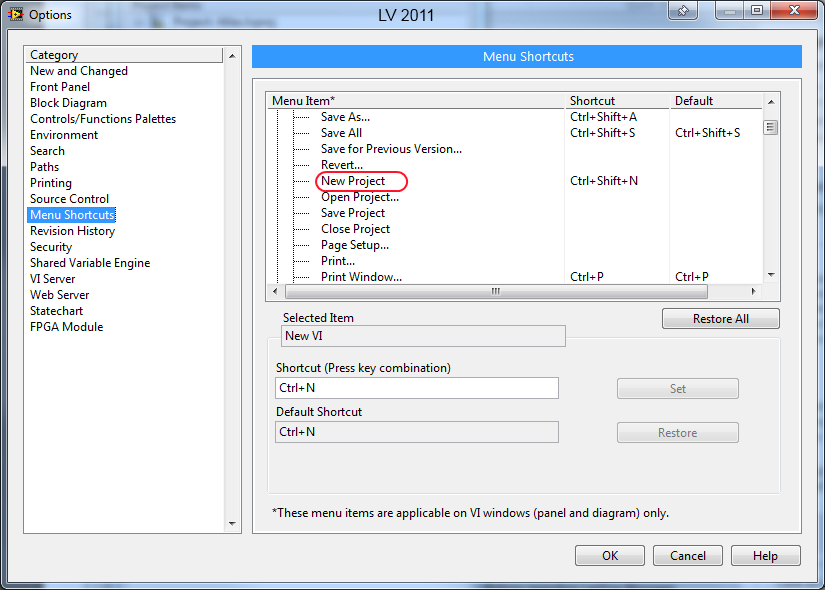
The new Create Project dialog is kind of a cool new feature that I haven't minded at all... until today. I went to set up my normal custom hot key combinations in LV2012 and discovered one of my favorites is MIA! I can now no longer use Ctrl-Shift-N to automatically open a new blank project; I have to go through the dialog. *sigh* A little piece of me died tonight. Rest in peace New Project menu item; you will be missed.

-
I've never thought comparing software products with hardware or physical products was particularly relevant. Retail software products are nothing like skyscrapers. Imagine if I said to an architect, "I want you to design me a new skyscraper I can build anywhere, but I don't know where I'm going to put it or what environmental conditions it will be subjected to." Would you expect the architect to be successful? If I built one copy of the skyscraper in Antartica and another copy in the Sahara, would they both function equally well, or would there be defects requiring changes to the design? What if I built one in an earthquake zone, or a tsunami zone, or on a raft in the ocean, or on the moon? The desktop environment in which retail software products exist is much less constrained than any architect has to worry about. Some companies may do public betas for that reason, but it's not universal in retail software and I really doubt any large software companies do it for that reason. (Except maybe Google with GMail and GoogleDocs) First of all, public beta testing isn't free. You need to hire beta coordinators to manage interactions with the beta testers, assemble feedback, nail down repro cases, distribute the information to the developers, build infrastructures for getting the software to customers, etc. True, beta testers typically do not get paid (though sometimes they get other forms of compensation,) but that very different than claiming beta testing exists to exploit a free resource. Second, in my experience, public beta testing usually results in relatively few new bugs being filed. There were typically at least some new bugs, but not nearly as many as you would expect. Public beta testing of retail boxed software is not a very effective or efficient way to find new bugs. If companies were just interested in saving money they would skip public beta testing altogether. Why do they do it? Depends on what kind of software it is. Sometimes game companies will release betas to test play balance. All the betas I've been part of like to get usability information from customers. They also specifically use beta testing as a way to check how the software works in a wide range of pc configurations. (Equivalent to putting the skyscraper in the Sahara or on the moon.) There is no way any software company can gather the resources required to test their software on all possible pc configurations. When I was at MS Hardware they had a testing lab that contained (to the best of my recollection) ~50 common computers for software testing. Some were prebuilts from Dell or other vendors, others were home built using popular hardware components. Between all the different hardware combinations and the various driver versions for each piece of hardware we still knew we were only covering a very small slice of the possible configurations.
-
LOL. I'm curious how people decide whether they are doing alpha or beta testing? I've always considered it alpha testing if there are large chunks of functionality that have not been implemented, UI is unfinished, etc. Beta testing is when the software is mostly (> ~80%) feature complete, UI is mostly in place, etc. I've had other tell me they don't consider the software to be in beta testing until it is feature complete and all you're looking for is bugs. Thoughts?
