Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-
I didn't expect to change your mind. That's okay... the first step to finding a cure is admitting there's a problem. Nope. First, it's not a bug. To clarify, while it is undesirable behavior from the developer's point of view, it's not a "bug" in that the cluster and bundle/unbundle source code is faulty. Rather, it is an inherent design limitation due to clusters not maintaining a history of their changes. The issues arise because people use typedeffed clusters in ways that (probably) were not originally intended--namely, as a robust mechanism to pass data between independent components. Second, NI has already implemented the solution. Classes. There may be some bugs in Labview's OOP code, but they will be fixed over time. It's unlikely clusters will ever be "fixed." For some, yes. Personally I was vaguely aware something was odd but, like you, chalked it up to Labview's quirkiness. It wasn't until I understood exactly what was happening and why it was happening that I began to recognize how frequently this issue was costing me extra time. As I said earlier, changing my design approach to use classes (or native data types) instead of typedeffed clusters to pass data between components has been liberating and saved me tons of time. Who won't run into this issue? -Developers who create highly coupled applications, where loading one vi essentially forces Labview to load them all. -Developers who adhere to strict process rules, such as maintaining Tree.vi and not making certain changes to clusters. -Developers who use the copy and paste method of code reuse, establishing unique instances of their "reuse" library for each project. When does this start becoming an issue that needs to be addressed? -In multi-developer environments, where process standards are hard to enforce and verifying they have been followed correctly is difficult and time consuming. -In decoupled applications, when dev work occurs at the component level instead of the application level. -When dev teams begin using single point deployed reusable components (i.e. installed to user.lib or vi.lib) instead of copy and paste reuse. I absolutely agree. However, the developer has to understand the risks and costs associated with the choices before an informed decision can be made. The risks of using clusters are not well understood, hence (in my experience) the cost is almost universally underestimated. OOP is new to the Labview community, so the difficulty in using classes in place of clusters is typically overestimated and the expected cost is set too high. With a skewed evaluation of the risks and costs it's not surprising there's so much resistance to classes. Now that we've put that issue to bed I have to figure out what you're trying to say about classes violating data flow, because it makes no sense to me. (I guess the stupid hour hit early today in the pacific timezone.) "Dataflow" means different things in different contexts. Can you explain what it means to you? (Note: I'm not ignoring Ben and Mark, but no time to respond right now.)
-
Chris. (Though I usually like mine pretty well too...)
-
Quick response on your videos. Everything else will have to wait. I'm seeing you not following the instructions. Step 2: Close the project. Open Control 1.ctl, LoadedBundle.vi, and LoadedUnbundle.vi. (You only opened the ctl.) Step 3: On the typedef, rename s1 to FirstName and s2 to LastName. Apply changes. (You didn't apply the changes before reordering the controls, which isn't surprising since the option isn't available if there are no vis in memory to apply the changes to.) Your examples showed a single edit. My instructions detail a sequence of two distinct edits that can be separated by an arbitrary amount of time. There is a difference. The instructions may appear to be an extreme corner case, but they are designed to simulate what can happen over a period of time as the project evolves, not give a realistic sequence of actions one is likely to sit down and do all at once. Most developers know (through painful experience) not to make lots of changes to typedeffed clusters without forcing a recompile by saving or applying the changes during intermediate steps. What the example shows is how the bundle/unbundle nodes reacts differently to the typedef edits depending on whether or not the vi containing that bundle/unbundle node is loaded in memory at the time of the edit. (At least it does if you follow the instructions. ) It's not an expectation I created. It's an expectation set because bundle/unbundle by name prims usually do successfully interpret what is supposed to happen. When you follow the instructions the bundle/unbundle nodes in LoadedBundle and LoadedUnbundle are still wired correctly. It's the vis that weren't loaded during the edits that end up wrong. Editing the typedef can easily cause inconsistent results that depend entirely on when in time the dependent vis were loaded into memory relative to a sequence of typedef edits. A series of small changes that under many conditions do not cause any problems do, in fact, cause unexpected problems in situations that are not well understood by the Labview community as a whole. That this happens is crystal clear and, as near as I can tell anyway, indisputable. (I think you'll agree once you follow the instructions correctly. ) The million dollar question is, how much do you want the quality of your software to depend on the state of your development environment while editing and what are you going to do to mitigate the risks? (That's a general "you," not you--Shaun--specifically.) You did see where I said "it takes almost a concentrated effort" to break the class, yes? (And yes, I do consider your example a bit of an effort because users are not likely to spend hours, days, or weeks making that single edit.) If you follow the scenario I gave the class doesn't break. I will also point out that if it was discovered sometime in the future that someone did break the class this way, it will be far easier to fix the damage than it would be with a typedef cluster. Why? Because the set of vis that have the ability to bundle/unbundle that data is known. Using a typedef cluster to pass data between modules means you have a lot more work to do Unless we parted ways somewhere along the line, the context of this discussion is how to best pass data around your application: clusters or classes. When I say "typedef" I have been referring specifically to typedeffed clusters because they are commonly used as Labview's equivalent to a struct as an easy way to pass data around the app and they have the (illusionary ) benefit of single point maintenance. I thought I mentioned it earlier, but maybe not. I apologize for not being more clear. (Da-yem... 9:15 pm. Mrs. Dak is going to kill me...) ((BTW, did I mention you didn't follow the instructions correctly? )
-
Personally I'm quite glad JKI uses well-establish file formats. It allows us to use other tools to manage these packages instead of being completely dependent on JKI for functionality.
