Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-
What is the name of this beautiful evil text-based temptress, and what led to your breakup? Details man... we need DETAILS!
-

Futures - An alternative to synchronous messaging
Daklu replied to Daklu's topic in Object-Oriented Programming
After my last post I tried to find the information I had originally read. Searching for "software engineering futures" or any of the many variations I tried returns long lists of articles on the future of the industry or stock market trading. The one small piece of information I could find about Futures as a software construct was in Java documentation. That described blocking as an integral part of Futures. To me, not wanting the results from the Future defeats the point of using the Future in the first place. I agree implementing the Java model in Labview is problematic, but by stepping back and looking at the intent of Futures instead of their behavior in Java I think we can come up with reasonably good alternatives. Their intent appears to be to avoid blocking the current thread while waiting for information not currently available by creating a token that will contain the information later. What I did is apply the concept of Futures to messaging between existing threads. The implementation is very different from Java's but the intent is the same--avoid blocking the current thread by waiting for information. I don't do Java programming, but my feeble understanding of the normal programming model is the app has a main thread and the developer creates new threads for specific asynchronous tasks. From that point of view it makes sense for Futures to automatically spawn new threads--the asynchronous code requires it. As near as I can tell the Java implementation closely follows the Asynchronous Call and Collect model made available in LV2011. In Labview we can write asynchronous code without dynamically creating a new thread (or Start Asynch Call in LV) so I don't think it is a necessary feature in a LV implementation. I know you have a much better understanding of the low level interactions between LV and the OS than I do, so this is a request for clarification, not an attempt to correct you. Even though there is a theoretically unbounded pool of operating system threads, the hardware still limits the number of parallel activities that can take place. Java may allow a unbounded number of operating system threads while LV transparently manages a fixed number, but a program written in G can have an unbounded number of "Labview threads." I don't see how there is much difference between Java's OS thread pool and LV's technique of dynamically mapping parallel execution paths to a fixed thread pool. They are both constrained by the same resource--CPU threads. Can you elaborate? I agree achieving the same level of genericism isn't possible in Labview. Given NI's focus on providing a safe environment for novice programmers it may never be possible. I don't agree the concept of Futures is useless for LV developers simply because we can't implement it in the same way. My car isn't a Audi, but it still beats using a tricycle for transportation. -
Your question is far too broad. It's a bit like asking, "I need flexible transportation. Should I get a skateboard?" There are dozens of additional details we need to know before we can help you decide if a skateboard is a good solution for you. It could be a great solution for a teenager living in suburbia. It's a much less desirable solution if you need to do grocery shopping or had a leg amputated. In the same way there are dozens of additional details about your specific application we'd need to know about before we can suggest an architecture. 0_o listed some of them. You say you want "reusable code that can be modified for different projects." How different will the projects be? What elements will stay the same and what elements will change? Are you working in a lab environment where each project is a temporary setup and tweaking code is part of the discovery process, or a production environment where code needs to be extremely stable and software releases are significant events? The nature of your question leads me to believe you don't have a lot of experience designing software. (I see you've used Labview off and on since 98, but writing code is not the same as designing software.) I suggest your first step to creating modular (and reusable) software is to learn how to separate the user interface from the business logic. Write your application so you could replace the entire UI without breaking any of the business logic. You can use the lessons learned from that exercise to modularize the rest of your application. To answer your question more directly (but less usefully,) I would say using a standard state machine template is best if it's the best solution for your requirements. Perhaps slightly more useful advice is this: use the state machine template only if you are designing your application (or that part of your application) as a state machine. As an aside, I wouldn't consider any of the bundled templates an "architecture." They are implementation templates, not architectural templates. An architectural template would be a LV Project prepopulated with tens or hundreds of vis implementing the architecture of choice.
-
Futures - An alternative to synchronous messaging
Daklu replied to Daklu's topic in Object-Oriented Programming
The information I read about them described them like an IOU in a "I don't have the data now so I'll give you this instead, and later on you can turn it in to get the data" kind of way. The point was to avoid blocking, not just postpone it. That said, I've not used them in any other language nor seen how they are implemented, so what do I know? For all I know what I implemented aren't really futures. -
Futures - An alternative to synchronous messaging
Daklu replied to Daklu's topic in Object-Oriented Programming
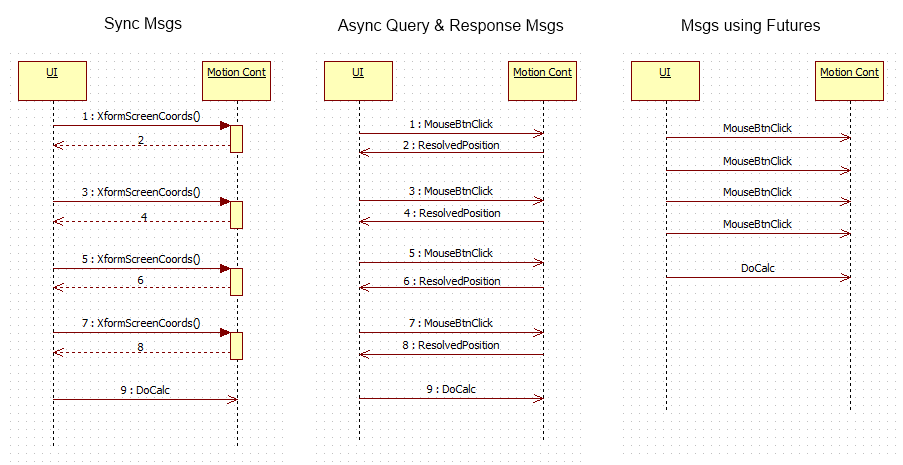
Agreed. I haven't needed futures again in the 7 months since the original post. Conceptually I understand what you're saying, but I'm having a hard time figuring out if it would have been a simpler solution in my particular case. (In fact, my actual implementation does use something similar to what you describe, though in my case it is simply a data identifier and is more of a "what" block than a "why" block.) Probably not, but let me think out loud for a bit. Anyone can jump in with alternatives or to point out flaws in my reasoning. The most obvious difference between query/response messaging and futures messaging is the number and sequence of messages transmitted between the two actors. Here are sequence diagrams for synchronous messages, asynchronous query/response messages, and asynchronous futures messages. One of the issues I've struggled with in actor based programming is message sequences. Understanding an individual actor's behavior in response to a message is fairly straightforward, but combining actors to create higher level behaviors often requires coordinating actors' actions using specific message sequences. It can be quite difficult to figure out a higher level behavior by reading source code when you're having to trace messages all over the place. With the query/response messages, the behavioral code is split between the MouseBtnClick event and the ResolvedPosition message handler. Not only do I have to mentally combine the behaviors from those two locations, but I also have to figure out if there are conditions where MotionController will not send ResolvedPosition messages and what happens in the UI if it doesn't receive all the ResolvedPosition messages. This is not insurmountable, but it does require a fair bit of work and I'm not entirely happy with the solutions I've used. The "fire and forget" nature of futures allows me to write the behavior's implementation largely within the code handling the button click event. There is no ResolvedPosition message handler, so I can look at that one block diagram and see the entire sequence of actions that occur in the UI component as a result of the mouse click. In this particular case the code is much easier to read and reason about. (At least it is for me, but I wrote it so I'm hardly an unbiased observer.) There are other difficulties with using query/response messages here. My UI's display and behavior change when going through this process, so it is implemented as a separate "Alignment" state in UI code. From the user's perspective the process is complete as soon as the fourth mouse click is done. From the programmer's perspective the process is complete when the DoCalc message is sent. The mismatch makes defining an Alignment state exit condition problematic. In my state machine implementations data that is specific to one state is not available to other states. The ResolvedPosition data will be discarded when the UI switches from the Alignment state to another state. On the one hand I can't leave this state until all four ResolvedPosition messages have been received and the DoCalc message is sent. On the other hand, the user expects the application's UI to revert back to normal after the fourth button click. How do I satisfy both requirements? Potential options include: - After the fourth button click, wait an arbitrary amount of time for the remaining ResolvedPosition messages. - Move the ResolvedPosition data from state specific data to state machine data, so the following state can continue the Alignment process. - Refactor the UI layer's state machine so UI Display and UI Behavior are separate state machines. None of the options were particularly appealling at the time. The first two seemed like bad ideas (still do) and third was too time consuming and adds a level of complexity that wasn't needed, since this is the only place where changes to UI behavior and UI display aren't simultaneous. Personally I'm not a big fan of query/response message sequences. I'm not opposed to them on principle, but they don't seem to fit very well with how I do event-based programming. In general I try to push data out to where it will be needed rather than pull it in by querying for it. Like I said earlier I haven't used futures again since my original post, and to be honest I'm not entirely sure what combination of conditions makes it seem like the right solution in this case. It could be that the UI doesn't actually use (or even see) the data in the future--it just holds on to them until the user has clicked the button four times and sends them to the Motion Controller for processing. It could be that I wanted to keep the transformed data type out of the UI code to help maintain encapsulation. It could be that the UI already had some inherent statefulness I wanted to leverage. It could be that subconciously I had a solution looking for a problem and I've become attached to it. It could be all of the above or none of the above. I dunno... I think we're talking about slightly different ideas of "state." An application's or component's "state" can be said to have changed any time a piece of its data in memory has changed. I'll give that concept the adjective-noun description, "data state." In this thread when I'm referring to state I mean "behavioral state," where an application or subsystem responds differently to a given input. I usually implement that by changing the set of message handlers processing incoming messages using techniques I've described elsewhere (though when faced with time constraints or very simple behavior changes I might grit my teeth and use a flag instead of implementing an entirely new state.) My remark about implementing a new state being "too heavy" refers to adding a new behavioral state to a state machine, not simply adding a flag to change the way a specific message handler works. I agree the total amount of memory used by the application to store the application's data state isn't reduced by an appreciable amount, if at all. Run-time decision making has to be based on a value somewhere in memory regardless of the implementation. I'm leaning towards disagreement on the question of complexity, but source code complexity is mostly subjective anyway, so I'll not belabor the point. I assume the "new state" you are referring to is being implemented as a flag of some sort, such as a "waiting for message" boolean. I've seen code go down that path (and written some myself) and agree it leads to a tangled mess if one does not keep the larger architecture in mind. In my terminology, a chunk of code is only a state machine if it can be described by a state diagram. (Note to readers: A flow chart is not a state diagram.) Systems whose behavior is controlled by a flag parade often cannot be represented by a state diagram. Adding a "new state" to code that is not implemented as a state machine first requires a state machine be implemented. And then the new state must fit in with the rest of the state diagram, with clearly defined entry conditions, exit conditions, and behaviors while in that state. Actually, I set the timeout to zero on the WFN function specifically because I didn't want to bind them together in time. The notifier was just a convenient way to to make the future a by-ref object. In retrospect it would have made more sense to make my future using a DVR instead of a notifier, since the option of waiting until the notifier is sent is unnecessary in my case. If the application logic made it possible to use the future before it was filled, I'd probably try to do some sort of data validation at the point where the future was redeemed. The Future.GetValue method could return an error if the notifier has not been set. MotionController would detect that and send out an "AlignmentCalculationFailed" message. The error would be forwarded to the UI, which would then alert the user that the alignment needs to be redone. (That's just off the top of my head though... no idea if it would work well in practice.)