-
I have heard a few (too few, imo) other developers say they limit it to UI code too. Unfortunately this information seems to get lost in the enthusiasm of "it's *so* flexible" thinking and people tend to use it as the basis for their entire application. (Because it's "scalable," right?) I cringe whenever I hear someone say, "I'm using a QSM architecture." I take this to mean any code that reads or writes to the clustersaur is encapsulated in a sub vi? I can see how that would be useful for a UI-oriented QSM. I'm not sure how useful it would be in non-UI related QSMs--seems like most of the cases will be doing that to some extent. This idea is helpful though. For a long time I've had this feeling that QSM states need to have some sort of classification if suitable rules are going to be created, but I haven't been able to nail down anything that felt right. The only two classifications I've been able to come up with so far are splits (cases that direct execution down one of multiple possible paths) and joins (cases where multiple execution paths converge.) Splits isn't a very good classification--the case that makes the decision which execution path to take isn't necessarily the case where the execution path actually diverges. Maybe there needs to be a modifying classification for those that change the shift data? (I get the feeling I'm treading down a path well travelled by theoretical computer scientists. Too bad I have no background in theoretical computer science to help me find the way...) You can only do that if B is always followed by the C/CD choice. The primary feature of QSMs is flexibility. People like being able to call any function at any time by simply typing the name. They want to be able to create sequence ABx, where x is any sequence of zero or more additional functions. Right, a sequence might inject a subsequence in the front of the queue. In practice I suspect most of the time that would be safe. Is it always safe? Nope. Can we identify the conditions under which it is not safe? What are your personal rules for reusing a function? If you have a macro A that in turn enqueues BCD, are you free to use any of those in another macro? What about macro m that enqueues arbitrary functions xyz? Are there limitations on what functions m can enqueue? I can think of one off the top of my head--m can't enqueue any function that in turn results in m being enqueued, (unless one is implementing a recursive algorithm and a terminating condition is also implemented.) When I join a project and open the QSM for the first time to a list of 30+ functions, how can I figure out how the functions are related to each other so I know which ones are safe to call? Your macro has the characteristics I consider necessary for my messages: atomicity and independence. It completes the entire operation before returning control to the message/event receiver and it doesn't require other functions to precede or follow it to ensure correct operation. Do all your message handling cases invoke macros, or do they sometimes invoke an arbitrary sequence directly? Do you make sure each of your functions is also independent and will operate correctly regardless of the function called immediately before it? [Note: I've been trying to write a paper capturing my various thoughts on QSMs. Last night I started referring to single-queue style QSMs as having a "public sequence," and those with a double queue (like the JKI SM) as having a "private sequence." It seems to accurately describe the functionality without specifying the exact implementation.] I agree with the first, I disagree with the second. If you accept that QSMs are an appropriate style of programming what basis do you have for rejecting public sequence QSMs? Race conditions are a major (and underappreciated) concern with them, but public sequence QSMs can be used correctly when appropriate restrictions are observed, and private sequence QSMs can be used incorrectly when appropriate restrictions are not observed. Furthermore, public sequence QSMs have the feature everybody wants: interruptability. Thanks for the example. I now see what you mean. I wouldn't use #2 either. Sending a message (event) to tell the receiver to check their messages (queue) is redundant. True, it does do it without polling, but what's the point? It reminds me of some business communication. How many times have you had someone send you an email, then call you up (or visit your desk) and tell you they just sent you an email, but because you haven't read it in the 12 seconds you had between receiving the email and getting interrupted by their phone call, they go ahead and repeat everything they said in the email? Hey, if you were going to repeat the contents of the email to me over the phone, why'd you send the email in the first place?
