Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-
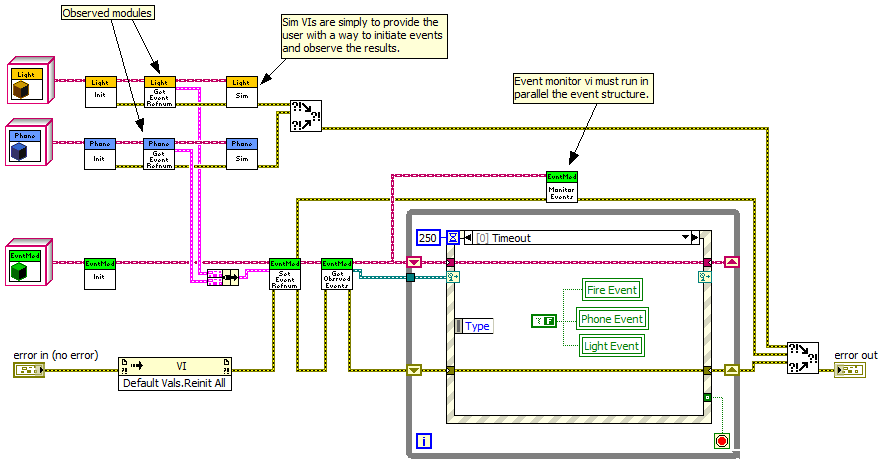
I'm not following. Why would you send a User Event Refnum from the caller to the xctl if the goal is simply to get a cluster of the xctl's User Events? I don't want the xctl to control when the calling code registers for events. This still requires the calling code to have direct access to the xctl's User Event Refnums, which I don't think is a good general purpose pattern. Too much risk of rogue code destroying the refnum somewhere along the way. If that happens the xctl has to be smart enough to create a new User Event Refnum and all the listeners have to be smart enough to reregister for the event. IMO this causes too much overhead for the xctl developer, couples xctl code to listener code too tightly, and most importantly, simply allows poorly written listeners too much control over the xctl's internals. -------------------- Here's the example code I developed several months ago. I cleaned it up but didn't test it thoroughly so you may find bugs. -------------------- [Edit] Yep, you're right. I stand corrected. "If the user event is not registered, the Generate User Event function has no effect. If the user event is registered but no Event structure is waiting on it, LabVIEW queues the user event and data until an Event structure executes to handle the event. You can register for the same user event multiple times by using separate Register For Event functions, in which case each queue associated with an event registration refnum receives its own copy of the user event and associated event data each time the Generate User Event function executes." Looks like the Observer example I just posted needs some... uhh... re-engineering. Observer Pattern.zip

-
FYI, that happens to people inside Microsoft too. (And it ticks them off just as much.)
-
I struggled with this question for a while too, though not specifically with regards to XControls. If I'm understanding your question, first you have to ask yourself, "should I use an observer pattern or a publish-subscribe pattern?" Often these two terms are used interchangably but I think there are important differences. In an observer pattern, the code being observed has no knowledge of any observers. It might have 20 observers; it might have 0. It doesn't care and just continues doing what it's doing. If you think of observing something through a telescope, the thing you're looking at generally doesn't know you exist, much less that you are interested in it. In a publish-subscribe pattern the subscriber has to register with the publisher and the publisher generally keeps track of who the subscribers are and how many subscribers there are. Consider subscribing to a newspaper; you call up the publisher, they record your name and address, and then they deliver the paper to your roof until you tell them to stop. Which pattern you choose depends on how you want to manage the lifetime of the publisher/observable code module. If you want the module to self-manage it's lifetime and stop only when nothing depends on the events it generates, use the publish-subscribe pattern. If you're willing to manage the module's lifetime yourself or if you don't care if the module stops while other code is waiting on its events, use the observer pattern. User events work pretty well for the observer pattern. However, if you expose the User Event Refnum, be aware that observing code can destroy the refnum and generate an error in the observable code. I prefer to expose the Event Registration Refnum and keep the User Event Refnums private. That protects the observable code from malicious code and inexperienced developers. The downside is that it's harder for the observing code to dynamically register/unregister for a subset of the events the observable code produces. I've experimented with using an event manager class as mediator between the observable code and the observing code. The event manager registers for all the events the observable modules expose. The observing code then tells the event manager which events it is specifically interested in. I think there must be a better way but I haven't figured it out yet. I don't have a very good feel for implementing a robust publish-subscribe pattern. My sense is injecting user events into the publisher isn't the best way to do it. Callback VIs? Separate subscribe/unsubscribe methods for bookkeeping? I don't know; I haven't explored it enough. For the observer pattern, I prefer option A. I have an example on my other computer. I'll try to post it later today. I agree with everything you said except this. I believe the user event queue exists at the event structure, not the the user event refnum or event registration refnum. If there are no registered event structures, there is no queue to fill up. Is the resource overhead of generating a user event on a user event refnum or event registration refnum that is not wired into an event structure high enough that this is something we need to worry about? Or is this just an easier way to manage the bookkeeping of which events the listener is interested in? Since the user event refnums and event registration refnums are strongly typed, you can only put them in an array if they have the same data type. What's the recommended technique for dynamically registering/unregistering for events that have different data types?
