asbo
-
Posts
1,256 -
Joined
-
Last visited
-
Days Won
29
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by asbo
-
More fundamentally, you might want to add some code to profile intensive sections of the software. You don't include any information to its specific function, so I can't recommend anything to you off-hand. You should have intimate knowledge of what your process will be doing at the times when you're grabbing these figures, so analyzing those routines should tell you what some potential sources might be. I wouldn't really expect the change in CPU usage you see between versions, but it could be that some nodes/VIs you're depending on have changed, so reviewing your code (especially when jumped 3.5 major versions) would be prudent. One thing to do would be swap back to source code and use the built-in profiler to see which VIs are racking up the most clock time. (Dan already suggested this)
-
As long as you use exactly the same name to obtain the notifier, it's the same notifier regardless of which VI obtains it. Unless you pass the notifier refnum around, though, there's no way to only obtain it in one place. For every time you obtain the notifier, you should release it; LabVIEW maintains an internal counter of how many times it has been opened/closed and only when that counter reaches zero can those resources be freed.
-
Really? Those slender, typecasting hips didn't clue you in?
-

OPC Server Permission Restriction
asbo replied to SearchingforAnswers's topic in Remote Control, Monitoring and the Internet
Is your traffic brokered through LabVIEW? I'm not sure I see how this relates to LabVIEW. I would expect this would be a configuration option of the RSLinx software. -
Oh, this is perfect, I've been needing to write one of these for a while. Thanks!
-
Whether it's worth the effort to change over, I can't say, but it would certainly be a more apt solution. I can imagine how frustrating it is to get support requests like that.. it'd be like me swapping some hoses around in the engine bay, bringing it back to the dealership, and saying, "Hey, your thing broke."
-
Can you expand on this? I'm not making the connection as to why it would be easier. For me, it's never about not trusting code I can't read - all of us do that all the time, it's practically unavoidable. It's more about knowing that there's something I could read and there's just one password between me and it.
-
The problem with comparing your two memory scenarios is that we really have no idea how it handles each. It's easy to theorize what it should be doing and convince ourselves what it's probably doing, but that's not always the case. Usually, it does make more sense to just test it out and see what happens. One consideration is that the memory might be held by whatever library is used for TDMS. I assume you're flushing/closing your file correctly, but the reason it persists after closing the specific VI is that the memory is not used by a LabVIEW data structure, but one from the TDMS library. As for your attachment, I've had very good luck in the past compressing TDMS files, but I don't remember if this board allows files with a .zip extension. It might be more advantageous to see your test case, anyway.
-
Remember that LV does its own memory management under the hood. In general, it is lazy about freeing large chunks of memory it has already allocated from the system. Unless the subVIs run simultaneously, I would expect the memory block to be re-used amongst them, unless there is a significant amount of data that is being passed out which would justify to keeping the allocation. In that case, it just means you don't have enough memory for what you're trying to do (or alternatively that there may be a more efficient way). There is a "Request Deallocation" node you can try, but I don't tend to put much stock in it. Said another way, I trust LV to handle its own memory. Based on your phrasing, though, this seems like a premature optimization - write a test case you think might cause out-of-memory issues and see if it actually happens.
-
Then you'd need to find out if a type cast and mask are faster than logical comparisons. Depends on how much overhead there is in the LabVIEW operators for NaN but hopefully it's pretty ideal.
-
I agree. However, I'd like to spend a few minutes and see if they benchmark differently. I fully expect the compiler to be smart enough to reduce mine.