-
First off I want to make it clear I am not claiming anyone is wrong for using JKI's SM, or a traditional two-loop, single-queue (2L1Q) QSM if that's what they like. I'm not claiming their code is "bad." I've often stated that if the code meets the requirements (both stated and unstated) it is good by definition. Second, my thoughts and comments about state machines are almost always directed at 2L1Q QSMs, not JKI's SM. However, since you brought it up we should probably spend some time on it, but it wasn't my original intent. As I've studied the QSM over the past several years there are two things in particular that stand out as high risk areas: 1. Race Conditions: Using a single queue for both the message transport and function sequencing is a huge red flag. 2. Branching Execution: Implementing conditional logic that changes the sequence after it has started is prone to errors. JKI's SM takes care of the first problem. It does not take care of the second. Okay, so we have an exception to the rule. "Sometimes it's okay to flush the queue." That's good. We all know there are exceptions; the trick is identifying and characterizing the exceptions as completely as possible. Is it ever not safe to flush the queue on abort? Can the queue be flushed for operations other than abort? I don't claim to know the answers. These are questions I've asked myself and been unable to answer to my satisfaction. I assume this is a rule you've adopted to help you use QSMs safely. I don't deny that it works for you, but that rule eliminates a huge chunk of flexibility that makes the QSM so attractive to users. By restricting yourself to only enqueuing to the front of the queue, all your in-sequence branching is in the form of "branch immediately and return." Other kinds of branching logic is very hard (and may be impossible) to write, and even harder to read. As near as I can tell branch immediately and return is not a sufficiently powerful operation to meet the QSM developer's flexibility requirements. To be able to implement the kind of branching options available using a message handler and sub vis you need to be able to add items to both the front and rear of the queue, and maybe even examine and modify the contents of the queue. You're thinking too specifically. Maybe the output from B is being fed into C and C has to occur before D. It doesn't matter. This is just a way to talk about sequences and functions abstractly without getting caught up in the details. Why the requirement exists is irrelevant; it only matters that the requirement does exist. The sequences I presented are all valid requirements for an application's execution flow. Can the QSM handle them as cleanly and safely as a message handler and sub vis? I don't know. I doubt it, but someone might prove me wrong. Branching logic is easy to implement when using sub vis, in part because there is execution time in between subsequent vis where the branching logic can be placed. In a QSM there is no in between time to put the branching logic. It has to be built into the function itself, which obviously limits its ability to be reused. I guess infinitely short transitions is the one way in which a QSM *is* similar to a real state machine. Too bad that leftover property has such a negative effect. QSM implementations seem to have this weird tension going on. You want to break down each function into small pieces to improve reusability, but it's very hard* to implement branching based on results from a previous function, so that pushes you toward larger functions. (*When I say hard I mean it is hard to do it in a way that does not obfuscate and clutter up the code.)
-
I appreciate the vote of confidence, but I know where my strengths lie. Snazzy UIs ain't it... ('sides, I've got my own laundry list of side projects I'm working on. )
-
So I've mentioned before my criticisms are aimed at the multi-loop QSMs commonly produced by beginning/intermediate developers. Single loop QSMs like the JKI SM do solve the problem of race conditions by virtue of separating the message transport and the function sequence, and they are harder to screw up than the typical multi-loop QSM. On the other hand, combining the UI event producer (the event structure) and event consumer (the case structure) into a single loop also has side effects that may not be acceptable to the end user. (Like an unresponsive UI.) No they aren't. JKI splits the message transport and function sequence into separate elements. That's good; it helps eliminate race conditions. But they specifically allow items to be placed on either the front or the rear of the function sequence in any case statement. If it can be done there needs to be guidelines explaining when it should or should not be done. Okay, so sometimes you break the rules. We all do. The question is how do you know when it is okay to break them? What do you do to make sure breaking the rule will not introduce unwanted side effects? I'm interpreting this to mean these rules are sufficient to implement any arbitrary sequence of functions. After all, the most often cited benefit of the QSM is it's flexibility, right? Suppose I have a QSM with cases A, B, C, etc. I have two sequences I want the QSM to execute based on UI inputs: Sequence 1: A; B; C; If results of C = 4, then D, else E; Sequence 2: A; B; C; If results of C = 4, then F, else G; QSMs can work well when the entire sequence is known up front. Once you introduce branching logic based on information obtained during the sequence things get much more difficult. Yes, you can implement this with a QSM. For example, you could add clustersaurus elements for 'Next Step if C=4' and 'Next Step if C != 4.' Or you could add new cases for 'Test C Results for Sequence 1' and 'Test C Results for Sequence 2.' Would you consider either of these solutions as satisfactory or easy to understand as connected sub vis and a case structure testing C's output? Here's another one: Sequence 3: A; X; B; X; C; X; D; Where X=True aborts the remainder of the sequence. Can you implement this in JKI's QSM? Yep, but can't implement it if you only put items on the front of the queue. Your rules are incomplete. You have to be able to flush the queue too. [Edit: In retrospect, actually you *can* implement it by only putting items on the front of the queue, but the code is so obfuscated as to be impractical.] [Edit] And another one: Sequence 4: A; B; if B = True then append D; C; if C = 4 then append E; {D;} {E;} There's no obvious way to implement this functionality at all without being able to add things to the end of the queue or examining the contents of the queue and maintaining sequence specific information in the clustersaur. Any design imposing rules to ensure safe use will also limit the developer's ability to add new capabilities the customer may require. QSM developers like the flexibility and from what I've experienced are loathe to give up any aspect of it. The challenge stands: Show me a QSM template and set of rules suitable for beginning/intermediate level programmers that provides flexibility, maintainability, and predictability. Until I see that I'll continue to oppose the belief that QSMs are appropriate constructs for developers at those levels.
-
Or you could post it to this forum and let others tinker around with it too. I'm just sayin'...
