ShaunR
-
Posts
5,033 -
Joined
-
Days Won
313
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by ShaunR
-
Oh. On this point. I'm currently struggling with the "dirty vi" propblem. If I set the state to changed, the VI it's used in wants to be saved (even though nothing has changed). If I don't set the state, the control won't update the facade.I can live withthe dirty VI but "Level where general public would find it useful" is just out of reach.
-
I don't think it matters. If it's a package that comes with LabVIEW, you can choose to use it or not.
-
A hooovahh said. They do but it's really only a wizard that takes the grunt work out of creating the properties and methods yourself (something xControls could have done and probably still could do). I think rather than thinking as it being an alternative. Think of it as a run-time only package. There are no edit time capabilities and it isn't encapsulated like an xcontrol. It would have been useful for my Markup String xControl if a little unweildy for the end user (they would have had to have init and deinit Vis and an event structure instead of just placing a control). But It wouldn't have been much use for my Tab Control as that needs edit time capabilities and doesn't inherit from any existing control. I see it has a place, but it doesn't seem to be a replacement for xControls.
-
We've been asking for that since about LabVIEW 6. Instead, we got xcontrols (xcontrols do a lot of what you are asking for, by the way. They are just buggy and unpredictable). NI can also have some DLL controls using a completely undocumented API. Sounds like that might be right up your street
-
Ah. It seems the ability came in in 2011 (was working in 2009). I was opening your controls in 2018 and back-saving to 2009, so it seems these features that are enabled are preserved with back-saving, which is useful to know. Also, I didn't realise that we now have a way (via ini-file) of making these controls multiple glyphs-I missed that memo (your link). So thanks again.
-
Perfect. Thanks hooovahh. Did you use flarns tool?
-
Almost. The classic one cannot change the colour of the scroll bars. I think I need a modern one (which can be changed).
-
Does anyone know of a version of this control that can have a transparent background?
-

Development Env packager
ShaunR replied to 0_o's topic in Application Builder, Installers and code distribution
This is serendipitous post. Short answer. Yes (but I'll caveat that). I have been thinking a lot about these things recently (see the installer thread) .... and I mean implementation wise. My concentration has been on the installation but it is so intertwined with packaging so I have had to think about that too. Go and put you wish-list over in the Intaller thread. -
That makes a lot of sense. thanks. I'll add that to the long, long list of why I ban ActiveX and .NET from my projects.
-
Right. So that means the root loop is per executable instance? Or shared (via some IPC mechanism)? Because I am asking in terms of the LV task scheduler.
-
OpenG Zip unable to detect file corruption
ShaunR replied to Mads's topic in OpenG General Discussions
Indeed. In the vanilla unzip.c; (minizip 1.2) the CRC is only used for the password so that files can be extacted. I had to calculate the CRC myself during extraction for integrity. -
If the DVM and power supply are SCPI compliant; you only need to change the address of the command you send.
-
This I know to be true (for executables). However. There is only one LabVIEW run-time per platform (which has the memory manager) so how does that affect processes? Is there a root loop per process or one global root loop?
-
OpenG Zip unable to detect file corruption
ShaunR replied to Mads's topic in OpenG General Discussions
Is that being done inside the DLL functions, rather than in the LabVIEW code? I don't see any checks in the LabVIEW code. Nor do I see the CRC being passed to a DLL function. -
Yes. The only way to guarantee that LabVIEW does not use multiple threads is to use the root loop. Unfortunately that is the same thread that the UI runs in for certain tasks (we all know not to use the native dialogues, for example). Under normal conditions, LabVIEW has a thread pool (sometimes a couple of hundred threads) that it uses and there is no control over which threads in that pool it will use to call a DLL. If the DLL is thread safe then you can choose "Run in Any Thread" and LabVIEW will use whichever thread it deems fit at the time to call the DLL and the DLL is assumed to handle thread locking. If it is not thread safe, then you must select "Run In UI Thread" so that it is always called by the root loop thread (there is only one single thread there). The easiest analogy to think about it in LabVIEW terms is that when you select "Run in Any Thread", the DLL is behaving like a reentrant clone with the setting "share clones between instancies". You will no doubt be aware that strange results can occur if the reentrant clone with this setting has a shift register as memory inside (akin to your DLLs global). The reason for that behaviour is because you cannot guarantee which which clone, in which order, is used so the state of the internal memory, is unclear. You obviously don't get a crash when that happens, just strange results but in a DLL you'll get deadlocks, crashes and an assortment of bad behaviour - especially if pointers are involved. The way to get around it in the LabVIEW example is to run it either as a "Preallocate For Each Instance" or a normal, non-reentrant VI. The former is not an available option for DLLs. The latter is the equivalent of setting the DLL to "Run in UI Thread".