-
 See... I *knew* I had read about that problem somewhere on Lava... I mentioned it because... you know... just in case you forgot you had already posted about it.
See... I *knew* I had read about that problem somewhere on Lava... I mentioned it because... you know... just in case you forgot you had already posted about it. -
It could be a known bug, depending on what changes LV thinks it made to those classes. I get it a lot when I am saving my project. Classes I haven't edited are asking to be saved again. Usually the reason is "An item in this library has moved" or "An attribute of this library has changed." I've done binary diffs on the scc copy versus the newly saved copy and they are identical. I just ignore them now, though it is a bit of an annoyance.
-
I really appreciate you taking the time to look this over Omar. Obviously I didn't get to post more details about what I was trying to do. I hope you didn't have too much trouble deciphering my intent. My initial reaction to your example is that the test method "testInvalid" is going to be skipped in all of the test environments, where what I'd need to be able to do is skip them only in certain test environments. Then the pieces starting coming together... Whereas I have multiple test cases for slightly different initial conditions that I establish (to some extent) in the testCase.setup method, you would have one test case for the List class with unique test methods for different initial conditions. For example, Where I have ListTestCase-Initialized:testInsertIndexZero, and ListTestCase-Uninitialized:testInsertIndexZero, You would have ListTestCase:testInsertIndexZeroInitialized, and ListTestCase:testInsertIndexZeroUninitialized Which is followed by ListTestSuite-Initialized, and ListTestSuite-Uninitialized Each test suite then skips the test methods that don't apply to the initial conditions it established. Essentially what I am doing with the different test cases you push up to the lowest test suite level. Correct? This naturally leads to the question, if all you setup is done in the test suite, do you ever use the test case's Setup or Teardown methods for anything? Heh heh... that's what one developer says to another when they think the implementation is wrong. (j/k) Being able to easily test List and ListImp subclasses was a major goal. Is this something you've had difficulty achieving? (I can't quite get my head around all the ramifications of your implemention.) I believe you are correct. Nice catch!
-
Responding out of order, starting with (what I think is) the most interesting part because it's late and I won't get to address everything... Uhh... disconnecting the constants from the typedef doesn't fix the problem. The only output that changed is code path 2, which now outputs the correct value instead of an incorrect value at the cost of code clarity. I can easily imagine future programmers thinking, "why is this unbundling 's1' instead of using the typedef and unbundling 'FirstName?'" And doesn't disconnecting the constant from the typedef defeat the purpose of typedeffing clusters in the first place? You're going to go manually update each disconnected constant when you change the typedef? What happened to single point maintenance? Regardless, the constants was something of a sideshow anyway... like I said, I just discovered it today. The main point is what happens to the bundle/unbundle nodes wired to and from the conpane controls. (Paths 1, 3, 5, and 6.) Your fix didn't change those at all. Results from Typedef Heaven: Path 1 is still correct. Path 3 still returns correct data but has incorrect code. Path 5 still returns incorrect data and has incorrect code. Path 6 still returns incorrect data and has incorrect code. And, fixing path 5 still alters path 3 so what used to return correct data now returns incorrect data. All I can say is, if that's your version of heaven, I don't want to see your hell. The errors these different code paths demonstrate cannot be solved with typedefs. You can put process in place (insist on keeping Tree.vi updated) to try to mitigate the risk, but the process only works as long as people follow it. You can implement testing to try to catch those errors that have crept into your code, but no testing is going to catch all bugs and anyone who relies on testing to ensure quality is playing a losing game. At the same time, these very same errors cannot exist with classes. The whole reason these bugs pop up is because vi's that bundle/unbundle the typedef aren't loaded into memory when the edits were made. With classes, loading any method in the class automatically loads them all. In other words, you can't edit the cluster without also loading all the vi's that bundle or unbundle the cluster into memory.** The way LVOOP classes are designed doesn't allow these bugs into code in the first place. (**Strictly speaking this is not 100% true. However, breaking a class in this way takes almost a concentrated effort to do so and classes are far more robust to these kinds of changes than typedefs.) I see your point with respect to the cluster constants, though as I mentioned above I'm not convinced disconnecting the constant from the typedef is a good general solution to that problem. Specification? You get a software spec? And here I thought a "spec document" was some queer form of modern mythology. (I'm only half joking. We've tried using spec documents. They're outdated before the printer is done warming up.) Is this because you have only made a relationship between typedefs as clusters being synonymous with a classes' data control only? What about an enumeration as a method? It's past the stupid hour in my timezone... I don't understand what you're asking. My concern with typedeffed enums is the same concern I have with typedeffed clusters. What happens to a preset enum constant or control on an unloaded block diagram when I make different kinds of changes to the typedef itself? (More precisely, what happens to the enum when I reload the vi after making the edits?) I'm shocked. Using a class as a protected cluster is neither complex nor disposes of data flow. There are OO design patterns that are fairly complex, but it is not an inherent requirement of OOP. So your modules either do not expose typedefs as part of their public interface or you reuse them in other projects via copy and paste (and end up with many copies of nearly identical source code,) right? My fault for not being clear. I meant multiple instances of a typedeffed cluster. I was freely (and confusingly) using the terms interchangably. Dropping two instances of the same class cube on the block diagram is essentially equivalent to dropping two instances of a typedeffed cluster on the block diagram. Each of the four instances on the block diagram has it's own data space that can be changed independently of the other three. No. Based on this and a couple other comments you've made, it appears you have a fundamental misunderstanding of LVOOP. Labview classes are not inherently by-ref. You can create by-ref or singleton classes using LVOOP, but data does not automatically become by-ref just because you've put it in a class. Most of the classes I create are, in fact, by-val and follow all the typical rules of traditional sequential dataflow. By-ref and singleton functionality are added bonuses available for when they are needed to meet the project's requirements.