-
Cool video. Too bad it stops just when it was getting interesting. I don't quite understand your comment though. Game theory is just a way to predict behavior of beings who behave according to their own self interest. It doesn't cause people to act in their own self interest. (And to clarify, by "self interest" I mean whatever gives a person the most utility, satisfaction, etc., not what is in best long term interests.)
-
I suspect most people--including me--would agree with you. I just don't think it's a realistic goal. How do you propose we do that? The economy is perhaps one of the most complex systems we deal with. It has so many inputs and interactions it is impossible to fully understand. We don't have the ability to manage it, much less control it. Heck, we don't even know how measure it adequately. It's not ignorance of scientific facts. It's distrust of scientists who have become political advocates. It's recognition that science is not, and never has been, the arbiter of truth. Beating people over the head with "facts" and "scientific consensus" is useless because it entirely misses the point. (Not that you have been doing that, but it seems to be the tactic most frequently employed by those espousing stronger environmental policy.) Disagree. The laws are--for the most part--adequate. Laws didn't prevent Enron or Bernie Madoff from happening. More laws and more regulations isn't the answer. It doesn't work. Throughout history people have shown remarkable ingenuity in finding loopholes in the laws (or ignoring them altogether) to advance their own self-interest. The idea that we can create a legal system to force people to behave morally is a fallacy. Strongly disagree. How do you propose to accomplish this? A corporation is simply a group of people united in a common interest. You cannot legally limit a corporation's ability to influence government without also limiting the individual's ability to influence government. Public participation in government via voting, contacting their representative, political discussion, etc. is what democracy is all about. Corporate influence over legislation is not inherently bad. Can it be misused? Yes. Is it sometimes abused? You bet. Is that sufficient reason to trample all over the first amendment? Nope, not in my opinion. (By the way, corporations already are more limited than citizens in their ability to affect the political process.) Several objections: 1. Corporations *do* pay for things like pollution and they directly affect their profit/loss calculations. They have to purchase, implement, and maintain pollution control system. They pay hazardous waste disposal fees. They are subject to penalties when systems fail or illegal emissions are discovered. They may not pay enough to induce them to behave how you think they should behave, but they do pay. 2. Before you can implement a "change so corporations make better choices," you have to define what a "better choice" is. That's far too vague to be actionable. "Better" is entirely subjective, so you'll have to be specific. You may think it is better to impose stricter environmental controls on industry, but the 400 people down at the paper plant might disagree when the plant closes because it cannot afford the costs associated with compliance. I don't personally know anyone who thinks that, though I can understand how the ideas can be interpreted that way. Corporations will act in their own self interest; that is patently obvious. But you know what? Everyone acts in their own self-interest. The only difference is a corporation's self-interest is measured in dollars and an individual's self-interest can't be measured. Interesting article. Thanks for the link. I knew McCain and Feingold were disappointed with the decision, but the conversation just reaffirms what I said earlier. They are disappointed (perhaps rightfully so) because of the immediate impact the decision has on campaign financing. Not once do they talk about the potential consequences of allowing the government to restrict political speech, which at the core is what Citizens United was about. I don't like the effect of the decision any more than you, but the effect of the opposite decision is much more frightening to me. Restricting speech is not the correct way to clean up politics. Who is going to audit the auditors? Agree that seems silly and a huge conflict of interest. It may be they currently have too much control over the regulations, but that doesn't mean they shouldn't be allowed input into the process. Does a judge lose objectivity because he listens to a defendant's argument? The only way a judge can act fairly is to hear arguments from both sides. Why should regulatory agencies be any different when making decisions on regulations? Regulatory agencies are in a position of power, and any form of power is subject to abuse by those who hold it. We can put checks in place to try and prevent abuse, but they are all imperfect and corrupt people find ways around them. Taking away a corporation's voice isn't the answer to corruption. Read the article--unimpressed. Listened to the podcast--still unimpressed. Downloaded the study and read it. Now it makes more sense but I'm still unimpressed by it, and even less by the NPR article because it appears to willingly overlook the realities of the situation. (And I usually enjoy NPR.) The article's tone strongly suggests that corporate lobbying is used to exert unethical control over legislation, broadly painting corporations, lobbiests, and congress as immoral for participating in the activity. In reality, congress' real choice was to either pass the bill allowing them to bring in the money at a 5% tax rate or not pass the bill and let the money sit offshore. The study even points out evidence that businesses often leave their offshore earnings in foreign accounts rather than pay the 35% tax rate to bring them back to the US. NPR doesn't mention that at all. Furthermore, the intent of the bill was to allow the businesses to repatriate the funds for the purposes of creating jobs. (It did not achieve that goal for a variety of reasons outlined in the study.) The NPR article is a classic example of a false dilemma. It presents the businesses as having the option between 'being selfish' and lobbying congress for the 5% tax rate at the expense of Joe Q Public or 'being good corporate citizens' and paying the full 35% tax rate. That is inaccurate, misleading, and irresponsible. It also feeds the public perception that corporations have undue influence over the legislature, when the study doesn't claim or support that idea in any way. Who is the real immoral entity in this scenario?
-
I assume you're referring to class members like "Message Constant.vi" and "Message Control.ctl?" Message Constant.vi allows me to put the class constant on the block diagram palette. It doesn't have any terminals and is not intended to be used directly on block diagrams. Message Control.ctl allows me to put a class control on the front panel palette.