-
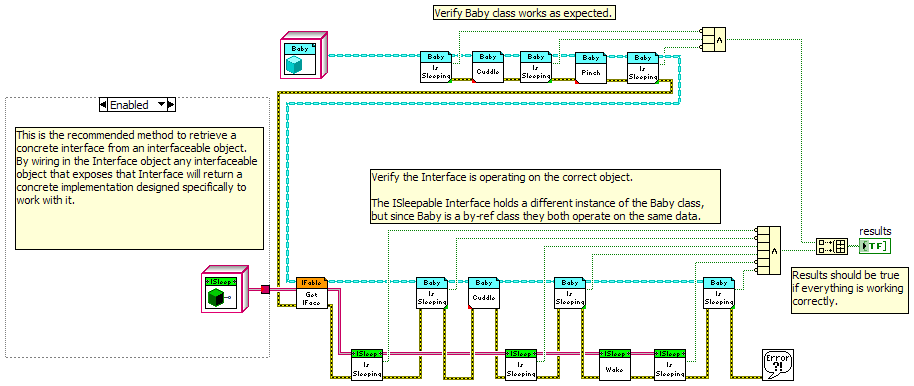
Updated to v0.10.0 [Note - Public api has changed. Backwards compatibility is broken.] -Removed the InterfaceBag from the framework. Interfaceable classes now override Interfaceable:_GetInterfaces and simply return an array containing the concrete interfaces that have been implemented for that class. -Changed the concrete interface retrieval mechanism from a string-based 'name' comparison to using the Preserve Run-Time Class primitive. -Removed all name properties from IUnknown. -Updated BabyDemo to reflect new public api. -Created some new UML diagrams to reflect the new design. [Edit Aug 3, 2010 - Removed pre-release version. Get current version from the Code Repository.] The change to the public api involves the inputs to Interfaceable:GetInterface. Instead of using the name of the Interface you simply wire in an object of the Interface you want to retrieve. I'm curious how my changes compare to yours kugr. These are questions for the class users, not the class developer. When using a class that exposes various interfaces, is there value in obtaining a list of names of Interfaces the class supports or an array of all the concrete interface objects? My gut says no. What do you think? I think I saw a comment from you somewhere indicating you are using this framework or a variation of it in real code, which is more than I've done. If so, you have more real-world experience than anyone else in the whole world with Labview Interfaces. Since you're the expert... what do you think? I'm really liking the simplified framework but I'll add the names back in if anyone can convince me of their usefulness. As I was working on this tonight I got to thinking again about using interfaces with by-val classes. When I looked at that previously I was never quite happy with what I had to do to recover the original object from the Interface. The PRT trick helps with that, though I would prefer a RecoverObject method smart enough that I wouldn't have to wire an object into that method to tell LV what to cast it into. I wonder how far up the wire the PRT prim looks for a valid object type?
-
No worries. A hijacked thread is better than a dead thread.