-
In principle I agree with you. In practice it doesn't work. Nobody understands the rules. I've tried to come up with an appropriate set of guidelines newbies can follow to avoid getting into trouble. It either ends up being so restrictive it borders on uselessness or too difficult to be practical. For example: Simple Rules: 1. Only the producer (UI loop), not the consumer (QSM), is permitted to put items on the queue. 2. Always put items on the rear of the queue. If developers follow these rules they will not have race conditions. But nobody does because it takes away one of the primary features people like about QSMs--the ability to interrupt an ongoing process. Difficult Rule: 1. It is okay for both the producer and consumer loops to manipulate the queue as needed, provided the manipulation does not introduce unintended side effects. The rule is correct. Race conditions will exist but become irrelevant if you follow this rule. Except... how does one know if there are unintended side effects? Grab a big stack of paper and start manually tracing through your code like I suggested to Kaz earlier, keeping track of the contents of the queue as you go along. There is no other way. There are situations where it is perfectly safe for either the producer or consumer to add items to the front of the queue, to the rear of the queue, or even to flush the queue. When I try to explain to people why QSMs are dangerous and show samples illustrating the problem, invariably I get objections from seasoned developers who say things like, "That's no big deal. I would just..." Usually they are correct. The solution they propose will work in this simple example application for this specific problem, but what I have a hard time getting across is it is not a viable general solution to the problem. Unfortunately there are also situations where it is not safe for the producer or consumer to do any of those queue manipulations. For any non-trivial QSM it is extremely difficult to tell when it is safe and when it is not. If you don't have an execution flow diagram it is borderline impossible, and it's not necessarily easy even when you do. When I was attempting to come up with general guidelines for safely using a QSM, I quickly realized the QSM can receive any message at any time. In other words, guaranteed sequences of messages are a myth. If I need to guarantee a sequence of procedures occur in order, I have to put them in a single case instead of spreading them between multiple cases. That, along with posts from other forumers (like this one,) led to the idea of atomic messages and ultimately blew up the entire concept of QSMs. When I cleared away the ashes and debris, what I ended up with is what I now call a Message Handling Loop. At the end of the day the best rule I've been able to come up with for guaranteeing a QSM application works correctly is, 1. Don't use a QSM. However, many developers still swear by them, so I am hopeful guidelines exist allowing developers to easily use a QSM correctly--I just haven't seen any. I'm keenly interested in any rules you believe are appropriate. That would be better, but personally I'd really like to see the "Queued" part of the name dropped from all the labels. IMO it focuses too much on the specific implementation rather than the important part--what it is intended to do. Take the QMH. What if I decide to use notifiers or a RT FIFO for a messaging transport? Does it then become a NMH or RTFIFOMH? What they all have in common is they receive and process messages, so why not just call it a Message Handler?
-
As do we all. If the goal is to communicate with other developers we don't really have a choice. [From my Hector post] "I could start calling an apple an "orangutan" and those who know me well would understand my meaning, but when somebody in an online forum asks for a dessert suggestion because the the in-laws are in town and I respond with "orangutan pie," it's bound to cause all sorts of trouble. (Especially when I recommend using peeled orangutans and removing the stem. ) I know I'm unlikely to change the world and get everyone to start calling it a "function machine." I'm sure there are those reading this (if anyone is left now that we've completely derailed the original topic) who dismiss this as a minor semantics issue. I disagree--what we choose to call things often conveys information about that thing. "QSM" implies that pattern is, in fact, a type of state machine when in reality it is not. If instead of "QSM" we referred to that pattern as "Hector," I would consider that a better (if rather arbitrary) name. "QSM" is an extremely poor name for the pattern." I hope the someday the term QSM will be universally recognized as inappropriate and replaced with something better. I don't see that happening without a concious effort from NI. I've heard some of their courses actively taught the QSM by that name. I don't know if they still do. [As an aside, while the QSM Hector's unpredictability is what trips people up, it also intrigues me a bit. I have this nagging idea in the back of my head to try using it for some sort of machine learning applications.]
-
Don't be too hard on yourself. Everyone has to go through the same learning curve. A couple years ago I was helping out on a project implemented as a QSM. It had grown so convoluted it took me over a day just to map the execution flow from one message. That was the day I decided QSMs were not, contrary to popular opinion, the bees knees and started looking for something better. yEd So learning multi-loop programming is the next step for you. You don't have to throw out all the work you've done. You can start by condensing your QSM cases so every case in the structure represents a single public message it can receive from an external source, like what I did in the example above. If you do that and follow the three guidelines I gave earlier that should go a long ways towards eliminating race conditions. Another thing you can do is learn what real state machines are--not the horribly and incorrectly named Queued State Machine. (Or as I sometimes call it... Hector.) Try modelling your application's behavior as a state machine on paper before writing any code. If you can create the correct behavior on paper writing the code is easy.
