ShaunR
-
Posts
5,033 -
Joined
-
Days Won
313
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by ShaunR
-

OpenG "Variant Data" palette not supported in NXG3.0 ?
ShaunR replied to LOIS LE BRAS's topic in OpenG General Discussions
You can get it to display Japanese under certain conditions (ini setting and Force Uncode Text on the control) but it is permanently "stuck" so you end up with spaces between chars for ascii. It also requires converting the to UTF16-LE via windows calls (hence you need the code language packs) so it is not cross platform and it doesn't work at all with filename controls or file functions. -
OpenG "Variant Data" palette not supported in NXG3.0 ?
ShaunR replied to LOIS LE BRAS's topic in OpenG General Discussions
If you want to display Japanese, you cannot on an English version of Windows - you just get question marks. -
OpenG "Variant Data" palette not supported in NXG3.0 ?
ShaunR replied to LOIS LE BRAS's topic in OpenG General Discussions
Thanks for doing the leg-work. A) Is a good thing but I would have preferred ASCII as the default for campitibility. I wouldn't relish going through an already working application and having to explicitly change all the nodes. The only time you would know if you'd missed a node to change is when data intermittently gives incorrect results. B) I don't really care about since I have only used it once or twice mainly for JSON. The other question is; can it actually display UTF8/16? We can already deal with UTF8 with the primitive. What we can't do, currently, is display it on non, language specific OSs. -
OpenG "Variant Data" palette not supported in NXG3.0 ?
ShaunR replied to LOIS LE BRAS's topic in OpenG General Discussions
Is this all strings and if so how do functions such as TCP/UDP Read/Write and Byte Array to String/String to Byte Array operate? -
An Extensible, Object-Oriented Alternative to XControls
ShaunR replied to The Q's topic in User Interface
Um. Can't we? If you select the objects on the front panel and press the "Reorder" button in the toolbar. There is a "Group" option. That will group the selected controls and you can move them around as one unit. Maybe I'm just misunderstanding what you are asking. -
This is a test harness I'm using. It is the VI loaded into the sub-panel (Example1.vi) that invokes the save dialogue when this VI (Example2.vi) finshes executing. It also happens if the the Abort VI button on the toolbar is pressed. (auto dispose ref = true makes no difference if that's a criteria).

-
It is loaded with Open VI Reference. The Explain Changes" dialogue states that it is a cosmetic change (A front panel object was resized). My current suspicion is that it is linked to the "Fit Control to Pane" setting of the xcontrol on the host VI and/or the facade (which the actual control is also set to). I've at least now ascertained that it also happens in normal sub-panels too and is repeatable. Maybe I should just publish it with a known issue - something I have always hated to do. Then at least others can fiddle with it.
-
I think so. Well. I know so but I'm unsure of the mechanism since it is an xControl on a VI that is loaded in a sub-panel of another xControl (if that makes sense-it's nested). When exiting, the host VI (loaded in the sub-panel) wants to be saved. I can stop it by not updating the display state of the xControl on the loaded VI host, but then the facade doesn't update properly. Additionally, it doesn't seem to be every time; just sometimes which is proving to be a barrier to finding a work-around. If it's not loaded in the xControls sub-panel (even a normal subpanel), then it all works as intended. I have, since, thought of a couple of things to try, but it'll have to wait until I can get round to it again. Amen.
-
Lol. Bonus points if you have one of those VIs on each virtual desktop. Keep 'em coming.
-
Dissapointing. I've managed to work around most of them but the one that prevents me from publishing is that I can't get rid of the xControl making the host VI dirty and requiring saving (a nested xControl). Still. It's OK for my personal use as I can put up with that.
-
My first ever meme prompted from this post
-
Not the words I would've used There has to be a meme that can link GoT and NI inter-departmental politics.
-
Are there plans to fix all the bugs? I've just spent a month writing two xcontrols and all that was mainly finding workarounds to the bugs (and I still don't know why some of the work-arounds actually work)
-
Load Warnings When Building
ShaunR replied to martin_g's topic in Application Builder, Installers and code distribution
Check the project XML and see if there are any absolute paths rather than relative paths. -
Setting "Verify" to false just turns off the certificate check so that any old certificate is accepted without error. This is of course a security risk and should never be used outside of development. IIRC. The LabVIEW HTTP functions use cURL and the "ca-bundle.crt" located in \National Instruments\Shared\nicurl. It contains the certificates of the Authorities. Adding the servers' certificate or the servers' trusted root certificate to that list once you have ascertained the certificate is correct for that website; is the recommended procedure for adding ad-hoc certificates (thus keeping "Verify" = True).
-
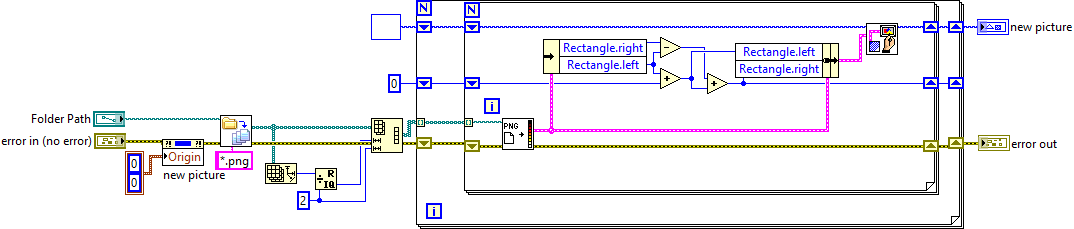
I only see a 1d array of images loaded from files (which you didn't post). Is the question to convert the 1D array of image files into 2D? How to stitch a 2D array into a single image that looks the like 2D array (stitch row, by row, column by column)? How to stich the images of a 2D array into one long image? (Vertically, horizontally?). If I were to "stitch" some images together, I would use the default Picture Toolkit or maybe Vugies Bitman library rather than the Vision Software. Here's an example using the Picture Toolbox, which loads a number of *.png files, splits them into a 2D array, then "stitches" them together as one long horizontal image. It should be fairly straight forward to "stitch" by rows or columns from this point, if it is required, by adjusting the Top/Bottom in the same way. Multiple row stitching.vi
-
Is Cirrus Logic part of NI?
-
That's probably after unchecking "place terminals as icons" and is what I shout when disabling the 32&64 bit Web-servers that NI installs (that I didn't ask for)
-
Yes. I set this value in the options (Front Panel>>General>>Open the control editor with double-click) and was able to open the button in a separate editor window by double clicking on it in "customise mode"
-
There must be another step or perhaps an ini-key because customise is greyed out for the browse button on my installations.
-
Really? I didn't find it difficult or onerous at all - just case statements for edit and run-time behaviour. With xControls, everything takes a lot of programming to get the basics, hence why your toolkit has a place (which it excels at, by the way). But once you have the basics of updating/drawing/refreshing the display (the hardest part), creating edit-time functionality isn't difficult. - mainly menu manipulation. In fact. Because front panel menus are mainly used to configure a control at edit-time and you can add in-built menu options to a custom menu; inheriting functionality from the architypical control (like enable/disabled/greyed out) isn't a problem and doesn't have to be re-implemented as it does with the diagram properties and methods.
-
I've no interest in NXG. When LabVIEW finally dies, I will use one of my other languages that supports x-platform.
-
Well. NI have never really worried about finding a way out of a corner - I'm still waiting for unicode support but I take your point. If NI see this as fullfilment of an issue, the 11 xControl bugs currently in the known bugs list will never be fixed.