-
No attachment this time... I'm running low on server space and haven't purchased a premium membership yet. I've been too busy to look at this for the past week and as far as I'm concerned that's ancient history. Hopefully I haven't forgotten everything.... Good point. As a matter of fact the InterfaceBag might be completely superfluous at this point. I suppose it could be replaced by a private data array containing the concrete interfaces a class supports. I'll have to think about the tradeoffs for a bit... Yep, that's what I was saying. I'd prefer to do direct type comparisons rather than rely on arbitrary string values; there's always a chance two different Interfaces will return the same string value. Very close. The PreserveRuntimeClass prim would be inside Interfaceable:GetInterfaces, meaning the Interface is returned to the class user correctly typed and the user doesn't have to use either prim to downcast to a specific Interface. Depends on the classes being discussed. SmartCellPhone objects will return an ISleepable interface, so the class designer needs to decide if the ISleepableCellPhone methods are appropriate in the context of SmartCellPhone objects. If not, they can override them with new implementations. I have some questions regarding using interfaces that anyone is free to respond to: Assuming GetInterface takes an Interface object as an input instead of the Interface's name as an input, is it useful to have a GetNames method that returns a string array of Interface names that an object supports? The more I think about it the more I have a hard time coming up with a valid run time use case for it. Is a GetInterfaces method that returns an array of supported concrete interfaces useful at runtime? The only use case I can think of for this is to check an interfaceable object to see if it supports a given Interface, and I think a better implementation is to simply raise an error in GetInterface if the class does not support that Interface.
-
Got it. Create/Obtain for by-ref classes. Init for by-val classes. (How do you distinguish between Init methods that modify an input object and Init methods that simply spit out a preinitialized object? Or is it best practice that Init methods always/never have a class input terminal?) It's not the cube itself that causes confusion. It's the inconsistent behavior of the object on the wire coming out of the cube. I look forward to your comments. I realize I'm in the minority with this viewpoint. I'm also aware that there have been lots of discussions about initializing classes and I suspect many at NI are tired of talking about it. The discussions I've seen focus on constructors or the improved convenience auto-initializing classes provide. The convenience is nice, but I'm more concerned about having consistent use patterns for classes with different behaviors and properly hiding the implementation from the class user. I have not seen any responses from NI people on these two questions with respect to this issue. (Granted I don't browse the NI forums very often.) Nor have I seen an explanation of why we shouldn't be able to create classes that automatically initialize runtime resources. The Decisions Behind the Design kind of skirts around the issue but it doesn't directly answer the question. The functions palette is useful for reusable code designed to be used across different projects. It is much less useful for project-specific reusable code. Also, the palette only hides the organizational complexity of the class. It does not 'hide' the effects a reference in the class has on class users. By the way, feel free to speak openly and tell me I'm a bonehead if that's how you see it. I opine a lot on Lava and I'd much rather have people come out and tell me I'm wrong than respond with platitudes or ignore the issue altogether. I won't be offended, I promise.
-
 I think I've used a global variable once in my 3 years of Labview programming. For me this is clearly a case of out-of-sight, out-of-mind. Using a global in this way never even occurred to me. I don't see why not. I like the idea -- as long as the class implements protections to prevent the problems you outlined. Global variables also have other advantages over a SEQ and DVR: No Init method required! Queue names, I think, exist in a global namespace. Though unlikely, it is possible two different code modules could attempt to use the same named queue. The global VI exists in the library namespace, so (I assume) you don't have to worry about stepping on another global with the same name. On the flip side, I can build GlobalLock and GlobalUnlock commands into a functional global to prevent a parallel write while I'm doing my read-modify-write. This gives the class developer an easy way to prevent race conditions. I don't think there's a way to do that with globals.* You could write GlobalRead, GlobalWrite, GlobalLock, and GlobalUnlock VIs, but you have no way to enforce their use within the class. The class developer can still use semaphores to prevent the class user from encountering race conditions. It's just harder to verify there are no race conditions possible in the class code. (*I suppose you could create a GlobalBase class with Lock and Unlock methods that set an internal flag. For each new global variable you would derive a new child class and implement ReadGlobal and WriteGlobal static methods. Once you've done all that you've essentially made a more complicated functional global, so I don't think there's any point in doing this...) I think if the class/library is small enough for a single developer to fully understand and verify race conditions can't exist, globals are a very good option. As the code gets larger and more complex, manually verifying race conditions can't exist becomes harder and the argument for one of the more accepted techniques become stronger.