-
I'm getting a decidedly anti-corporate tone from your posts. Forgive me if I'm reading too much into them. If I understand correctly, you are essentially criticizing corporations because they are inherently amoral and you believe they should be held to a moral code outside of the law. I believe expecting a corporation to behave morally outside of a legal framework is irrational and impractical. Just as well to criticize a tiger for eating meat. First, there is no universally accepted moral code. What I think is moral may be different from what you think is moral. Whose moral code should businesses adhere to? I agree sometimes corporations act in ways that upset me. Consumers have a couple ways of influencing the legal but morally questionably actions done by businesses--we can choose not to purchase their products and services (unless the business is a monopoly over a necessary service) or we can lobby our legislature to create a law making the action illegal. When enough people agree their actions are immoral, the business is prompted to change their actions. Second, there are likely to be undesirable side effects to self-imposed moral restrictions. For example, suppose a significant fraction of the population believes organ transplants are immoral. Should transportation businesses refuse to transport the organ because it is enabling immoral behavior? How do you justify that decision to a grieving mother whose child died because a suitable heart in Miami couldn't be flown to Chicago? Third, like it or not our society is built on competition. The competition forces businesses to seek ways to do things faster and cheaper. There's very little room in the business environment for a business to voluntarily adopt purely moral policies that increase costs. That puts the business at a competitive disadvantage, possibly to the point of causing the business to shut down. Who suffers most when that happens? The employee who find themselves without a job and the shareholders now holding worthless stocks. In the case of public companies the executives and board of directors are caretakers of the public's money. Unnecessarily decreasing profits is irresponsible use of the shareholder's money. "You can't legislate morality" is a phrase I remember hearing from many abortion rights activists. I tend to agree with that, though to be more accurate I'd say, "you shouldn't legislate undecided moral issues." I believe it is a valid general principle that helps preserve our freedom when it is applied to legislative ideas. At the end of the day the highly publicized failings aren't caused by inherent flaws in corporations or governments--they are caused by human nature. Any system preventing everyone from acting on those less desirable traits (greed, envy, etc.) will necessarily restrict our freedom to act on our more desirable traits (compassion, honor, etc.) At that point we are no longer human, we are robots. Typically the public reaction to Something Bad Happened™ is to demand the government to do something to prevent it from ever happening again. I get the impression people believe it is their right to not have bad things happen to them. We expect to create a system which prevents imperfect beings from behaving imperfectly. The long term consequences of that mentality frightens me. Freedom means that people are free to choose actions that advance their own interests at the expense of everyone else. That's not to say there should not be consequences for those actions, just that we cannot reasonably expect to prevent everyone from participating in the action. Like I tell my kids, "Life isn't fair. Get used to it." I assume you're talking about the recent supreme court decision regarding corporate political donations? That a whole 'nother rat hole to explore. For the record I think the decision was correct even though I don't like the consequences of it. Most of the objections to the decision I've seen center around the impact of the ruling. I'm not particularly fond of having the supreme court issuing rulings based on expected side effects. Their job is to interpret the law as it was written and intended. We have a mechanism in place for changing laws and the constitution. Hoping the supreme court will short circuit the process is asking for trouble. Agreed, though regulations and regulation agencies are not the solution they are often made out to be. Often regulation agencies are captured by the industries they are designed to oversee. (See Regulatory Capture.) That can be worse than no regulation at all. What's the solution? The agency cannot operate in a vacuum; it has to have close connections with the industry it oversees. It would be irresponsible for an agency to unilaterally impose restrictions without understanding how the businesses in the industry will be affected. It is necessary and proper for any entity--individual or corporation--to have the ability to present their point of view to those who govern them. How do you stop a business from having "improper" influence over the agency that regulates it without eliminating its ability to be heard? For that matter, how do you define what is "improper?" Not likely. There's little market for a soda that blathers on endlessly when you open it.
-
You're an employee of a corporation. Have you shed all your morals? Contrary to popular belief, I certainly didn't check my morals at the door when I was part of Microsoft. I've run across people who seem to have few moral guidelines, but they didn't become that way because they were part of a corporation. I agree with this. I disagree the fault lies with corporations--I lay the blame squarely at our own feet. Corporations chase profits because that's what the public has told them to do, as evidenced by where we invest our retirement money and stick our children's college tuition. I'm also unconvinced corporations should consider morals outside of laws and tacit agreements made with their customers. If there was demand for Seal Soda and it was legal, then yes, I expect some company would step in and provide it. Morals are nothing more than one's idea of what's right and what's wrong. When enough people agree a particular behavior is immoral, the moral code is made into law and imposed on the entire society. However repulsive I find it personally, I'd argue the legality and demand for Seal Soda is sufficient to show grinding up baby seals isn't universally immoral. Why do any of those things? Why do anything at all? I don't think it's the government's responsibility to protect us from All The Bad Things in the World That Might Happen . (I'm not real popular with either of the major political parties.) Democracy and the free market are pretty good at giving us what we want. They are not good at giving us what we need but don't want. We'd have to toss out the constitution and create a benevolent dictatorship (how's that for an oxymoron) with broad enough power to implement things against our will. Frankly I don't see that happening any time soon. I agree with this part... ...but not this. A corporation in itself is nothing more than a legal construct. It has no will, no morals, and no objectives independent of the people who make up the corporation.
-
I see. When I'm feeling cynical I would agree with you. Usually I prefer to believe people are generally good and, for the most part, those in government are trying to do the right thing. I may disagree that what they are doing is the right thing, but I believe they think it is the right thing. Yeah, I agree. It may be 5 years, 50 years, or 500 years, but at some point the problems will outpace our ability to develop technology to overcome them. Personally I don't think humanity will be willing to make the necessary changes until after some worldwide catastrophe. Society as a whole operates reactively rather than proactively. The story of Easter Island is an interesting microcosm of what the future may hold for us. (As an aside, I smile inside every time I hear someone say "earth first" or some other eco-friendly catch phrase. I'm pretty sure earth will survive no matter how badly we abuse it. What possibly won't survive is people. Shouldn't they be saying "people first?") Green solutions are subsidized too so I have a hard time accepting that as a valid argument. All large industries are subsidized to some extent, either through tax breaks, grant money, favorable contract terms, or whatever. I'm not disagreeing with what you said, just pointing out why I don't find the argument particularly convincing. In fact, economic viability and ecological impact aren't really related to my point--well meaning actions taken today will have some negative impact not discovered or understood until many years in the future. Often the impact is due to changes in our behavior. Recycling gives us the feeling we are "doing our part" to help the environment. What is the logical result of that? I suggest one likely outcome is less aversion to purchasing packaged products, which ironically leads to more packaging being in the system. Does the savings from recycling offset the impact recycling has on our overall behavior? I don't know... studies suggest people tend to modify their behaviors in a way that cancels out the benefits of the change. Change to flurescent light bulb? People leave lights on. Switch to a high mileage car? People drive more. Give NFL players a helmet to prevent head injuries? They become less concerned for their own safety and head injuries increase. The pattern is there. I'd be surprised if it didn't extend into our environmental behaviors. I don't know enough about chemistry or the processes involved to speak about this knowledgably, but apparently the EPA disagrees with you. "But researchers have suspected for years that the converters sometimes rearrange the nitrogen-oxygen compounds to form nitrous oxide, known as laughing gas. And nitrous oxide is more than 300 times more potent than carbon dioxide, the most common of the gases that trap heat and warm the atmosphere like in a greenhouse, experts say..." "In contrast, an older car without a catalytic converter produces much larger amounts of nitrogen oxides, but only about a tenth as much nitrous oxide, the greenhouse gas."
-
Observations: Microsoft's Visual Programming Language compared to Labview
Daklu replied to Daklu's topic in LabVIEW General
Yeah, any sort of message routing framework would probably best be presented as a different development environment. I hadn't considered something similar to the state-chart add-on. That's a good idea. VPL runs on top of the Decentralized Software Services (DSS) framework, which in turn runs on top of the Concurrency Coordination Runtime (CCR.) I suspect the Labview runtime engine can fill the role of the CCR, but NI would have to develop an equivalent for DSS. As far as I can tell, when I run a VPL application the DSS framework is responsible for starting all the services needed by the app. Something similar would have to be implemented for the Labview environment. Also, any actors used by the messaging toolkit would need to have some sort of reflection capabilities so the toolkit knows what methods the actor exports. Not trivial, but not impossible either. Emilie liked your comment so maybe it is. I didn't know that. Thanks for the tip. -
Can you clarify? Are you saying carbon dioxide and nitrous oxide aren't greenhouse gases, or catalytic converters don't cause more of those gases to be released into the atmosphere? Maybe sometimes... but often? That would require a level of foresight and understanding of complex systems we just don't have. My favorite podcast of all time, Freakonomics, frequently talks about unintended consequences. Here's an article talking about the unintended consequences of three well-meaning laws and how they may do more harm than good.
-
That's fairly common in the pacific northwest area. I assumed it was a nation-wide trend. I take it your neck of the woods is different? Anyhoo, the one immutable and unrevokable law regarding any public policy is the law of unintended consequences. What sounds like a good idea today will be identified as the root cause of some crisis 20 years from now. When I was a kid catalytic converters were going to save the world from the terrible evil of automobile pollution. All the bad stuff coming out of the exhaust pipe will be replaced by natural and harmless elements: oxygen, water, and carbon dioxide. 35 years later we're told automobiles are one of the primary sources of greenhouse gases. So much for harmless... Don't get me wrong, I think it's good to be concerned about the environment and do our best to avoid negatively impacting it. At the same time, I think green technologies and promises of environmental friendliness are oversold to the public. Human civilization requires more resources every year. There's no way to extract those resources from the planetary system and deliver them to where they are needed without impacting the environment. *shrug* What can be bad about separating trash, biodegradables, and recyclables? I don't really know. I suppose having 3 trucks pick up the waste instead of 1 adds a certain amount of pollution to the air. Purchasing and maintaining extra trucks and employing additional drivers adds cost to the collection service, which in turn is passed on to consumer. Maybe the extra disposal trucks add to traffic congestion, keeping everyone on the road longer and multiplying the pollution effect. Maybe these are real effects, maybe they aren't. But I'll lay dollars to donuts there is some crisis lurking in the shadows waiting to attack our collective conscience in a couple decades.
