

mje
-
Posts
1,068 -
Joined
-
Last visited
-
Days Won
48
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by mje
-
-
Hah, yes, of course I meant occurrences. Doh.
-
I'd hazard a guess that notifiers aren't recommended due to their behavior being different than the other sync objects. The behavior is a little odd, but once understood they are perfectly usable.
-
I'd probably throw in a release primitive in there for good practice, but otherwise all good I'd say.
-
 1
1
-
-
Well I never learned that leason so being the fool that I am I went off and started pushing evnts down into the sub-VI that handle each of the modes the app runs in. I will not multiply words but I will invite you to examine the images I uploaded to the Dark-side that can be found here.
This approach lets me develop sub-VI that are clean and focused on only the events that apply to the current operating mode as shown here.
Indeed, I do the same. My only real rule is to "never" pass event registration refnums to subVIs due to the static typing. The event registration always stays in the VI that has the event structure using the registration, but I impose no restriction on where these are relative to the actual event source(s).
-
1
-
-
I would use a SEQ in a way that mirrors a DVR: never use Preview Queue and always dequeue before enqueue. This way the queue provides its own locking mechanism, no need for a separate lock.
Quite true, the whole point of the SEQ/DVR is to provide a locking mechanism such that you don't need a secondary semaphore or similar object. When you dequeue the SEQ element or enter an IPE with a DVR, it becomes impossible for any other task to get a value from it until you enqueue a new value or exit the IPE.
However using the preview primitive is still normal in many situations when using an SEQ implementation. Consider having multiple views which must render the data in a common SEQ. The views likely have no interest in modifying the value, so they could just as easily use a preview to get their own local copy to do what they want with, there is no need for an explicit check out/in. I do this all of the time in my code, however I don't use SEQs anymore (moved exclusively to Object DVRs). What I often end up doing is signalling my views to update themselves with new data from some model, and the view will then pull off all the data it needs from the model via a single property node, generating a local copy of the data for it to use. Of course this isn't always the way it works, for example when a copy would be prohibitive from a memory stand point, but that brings up a whole other can of worms involving data models and what not.
I would use a SEQ in a way that mirrors a DVR: never use Preview Queue and always dequeue before enqueue. This way the queue provides its own locking mechanism, no need for a separate lock.
Quite true, the whole point of the SEQ/DVR is to provide a locking mechanism such that you don't need a secondary semaphore or similar object. When you dequeue the SEQ element or enter an IPE with a DVR, it becomes impossible for any other task to get a value from it until you enqueue a new value or exit the IPE.
However using the preview primitive is still normal in many situations when using an SEQ implementation. Consider having multiple views which must render the data in a common SEQ. The views likely have no interest in modifying the value, so they could just as easily use a preview to get their own local copy to do what they want with, there is no need for an explicit check out/in. I do this all of the time in my code, however I
I would use a SEQ in a way that mirrors a DVR: never use Preview Queue and always dequeue before enqueue. This way the queue provides its own locking mechanism, no need for a separate lock.
Quite true, the whole point of the SEQ/DVR is to provide a locking mechanism such that you don't need a secondary semaphore or similar object. When you dequeue the SEQ element or enter an IPE with a DVR, it becomes impossible for any other task to get a value from it until you enqueue a new value or exit the IPE.
However using the preview primitive is still normal in many situations when using an SEQ implementation. Consider having multiple views which must render the data in a common SEQ. The views likely have no interest in modifying the value, so they could just as easily use a preview to get their own local copy to do what they want with, there is no need for an explicit check out/in. I do this all of the time in my code, however I
<p style="font-family: 'Helvetica Neue', Arial, Verdana, sans-serif; font-size: 14px; color: rgb(34, 34, 34); background-color: rgb(255, 255, 255); ">
I would use a SEQ in a way that mirrors a DVR: never use Preview Queue and always dequeue before enqueue. This way the queue provides its own locking mechanism, no need for a separate lock.
Quite true, the whole point of the SEQ/DVR is to provide a locking mechanism such that you don't need a secondary semaphore or similar object. When you dequeue the SEQ element or enter an IPE with a DVR, it becomes impossible for any other task to get a value from it until you enqueue a new value or exit the IPE.
However using the preview primitive is still normal in many situations when using an SEQ implementation. Consider having multiple views which must render the data in a common SEQ. The views likel
-
I'm thinking out loud here. The last application I built has been out in the wild now for about 6 months, and some users are running into limits imposed by 32-bit memory space.
I've updated my code (mostly LabVIEW with a tiny amount of C++), plopped all my DLL calls in conditional disable structures that depend on the target bitness, and can now successfully load and execute the application in both 32-bit and 64-bit versions LabVIEW IDE. If all goes well tonight, when I run the builds I'll have a pair of installers in the morning.
I'm assuming there's no easy (that is native LabVIEW) way of creating a unified installer that will just plop the right version on the user's computer?
My strategy I suppose is to create a separate setup32.exe and setup64.exe, and then have a basic (32-bit) setup.exe check the bitness of the operating system before proceeding to execute the appropriate "real" installer. Or is there some automagical way of doing this in a build spec?