I think I've used a global variable once in my 3 years of Labview programming. For me this is clearly a case of out-of-sight, out-of-mind. Using a global in this way never even occurred to me. I don't see why not. I like the idea -- as long as the class implements protections to prevent the problems you outlined. Global variables also have other advantages over a SEQ and DVR: No Init method required! Queue names, I think, exist in a global namespace. Though unlikely, it is possible two different code modules could attempt to use the same named queue. The global VI exists in the library namespace, so (I assume) you don't have to worry about stepping on another global with the same name. On the flip side, I can build GlobalLock and GlobalUnlock commands into a functional global to prevent a parallel write while I'm doing my read-modify-write. This gives the class developer an easy way to prevent race conditions. I don't think there's a way to do that with globals.* You could write GlobalRead, GlobalWrite, GlobalLock, and GlobalUnlock VIs, but you have no way to enforce their use within the class. The class developer can still use semaphores to prevent the class user from encountering race conditions. It's just harder to verify there are no race conditions possible in the class code. (*I suppose you could create a GlobalBase class with Lock and Unlock methods that set an internal flag. For each new global variable you would derive a new child class and implement ReadGlobal and WriteGlobal static methods. Once you've done all that you've essentially made a more complicated functional global, so I don't think there's any point in doing this...) I think if the class/library is small enough for a single developer to fully understand and verify race conditions can't exist, globals are a very good option. As the code gets larger and more complex, manually verifying race conditions can't exist becomes harder and the argument for one of the more accepted techniques become stronger. -
Unit Testing Error Pass Through
Daklu replied to Chris Davis's topic in Application Design & Architecture
I appreciate the example too. I've been having a little trouble figuring out the best way to organize my tests. In the past I've created a new test case for each unique initial condition of the class I'm testing. For example, if I have a class that has a private refnum I'll have a test case with a valid refnum and another test case with an invalid refnum. I used the setUp method to set the object's initial conditions. I think this is similar to what you described when you referred to 'setting the TestError property in the TestCast.setUp method.' It looks like the preferred breakdown is to use Test Suites to set an object's initial conditions and have a unique Test Case for each sub vi? Previously I had thought of Test Suites as simply a way to enable 'single click' execution of a subset of Test Cases. In the VI Tester Example project (VI Tester Help -> Open Example Project...) the Queue TestCase has a diagram disable structure in the setUp so we can see what the response would be if the queue were not created. Suppose I wanted to test both conditions: valid queue and invalid queue. What would be the best way to set that up in the context of the Example Project? Another thing I have done in the past is enclose the vi under test in a for loop and create an array of different inputs I want to test. I'm pretty sure this violates the idea of 'each unit test should test one thing,' but it is easier than creating a unique test VI for each string input I want to test. I'm wondering how well that technique would carry over in this paradigm. Maybe it would be completely unnecessary...? -
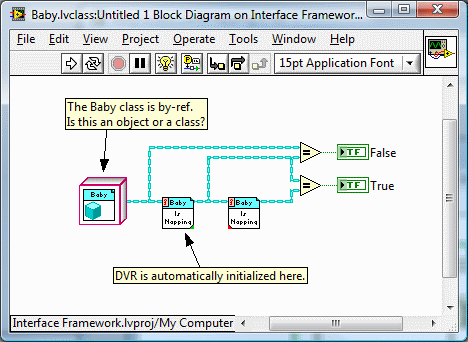
Note the distinction I make in the previous post between a 'by-ref' class and a 'reference' class. Because two different threads had turned into discussions on Create methods and neither thread reflected that subject in the title. I thought it better to create a dedicated thread. True. (Strictly speaking LV doesn't even have variables. Everything is a constant.) However, I wasn't using the term 'constant' to describe the R/W attribute of a piece of data; I was using the term to describe the graphical representation of the data type on the block diagram. There are no cases I'm aware of in LV where you drop a refnum constant on the block diagram and have to send it through an Init method before you can use it.