-
You suck up. You're limited to extending what operations are done on the data. Using classes I can extend what operations are done on the data AND extend it to different kinds of data. Yep... dynamically loaded vis present a problem. You also have a problem if you have a sub vi that isn't part of the dependency chain--perhaps you temporarily removed it or are creating separate conceptual top-level code that uses the same low level functions. There are lots of ways to shoot yourself in the foot when your workflow depends on vis being loaded into memory. (I have two feet full of holes to prove it.) Actually your comment reveals a fundamental difference between our approaches. "Loading the top level application" implies a top-down approach. After all, you can't load the top level vi during development if you don't have one. I tried that for a while but, for many reasons, abandoned it. I have had much more success building functional modules with fairly generic interfaces from the bottom up and assembling the top level application from the components. My comments are directed at typedeffed clusters. I'm still on the fence with typedeffed enums in a public interface. I can see holes where changes might cause things to break, but I haven't explored them enough yet. Sure thing. Grab the attached project (LV2010) and follow the steps in Instructions.txt. The example should only take a couple minutes to work through. Once you do that come back and continue reading. ... There are a couple interesting things to note about this example. 1) After editing the typedef, there were no compiler errors to indicate to the developer that something went wrong, yet three of the six paths returned the wrong data and five of the six paths now have incorrect source code, even though none of the sub vis were edited. I don't know about you, but I'm not too keen on code that automatically changes when I'm not looking. 2) Although Test.vi illustrates the outcome of all six code paths (Case 1 through Case 6) simultaneously, in a real app you usually won't have that luxury. You'll be looking at one specific code path in isolation because that's where the bug popped up. After following the steps outlined you can't make a change to a sub vi that fixes one code path without creating an error in another code path. (Ignoring the two paths using the constant, which are kind of degenerate cases I didn't know about until today.) For example, let's assume you made the edit described in Instructions.txt and during testing happen to encounter outputs from the code paths in order, 1 through 6. However, there could be some hours of dev work between one path and the next. Probing the outputs from the different code paths could easily lead to the following: Case 1: Output is correct. Nothing to investigate. Case 2: That's weird. I wonder how that constant got mixed up? No worries. I'll just swap the data and the output will be correct. Case 3: Output is correct. Nothing to investigate. Case 4: Output is correct. Nothing to investigate. Case 5: Hmm... output data is wrong. Oh look, the wrong element is unbundled. I can't believe I made that mistake. I'll just fix and... sure enough, the output is correct. Let me stop here and point out something. Fixing code path 5 actually breaks code paths 3 and 4, which were already checked and verified to return the correct result. Surely there's no reason to test them again, right? Eventually, if you keep iterating through the list of code paths and testing them you'll end up with correct code. (I'm not sure that's mathematically provable, but I think it is true.) In this example there are only 6 bundle or unbundle nodes in a total of four vis and it's pretty easy to see how the sub vis with the data. How many bundle/unbundle nodes will there be and how many sub vis have bundle/unbundle nodes in a medium sized application? Are you going to go check them everytime you edit the typedef? Furthermore, how do you *know* a typedef edit hasn't accidentally changed your code somewhere else? Opt 1 - Make sure all dependent vis are loaded into memory before editing the cluster. Ans 1 - This is impractical for the reasons I explained above... you can't *guarantee* you have all the dependent vis loaded unless you have known, closed set of vis that can access the typedef. Opt 2 - Limit the kinds of edits allowed. It's okay to add new elements but don't ever reorder them. Renaming is probably okay, as long as you never use a name that has been used previously in that cluster. Ans 2 - Personally I use naming and grouping as a way to help communicate my intentions to other developers and my future self. Removing the ability to do that sacrifices code clarity for me, so I reject that option just based on that alone. However, there are other considerations that also make this option undesirable. How easy is it to recover when somebody mistakenly violates the rule? If discovered right away it's not too bad. You can just revert to a previous check in and call it good. If it's been a couple weeks you're in a whole lot of hurt. There's no way to know exactly which vis were affected by the change and which were not. (Remember, testing doesn't necessarily uncover the problem.) You either revert two weeks of work or manually inspect every bundle/unbundle node for correctness. Neither option is appealling when schedules are tight. Opt 3 - Use classes as protected typedeffed clusters. Ans 3 - A few extra minutes up front pays off in spades down the road. Opt ? - Any other ideas I've missed? Typedeffed clusters are safe when used under very specific circumstances. When used outside of those circumstances there are risks that changes will break existing code. In those situations my confidence that I'm making the "correct" change goes way down, and the time required to make the change goes way up. Using a class in place of a typedeffed cluster gives me a much larger set of circumstances in which I can make changes, and a larger set of changes I can make and still be 100% confident no existing code, loaded into memory or not, that depends on it will break. "Single point maintenance" of typedeffed clusters is an illusion. Absolutely it is. My point was that even if a class was nothing more than a protected typedef, there are enough advantages just in that aspect of it to ditch typdeffed clusters and use classes instead. Don't underestimate the value of *knowing* a change won't negatively impact other areas of code. Some may consider adequate testing the proper way to deal with bugs my example illustrate. I prefer to design my code so the bugs don't get into the code in the first place. (I call it 'debugging by design,' or alternatively, 'prebugging.') The object is instantiated with default values as soon as you drop the class cube on the block diagram, just like a cluster. What do you do if you want multiple instances of a cluster? Drop another one. What do you do if you want multiple instances of a class? Drop another one. What does a class have inside its private ctl? A cluster. How do you access private data in a class method? Using the bundle/unbundle prims. At it's core a class is a cluster with some additional protection (restricted access to data) and features (dynamic dispatching) added to it. Nope, I mean immutable objects. Constant values are defined at edit-time. The values of immutable objects are defined at run-time. I might have many instances of the same class, each with different values, each of which, once instantiated by the RTE is forever after immutable and cannot be changed. I can't wait... Typedef Hell.zip
