ShaunR
-
Posts
5,017 -
Joined
-
Days Won
312
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by ShaunR
-
This also has other subtle implications such as you can change the ring strings at run-time whereas you cannot with enums. This means that if you want to translate a UI.......don't use Enums on the FP.
-

How to increase performance on lage configuration INIs?
ShaunR replied to flowschi's topic in OpenG General Discussions
Buy an SSD? Only load the sections that are not the same as the LabVIEW in-memory defaults? Only load what you need when you need it (just in time config)? Split out into multiple files? (diminishing returns) Refactor to to use smaller configurations? Lets face it. 15-30 seconds to load 10,000 line inifiles is pretty damned good for a convenience function where you are probably stuffing complex clusters into it. What is your target time?- 7 replies
-
- 1
-

-
- variantconfig
- configuration ini
- (and 2 more)
-
It's no worse than having to use the property nodes and callbacks for ActiveX/.NET controls or the external windows of the Vision toolkit and this is, or is potentially, cross platform.
-
Well. you are sending a waveform as a block (array) of data which has a fixed dt so you need to know the start time, Prepend the date/time to your double array and read it the other end to set your x axis start. You can then compare that value with the time you received it to get a rough latency of transmission.
-
Sharing configuration information between processes
ShaunR replied to Neil Pate's topic in Application Design & Architecture
OK. So you want to "pull" and like ini-files. Hell. there is a whole operating system based on ini files, eh Linux? So why not? Each "actor" (I hate that terminology) has its own ini-file, whos name is dependent on the actor, process, service or whatevers name Lets say you have an "Acquire_DC_volts" then you could have acquire_dc_volts.ini. Your "System config Engine" broadcasts a "UPDATE" message (event or queue list-up to you and your architecture) that prompts each actor that wants config info to issue a query message to the "System Config Engine" that says "I want this file". The "System Config Engine" then loads the file and sends it to the requester. Why do it this way instead of relying on each actor to load it? Because you can make an API and handle more than just config files, you can order the requests if there are inter-dependencies and you can swap out ini-files for a DB later once you have succumbed to the dark side .. You can see this type of messaging in the VIM Hal Demo. There is a FILE.vi [service] that does the actual reading and if you look in MSG.vi you will see the requests (e.g. MSGPOPUP>FILE>READ>msg.txt" and "MSGPOPUP>FILE>READ>bonnie.txt" ), It doesn't happen on config changes because there is no user changeable config, rather, when certain events happen - but it's the same thing. -
Sharing configuration information between processes
ShaunR replied to Neil Pate's topic in Application Design & Architecture
Yes. I use a different topology-I'm at the other end of the spectrum I talkedabout earlier. I only send UPDATE messages and whoever needs the configuration goes and queries the database for whatever they are interested in. You push; I pull -
Sharing configuration information between processes
ShaunR replied to Neil Pate's topic in Application Design & Architecture
Well. Messages are ephemeral and config info is persistent so at some point it needs to go in a file. This means that messages are great for when the user changes something but a pain for bulk settings. Depending on the storage, your framework and your personal preferences, the emphasis will vary between the extremes of messaging every parameter and just messaging a change has occurred. -
Sharing configuration information between processes
ShaunR replied to Neil Pate's topic in Application Design & Architecture
If you can use a LV2Global to transfer information then it isn't a separate process-in the operating system sense. May seem pedantic, but it makes a huge difference to the solutions available. Anyway..... I think most people now use a messaging system of various flavours so it's usually a case of just registering for the message wherever you need it. Usually for me that just means re-read the database which can supply you with the sharing like a global but without dependencies.. -
Find orphan VIs in project hierarchy (on disk)
ShaunR replied to LogMAN's topic in Source Code Control
Commented Out Diagrams? No Specifies whether LabVIEW returns dependencies that LabVIEW does not invoke, such as those in the Disable case of a Diagram Disable structure. Also, if you wire a constant to the selector terminal of a Case structure, LabVIEW considers dependencies in non-executing cases to be commented out and does not invoke them. -