-
I knew what you meant and I think those are excellent suggestions. Knowing the dependencies during deployment is important if you're deploying your app as components or have external dependencies. I don't do that very often, but I still pay strict attention to my dependencies during development because it has a huge impact on the development process. Poor static dependency management affects my ability to test code, reuse code, and make the correct changes to the code. I don't like to make changes unless I'm confident I know what will happen, and I can't know that unless I also know the dependencies. (Not just static dependencies, but behavioral dependencies as well.) Just out of curiosity, do you code primarily top-down or bottom-up? I've found bottom-up development to be much more flexible as requirements change over the life of a project. For the past couple years I've been focusing my personal development on using implementation patterns and practices that support (relatively) easy and correct refactoring. My goal is to never have to say to a customer, "The application has outgrown this architecture. We'll have to rewrite it." I'm not 100% there (and probably never will be), and some changes that are more difficult than others, but I think I've got a fairly smooth path from a simple two loop single vi to a multi-target distributed application.
-
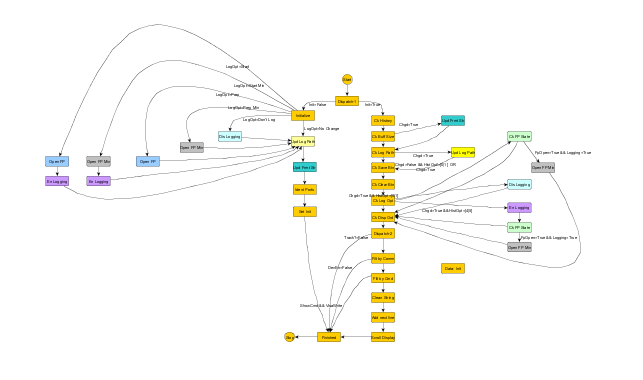
Heh... I like to think I'm a reasonably proficient developer. After spending the last couple hours looking at the Track History QSM, I think your fears are justified. I even took the time to map out the execution flow and I still don't know if it will do what it's supposed to do. If my map of the execution flow is correct, then I don't think it will slow the whole app down. As near as I can tell it terminates fairly quickly. It really depends on how you integrate it into your app. Track History is a perfect example of why I dislike QSMs so much. It might work, but it's a huge pain in the neck trying to figure out how it works and it can be nearly impossible to tell if a change I have made breaks something else. Whenever I have to work on a non-trivial QSM like this one I'm forced to adopt a code-and-fix development pattern, and I don't have nearly the confidence in the code that I do using other techniques. I was going to map out your application too, but honestly I just don't have the time or motivation. I really, really, don't like QSMs. Maybe I'm just too stupid to wrap my head around these things... *shrug* Yeah, but my implementations don't fit very well with QSMs so anything I told you to do would require significant refactoring. If you don't want to impede the main UI make sure nothing blocks execution in the UI loop. You can launch Track History dynamically and send it data on a queue. It's one thing to write some data collection and display tools--Labview is great at helping engineering and scientists do these things quickly. However, your requests are moving beyond the realm of quick tools and moving into software engineering. There is much, much, more to designing good software than figuring out what procedures to string together. Please believe me when I say I don't mean this to be derogatory in any way, but I think you may be getting in over your head a bit. Physicists have specific training and knowledge that allows them to perform their job. So do software engineers. Based on some of your comments on this thread my guess is you'd eventually be able to implement some of what you're looking for, but it will never work quite like you wanted. It will crash, lock up, or maybe the front panel won't respond correctly all the time. Furthermore, you won't know why it has problems. New features will be added a bit at a time until the entire project becomes so rigid and fragile nobody can make any changes without breaking it. Anyone who has been around software development long enough has seen this pattern repeat itself countless times. Can you learn the skills and knowledge required? Absolutely. Do you want to spends months or years studying software engineering so you can write the application yourself? I don't know, that's your call. If this software is important for the physics lab, I suggest you find an experienced LV architect to come in for half a day and help you break down your app into a manageable design. It will save you scads of time and frustration in the long run. I'm sure there are good developers in the UK here on Lava that could help you out. (*cough* Shaun *cough*) If budgets are too tight, check you local LV user group for experienced developers. You might find someone to help you out for an hour or two for the cost of lunch. Again, I don't mean for this to be condescending or dismissive. You're starting a journey across the Atlantic and I'm just trying to point out that a rowboat isn't an ideal vessel for the trip. I understand, but I respectfully disagree. If I don't know how to fly an airplane does that mean airplanes are limited to the ground? Or does it just mean I need to learn how to fly an airplane if I want to be able to use it? Why is that bad? Yes, you can do that. And the poor sod trying to figure out what's going on (that would be me) has to trace into "Orbit: Send & Receive", then follow that into "Orbit Param: Proc.increment", only to discover you're eventually sending the execution back to "Orbit: Send & Receive." (Perhaps after a brief detour to "VNA: Read" and "Graph: Display", which I also have to examine