-
Wow... lots of comments and limited time. (It's my wife's bday today; can't ignore her and surf Lava too much.) It doesn't make it not reusable. Rather, it limits your ability to reuse it. A good reusable component doesn't just wrap up a bit of functionality for developers. It gives them extension points to add their own customizations without requiring them to edit the component's source code. When a component exposes a typedef as part of its public api it closes off a potentially beneficial extension point. My bigger issue with typedefs is that it makes it harder to refactor code during development, which I do a lot. I know typedefs are the golden boy of traditional Labview programmers, due (I think) to their ability to propogate changes through the project. Here's the rub... changes propogate only if the vis that use the typedef are loaded into memory. How do you know if everything that depends on that typedef is loaded in memory? Unless you are restricting where the typedef can be used (by making it a private member of a library, for instance) you don't. "But," you say, "the next time a vi that depends on the typedef is loaded it will link to the typedef and all will be well." Maybe it will, maybe it won't. Have you added new data to the typedef? Renamed or reordered elements to improve clarity? Sometimes your edits will cause the bundle/unbundle nodes to access the wrong element type, which results in a broken wire. So far so good. However, sometimes the bundle/unbundle node will access the wrong element of the same type as the original, in which case there's nothing to indicate to you, the developer, that this has happened. (Yes, this does happen even with bundle/unbundle by name.) You have to verify that it didn't happen by testing or by inspection. Classes are superior to typedefs for this reason alone. If I rename an accessor method (the equivalent to renaming a typedef element) I don't have to worry that somewhere in my code Labview might substitute a different accessor method with the same type output. If it can't find exactly what it's looking for I get a missing vi error. It might take me 2 mintues to create a class that essentially wraps a typedeffed cluster, but I save loads of time not having to verify all the bundle/unbundle nodes are still correct. Another thing I've been doing lately is using classes to create immutable objects. I give the class a Create method with input terminals for all the data and appropriate Get accessors. There are no Set accessors. Once the object is created I can pass it around freely without worrying that some other process might change a value. This saves me time because I never even have to wonder what happens to the data, much less trace through the code to see who does what to it. In short, using classes instead of typedefs gives me, as a developer, far, far, more confidence that changes I'm making aren't having negative effects elsewhere in my code. That translates directly into less time analyzing code before making a change and testing code after the change. Doesn't mean there aren't better alternatives. Sending messages by telegraph was a well-established technique for many years. Can I expect your response to come via Western Union? That was an off the cuff comment intended mostly as a joke. However, -My premise 2 can be proven to be true, though I have not done so. -There's no reason deductive reasoning doesn't work for generalizations as long as the conclusion doesn't claim certainty. -"Most OOP programs are more complex..." Software complexity is a completely subjective term. How do you measure the relative complexity of different programming paradigms? Lines of code written? Number of execution paths? Time it takes to understand enough code to make a necessary change? Yep, it's a no. You're asking for scientifically verifyable and repeatable evidence for a process that defies scientific analysis. Doesn't mean it's a false claim. If I'm understanding this chain of reasoning... You've found limited success reusing code across projects using traditional LV techniques, therefore, the benefit of improved reuse using OOP techniques isn't "real" benefit. That seems like flawed logic. Nope. As a matter of fact my personal experience is that using that as a way to decompose a problem into a class implementation doesn't work very well. It creates hierarchies that tend to be inflexible, which defeats the purpose of using OOP in the first place. Odd, because I view this as a major weakness of traditional LV techniques. With traditional programs I often need to trace code down into the lowest level to understand what is happening. Even if the lower level stuff is of the cut-and-paste or boilerplate reuse variety (often favored by traditional LV programmers) it could and probably does contain custom modifications, so I have to dig into it everytime I encounter it in a different project and if I am working on multiple projects it is easy to get the differences mixed up. I believe overly complex interactions are a result of inadequate componentization as opposed the decision to use an OOP or structured programming approach. Classes make it easier to create decoupled components, which in turn makes it easier to create an application using components compared to structured programming. (I'm not even talking about reuse components here, just the major functional components of that application being developed.) -OOP does use a lot more vis than traditional techniques. That used to bother me, but I view it as a benefit now. That's one of the things that keeps them flexible. Building too much functionality into a single vi increases the chance you'll have to edit it. Every time you edit a vi you run the risk of adding new bugs. Furthermore, on multi-developer projects only one person can edit a vi at any one time without having to merge the changes. (Which LV doesn't support very well.) -What extra tools are required to realize OOP? I have Jon's class theme changer, but it's certainly not a requirement. -Bugs in OOP core... I do get frustrated with the occasional crash. Some of them are directly related to using classes. I don't think all of them are though and the crashes I