-m
-
There's an impressive amount of information in that presentation. How long are your meetings by chance?
-
Is that what the checkmark does? I couldn't figure out what I was doing by taping it...
Don't mind my ramblings about file interface. I should learn not to make any posts after midnight.

-
I have often wanted similar features to Jim, or mainly some way to perform type reflection at runtime so as not to violate the very important encapsulation. This would allow for some very powerful serialization methods to be (dynamically) defined. I would also love to explore the possibility of late binding should such a system ever exist, but that's a whole other can of worms...
JG's idea is interesting though, as it still allows automatic serialization via the anonymous cluster. I like it! Extra kudos for the serialization method itself, if it's dynamic each level in the hierarchy gets a crack at serializing. Even more kudos for abstraction the file interface!
Edit: I misread part of your last post, doesn't look like there is an abstracted file interface. What can I say, it's late and I'm tired. Also appears not to be a way to "like" a post from the mobile version of the site. /sadface
-
Cryptography is nice, but also implies some levels if security that are used when handling data passed to the methods which most definitely can't be satisfied in G code. I'd say encryption or even simply hashing is a more honest description.
-
What? Who? But..
Not sure what to say. Part of me is so happy the ability is there. Part of me is annoyed that after over a decade of programming LabVIEW GUIs I never stumbled across that little subtlety. I...just...
Thank you for pointing that out!
-
-
LabVIEW has no notion of a click, let alone a double click. In the past I've handled this with a combination of mouse down/up events. Mouse down records a timestamp and location. Mouse up then checks to see if the location is the same (possibly allowing for some drift) and if it's within a threshold time, registers a click. For a double click, you'd have to add just do this twice.
Yes, I know it's hard to believe that in 2011, LabVIEW still has no idea what a "click" is.
-
In most cases the application builder will be able to determine you need the DLL, and in your case it looks like it has done just that, you shouldn't need to do anything else.
I'm sorry, but without a more specific error message I can't offer any more advice, the DLL was just a guess!
-
Was lvanlys.dll packaged properly with your executable? The library that mean.vi is a part of requires that dll. Is there any more details about the error message?
-
That's my interpretation, which left me wondering why it even is a pattern. To me it's no different than creating a sub VI that manages several calls to other VIs, whether we are talking about objects or not.
I always figured there was some magical subtlety I was missing that made the pattern worthy of a special name. I guess not?
-
Heh, I'm even interested in an intelligible example of the facade pattern in *any* language. I find the chapter in Gamma et a less than enlightening.
-
I haven't tried reproducing the behavior you describe, but it sounds a lot like something I posted earlier relating to the tree controls. If it is fixed in LV2011, that's good news.
In the past, behavior such as this has made me loathe using LabVIEW list/tree/table controls in any system style UI.
-
For what it's worth, attached is a zip containing three Create GUID implementations consistent with IETF RFC-4122:
Version 1: Timestamp
Version 3: MD5
Version 4: Random
The V3 implementation requires the OpenG MD5 library. Also included is a VI that generates a 100 ns base timestamp (used in the V1 implementation, actually works as advertised now), along with a typedef that is used in the implementations.
There is no V5 VI, I haven't tracked down the SHA-1 library you have been talking about, but it should be trivial to modify the existing V3 VI (replace the checksum call with a SHA-1 and modify the version bitmask) if it doesn't already have the functionality you describe.
If there's interest in having the Is A GUID method perform a basic timestamp validation for V1 GUIDs, I can throw some code together.
-m
-
1
-
-
Urgh. I just realized the epoch on the RFC is 00:00:00.00, 15 Oct 1582. Please ignore the timestamp version of the GUID generator, it is not accurate until I fix the epoch (along with a precision bug).
-
LabVIEW is so not self-documenting. I know I had a reason for using the time and IP address in my VI.
There is precident in the document. Version 1 of the GUID uses a timestamp to help reduce the probability of collisions. In this case though, the prospect of a "valid" GUID comes up, in that it can never contain a timestamp in the future. This version though typically uses the 48-bit MAC address, not the IP.
I've updated the VI I wrote to generate GUIDs. It now supports version 1 (timestamp) and version 4 (random). I'll look into adding support for version 3 (MD5) on the weekend if there's interest. Maybe even version 5 (SHA-1), though I don't think we have access to a platform neutral SHA-1 algorithm in LabVIEW?
Also note in the version 1 implementation, I created a multicast MAC address out of thin air. I don't believe there's a cross-platform way of getting the MAC from LabVIEW, correct? Regardless by setting the address to multicast, the random number should never collide with a real NIC's MAC as the RFC recommends.
The files are now in a zip because in addition to Create GUID.vi, there's also a new VI to create properly resolved timestamps, and a GUID typedef.
I also apologize for for derailing this review. I just think that if you're going to have an Is GUID.vi, it should be consistent with whatever means you have of generating said GUID since there is no standard adopted for formatting.
I'll also pose the question of do we want the Is GUID.vi to validate version 1 GUIDs, insomuch as it would return false if the timestamp is in the future?