to see if the execution is diverted anywhere else.) All this, just to figure out you're doing a simple loop. What advantage are you getting out of having "Orbit Status: Get" turn around and queue up a bunch of additional cases? Flexibility? You know what else is flexible? Jello. Doesn't make it a good building material. The ability to interrupt processes like you mentioned with users changing the temperature of Shaun's oven? Nope, not with any sort of reliability anyway. Take your exit button as an example. When the user hits the exit button the UI loops puts "Macro: Exit" on the front of each of the queues. Lots of people do this with the expectation that it will be the next message read and everything will shut down nicely. They're all wrong. (Most of the time. It can work under very limited restrictions that nobody ever follows.) Suppose the bottom loop has just dequeued the "Orbit Status: Get" message, but has not entered the case structure. Then the event loop places "Macro: Exit" on the queue. How many iterations will the lower loop go through before "Macro: Exit" is processed. Here's a hint--you've built a race condition into your app. Were you aware of that? (Kudos if you were. I've talked to many experienced developers who didn't realize it.) Here's an exercise for you. Trace out the execution flow of your lower loop like I did in the diagram above. Now, for each arrow leading from one case to another, figure out what happens when each of the messages from the UI loop is placed on the queue during that transition. You've got five different messages the UI loop can send. On the Track History vi there are roughly 40 transitions, so that would be 200 different potential race conditions I'd need to verify will not cause problems. Off the top of my head I'd guess your app has roughly the same number of transitions. Oh, and there's not really any way to automate this testing, so you have to verify it by hand. Be sure to take good notes, because every time you make a change to the execution flow diagram or add another message from the UI, you'll have to go through the process again. If you find it easier to develop your stuff using QSMs, that's great. They can work sufficiently well for small, uncomplicated applications with no growth potential. In my experience they don't scale well at all and, like a Jello house, collapse under their own weight long before they become useful to me.
-
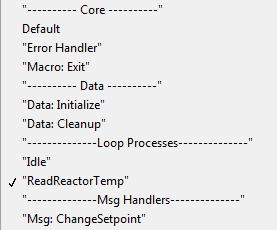
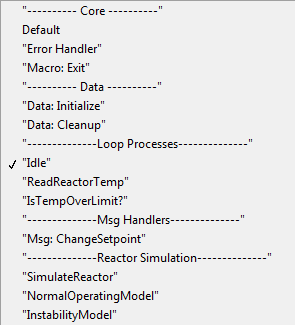
Let me explain in a little more detail. On the left is the cases from the QSM reactor controller. On the right is the cases from a functionally identical reactor controller using sub vis. (You can review both loops in the attached project.) With the QSM the case structure has four "private" cases that should only be enqueued when ReadReactorTemp is executed. (IsTempOverLimit?, SimulateReactor, NormalOperatingModel, and InstabilityModel.) When I open the list of cases there's nothing to indicate which of them should be private. Contrast that with the list of cases when using sub vis. Every one of the cases handles a message received from an external entity. [Edit - Every one of the cases I added. The first two sets were built into template and I didn't mess around with those.] Once I've examined the loop and am convinced it works correctly I don't care about the details. With the QSM every time I open the list of cases I'm faced with implementation details. In the past I have tried various things to differentiate "public" cases from "private" cases in a QSM, like indenting the names of private cases. It helps a bit, but in the end the "loop api" is much easier for me to use and understand when I don't have to sift through all the private cases. When private cases exist it can be very difficult to present an appropriate level of abstraction to the developer. I'll just go ahead and pretend you didn't say this. I've said before the QSM is great if writing code fast is your goal. I read far more code than I write, so spending a few extra minutes to make the code readable is a trade I'll take every time. In that particular case, yes. If I had to do that exact same fp update in response to more than one message, the first thing I'd do is copy and paste using local variables. Eventually I'd move the limit checking logic to a sub vi. Yeah, it does cause some code duplication. IMO that's the lesser of two evils in this situation. QSM vs Sub VI.zip I apologize if I was not clear. Yes, each loop needs to have its own receive queue; however, each queue does not need its own set of enqueue/dequeue vis. You can use the same vis for all the queues in your app. Each time the Obtain Queue function executes it creates a new queue, as long as you are not using named queues. I'm not quite following #2. Do you mean have the dequeue fire a user event when it receives a message on the queue, in order to release the event structure block? It doesn't work. The dequeue vi has to be executing to check the queue or fire a user event, and it won't execute until the event structure releases its block. There is another strategy several of us prefer. Use user events to send messages to event handling loops and queues to send messages to other loops. I have a hunch you'd see very significant performance problems if you implemented strategy #2. If you have multiple receive mechanisms in a single loop, you *have* to use a timeout and polling. (Unless you implement something like AQ's priority queue.)