can positively attribute to using classes amounts to less than half of all crashes I have. -Whether a class requires initialization depends entirely on what you put in the class. There's nothing inherent to classes that makes initialization a requirement. I'll have to think about this for a bit. Off the top of my head I'm not sure there's a real difference. At a fundamental level a class is just a cluster that uses accessor methods instead of bundle/unbundle. I don't see how that makes a difference here. I don't think this analogy holds. Classes only need to be "launched" if they contain run-time references. A closer approximation of an object instance is dropping a typedef constant on the bd. If the typedef has a queue constant in it then you have to worry about the same things. See, I don't follow this argument. There's nothing inherent about classes that violates data flow. Some do, some don't. It's all about what the class designer intends the class to do. The reason I use classes instead of AE's if I need a singleton has more to do with not wanting to put too much functionality in a single place. I do try to avoid using singletons though, simply because it makes it harder to control the sequencing. Me too! Brother! QFT. I'm pretty sure you can get about the same level of encapsulation using libraries and traditional techniques. Using classes instead of typedefs and naked vis for the component api makes the component much, much, more flexible. Not necessarily. Like Shaun, I also use an agile approach. My dev work is broken down into 2 week sprints, with the goal of delivering a functional and complete component at the end of the sprint. The components are designed without a UI, so I'll create a very simple UI that wraps the component and exposes all of it's functionality. I build a small executable and give that to the customer so they can determine if that part of the app does what they need it to do. There's no big design up front, I'm just focusing on how to get that component working correctly. Because the rest of the app hasn't been designed, I don't necessarily know what the data sent into the component is going to look like. The flexibility provided by classes are a big help here. In fact, Friday afternoon I finished a PacketFilter component for extracting only the data I'm interested in from a fairly complex communication protocol from one of our devices. I should do a write up of how a component evolves over time. The charge of being too interested in the academic aspects of OOP at the expense of practical functional has been levelled at me before, but I don't think this analogy applies to me. My decision to use OOP derives entirely from practical considerations. I can deliver a more robust application and reduce the time I spend on that app over its lifetime. Admittedly, I am interested in what the "academically optimal" design looks like. Understanding that helps me understand the tradeoffs of the many implementation shortcuts, knowing that helps me know when it's okay to use those shortcuts.
-
Last year's summit is what inspired me to move forward with my own certification.
-
Quick response... I'll try to fill in more later. Hmm... how to explain this without coming across as a pompous ass? I'm not sure why you disagree. Most LV users are not professional developers who get paid to write LV apps. (NI has said as much--that's why they make decisions that focus on ease of use and approachability.) They are engineers, scientists, or technicians who use LV to accomplish a task that's related to what they *are* paid to do. The software is a side effect of their work, not the goal of their work. Contrast that with users of other major languages, such as c/c++, java, or c#. Producing software is typically what they are hired to do. They are much more likely to be working in a dedicated software development environment and can reap the benefits of that. My statement reflects that, on average, people who use LV in their work environment have less formal training and software development experience than, say, people who use c++ in their work environment. "Elitism" carries the connotation of unjustified authority and the arrogance of personal superiority over those who are not elite. In that sense I hope I do not come across as elitist. Am I elitist for recognizing that certain people have learned a set of skills and have the experience that makes them better suited for specific tasks? Personally I don't think so, but others might. (Though I wonder how they would justify hiring a contractor for their home remodel as opposed to, say, the paperboy.) Again, not trying to be a pompous ass... If one perceives classes and action engines are equivalent, it's pretty apparent to me they don't understand OOP. (By logical symmetry it could be that I don't understand AE's... I'll leave that debate for another time.) The differences between them have significant long term implications. I really don't have an issue when an informed business decision is made to use an AE. Sometimes, based on programmer skill, existing code base, and project requirements, an AE is the correct business decision. As a software design construct it is clearly inferior to classes. What I frequently see is AEs implemented without considering alternatives or even understanding the tradeoffs between the various options. Out of time. The rest will have to wait until later...
-
I like to do this too. One thing I haven't figured out is how number a test build for a new major release. I'd like the released build to be version 5.0.0, but then I run into the irritating mathematical property that any version number less than 5.0.0 is part of the version number set defined by 4.x.y, which defeats the purpose of using the major version number. How do you deal with that? (Idle thought... I wonder how a negative minor version number would affect the many tools we use...)
-
Done. Your serve. I agree it looks good. And don't let the apparent simplicity discourage you from posting. If you're exploring modular programming and learning how to handle those issues, the last thing you want is a lot of complexity in each module. One point here... by putting the analysis algorithms in the xcontrol you are prevented from using those algorithms programmatically. You can't reuse the analysis in other apps unless you want to display it in exactly the same way, and there's no way for you to get the results of the analysis to do additional decision making. A more flexible approach is to create a lvlib or class that does the analysis and returns the results, then display the results on a control in your application code. Xcontrols are best used to customize the way a user interface element responds to user actions. We have some legacy code in which a fairly complex parsing process was implemented as an xcontrol. Now we all look at it and say, "well that was silly."