-
Observations: Microsoft's Visual Programming Language compared to Labview
Daklu replied to Daklu's topic in LabVIEW General
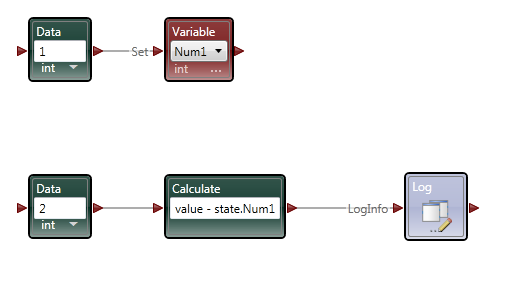
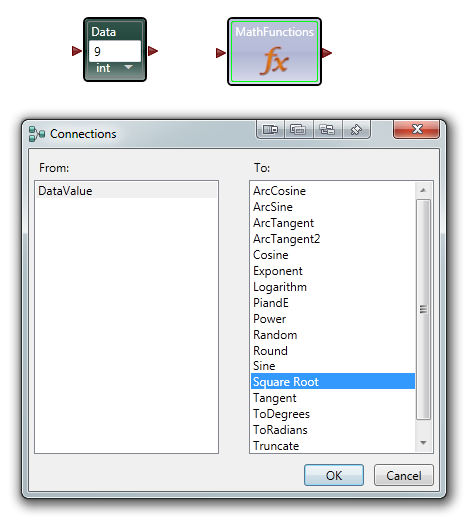
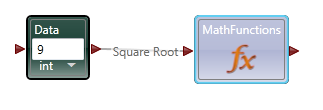
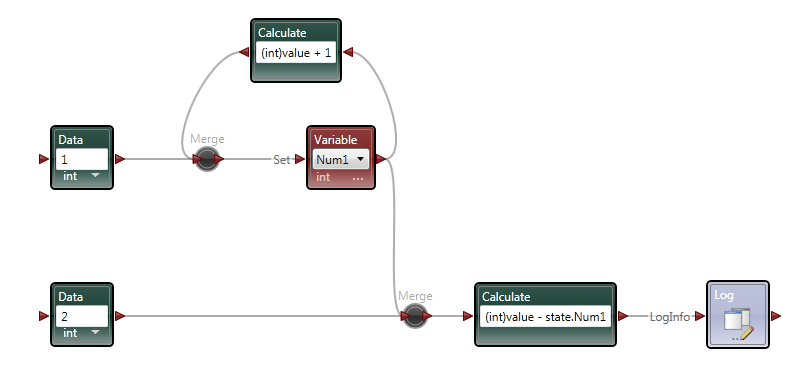
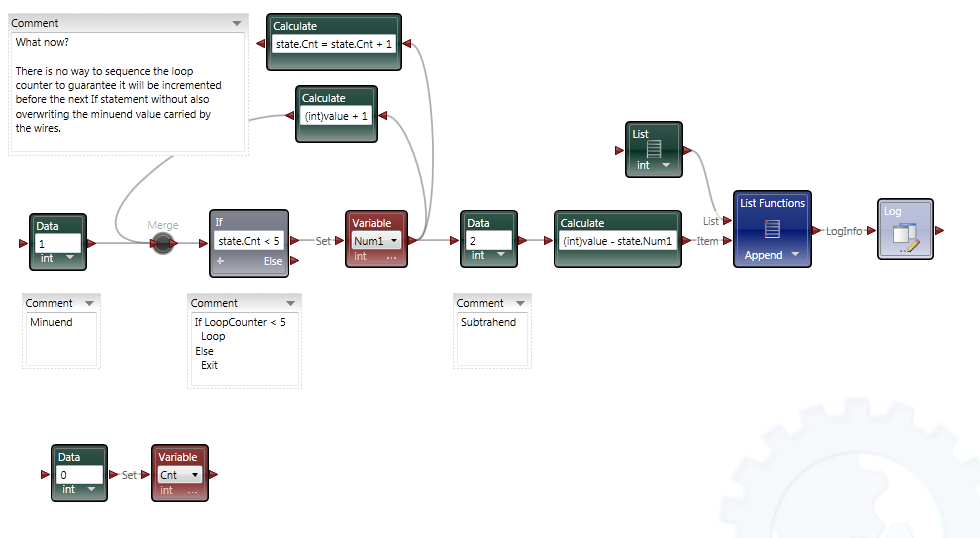
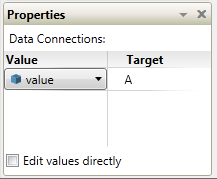
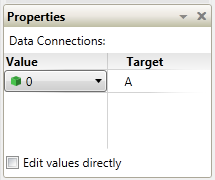
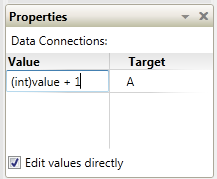
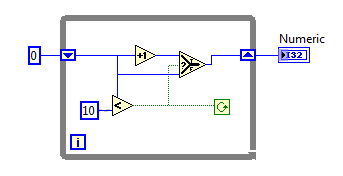
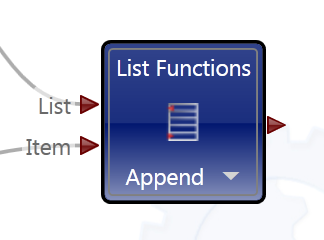
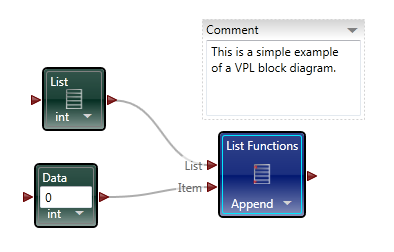
Part 2 In the first post I focused the IDE and few things NI might consider implementing in Labview to make our lives easier. In part 2 I’ll compare a few ways VPL code differs from Labview code and illustrate why it seems all wrong to a Labview developer. At the end of part 2 I’ll show why, despite all the apparent flaws in VPL, it actually makes a lot of sense. Show me something simple On the surface VPL and Labview look very similar, but if you try reading a VPL block diagram using Labview’s data flow model, you’ll quickly discover it doesn’t make any sense. In fact, it turns out simple tasks in Labview can be quite hard to accomplish in VPL. Let’s take a look at an incremental looping routine. In pseudocode, I might write something like this: int i = 0 while i < 10 i = i + 1 wend [/CODE] One functionally equivalent G implementation is, We know NI has patented the rectangle, which means other graphical data flow languages need to develop another way to describe the same semantics. A VPL while loop looks like this. [u][i]Hold up. What’s a “Merge” node?[/i][/u] Interpreting the VPL code from a Labview mindset leads us to believe the program is faulty. There is a circular data dependency. It appears we have a deadlock at the Merge node. Looking closer, we can see there are inputs from [i]two[/i] source terminals connected to a [i]single[/i] destination terminal on the Merge node. Labview doesn’t allow that—every destination terminal can have at most a single source terminal. What’s going on here? VPL enforces the same rule of a maximum of one source for each destination pin, [i]except[/i] with the Merge node. The Merge input pin is the one pin that accepts multiple sources. Its function is to simply pass on all the data it receives as soon as it receives it. It seems very peculiar at first, but without the ability to merge multiple data sources into one, loops like this would not be possible. From a certain point of view, Labview’s shift registers do exactly the same thing; they accept the initial value from a source outside the loop, then the same shift register later accepts values from sources inside the loop. The main differences are: 1) Labview’s patented rectangles provide a clear delineation between what is inside the loop and what is outside the loop, and 2) in Labview the wire showing the return path is hidden from users. [u][i]Why does “If” have two output pins?[/i][/u] Here’s a question for you: Looking at the above VPL diagram, how many times does the Log node execute? The ‘If’ node will execute 11 times total (i=0 through 10, inclusive) so according to Labview’s data flow model we expect the Log node to execute 11 times. That would be wrong. Data is sent to the Log node only once, when i=10. This illustrates a key difference in VPL’s handling of data flow with respect to nodes. In LV, [i]none[/i] of the data exits a given node—sub vi, case structure, loop, etc.—until [i]all[/i] of the output nodes have data. That’s not true in VPL. When data becomes available on one output pin, other output pins may or may not also have data available. In the case of the ‘If’ node, the text shows us the conditions under which each output pin will have data. If i < 10, the top pin will have data; otherwise the bottom pin will have data. Last year Steve Chandler started a discussion on LAVA questioning whether or not Lavbiew is a “pure” dataflow language. The conversation touched a bit on the behavior of output terminals on nodes. NI’s approach in Labview makes it much easier to develop and reason about a program. Microsoft’s implementation in VPL is arguably a purer interpretation of dataflow. [u][i]I’ve only seen a handful of nodes. Show me the core functionality.[/i][/u] We are all aware of Labview’s rich set of basic functions. There are so many built-in nodes on more than one occasion I have created my own sub vi to do something only to discover later the same functionality is already included in a native node. By comparison, VPL’s basic functions appear wholly inadequate. There are a total of 11—yes, 11—nodes that define the native operations in VPL. (VPL does have a respectable set of advanced features available from the services palette, but they are not core parts of the language.) Something as simple as subtracting two numbers requires excruciatingly unnatural code. [u][i]What do you mean? Subtracting is hard?[/i][/u] Almost all nodes, including the Calculate node, are restricted to one input pin, so the second number has to be made available to the calculation by other means. In this code I have created a variable named “Num1” and assigned it the value of 1. I’ve also created a data constant with the value of 2 and connected it to the Calculate input pin. The statement inside the Calculate node shows the calculation that will be done. “Value” refers to the value received on the input pin. “State.Num1” refers to the value in the Num1 variable I created. VPL variables are analogous to Labview local variables, except VPL variables are not tied to a front panel control; they are available via the “state” object. Compared to the simple code required to subtract two numbers in Labview, the VPL code almost appears purposely obfuscated. To take it a step further, suppose I want to subtract two numbers multiple times while incrementing the minuend (the number being subtracted from.) In Labview it is easy. I spent about 20 minutes trying to figure out how to do the same thing in VPL. My first implementation doesn’t work. In this code I tried to retrigger the Calculate node by linking the Variable.Set node to the Calculate node’s input pin. The idea is every time the variable is incremented and set the calculation will be performed again. A little thought reveals why this doesn’t work. Since the wires attached to the variable output pin carry the value contained in state.Num1, the calculation will always be equal to zero. After trying a few different things, I’m not sure the code [i]can[/i] be written in VPL without adding a lot of complexity. The diagram below is as close as I could get in the amount of time I was willing to spend on it. The minuend and the loop counter variables are completely independent—there’s no way force both operations to complete before sending the modified minuend on to the next node without overwriting loop counter. [i](Note: While playing around in VPL some more after finishing the writeup, I discovered a way to force the loop counter and minuend to be updated before executing the If node again. I didn't really feel like going back and rewriting this section, but if there's [s]enough[/s] any interest I'll post a block diagram showing the code.)