-
Hmm... can you describe a use case where you want to stop and restart a message receiving loop? The only time I ever stop a message loop is when the component is being destroyed. If I need to start the component up again it creates a new message receiving queue. Okay, that's pretty much the strategy I use too, except only UI components have event loops. It seems like an unnecessary extra step since I don't have to worry about stale messages. On the other hand, it does more clearly separate the component's control/request interface (used by the owning component) from the event handling interface (used by subcomponents.) Maybe I'll try it out and see how I like it...
-
Can you explain what you mean by leftover messages? So since any given component can receive both control messages and response messages, you implement two message receiving loops in them? Or do you use the "event structure inside the timeout case" technique?
-
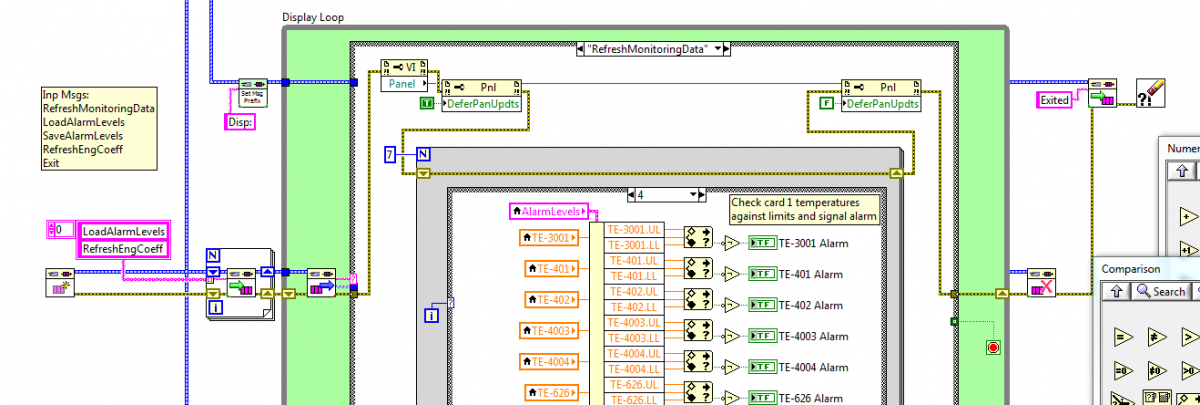
That's correct. However, you have two message receiving mechanisms in that loop: the queue and the event structure. You have to make sure both are being serviced. If you don't have a timeout on the event structure none of the messages from the lower loop will be processed until the user initiates some action on the UI. I've attached a simple Reactor Controller project based on your template where the event structure does not have a timeout. Use the up/down buttons to change the temperature setpoint and watch what the UI reports as the current temperature compared to what the debug indicator shows is the current temperature. Then take the temp up to 163 degrees and watch what happens. After you do that, change the event structure timeout to 1 ms and do the same thing with the temp setpoint. See how the UI is able to respond to the messages from the controller loop? That's because the timeout on the event structure is allowing the dequeue vi to process messages. This problem is why I don't think it's a good idea to have multiple message receiving mechanisms in a single loop. QSM Reactor Controller.zip Sub vis are useful for more than just reuse. They also serve as a way to abstract away the details and using the context help window to read notes about it helps me a lot. When I'm sifting through a chain of sequential cases I find the details are too exposed and I have a harder time seeing the bigger picture. Plus it's way easier to test a single vi in isolation for proper behavior than a single case in a large QSM. The reactor controller is a perfect example of someplace I'd use sub vis instead of sequences cases. The sequence of 5 cases (SimulateReactor, NormalOperatingModel, InstabilityModel, ReadReactorTemp, and IsTempOverLimit?) that executes every 50 ms should be compressed into a single message handling case with sub vis chained together. It would be far easier to understand what is going on than switching between multiple cases. I'll admit on rare occasions I do find it more efficient to execute a fixed sequence of case statements instead of putting each one in a sub vi. Here's an example from a recent project I did. In this instance I had to do a lot of front panel updates. Rather than using control references and sub vis I decided to put all that code on the UI block diagram. The difference is I don't make each one a separate case in a string based case structure; I put it into a For loop and interate through them sequentially. It's much clearer to me this way because I can easily see that all these actions occur when the RefreshMonitoringData message is received. Also, my main case structure isn't cluttered up with extra message handlers that shouldn't be available outside of this one message. So did I. And so do many other developers. There's more to it than that. Having two event queues behind the scenes occasionally trips people up. In general, there are far more posts asking "Why don't my events work right?" than there are posts asking "Why don't my queues work right?" You've been around a long time asbo... I thought you had already jumped to oop?