-
This thread branched from the latter part of this discussion. Visit that thread for the background. I'll start off by responding to Shaun's post here. (Although this started as a discussion between Shaun and myself, others are encouraged to join in.) The OOP mantra is "traditional LV programmers create highly coupled applications..."? Huh... I didn't realize LV had become so visible within the OO movement. I think you're extrapolating some meaning in my comments that I didn't intend. You said most LV users would use a typedef and be done with it, implying, as I read it, that it should be a good enough solution for the original poster. My comment above is a reflection on the primary goal of "most" LV programmers, not an assertion that one programming paradigm is universally better than another. "Most" LV programmers are concerned with solving the problem right in front of them as quickly as possible. Making long term investments by taking the time to plan and build generalized reuse code libraries isn't a priority. Additionally, the pressures of business usually dictates quick fix hacks rather than properly incorporating new features/bug fixes into the design. Finally, "most" LV programmers don't have a software design background, but are engineers or scientists who learned LV through experimentation. In essence, I'm refuting the implication that since "most" LV programmers would use a typedef it is therefore a proper solution to his problem. He is considering issues and may have reuse goals "most" LV programmers don't think about. With uncommon requirements, the common solution is not necessarily a solution that works. My statement can be shown to be true via deductive reasoning: Premise 1: *Any* software application, regardless of the programmer's skill level or programming paradigm used, will become increasingly co-dependent and brittle over time when the quick fix is chosen over the "correct" fix. Premise 2: "Most" traditional LV programmers, due to business pressure or lack of design knowledge, implement the quick fix over the "correct" fix most of the time. Therefore, most traditional LV programmers create applications that limit reusability and become harder to maintain over time. However, I suspect you're asking about scientific studies that show OOP is superior to structured programming. I read a few that support the claim and a few that refute the claim. Personally I think it's an area of research that doesn't lend itself to controlled scientific study. Software design is a highly complex process with far too many variables to conduct a reliable scientific study. As much as critical thinkers eschew personal experience as valid scientific evidence, it's the best we have to go on right now when addressing this question. Just to be clear, I don't think an OO approach is always better than a structured approach. If you need a highly optimized process, the additional abstraction layers of an OO approach can cause too much overhead. If you have a very simple process or are prototyping something, the extra time to implement objects may not be worth it. When it comes to reusablity and flexibility, I have found the OO approach to be clearly superior to the structured approach. One final comment on this... my goal in using objects isn't to create an object oriented application. My goal is to create reusable components that can be used to quickly develop new applications, while preserving the ability to extended the component as new requirements arise without breaking prior code. I'm not so much an OOP advocate as a component-based development advocate. It's just that I find OOP to be better than structured programming to meet my goals. So does a class. Classes also provide many other advantages over typedefs that have been pointed out in other threads. No time to dig them up now, but I will later if you need me to. I'll bite. Explain. I'm curious what you have to say about this, but no programming paradigm is suitable for all situations. Hammering on OOP because it's not perfect doesn't seem like a very productive discussion.
-
You are absolutely correct. Most traditional LV programmers would use a typedef without a second thought. Of course, most traditional LV programmers create highly coupled applications that offer little opportunites for reuse and become increasingly rigid and fragile over the life of the application. However, since the OP mentioned creating "a modular data acquisition & analysis tool," I inferred that he is interested in avoiding those problems. As a general rule I think it is a bad idea to expose typedef clusters as part of a component's public interface. Not because they create dependencies, but because they do not provide sufficient safety in the face of changing requirements. If you can guarantee that all code that will ever depend on that cluster will be loaded into memory whenever the typedef is changed, then you're fine. Sometimes I'll use them as private members of a component library to facilitate passing data between member classes. On the other hand, as soon as your cluster is released as part of a reusable component's public interface, you can't make that guarantee and any changes to the cluster run the risk of breaking existing code. If my component's public interface has data that can't be represented using LV's native data types, I'll create a class that encapsulates the data and provide appropriate accessors that *do* use native data types. It's safer, more flexible, and ultimately results in reuse code libraries that are easier to understand and use. Now... tell me more about this "Task" place you're taking me to. It sounds fascinating...
-
Smart! I think this solution will get the OP up and running quickest. Typedefs (any custom type, really) create dependencies between components. Using the waveform attribute or variant messaging keeps each component from being dependent on other components. Instead, the components are dependent on the interface definition. (i.e. Tag the waveform with the attribute "accelerometer" to indicate it contains accelerometer data.) If the component is reusable, it's much easier and safer to update the interface later as new requirements arise this way.
-
I knew they were expensive--I didn't know they were *that* expensive. I wouldn't normally consider 15 pts/sec on four charts an excessive amount of data. Running the decimated case on my work computer loaded the cpu ~20% when scrolling the data. Holy missing processor load Batman! Turning off y-axis autoscaling on each of the four charts reduced the load from ~20% to less than 5%. (Too bad it's already turned off on my app...)