[/i] [u][i]That’s some weird behavior for a sub vi[/i][/u] There are other things an experienced LV user may struggle with when using VPL. We primarily think of nodes in terms of sub vis with each function represented by a different sub vi. Most VPL nodes, especially the advanced nodes, behave more like a polymorphic sub vi. Instead of selecting the function and dropping the correct node, in VPL you drop the node first and select the function to be performed. In VPL the function is chosen via dialog box when attaching a wire. In the diagram below I want to find the square root of 9. When I attach the wire, the dialog box appears asking me to define the math function I want to use. After choosing the function, the diagram shows the nodes connected with the function represented by the pin label. (In part 1 I commented on pin labels being more important in VPL than in Labview. This is why I said that—without the pin label we’d have no way of identifying which function was being performed.) Wires in general play a more active role in VPL than the passive data carriers they are in Labview. Since nearly all VPL nodes are restricted to a single input pin, the wire—not the node—defines which node outputs and node inputs are selected. Sometimes wires also have the ability to directly manipulate data. Selecting the wire shown above and checking the Properties window shows me the default wire behavior. The value put on the wire is being passed on through. The dropdown box also gives me the option to set the value to 0, overwriting the input value. If that doesn’t do enough for me, I can also select the “Edit values directly” checkbox and enter an expression of my own, using the input value or any diagram variables available through the state object. This is definitely an interesting feature; however, on the block diagram wires with custom properties look exactly like wires with default properties, potentially leading to confusing block diagrams if this feature is overused. [u][i]VPL looks practically unusable. Are there any redeeming features besides the IDE?[/i][/u] Throughout these write-ups I’ve used the term “node” to refer to any block diagram element whether it is taken from the Basic Activity palette or the Services palette. In truth they are not the same. Basic Activity nodes are similar to sub vis. They take inputs, do some stuff with it, and return an output. Service nodes are more than that. They run continuously in the background. Depending on the service, it may wait patiently for you to ask it to do something, or it may work independently in the background sending you periodic update messages. If you think this sounds remarkably similar to [i]actors[/i] or [i]active objects[/i], you’d be right. If you try to use VPL to do the same type of low level data manipulation we’re used to doing in Labview, I agree it probably isn’t worth the effort. It is clearly missing all sorts of core functionality needed to be effective at that level. However, I don’t think VPL is intended to be that kind of language. VPL is primarily a message routing language. Its purpose is to explicitly define message flows between concurrent services (i.e. actors) to accomplish a larger goal. All those decisions that look questionable to us make a lot more sense when you think about VPL as a message routing language instead of a dataflow language. Don't get me wrong--it is dataflow, but not in the same sense Labview developers are used to. In fact, the relatively few hours I’ve spent with VPL leads me to believe it is far better at defining and showing interactions between actors than anything we have available in Labview. [u][i]Hey Dave, wrap it up already[/i][/u] With the increased visibility of actor oriented programming within the Labview community, the difficulty in concisely and clearly showing message routes and message sequences between independent actors is certain to become more apparent. Simple message routing can be done in Labview using a mediator—a loop that reads a message and places it on the queue of the actor it is intended for. If the message route requires several hops before getting to its destination the complete route information is no longer contained in one place. Good for modularity, not so good if you’re trying to understand a message’s path through the application. Sometimes actors need to exchange a sequence of messages to do a task. Like multi-hop routes, it is hard to show this sequence concisely in Labview code. The overall sequence must be inferred by digging into individual message handlers and tracing through the code. Clearly presenting multi-hop message routes and message sequences is something I’ve struggled with in my own code. There are no good ways to accurately communicate that information to other developers, and to some extent you just wave your hands and hope they are familiar with actor oriented programming. I started looking into VPL a couple weeks ago mainly to get another perspective on dataflow languages. I expect it to address the same types of issues Labview does. Instead I discovered the relationship between VPL and Labview is an odd mix of contradictions. VPL is not a direct competitor to Labview, but its higher level of abstraction does pose a distinct threat to Labview’s simple concurrency model. It’s not intruding on Labview’s domain in the test and measurement industry (yet,) but it does make it harder for Labview to gain acceptance as a general purpose concurrent programming language. In short, VPL doesn’t [i]replace[/i] Labview, but in some ways it [i]surpasses[/i] Labview. I’m quite curious to see how well VPL scales when there are tens or hundreds of messages between actors. How much clarity does it lose? How easy is it to accidentally break an app? How long will it take to implement? My gut feeling is an experienced .Net developer using C# to create services and connecting them using VPL would spend roughly the same time as an experienced LV developer writing the same application in Labview using actors, but when the code is complete the VPL code will provide a much better high level view of what is happening than the Labview code. A better understanding naturally leads to faster changes and fewer bugs. And in the end, isn’t that what we all want?