-
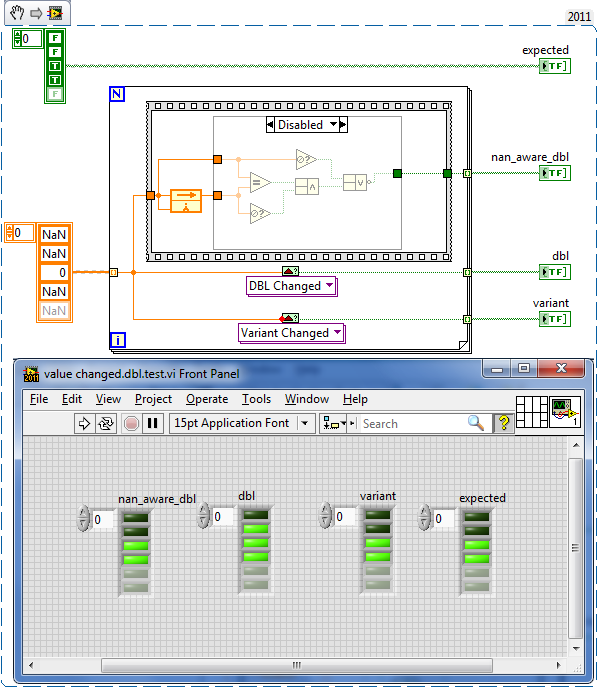
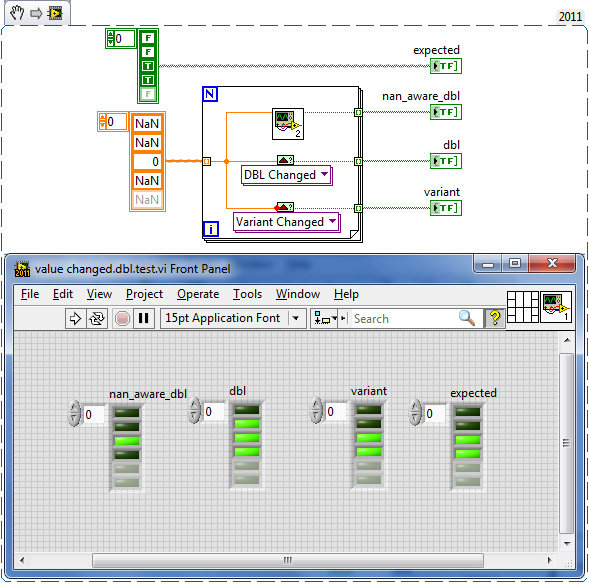
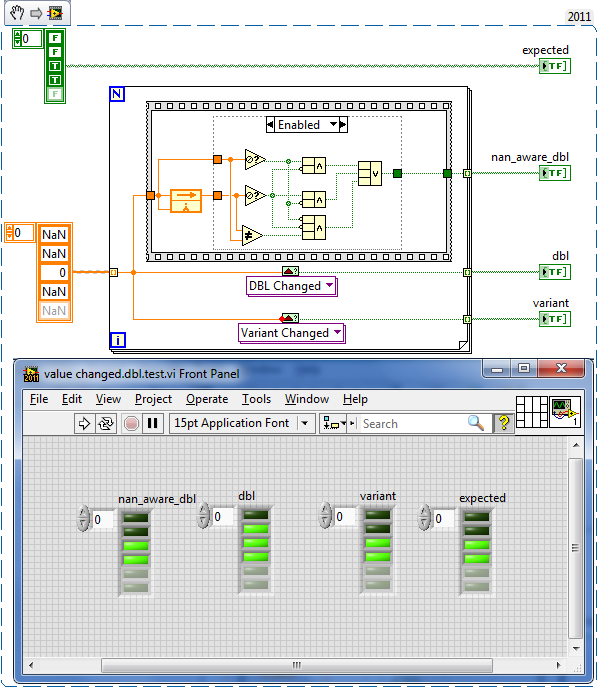
It's in the opposite case of the diagram disable structure, so: The answer is that I wired the "value" input's "Not a Number?" node to the NOR instead of the AND. Alas...

-
And my public smear campaign is foiled... I mentioned above, I used his snippet (which didn't include the subVI), so I probably didn't wire it up correctly. Sorry I couldn't be a poster boy, AQ
-
Using your VI (sorta, I had to rewrite it), I changed the test case, I think the new implementation VI misses (non-NaN) -> (NaN). I took a couple minutes to play with it, and think this covers each of the possible transition cases.