-
Huh? What do you mean? I've heard of "outside-of-work" but I've always put it next to Santa Claus on the believability scale.
-
This should be item #1 in your list. The other two are possible because you do this first. Dependency Management: For larger applications this is the most important requirement few people ever consider. [Note to Elijah: Time to write another article.]
-
And how do I regain membership?
-
Yep. That's been one of my two primary concerns with the AF--command-pattern messaging. It causes static dependencies to permeate the application to the point where you can't work on any single component in isolation. Developers have to write extra code specifically to break the dependencies. Nope. Child classes are statically dependent on parent classes, but parents are not dependent on children. Loading ActorA.lvlib will cause Actor Framework.lvlib to load, but it will not cause ActorB.lvlib to load unless A uses vis from ActorB.lvlib. I really like lvlibs too. Given your time constraints that may be the best route for you. In the future you can prevent this by switching from an "input-only" messaging paradigm to an "input-output" paradigm. To do that with the AF you'll have to implement an event callback mechanism so the owning actor can tell the subactor at runtime which of the owning actor's messages to send when each event occurs.
-
I agree it is an improvement over most QSM implementations. The JKI SM is a single loop QSM whereas traditional implementations are multi loop constructs. I have mentioned in the past my criticisms apply to multi loop QSMs, but I'm not always very clear about it. There are a few things I don't like about JKI's SM, but they are soft objections having to do with style and clarity rather than hard objections due to inherent technical flaws (as is the case with multi-loop QSMs.) For instance, I'm not at all fond of the practice of using cases as a substitute for sub vis. I think using a queue to control execution flow unnecessarily obfuscates the code and is more error prone compared to simply connecting sub vis on a block diagram. Complex branching can get especially tricky using that technique. You are correct that the JKI SM only has one external message receiving system, but the private queue is in effect an internal message receiving system. Yes, keeping the queue private does eliminate the most egregious flaw of multi loop QSMs. It also encourages developers to avoid creating sub vis and lends itself to "sequential message" thinking. These habits create problems for developers moving from simple data collection and recording tools into applications with interactive UIs. Another thing I don't like is using user events for the primary communication transport between loops. Events are... quirky. Every so often a thread springs up with somebody having a weird issue with events not behaving how they expect. (Somewhere in the back of my head I have the notion that multiple event structures on a single block diagram is dangerous, but the memory is vague and could be wrong.) Events favor broadcast or observer-based systems and I've described on other threads why I don't like those. Queues are far more transparent, predictable, controllable, and just easier to work with. I would consider the JKI SM for things like a dialog box in non-LVOOP code. Michael's 3-Button dialog rewrite is a good example. It's a relatively simple UI element that may contain more functionality than can comfortably fit on a block diagram, doesn't need real time communication with other code, and for portability shouldn't call any sub vis. Beyond that I think other techniques provide more flexibility and better readability.
-
Sorry, I forget that experienced LV developers have lingo that newer users may not be familiar with. I meant to connect the Timeout input on NI's Dequeue function to a front panel control on your Parse States vi. That way you can change the Timeout value on each when you create copies of the template without having to mess around inside the the Parse States vi. It depends on what you're trying to do. It's not hard to use a few objects in your applications, yes, creating a well-designed fully object oriented application isn't something you'll know how to do after a couple weeks of poking around... or even a couple months. There's a lot of stuff to learn. Of course, learning how to create a well-designed non-oo application is going to take time too. BTW, you know those three rules of thumb I gave you to get started on multi-loop programming? They are not generally accepted by the larger LV community. You might find yourself having to defend your decision to follow them if you post code or questions online. We who distrust QSM designs are still in the minority. Just giving you a heads up...
-
...if I'm lucky I'll get to keep my man card. I just received a cRIO and miscellaneous hardware for a new project I'm starting for a client. Included several strain relief kits were included for 2 and 4 position screw terminals. Simple little two piece plastic shells to go around the terminal blocks, right? Yeah... it took me 15 minutes of fiddling around to figure out how they mate up.
-
Yeah, that's not quite the same--it doesn't show dependencies. Adding the library to a new project will also yank in all the dependencies so you can get an idea of what else it is linked to. If it drags in a sizeable chunk of your project that could be part of the problem.