-
(Somehow I missed this response earlier. I also don't know what happened to the original message... maybe AQ deleted it?) I appreciate the reply. Figuring out the terminology is often one of the biggest hurdles to learning different approaches. I have written C# programs and understand the certain parts of the .Net framework, but I'm not nearly as fluent in it as I wish I was. (In particular the whole UI / delegate / event system still puzzles me.) Your explanation helps. Using Tasks for concurrent programming is still a little confusing. I'll use your example of a button event handler that creates a task to do the 5 second calculation, launches it, and await on it. As I understand it, the state of the local variables in the event handler are remembered and execution "jumps" out of that method to continue processing UI code. When the task finishes the UI execution jumps back into the event handler at the await call, restores the values of the local variables, and continues processing the method from that point. Is that mostly correct? What happens if, immediately after awaiting on the 5 second task, I press another button that starts a 10 second calculation in the UI thread? Is my UI calculation interrupted to finish the remaining statements in the the first event handler? I guess I'm wondering how the remaining code in a method following an await is scheduled relative to code currently executing in the UI thread. Does the Task response interrupt the UI thread or is the response just added to the event queue to be processed in order? In Labview I primarily use queues and messages to transfer data between concurrent code. The points at which my parent loop will actually process the response are clearly shown by the dequeue node. I may not know exactly when the response message will be processed relative to other messages, but I can easily see it won't interrupt any other messages being handled. I don't see that clarity in the .Net model. Maybe it's a inherent rule experienced C# developers know about? Yeah, I can see how the automatic jumping out and jumping in to a method would make it easier to write certain kinds of methods. At the same time, jumping out of an event frame before it has finished and jumping back in to continue from where it left off is a huge dataflow violation and we'd all freak out the first time we saw it happen. I have admit, the more I think about it the more I kind of like it. Suppose I want to execute lengthy calculations A, B, and C in series when a button is pressed. In really bad pseudocode, using await the event handler would look something like this: MyMethod handles btn.OnClick ... start TaskA; await TaskA; msg.text = "TaskA finished"; start TaskB; await TaskB; msg.text = "TaskB finished"; start TaskC; await TaskC; msg.text = "TaskC finished"; ... [/CODE] It's very clear from looking at the code that each of the tasks will be executed in sequence from this one button click. In G I can't do that. I need to create separate message handlers for when each of the tasks is finished and chain them together in code. The bad pseudocode textual equivalent would be... [CODE] MyMethod handles btn.OnClick start TaskA; End TaskAFinished handles TaskA.finished msg.text = "TaskA finished"; start TaskB; End TaskBFinished handles TaskB.finished msg.text = "TaskB finished"; start TaskC; End TaskCFinished handles TaskC.finished msg.text = "TaskC finished"; End [/CODE] This is clearly not as easy to understand as the implementation using await. Furthermore, this code permanently establishes the sequential nature of the tasks. I can't start task B and get a response without also invoking task C. There are way to work around that within the restrictions imposed by data flow (like using UI states to implement different responses to the same message,) but I haven't found anything as simple, clear, and robust as what the task based await approach appears to give C# developers. In some respects await is like an abstracted, [s]generic[/s] anonymous event handler temporarily bound to the Task. You get the same behavior without all the messy delegates and event handling code. None I can think of off the top of my head, but now that I understand the task-based approach better (assuming my descriptions above are correct) I'll certainly be thinking about it. Message sequences in Labview are difficult to infer simply by looking at code and I've struggled with how to overcome that for a while.
-
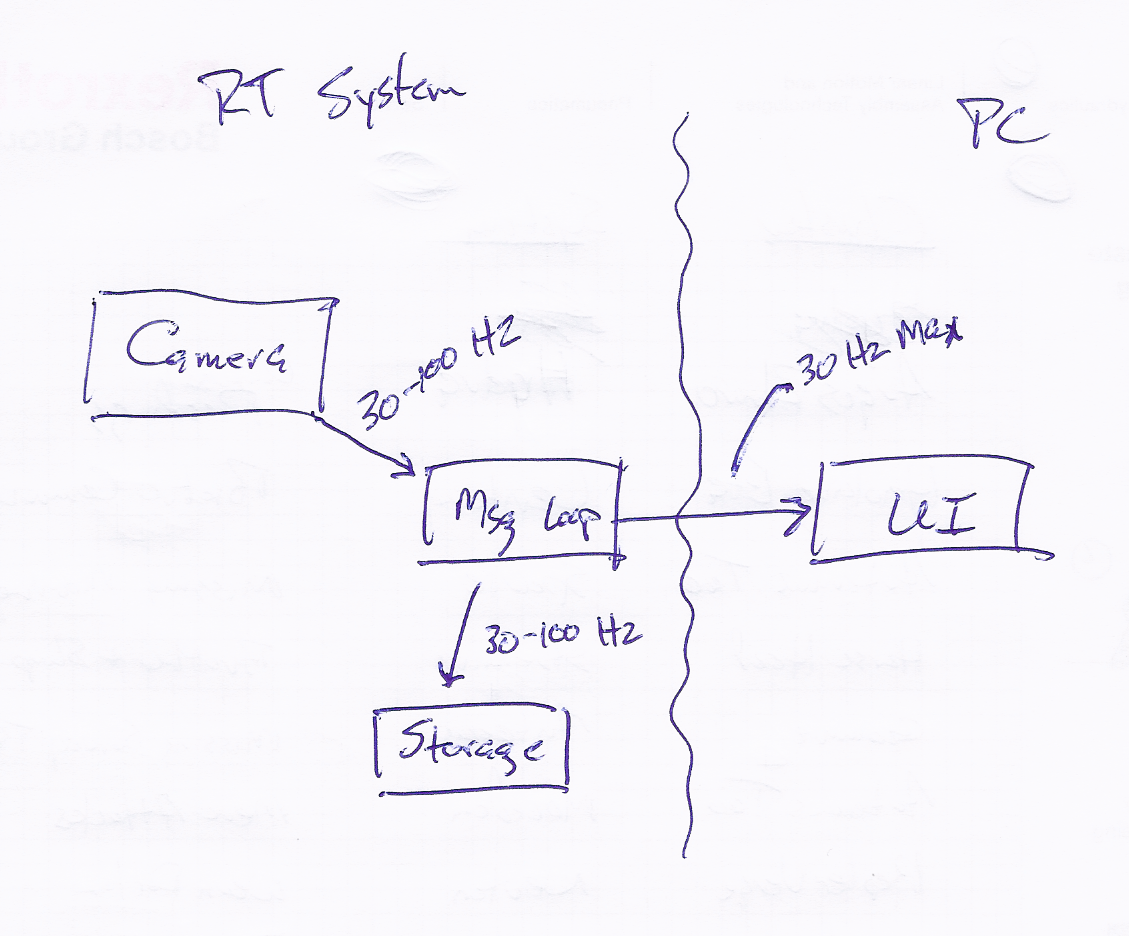
Here's a link to changing the read/write attributes in Windows 7. Is this an accurate representation of your system? The camera may be taking images at any speed and you want to save all those images, but to avoid choking the connection you're only sending images up to the UI at a maximum of 30 Hz regardless of the image capture rate. If that's what you're intending, I don't think a priority queue would help you out. The priority queue as I implemented it has the same size for all priority levels. You can't set the internal priority 1 queue to a length of 100 and the internal priority 5 queue to a length of 1. You'd either have to set the length to a low number and risk losing high priority messages, or set it to a high number have the UI show the image the camera took 100 frames ago. (Since the most recent image will be put at the rear of the queue.)
-
Observations: Microsoft's Visual Programming Language compared to Labview
Daklu replied to Daklu's topic in LabVIEW General
I do. I actually worked on the Zune team from the time the Zune 30 was released up through the Zune HD. (I was responsible for testing the capacitive touch technologies.) I can't say what the army of MS vice presidents were talking about behind closed doors, but I can share my thoughts as a rank and file employee. Yes, Windows Phone 7 does include a lot of what was learned during Zune. No, it was not a precursor to phone by design. Zune was conceived and launched before the iPhone revolution. Windows phone had been fairly successful sticking with the interface it had and there was no reason to change it. The Zune hardware and Zune Market were designed to compete with the iPods and iTunes that existed at the time. In that respect I think they were successful. In my admittedly biased opinion, Zune was better than iPods and iTunes in almost every way. The hardware was cheaper, offered more storage space, had bigger and better screens, and (imo) was more intuitive to use. It could play video, supported wifi, and had an fm radio. Zune software was way more visually interesting than iTunes, even if it had a smaller music library at the start. The Zune market also offered subscriptions long before iTunes did. (I'm not even sure if iTunes offers them yet.) Why did Zune fail as a hardware platform? I believe unfortunate timing and poor marketing are primarily at fault. Marketing tried to attract the edgy/alternative crowd and used non-standard channels for getting the message out. That's not a bad thing; targeting early adopters is a good strategy. But the message they presented was, to be blunt, absolutely incomprehensible. (At the time I wondered if the advertisements made more sense with a healthy dose of THC.) I don't remember a single advertisement that highlighted any of Zune's advantages. Looking back, it seems like marketing was trying to "out cool" Apple at a time when the iPod defined coolness. The iPhone and iPod touch were released a year after the Zune 30, and shortly before the first Zunes with capacitive touchpads. The buzz and excitement generated by the Cult of Apple is always hard to overcome. iOS changed the way things are presented to the user, but it wasn't exactly revolutionary. (Icons on a screen... wheee!) There were still holes in the iOS devices Microsoft could, and did, exploit. The one thing that was revolutionary was its multitouch support. Other devices have supported multitouch (like Microsoft Surface) but it had never been implemented so well on a platform that small. I was given a couple early iPhones to