* You have to create them. (Though I believe the preferred LV terminology is obtain.) Yet with LV reference classes that's exactly what you have to do--drop the constant and wire it through your Init method. (*Before you object and point to your snippet as an example of this, I believe opening a reference to an external resource, such as a vi, is a distinctly different operation than creating a reference to a resource that is entirely internal, such as a queue.) Wrapping the class constant and Init functionality in a Create method isn't an adequate solution for several reasons: As The Decisions Behind the Design points out, LV classes do not need creators. They are created as soon as you drop the cube on the block diagram. Requiring a class to be "created" (via the Create method) before it can be used directly contradicts that. There is no way to prevent the user from dropping an reference object cube on the block diagram and attempting to use it directly without sacrificing some of the advantages of OOP. There's not even a way to discourage them from doing so. Wrapping the class in a library and making it private stops users from putting the object cube on the block diagram, but it also prevents users from inheriting from that class. Dropping constants directly on the BD is in fact the normal way to program in Labview. Using creators is abnormal; there are only a few native data types that require them. Having a mix of classes, some of which require creators and some do not, is very inconsistent and non-intuitive. How do you explain to the casual LV user (and non-programmer) why some objects need to be created and some do not--especially when the need for a Create method appears completely arbitrary from the outside? That's the point. An object should behave like an object, not a reference. Any reference class I create starts behaving like a reference instead of an object. If I want my object to behave like a reference, I'll wrap it in a DVR. But I want my reference classes to behave like objects, and there's no way for me to do that. Since in my example I defined that class to be a by-ref class, both equality checks should be true. The only reason it does make sense to you is because I told you when the internal references, which you should not need to worry about, are being initialized. Replace the object cube with a FP control and what will the results be? Unknown, unless you can discover the state of the internal references (you know... those things in the private data) when they are passed into the sample. I'm not saying the current behavior is incorrect. This isn't a bug I'm complaining about. Whether or not the behavior is ususual depends fully on how well you understand references in Labview and how well you know the class' implementation. It does, however, cause behavior that can be very non-intuitive and difficult for class users to comprehend. In my first post I concluded with the statement, "I'm having a hard time figuring out exactly what I'm objecting to." Having thought about it a lot over the past week, I think I hit on the problem with my post from yesterday. The core issue is there's no way for a class developer to properly encapsulate the complexities of references from class users. All the other problems are a result of this. I've been wishing for implicit class initializers for a long time, but a solution might also be found in an automatically initialized queue (and notifier, etc.) control that can be dropped on the class control. I'm sure there are other potential solutions as well.
-
Good intro. I'm really looking forward to the advanced webcast in January. 0:52:55 - Regarding multiple inheritance: "There are some advanced design principles which need multiple inheritance to be implemented. It's generally the case that these are not required in Labview." Followed by Norm's comment: "Saying patterns requireing multiple inheritance just aren't needed is shortsighted" And the comment from the mysterious NI Leader 5 responding to a question at about the same time: "And I am not denying that references are occassionally useful. But in a highly parallel environment like LV they are a signficant source of hard-to-diagnose race conditions and they are a performance hit since LV cannot perform any dataflow optimizations on the data. Many of the programs I have observed where people are -- happily -- using references can be rewritten with little effort to use by value syntax. It just requires a different mindset when designing the program. Rewriting those projects has frequently improved performance substantially." Are there specific examples of typical by-ref designs being converted into a by-val design?
-
Look in the Numeric -> Data Manipulation palette. There are four bit manipulation primitives there: Shift, Rotate, Rotate Right With Carry, and Rotate Left With Carry.
-
That's a more generalized solution -- and more complex -- than what I need. Really all I want to do is check and make sure an InterfaceBag doesn't contain two implementations for the same Interface. I'd prefer to do direct type-checking rather than relying on strings defined by the developer. Since this feature is a check for the interfaceable class designer, not the class user, I'm going to shelve this idea for now. Framework simplicity is more important at this point. Funny you should mention that. I don't know if you've seen my latest update but in the demo I've changed the workings of the interfaceable object's GetInterfaces method. Rather than store the array as private data, I simply dynamically create a new array of concrete Interfaces every time the GetInterfaces method is called. I commented on this here.
-
I responsed here.