-
The answer depends somewhat on your goal for your modules. I'll assume your two main modules are daq and analysis. Do you intend to be able to reuse either of them in other apps independently of the other? If so, there can't be any dependencies between the two modules. On the other hand, if this is all application-specific code then coupling them together somewhat will help you get the job done faster. Jon's suggestion is good and will work. The downside is that by using the channel class into your analysis module, the module becomes dependent on that class. If you want to reuse the analysis module in a different app the channel class hierarchy needs to be duplicated too. This isn't necessarily a bad thing--it depends on what your goals are. If you do go that route I'd suggest making the channel class hierarchy part of your ChannelAnalysis.lvlib to avoid missing links when reusing the library. Being aware of and managing dependencies between components is critical to building a successful system. It's one part of "managing the seams" of your application. Make sure you take time to consider each component as an independent entity, ignoring all the other components in your system. What does this component do? What will it need to do in the future? What are its dependencies? Are those dependencies okay? What does the public api look like? Is it clear? Is it complete? (Can component users do anything they reasonably would expect to do?) Are the methods distinct? (Is there overlapping functionality in any of the public methods?) If you want a component to be completely independent of any other code, your public api can only expose types that are either native LV types (string, variant, LVObject, etc.) or types that are included in your component's library. If I'm understanding your problem correctly, you've discovered you now need to send information about the waveform along with the waveform data itself, but you can't because the queue is typed for waveforms. Using 'traditional' LV techniques this was often accomplished by flattening the data to a variant and adding attributes for the meta-data. Your analysis component then reads the variant's attributes and acts according to what it finds. Personally, that doesn't provide enough type-safety for me. I find the explicit contracts of an OO approach are easier to work with from the component users point of view. I have a generalized queue-based messaging library where all my queues are typed for Message.lvclass. In your case, I would have created a Message subclass (call it "WaveformMsg.lvclass") with accessor methods for carrying the waveform data. When it came time to add meta-data to the message, there are several options. I won't go into too much detail here, but feel free to ask questions if you're interested. They all accomplish the same thing. 1) Use the same WaveformMsg class for each waveform configuration, but give the object a different message name that reflects the configuration. This is what I usually do. It provides a balance of flexibility and type safety that I'm happy with. 2) Add fields for the meta-data to WaveformMsg and generate the accessor methods. Use the accessors in the analysis component to decide what to do. If there were potentially a large number of waveform configurations I'd do this to avoid having too many similarly named messages exposed in the component's api. 3) Create a new message subclasses for each of the waveform configurations. The subclass can derive from Message or from WaveformMsg. This provides the most type safety, but creating new classes for every possibly message can become cumbersome. Not quite. By-value, by-reference, and global objects refer to a high-level view of when copies of the class data are created. By-value objects create a new instance (copy) of the data when wires are branched. Most LV data types are by-value. By-reference objects don't create data copies when the wire is branched; each branch still refers to the same instance of data. Creating a new instance of that type requires calling the type's Create method again. Unnamed queues are a native LV type that is by-ref. Note that both by-val and by-ref require wires are passed around. Global is similar to by-ref, except calling the constructor again doesn't create a new instance of the data, it gets a reference to the existing instance of the data. A named queue is an example of a global object. This is what you are considering. I try to stay away from globally available objects. It tends to lead to nasty dependency issues with too much interlinking between components.
-
Really? I don't use named queues since that opens a hole in my encapsulation. Yep. With the last vi I posted the load is <2% prescrolling and ~8% while scrolling if I enable decimation. When I disable decimation the prescrolling load is ~5% and scrolling load is ~30%. My app does use decimation though, so the question I'm facing now is why does repainting the model use so much less cpu time than repainting the app? They do essentially the same thing, except the apps functional components are wrapped in more layers of abstraction. That question is going to have to wait until I get back to work on Monday.
-
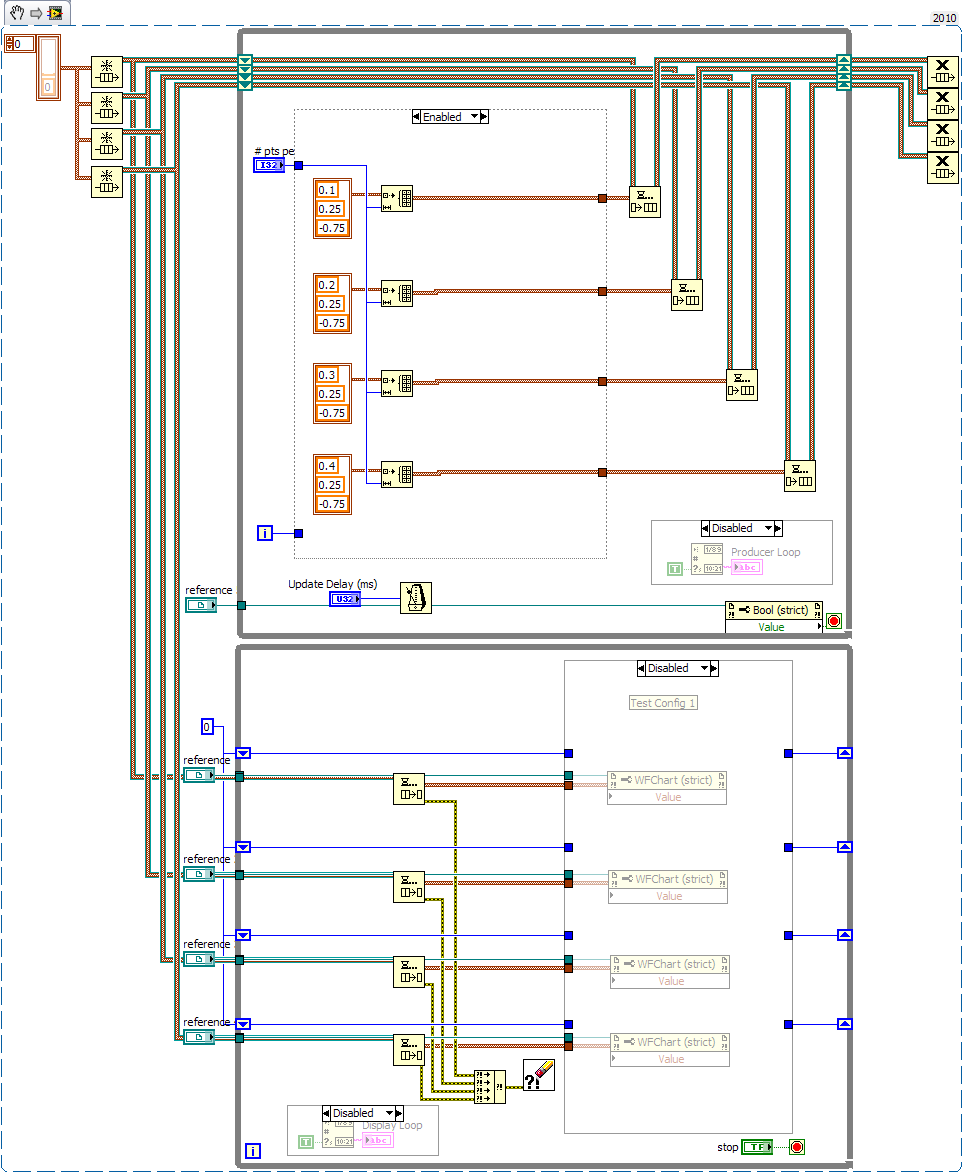