test and characterize their multitouch capabilities. I'll be honest--it was damn impressive. During Zune HD development we tried lots of different ic vendors looking for a comparable solution. None of them even came close. Their algorithms were either too slow or not robust enough to prevent potential gesture confusion. We went through a lot of iterative development with ic vendors to get their multitouch capabilities up to expectations for the Zune HD. I think the first touchscreen Zunes were released 2 years after first gen iDevices. (Just to poke a stick in the ribs of Apple fanbois who blast MS for never doing anything original, Apple purchased Fingerworks in 2005 to acquire the touch technology used in the iPhone.) I don't think Zune hardware sales ever met expectation. During development of the Zune HD there was talk that it was going to be the last retail version and we'd start developing reference hardware platforms manufacturers could use to create their own devices. There were also rumors of providing the Zune software as a stand alone product to third party developers. I suspect around that time Zune executives started shopping it around to other divisions in Microsoft to see if it would stick somewhere. I think Zune's influence on Windows Phone 7 is simply a matter of WP7 designers finding elements they liked in it. I haven't seen anything to suggest a grand scheme to use Zune as a development platform for the WP7 user interface. ------ In case anyone is wondering why I mentioned those two products, I also worked in MS's mouse/keyboard group when the gaming device group--a sister to our group--switched to home networking. Our devices offered real ease-of-use advantages over other offerings at the time, but the profit margins plummeted and MS bailed out. Yeah, and I've even downloaded and installed it a few times. Never got around to trying it out though... -
No worries about the PMs. I just didn't happen to be online when you sent them. Thanks for reposting your questions publicly. I prefer to make questions and answers available for searching. I often make my reuse libraries read only. It helps prevent me from accidentally editing them and breaking other apps that depend on them. Labview automatically recompiles code when it is loaded (if it is necessary) so usually it is safe to discard recompiles. If you do want to save the recompiles, just go to the directory in vi.lib and change the file attributes to read/write. Note: I've only worked on a few real-time systems and I've never used LapDog on one. It's not designed with RT efficiency or determinism in mind. I think it will work fine on a RT system, but it may introduce jitter or other timing issues. Yeah, there's no problem using the deprecated version if you want. It will be included in all v2.x packages. I do plan on removing it from the v3 package, but it will not cause any problems with apps you have developed using v2. Changes that break backwards compatibility (like removing the priority queue) are released as a new package with a new namespace and a new install location. Breaking changes are indicated by incrementing the major version number. That means classes from LDM.v2 cannot be directly used with classes from LDM.v3. This is intentional. It does make it inconvenient to upgrade an application to a new major version, but it also allows users to have incompatible versions of the libraries to be installed and loaded simultaneously. Users can be reasonably confident they can install a updated version of a package without breaking any existing code. (Guaranteed compatibility is nearly impossible to achieve.) I'm undecided. My current thinking is a priority message queue is unnecessary because messages should be processed instantly. If messages are getting backed up to the extent a priority queue becomes desirable then the message receiver should be refactored to eliminate the bottleneck. That's my current line of thought anyway. There are valid use cases for a work queue, which programmers would intentionally keep backed up so the worker is always running. Message queues and work queues are different concepts and I'm not sure how to separate the ideas in the LDM api. A priority queue blurs the line between the two and--if my current thinking is correct--encourages tighter coupling between components. Regardless, I don't have any concrete plans for releasing v3. Major releases occur when I have to make a change breaking compatibility, and for the time being I don't see anything on the horizon requiring that. I might have to make some breaking changes if I submit LDM to the NI Tools network, but even then it would likely be a straight repackaging of v2 with a new namespace and install point. Does that answer your questions?
-
Observations: Microsoft's Visual Programming Language compared to Labview
Daklu replied to Daklu's topic in LabVIEW General
Yeah, MS has a habit of jumping into a market for a couple years then abruptly jumping out. (Home networking products and Zune come to mind.) From a business perspective cutting deadwood is good, but as a consumer it can be frustrating. I've installed Robotic Studio several times over the years, but this is the first time I've actually been able to dig into enough to understand it. I don't believe MS intends to position it as a direct competitor to Labview, but I do think it has long term implications on Labview's future. I'm thinking MS developed Robotics Studio as a platform designed to help flesh out the underlying frameworks, DSS and CRR. -
Observations: Microsoft's Visual Programming Language compared to Labview
Daklu replied to Daklu's topic in LabVIEW General
I don't like developing in the Mindstorms environment. It's kind of buggy and I find it hard to do anything moderately complex using the Mindstorms language. My Mindstorms kit sits around doing nothing because I dislike the environment so much and I haven't got around to setting up a better one. I don't think Mindstorms and VPL are directly comparable. Mindstorms does use an MDI IDE, by it's really limited in what you can do with it. Given that it's designed for kids that's perfectly understandable. More importantly, Mindstorms is a code editor and compiler. If I remember correctly there is almost no debugging capabilities. Code execution occurs on the brick, not the pc. With VPL the code executes on the PC. The set of requirements is entirely different. It's been on my to do list for... 3 years or so? Robotics is a huge playground for anyone who likes to tinker. How can anyone not <heart> robots? VPL started as a tool for roboticists, but I'm actually looking at it as more of a general programming tool. I've seen posts indicating people are using it to address concurrent programming issues in other domains. The more I learn about VPL the more... interesting... it becomes. -
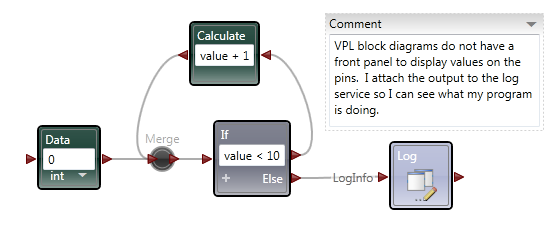
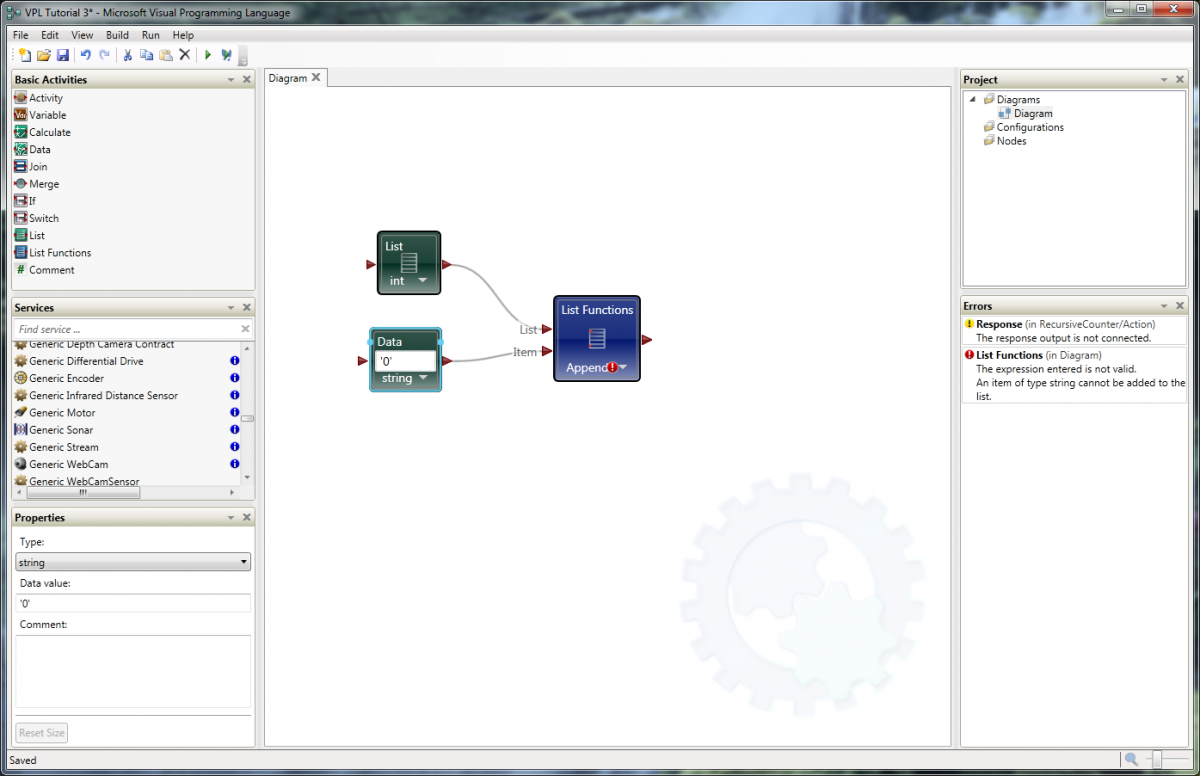
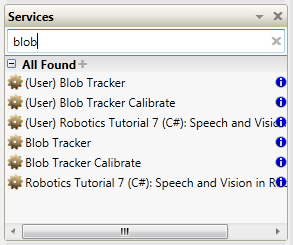
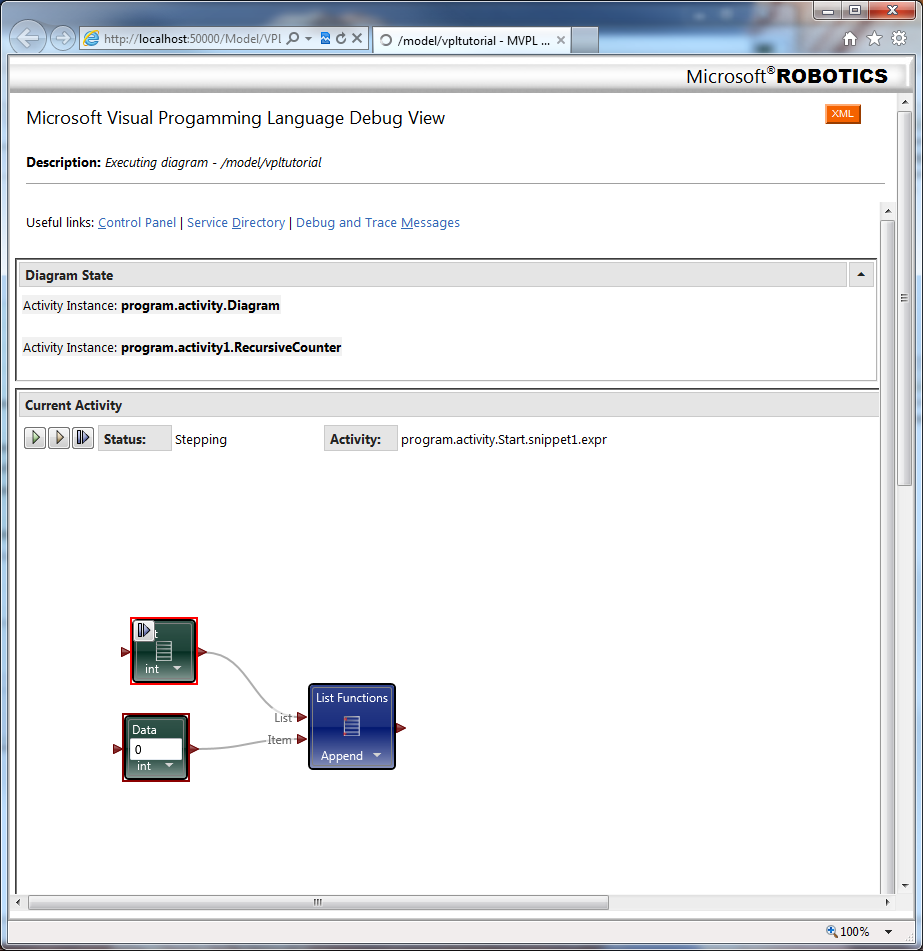