-
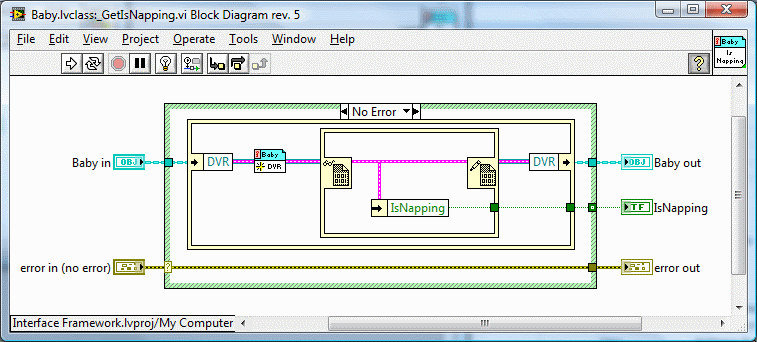
Copied from a different thread I think we're mixing meanings of 'by-ref' object. It sounds like you're referring to a DVR wrapping an entire object. I'm referring to the 'Lava-style' by-ref object developed by SciWare, where the class' private data is wrapped in a DVR. So the answer to your question, IMO, is no. By-ref objects don't, and shouldn't, behave like references. They should behave like objects. The question that then needs to be answered is, how should objects behave? I'm sure AQ and his team have answers for this but here's my take on it: In general, a class user can expect one of three kinds of behaviors from a class. These are the things the user needs to know about the class to use it correctly. By-val. Any branch or independent data source creates a new object. By-ref. Branching creates a reference to the original object. Independent data sources create new objects. Singleton. Any branch or independent data source refers to the same object. You can also categorize classes based on how they are implemented. The user should not have to know these details to use the class correctly. Reference class. A class that contains a resource that must be initialized at run-time. Non-reference class. Does not contain resources that must be initialized at run-time. Part of the problem as I see it is the class user needs to know implementation details to know how to use the object with respect to Init methods. The only thing the class user can be sure of is that a by-ref object must be initialized before it can be used.* Does a by-val class need to be initialized? Maybe... depends on how it was implemented. Does a singleton need to be initialized? Maybe... depends on how it was implemented. What happens if I branch either of those objects before initializing it? Dunno... depends on the implementation--does the Init method actually initialize something or is it an empty wrapper? Requiring the user to know all these details clearly violates encapsulation. (*Most of the time... sometimes it will work just fine.) My frustration mainly stems from the inability to adequately hide the complexities of references from the class user. They not only need to know that the class uses references, they must also be aware of the state of the internal refnums; is it valid or is it 0? I've experimented with implicitly initializating run-time resources in class methods on an as-needed basis, but it turns out this is not a very good solution. It often leads to results that are inconsistent with the class' expected behavior. Also consider the situation where I have deployed a non-reference class but for some reason or another an update requires adding an internal refnum. Even if nothing in the public api has changed, I've just broken backwards compatibility and have to go back to every application that uses that class and add Init methods. This should not be necessary. The static dispatch create method described by Tomi here addresses the issues with dynamic dispatching I outlined in my previous post and is the best solution to that particular problem I have seen so far. But it does not address the fundamental problem that object cubes can still be placed on the block diagram in a "nonfunctional" state and manipulating object cubes directly on the block diagram is a natural way to work with them. The same is not true for refnum constants.
-
Probe Watch Window usability issue
Daklu replied to PJM_labview's topic in Development Environment (IDE)
FWIW I'll jump in and say I like the new probe window. I think it can use a few tweaks to improve it but I find it much easier to deal with. -
I believe the work around it to use a factory method. A factory method would be a vi not in the class that passes out an object based on string or enum input. The user will have to downcast to the specific object requested to use any methods not exposed by the common parent. If you have complete control over the entire class tree you can include the factory method when distributing the class without too much trouble. If you expect users to extend your class tree, they'll have to create their own factory method that wraps yours and add their classes to it. Obviously they'll need to rename their factory method, or wrap it in a library, or wrap yours in a library.
-
LOL! Gratz Jim!
-
Enjoying it as in, "Hey look at the goofy circus clown who can't figure out how to do reference classes?" The Create method discussion continues here.
-
Thanks Tomi! I'll have to play around with that and see how well it works in my situation. The Create method discussion continues here.
-
This thread is a continuation of the two discussions of using Create methods for reference classes here and here. Yeah, I've thought about that. The difference is that there's almost* no reason to put a queue constant or file I/O constant on a block diagram and when you do there's a clear indication via the dog-eared corner that you are dealing with a reference. There are valid reasons to put a by-ref object cube on the block diagram (upcasting and downcasting for example) and when you do, it looks exactly like a by-val object. (*The one corner case I can think of is if you need to wire it into a bundle prim as a place holder.) Nope. Static VI references are configured at design time. TCPIP, UDP, Bluetooth, and IRDA constants can't be initializied at run-time. You have to create a new one. (I don't have IMAQ installed so I can't check it.) Same with queues and notifiers. Functionally, those constants (minus the Static VI Ref) on a block diagram are only useful for their type information. There are no prims you can wire through that magically convert it into a valid refnum. Contrast that with a by-ref object constant. It's useful only for it's type information** unless you wire through its Init method, which magically converts it into a fully functioning object. (**Depending on how it's written, certain methods may be functional before creating the internal DVR; however, I think this confusion only compounds the problem.) Certainly using a Create method (class output only) rather than an Init method (class input and output) works in some situations. But it's not always a viable solution. Suppose I have a reusable by-ref class that is intended to act as a parent for other developers to extend for their own purposes. They'll need to have their own Create method to initialize the parent object, but they can't do dynamic dispatching on the parent's Create method because there's no class input. Work arounds, such as making the Create method external to the class and wrapping it all in a library to take advantage of namespacing, are bulky and cumbersome. Furthermore, sometimes developers do their LOOP work primarily out of the project window rather than from the palette. There's no way I'll drag a queue constant from the project window onto the block diagram and then wonder why it's behaving oddly. That can very easily happen with by-ref classes. I know I'm kind of all over the place with this discussion. I'm having a hard time figuring out exactly what I'm objecting to. I've just had a long-running sense that using objects with references introduces a lot of inconsistencies in the user experience (which leads to confusion for new users) and that it could be so much simpler.