-
Unless the DLL is thread safe (which you have said it's not) you must run it inthe root loop (AKA single threaded).
-
You are running it in the root loop (Orange Node), rather than run in any thread. right?
-
Strange "VI is External Editor" option in palette context menu
ShaunR replied to Sparkette's topic in LabVIEW General
I was actually working in 2013 at the time but have just checked 2018 and it is indeed in there. So it was obviously added after 2013. -
How do I open the right-click menu when I can't click the object?
ShaunR replied to Sparkette's topic in User Interface
I know. You obviously didn't get the dig at a keyboard warrior vs a mouse clicky, coffee in hand, reclined on the sofa, coder layabout like me -
How do I open the right-click menu when I can't click the object?
ShaunR replied to Sparkette's topic in User Interface
Quick drop? What's that? -
How do I open the right-click menu when I can't click the object?
ShaunR replied to Sparkette's topic in User Interface
IC. I'll have a play around with the XML now that you have shown me how to do it (many thanks). Maybe I'm just being a bit OCD about it but once/if it's done, I won't have to revisit it anytime soon. -
How do I open the right-click menu when I can't click the object?
ShaunR replied to Sparkette's topic in User Interface
Many thanks. I thought that might be an issue. I can move it around using a property node (if I scan the FP objects to get a reference). Like you said. You can't select it (not that you can with the vanilla splitter either) which means you can't create property nodes either so scripting would be the only way of doing anything. Is it possible to make it 1px in edit and 0 in run modes? I've no idea how these controls are put together but xcontrols can be different in run or edit. -
How do I open the right-click menu when I can't click the object?
ShaunR replied to Sparkette's topic in User Interface
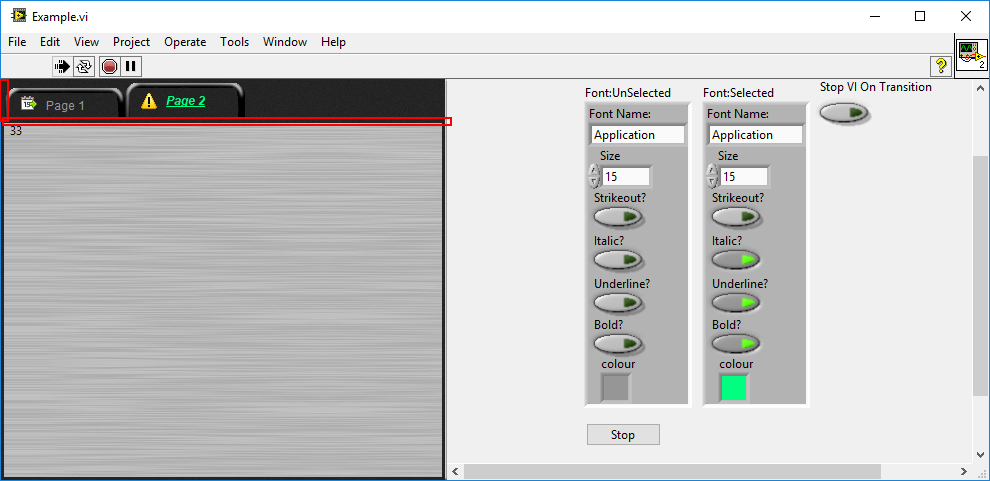
Yes. If you can get rid of the gaps created by the splitter and array border (marked in red on the second image), that'd be great. -
How do I open the right-click menu when I can't click the object?
ShaunR replied to Sparkette's topic in User Interface
The picture control is just what I'm looking for (thanks Hooovahh). that eliminates the gap between elements The array border and the splitter wouldmake it perfect