-
In the past, we have been known to use cDAQ chassis of both the USB and Ethernet variety, and I expect that's how we would use these modules. Are you primarily targeting the cRIO platform?
-
So tweak the VI and post a fixed version for inclusion All it should take is a couple of "Not A Number/Path/Refnum?" nodes in the DBL instances and you're set.
-
Thanks for posting this up. I don't need it at the moment, but it sounds like it'd be interesting to play with. It would probably be small potatoes to add a supervisory bit of code to make the timeout behave in LabVIEW terms.
-
Are there any plans for IVI or NISE support for the WF-3132 module?
-
Just as trivia, LabVIEW does not differentiate quiet NaNs - I remember finding this out after parsing a dataset which did require differentiation.
-
I would bet dollars to donuts that those are the functions employed by the PP'd VI and one of them is throwing the exception. Based on rolf's input, I would probably expect that there won't be much you can do about it while using only a pixmap.
-
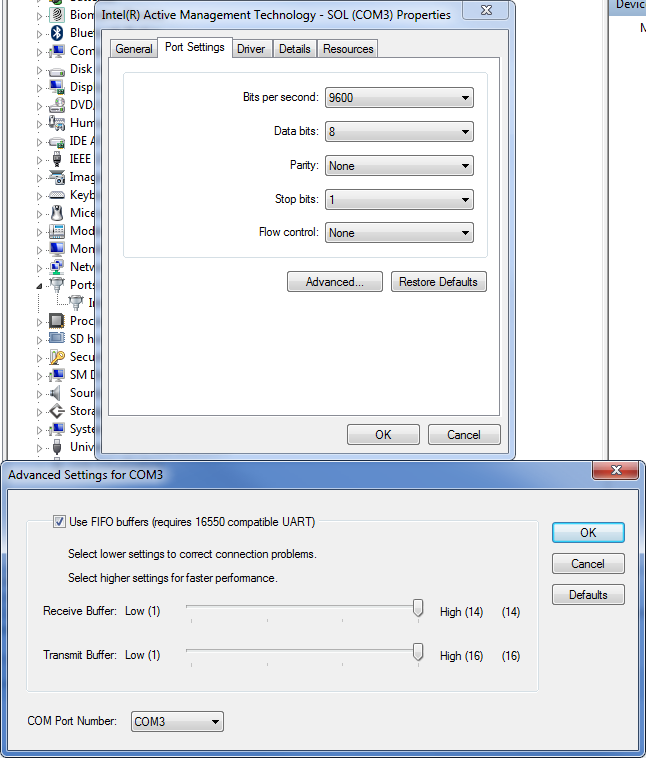
Ahh, I recognize that panel. I have a FTDI RS232-3V3 adapter and I was a little slack-jawed at how much stuff you can tweak, especially compared to my built-in one.
-
What API calls do you think are relevant? Rather than messing with that, is it possible to put your devices on separate buses and use individual COM ports? That would give you some parallelism which may combat the constant time delay. The unfortunate fact is that even if you could bump up to 150k baud or higher, you're still only picking at < 20% of your overall iteration duration.
-
Cool, that's kind of what I was expecting to see (though the 30ms I mentioned obviously includes the write duration as well, oops). The obvious approach is to increase the devices' baud rate, but if it were so easy, I suspect you would not be posting. To follow up on what Todd said, some (most? all? few?) COM ports have some hardware/buffer settings you can dink with. Check out the attached, maybe your COM port is mal-adjusted.
-
If you add a 30ms delay between read and write and then time across the VISA read, you should be able to measure the latency of the read call itself, as all the data will already be at the port. Alternatively, use the read node in a loop, reading only one byte per iteration. This should allow you to see how long it takes to read each byte.
-
You mean I have to read entire posts in order to understand people? The Internet is ridiculous.