-
"Fructarted?" That's my new favorite word! Neither really. The idea of a Create method doesn't bother me, but the requirement of using a Create or Init method on an object constant that looks like it should work fine without one does bother me. More details can be found here.
-
Yeah, I understand it's not really 'smart' and the behavior is just a side effect of the way LV stores references and the by-val nature of testing for equality. No, I don't expect it to behave that way. Before now I hadn't really given it much thought as I never had to do object comparisons, but the behavior does make sense to those well-versed in how LV works. I do wish it were possible to create auto-initializing classes (without crippling other basic class capabilities by wrapping it all in a library and making it private.) Part of my job is figuring out APIs for various internal reusable components. The long-term goal is to create APIs that are easy enough for new(ish) Labview users to understand, so they have the tools to quickly put together simple test scenarios. I've been struggling with a way to encapsulate the complexity and present a uniform experience to the user. Reference classes (by which I mean classes that contain any refnum that must be initialized at run-time) are necessary for lots of advanced behavior, but it is difficult to wrap them in a package that is intuitive to use. I submit that the only reason it seems perfectly normal to you is because I revealed information about the implementation. Specifically, I explained that it is a by-ref object and told you where the DVR initialization was taking place. Had I presented it as a normal by-val object the results would not have made any sense whatsoever. I think that's part of the problem... By-val classes and by-ref classes are fundamentally different beasts, with different behaviors across a wide range of operations, yet to the average user they look identical (subject to the class designer's icon making skills) and at design-time they behave identically. By-ref object cubes on the BD aren't really "objects" in the sense that they are ready to be used. They behave more like a traditional class definition--the user still has to "create" (i.e. initialize) the object before it can be used. Are there any other BD constants in Labview that have to be initialized at run time before you can use them? (Honest question... I can't think of any off the top of my head.) ------------------- [Note - I didn't start this thread with the intent of bridging even a little bit into the topic of constructors auto-initializing classes. Yet the more I work with reference classes the more uneasy I become with the toolset we have for managing them. I have this nagging voice in the back of my head telling me that it could be much simpler. (Maybe it's Evil AQ again... )]
-
No worries, we all are. A string-based tag works if you have control over the entire hierarchy. In my case I don't. Users can create their own Parent classes and give them whatever name they want. In your example perhaps your Serial Anemometer class is from manufacturer A, but I create a Serial Anemometer class for devices from manufacturer B. My plug-ins and your plug-ins will be tested as siblings, even though they are not. (Besides, I hate Init methods. )
-
I hope you have the requisite pictures of it hanging in your cube. ------------------ I did discover a gotcha while goofing around with it last night. By-ref objects need to initialize the DVR before the object can be used. Comparing a pre-initialized by-ref object with a post-initialized by-ref object returns False. Again, it makes sense if you think it through; however, I think it is counter-intuitive and it requires fairly deep Labview knowledge and under-the-hood understanding for it to make sense. The rule-of-thumb for by-val objects is "branching always makes a copy." (We know that's not always true, but it's a useful way to explain the behavior to new users.) The rule-of-thumb for by-ref objects is "branching always refers to the same object." Now we have to throw in the caveat, "unless you haven't initialized your by-ref object." It's as if by-ref object constants on the block diagram aren't objects at all, but are classes instead. Before LV'09 you couldn't put classes on a VI--only objects. Now you can, and they look suspiciously like objects. It can be particularly perplexing for class users if, like me, you try to simplify the class by initializing the DVR at runtime on an as-needed basis. In those cases, simply reading a property will lead to unexpected results for the new LOOPer.