Here is a better model of my app. In particular, the case structures in the display loop was the quick and dirty way I decimated the data. (Friday afternoon I replaced that with a time-based decimation, but I think this is sufficient for the model.) Some of the differences between my app and this model are: -Data is collected from a Beagle I2C monitor. -The data collection module runs in a dynamically launched actor state machine. -App has more threads... data collection, user input, chart update, mediator, etc. -Uses my object-based messaging library to pass messages between the loops, so there is a (tiny?) bit more overhead with the boxing/unboxing. -Each of the four I2C ICs output data at slightly different rates. The data collection module sends the data out as soon as it gets it from the Beagle. Overall I receive ~1250 data packets/sec. I added a multiplier to simulate changes to the source signals. In the app, sometimes source signal changes don't show up on the chart until several seconds have passed, even though the receive queue is empty. I haven't been able to recreate that condition in this model. I also added code to monitor the queue size. Sometimes, inexplicably, the data queue in the app will continuously grow. The only way to fix it is to close the project. (I posted a bug about that recently.) That hasn't occurred in my model either. WaveformStressTest2.vi
-
Absolutely. Good catch! That also could be why I get very different results on my laptop and desktop. On my home computer probing the loop counters had the lower loop running about twice as fast as the upper loop. The easiest solution is to remove the dequeue timeout completely, though adding 2 ms to Update Delay before wiring it to the timeouts solved the problem too. (I'll have to add more code to more closely model what my app is *really* doing... it only has a single queue.) When I was testing with this I was making big changes to the Update Delay and I didn't want to have to stop and restart to fix the timeout value. Why did I have the timeout value in the first place when it isn't needed? I don't remember exactly, but I think when I was first putting it together I didn't have the release queue prims outside the top loop, so the lower loop would block and the vi would hang. Looks like I wasn't diligent enough checking my code as it evolved. I'm pretty sure this is incorrect, unless I have a fundamental misunderstanding of how the obtain queue prim works. I should be getting four different unnamed queues, not four instances of the same unnamed queue. Probing the queue wires gives me four unique queue refnums and the code runs correctly when I change the top loop as shown here. Regardless, your point about the race condition was spot on.

-
It shouldn't be free running straight out of the box. The default update delay is set to 3ms. Am I missing something obvious? The original testing was done on my work laptop. Downloading and running the code at home on my desktop has very different results. Running it straight out of the box used <3% of my cpu. My home computer is 3 years old so it's no powerhouse, but it does have a good video card. I wonder if that could be the difference? I'm also running XP at home and Win7 at work, so that could contribute too. I dunno... seems weird.
-
Thanks for the reply Omar. I take it you're the resident VI Tester expert? (You seem to be the one always responding to questions about it. ) BTW I updated the original post with code that includes the missing library. That's what I figured, but without someone to bounce ideas off of I'm left fumbling around in the dark. It feels a lot like when I first started designing OO applications. I have created several test cases with properties that can be set up by the test suite. That's what prompted the question about independently executing test cases. Since the algorithm determining the test case results are hard coded into each test method, the test methods themselves will return test failures if the properties are not set up correctly. Visualization is reportedly a powerful way to make good things happen, but I haven't figured that one out either. I tried that the last time I dug heavily into VI Tester. I didn't think it worked very well either. I haven't figured out a good way to do that yet without making the test case really complicated. Not every test method needs to be executed for every test environment. (I don't think there's a way to exclude *some* of a test case's test methods for a specific test suite is there?) So I ended up putting a lot of checking code in each test case to determine what the input conditions were so I'd know what to compare and whether the test passed or not. Ugh... my test methods got more complicated than the code it was testing. In this project I'm testing a single class. I have five test cases for it right now: ListTestCase-Initialized -- Happy path test cases. The object has been set up correctly before calling any methods. ListTestCase-Uninitialized -- To test behavior with objects where the Create method hasn't been used. ListTestCase-ErrorIn -- Test error propogation and make sure the object's data hasn't changed. ListTestCase-CreateListMethod & ListTestCase-DestroyMethod -- I created independent test cases for the creator and destroyer in order to make sure they obtain and release run-time resources correctly. I do this by injecting a mock dependency object with a queue refnum I can access after the creator or destroyer is called in the test method. But there's no need to test all the other methods with the mock dependency, so they ended up with their own test cases. *shrug* I think I understand a little better now... the Test Hierarchy view is a virtual hierarchy. With the latest release (I think) each test case can show up under more than one test suite. The test suite setup code will be called depending on where in the hierarchy view you chose to start the test. Correct? Absolutely it helps. Thank you. I realized that if you're going to look at my code I probably need to explain how the code is expected to be used so you understand what I'm trying to accomplish with these tests. I'll try and get something up this weekend. In the meantime the discussion has helped me identify a few places where I think I can improve my test cases.
-
Great, I just encountered this error too. I guess I'll just call them up and not say anything....