-
1
-
-
I would recommend the FG over the global if you are going to access the value frequently...
Yes, frequency of access is a normal situation where I force a FG over a real global. When I say FG, it's not really accurate since there is never a write operation. Essentially they're just VIs acting as constants as others have implied.
If it's a value that never changes and you don't load, a VI with a constant in it could be set to inline, thus providing the same (similar?) overhead as a constant with the benefit of changing the value one place.
Brilliant, I never thought about inlining. This is infact exactly what was missing from my usage, it never occurred to me to apply inlining to these VIs.
I am down with Tim_S here, IMO that's a perfect use case for Global Variables - why? because anything else (FGV, MAPs) seems like much too hard work.
Indeed, globals are just SO EASY. But I dislike doing that because you never know when one of these VIs will end up in a tight loop once your code gets refactored for the umpteenth time.
-
I was wondering how each of you handle named constants in LabVIEW. Basically these are values that never change during execution, but I might want to edit their value in the IDE. The C equivalent would be a #define statement in a .h file if we were talking about global scope.
I've taken to using LV2 globals (or if I'm really lazy, a normal global), but there's of course overhead in both cases since there's some kind of referencing going on relative to a static constant.
Lookup tables are another possibility, but then the overhead is even larger because in addition to the referencing to another VI to do the lookup, you have the actual lookup logic to contend with. Too much for a constant value if you ask me.
I've often thought about using literal constants on the diagram, where the labels are decorated with special tags I can search for, but I have no experience in how maintainable code like that is. Changing the type of a named constant would seem particularly prone to errors in code. Anyone ever attempt this?
It would be really nice if in addition to {Control, Typedef, Strict Typedef} ctl files, we were also able to define a Constant which would not allow the value to be mutated outside of editing the actual *.ctl (might have to put that one in the idea exchange). But that one's more of pipe dream, how have you handled named constants historically?
-
Just from quickly browsing the doc, is that was jcarmody has done (or similar) in his screenshot?
I don't believe so. By my reading, a pseudo-random GUID conforming VI would follow the logic in section 4.4. Given the following syntax:
typedef struct { unsigned32 time_low; unsigned16 time_mid; unsigned16 time_hi_and_version; unsigned8 clock_seq_hi_and_reserved; unsigned8 clock_seq_low; byte node[6];} uuid_t;4.4. Algorithms for Creating a UUID from Truly Random or Pseudo-Random Numbers
The version 4 UUID is meant for generating UUIDs from truly-random or pseudo-random numbers.
The algorithm is as follows:
- Set the two most significant bits (bits 6 and 7) of the clock_seq_hi_and_reserved to zero and one, respectively.
- Set the four most significant bits (bits 12 through 15) of the time_hi_and_version field to the 4-bit version number from Section 4.1.3.
- Set all the other bits to randomly (or pseudo-randomly) chosen values.
So something like this (all optimization aside):
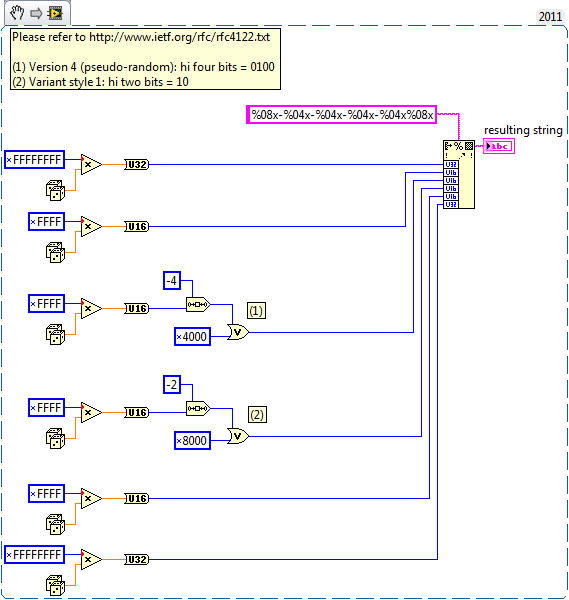
Also of note:
Validation mechanism:
Apart from determining whether the timestamp portion of the UUID is in the future and therefore not yet assignable, there is no mechanism for determining whether a UUID is 'valid'.
-
1
- Set the two most significant bits (bits 6 and 7) of the clock_seq_hi_and_reserved to zero and one, respectively.
Profile Performance and Memory - Inaccurate Numbers
in LabVIEW Bugs
Posted
Any of you ever see something like this?
I'm trying to pinpoint a bottleneck in a new process I wrote, but I'm seriously questioning the results here...
The numbers for those four VIs do not change over the lifetime of an execution, or if I execute the application multiple times within the same instance of the IDE. If the IDE is restarted, some of the VIs will return the same numbers, others not so much.
Also, some of the more reasonable looking large numbers, like the VI which has reportedly been executing for 179 seconds are definitely wrong, as the application had been running for less than a minute.
Some clues as to what might be going on:
Maybe this is old news with timing reentrant/async methods, or is there something else afoot?
-m