Leaderboard




Popular Content
Showing content with the highest reputation on 06/10/2024 in all areas
-
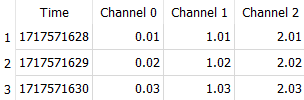
A non-JSON option you could try is: CREATE TABLE TestData ( Channel, Time, Data, -- individual reading at Time for Channel PRIMARY KEY (Channel,Time) ) WITHOUT ROWID This is every reading sorted by a Primary Key that is Channel+Time. This makes looking up a specific channel in a specific Time Range fast. BTW, you don't need to make an index on a Primary Key; there is already an implicit index . You would select using something like: SELECT (Time/60)*60, Avg(Data) FROM TestData WHERE Channel=? AND TIME BETWEEN ? AND 1717606846 GROUP BY Time/601 point
-
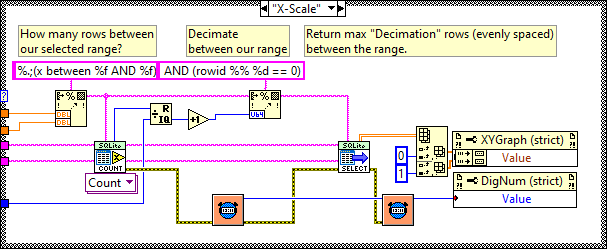
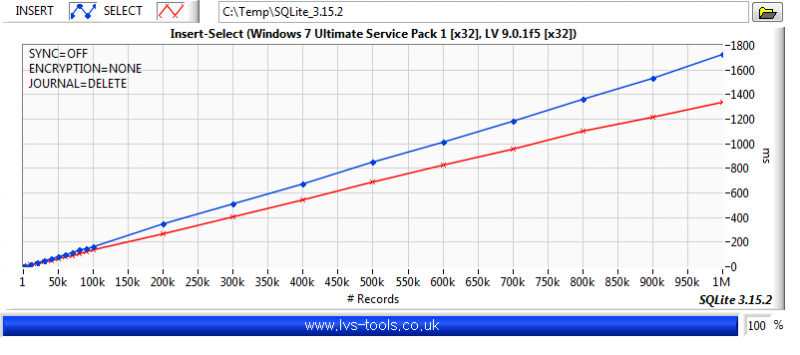
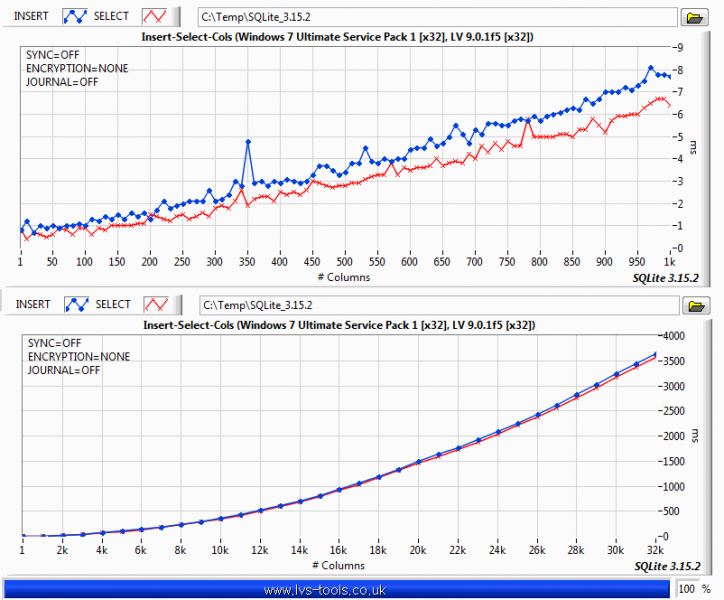
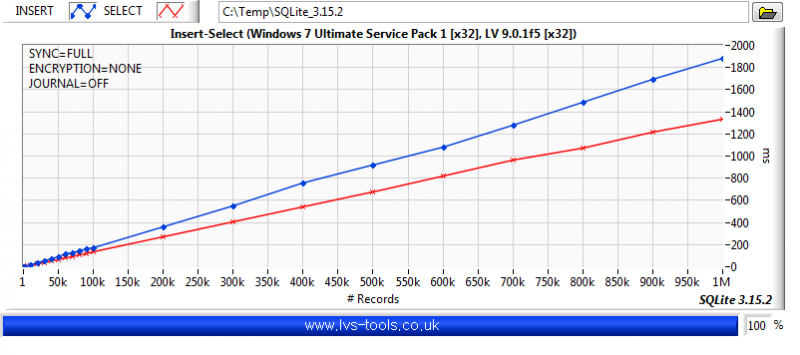
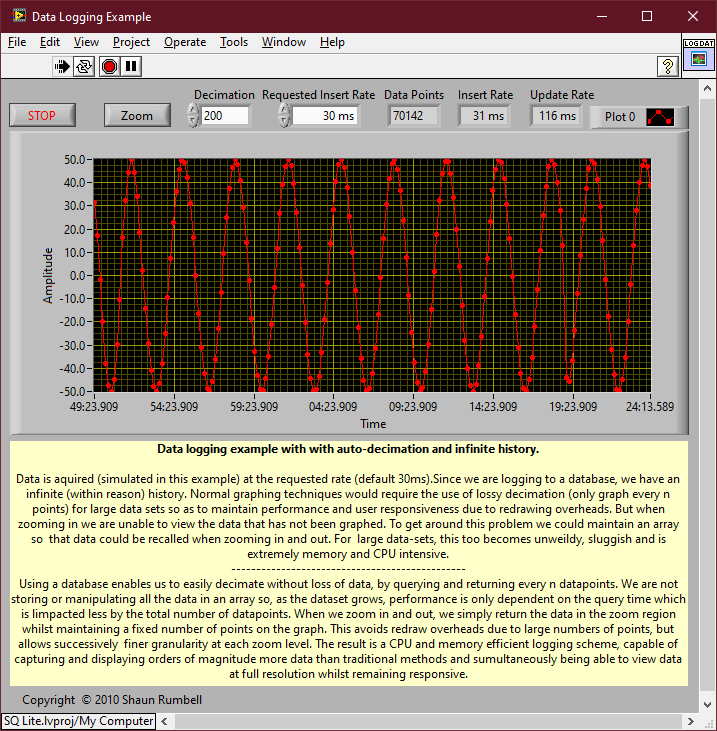
You want a table per channel. If you want to decimate, then use something like (rowid %% %d == 0) where %d is the decimation number of points. The graph display will do bilinear averaging if it's more than the number of pixels it can show so don't bother with that unless you want a specific type of post analysis. Be aware of aliasing though. The above is a section of code from the following example. You are basically doing a variation of it. It selects a range and displays Decimation number of points from that range but range selection is obtained by zooming on the graph rather than a slider. The query update rate is approximately 100ms and it doesn't change much for even a few million data points in the DB. It was a few versions ago but I did do some benchmarking of SQLite. So to give you some idea of what effects performance:
 1 point
1 point -
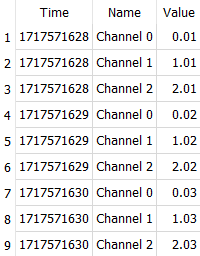
It probably selects all elements before it applies the filter. You can get more insights with the EXPLAIN query: EXPLAIN (sqlite.org) Without the database its difficult to verify the behavior myself. It may be more efficient to query channels from a table than from JSON, especially when the channel names are indexed. That way, SQLite can optimize queries more efficiently. Find attached an example for a database to store each data point individually. Here is a query that will give you all data points for all time stamps: SELECT TimeSeries.Time, Channel.Name, ChannelData.Value FROM TimeSeries INNER JOIN TimeSeriesChannelData ON TimeSeries.Id == TimeSeriesChannelData.TimeSeriesId INNER JOIN ChannelData ON TimeSeriesChannelData.ChannelDataId == ChannelData.Id INNER JOIN Channel ON ChannelData.ChannelId == Channel.Id You can also transpose the table to get channels as columns. Unfortunately, SQLite does not have a built-in function for this so the names are hard-coded (not viable if channel names are dynamic): SELECT TimeSeries.Time, MAX(CASE WHEN Channel.Name = 'Channel 0' THEN ChannelData.Value END) AS 'Channel 0', MAX(CASE WHEN Channel.Name = 'Channel 1' THEN ChannelData.Value END) AS 'Channel 1', MAX(CASE WHEN Channel.Name = 'Channel 2' THEN ChannelData.Value END) AS 'Channel 2' FROM TimeSeries INNER JOIN TimeSeriesChannelData ON TimeSeries.Id == TimeSeriesChannelData.TimeSeriesId INNER JOIN ChannelData ON TimeSeriesChannelData.ChannelDataId == ChannelData.Id INNER JOIN Channel ON ChannelData.ChannelId == Channel.Id GROUP BY TimeSeries.Time If query performance is important, you could perform the down sampling in the producer instead of the consumer (down sample as new data arrives). In this case you trade storage size with query performance. Whichever is more important to you. Probably in a database 🤣 Seriously, though, these kinds of data are stored an processed in large computing facilities that have enough computing power to serve data in a fraction of what a normal computer can do. They probably also use different database systems than SQLite, some of which may be better suited to these kinds of queries. I have seen applications for large time series data on MongoDB, for example. As computing power is limited, it is all about "appearing as if it was very fast". As mentioned before, you can pre-process your data so that the data is readily available. This, of course, requires additional storage space and only works if you know how the data is used. In your case, you could pre-process the data to provide it in chunks of 2000 data points for display on the graph. Store it next to the raw data and have it readily available. There may be ways to optimize your implementation but there is no magic bullet that will make your computer magically compute large datasets in split-seconds on-demand (unless you have the necessary computing power, in which case the magic bullet is called "money"). dbtest.db.sql
1 point
-
We could allocate/resize the array but it is highly complicated. There are two basic possibilities: 1) Using NumericArrayResize() is possible but you need to calculate the byte size yourself. With complex datatypes (clusters) the actual byte size can depend on the bitness of your compilation and contain extra alignment (filler) bytes for non Windows 32-bit compilation. Really gets complicated, but the advantage is that it is at least documented. 2) There is an undocumented SetArraySize() function. It can work for arbitrary array elements including clusters and accounts for the platform specific alignment but is tricky since the datatype description for the array element is a LabVIEW type-descriptor. To get that right is pretty much as complicated as trying to calculate the array element size yourself and as it is undocumented you risk that something might suddenly change. The declaration for that function is: TH_REENTRANT MgErr _FUNCC SetArraySize(int16 **tdp, int32 off, int32 dims, UHandle *p, int32 size); tdp is the 16-bit LabVIEW type descriptor for the array element data type. This is basically the same thing that you get from Flatten Variant but you want to normally make sure that it does not contain any element labels as it does not need them and only makes the parsing slower. off is usually 0 as it allows to specify an offset into a more complex tdp array. The other parameters are exactly the same as for NumericArrayResize(). In fact NumericArrayResize() is a thin wrapper around this function that uses predefined tdp's depending on the first parameter of it.1 point