Recently I've been looking around at other dataflow languages, primarily because I'm curious to see how G's language design influences the way we think about dataflow. Last week I downloaded and installed Microsoft's Visual Programming Language, a dataflow language included as part of their Robotics Development Studio. On the surface VPL appears to be a direct competitor to Labview. If that concerns you, don't worry... imo VPL has a long ways to go before it can offer the simple workflow and overall ease of use as Labview. In fact, when Robotic Studio was first released MS did not publicly consider it a competitor to Labview. Still, it has interesting features that may (or may not) be useful in a Labview context. This post is not intended to be a criticism of Labview or question NI's design decisions surrounding the language and IDE. It's just pointing out a few of the differences and my reaction to them. The IDE The very first thing to notice is the MDI (multi-document interface -- docked windows) IDE. In my opinion Microsoft does a very good job creating developer-friendly IDEs. The VPL IDE, though sparse, has the look and feel many text language developers are used to. Although we've learned to accept it, Labview's window management can be a pain sometimes and it was refreshing to work in an environment where that wasn't a concern. The Basic Activities and Services palettes contain all the components I can use on the block diagram. The Project and Errors window are always visible, making it more convenient for me to use those features. The project window doesn't contain all the information I would expect it to and in fact some parts of my project can be difficult to get to. In particular, in this project I have a custom activity--roughly analagous to a LV sub vi--and the only way I've been able to get to that block diagram is through the error window. I can't say whether this is an oversight in the IDE design or me not fully understanding the programming model. In the diagram above I'm trying to add a string to an integer list, which is a type mismatch error. Selecting the List Functions error from the error list causes the corresponding error icon to throb, drawing the developer's attention to it. Does VPL's error highlighting provide better usability than LV's error highlighting? Not really, but having worked in LV's visually static environment for so long there was a certain amount of juvenile delight in seeing dynamic graphics on the block diagram. The Properties window shows the properties of the selected block diagram item. I'd love to have a similar feature in LV. LV's modal properties dialog box feels antiquated and clunky in comparison. To be fair, a sub vi has far more properties than any of the VPL nodes I used, so presenting all that information to the user is not a trivial challenge. The Services palette offers a search box, similar to LV's palette search, but extends it in an interesting and useful way. It is possible to save the search results in a custom palette group. For example, if I type in 'blob' the palette shows all the related services. Clicking on the '+' symbol creates a new grouping named 'blob,' making it very easy for me to locate commonly used palette items. I expect groups would be created and destroyed frequently during a development session. Also noteworthy is the blue information icons on the palette. Clicking on the icon opens the help associated help page in a browser. It seems insignificant, but it is more natural than LV's process of hovering over the sub vi and mousing over to the context help window to click the link. For reasons I'll explain later, in VPL visible pin labels are more important to readability than they are in LV. I like how MS has made them less obtrusive. The label is translucent, not transparent. Wires passing under a label are dimmed somewhat instead of completely obscured, preserving the visual connection while retaining readability. I've often wished for better transparency support in LV. VPL includes comment blocks, which are similar to free labels. Comment blocks have the added features of being collapsable and having scrollbars when they are needed. These are features I'd love to see ported to Labview. Oddly, comment blocks do not offer a word wrap option, something they would definitely benefit from. The IDE also offers something many LV users have lobbied for and equally many LV users have lobbied against: block diagram zoom. Insert religious war here. Debugging Running a program from the dev environment gives us some insight into what is going on under the hood with VPL. A dialog box opens telling me my project is running with a list of messages. As you can see from the image below, even simple programs have some pretty significant stuff behind them. If your program isn't behaving as expected, errors will show up here. In typical Microsoft fashion, there is an abundance of cryptic information to sift through. While perhaps intimidating for new users, I'm certain it would be very useful in the hands of experienced developers. I haven't decided if I like VPL's debugging features or not. It's very different from anything I've used in the past. For starters, the debug environment is presented in a browser window. Current Activity highlights the next step to execute in the block diagram and provides controls for single steps, running, and setting break points (not shown), but the block diagram is just an image; there's no interactivity with any of the elements. You cannot probe a wire to see what value was sent. VPL offers a "Log" service you need to add to the block diagram instead. One nice thing LV does that VPL does not is execution highlighting. In VPL's debugging view the execution jumps from node to node. The ommission makes it harder to follow the data flow--especially for LV developers--because VPL's concept of dataflow on the block diagram is very different from LV's interpretation. (More on this later.) In these ways VPL's debugging features feel very primitive compared to those available in LV. On the other hand, near the top of the debug window are links to the control panel. I haven't used VPL enough to understand how useful it is in a real application. In general I prefer too much information over not enough, and the control panel contains a lot of information. There are certainly times I've wanted more visibility into LV's inner workings to help troubleshoot a problem. I didn't even get to the parts I really wanted to talk about--activities, merge nodes, notifier pins, and the differences in data flow models. I'll post a followup covering those topics in the near future.
-
I'm openly trolling for participants in an api development "contest." The contest objective is to create an api that can adapt to new requirements without affecting backwards compatibility. The purpose of the contest is to gather information about api development and deployment strategies and compile all the caveats and warnings into a document of best practices. The original thread is here. To keep information centralized please post all questions and comments there.
-
Perhaps it is your debugging technique that is shoddy? (Just kidding... I couldn't resist. ) I have experienced the same frustration with the block diagram jumping all over the place while I step through a vi. As my programming skills have evolved I've switched back and forth between allowing multiple loops and not allowing multiple loops. With actor-oriented programming I find I rarely need to step through the code looking for an error. Usually it's pretty clear where the error is coming from so I can set a probe and a breakpoint and get the info I need to take the next step. And since most of my loops sit around waiting for a message, in those cases where I do need to step through the code the block diagram doesn't jump around. Admittedly, sometimes I do create sub vis purely for the sake of saving space because it better establishes readability*. When I do I'll mark it private and put it in a virtual folder named "Space Savers" or something like that to indicate it falls outside of the abstraction levels (both public and private) I've established for that component. (*When I say readability, I'm not referring to just the readability of a block diagram. Usually I'm more concerned with clarity of the app as a whole rather than readability of any single block diagram. In other words, I favor decisions that help the developer understand how components interact over decisions that help the developer understand any single block diagram.)
-
Sometimes for high throughput data streams I'll create a direct data pipe from the source to the destination to avoid loading down the messaging system. The pipe is just a native queue (or notifier depending on your needs) typed for the kind of data that is being sent. You can send the queue refnum to the data source and/or destination actors as a message. The data pipe is *only* for streaming data; all control messages (StartCapture, FlushToDisk, etc.) are still sent through the regular messaging system.