Oooh. This is fun. http://www.indeed.com/jobtrends/q-labview-q-programming.html?relative=1 Python is far superior to PHP and IMO is why it is enjoying the attention. http://www.indeed.com/jobtrends/q-php-q-python.html?relative=
-
I have access to all versions from 7 through to 2015 (32 and 64 bit as well as other platforms). Let there be no mistake. I am not calling into question LabVIEWs performance and stability - which has always been exemplary. My jocularity is that people still believe this is a valid excuse for shipping commercial software and proffering it as a feature. We have "software as a service" (SAAS) so I will coin the phrase "excuse as a feature" (EAAF) Also, to an extent, it's a case of "you have to laugh or else you would cry" to my disappointment that this myth is allowed to perpetuate when it was a single version (2011) that was supposed to be the "Stability and performance" release after the pain of 2010. I laughed then when they came out with it and I'm still laughing 5 years later (You can find it on LavaG.org) Try charging your customers for a "performance and reliability" version of your software and see how far you get
-
-
Register for shared variable data value change notifications
ShaunR replied to george seifert's topic in LabVIEW General
It did. It was called "BridgeVIEW". They didn't sell many so decided to make it a toolkit instead . -
Register for shared variable data value change notifications
ShaunR replied to george seifert's topic in LabVIEW General
The same way you do from any DLL - PostLVUserEvent. Generating events for LabVIEW is trivial. Maintaining a DLL (especially multi-platform) is a right royal pain in the proverbial,however. -
Find orphan VIs in project hierarchy (on disk)
ShaunR replied to LogMAN's topic in Source Code Control
I do this slightly differently (in Project Probe). Yours might be faster if you only look at link info from the file rather than loading the hierarchy but I have to look at lots of other VI stuff that require opening the VI anyway too (like re-entrancy, debugging enabled, icon, description etc). I also use it to sort VI refnums when force compiling hierarchies. I create the file list similarly to you then I open each VI and check if it has dependencies (Get VI Dependencies Method Node). The VI opened and its dependencies are added to a [found] list. If a VI in the file list is already in the list or in memory then it doesn't need to be opened and could be considered already processed (it has a parent that was previously opened). If a VI has no parent and has no dependencies then it is an orphan. It can also find VIs in conditional disables. So I deduce if it is an orphan from the dependencies of all the VIs -
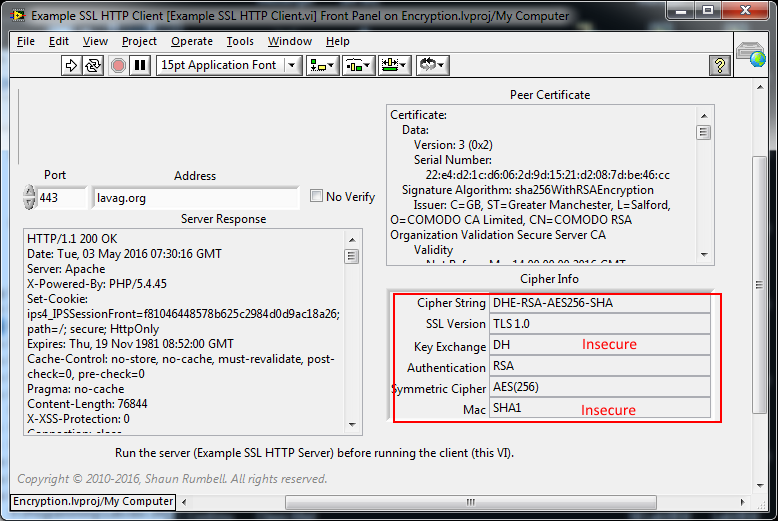
Centos5 by any chance? This issue is (or at least TLS unable to support greater than 1.0 in Centos5) is the reason I have not moved to TLS on lvs-tools.co.uk yet even though I have the certificate. The problem is that it trains users to ignore privacy and security warnings.. When they are compromised for real, they just carry on without questioning instead of not visiting the suspect site and certainly not putting in user names and passwords..I'm sure there is a proper name for this conditioning but it is the same (but with possibly greater consequences) than T&C dialogues.
-
It's not the certificate. It is because LavaG only supports TLS 1.0 ciphers and they have been deprecated in the latest Chromium (51?) based browsers.

-
Multiple Client, Single Server Configuration
ShaunR replied to stefanusandika's topic in LabVIEW General
OK. So you have a number of processes that handle different IO devices/hardware/things that sit in the "Analog" directory. Most of these (I only looked at a couple) seem to be self contained applications in their own right with things like TDMS logging of data and in-line analysis. By "Applications" I don't mean executables, by the way, just that they can exist standalone. These applications share their data via some Functional Global Variables (FGV_Sensors, FGV_Can et. al.) which are used to collate and store the data for reporting and stuff. These are effectively the" Internal Process" you show in your images that your were talking about creating. Well. You already have them - sort of There were also some global variables in the "Globals" directory but these seemed to be concerned with UI state and list management so I didn't look too closely.. So the question is. Are you looking to bolt on a TCPIP interface on the existing software; changing as little as possible then walk away to do more interesting stuff. Or are you looking to refactor completely for reasons like future-proofing, identifying reuse, enlightenment, and other noble sacrifices of your time - and while you are at it, put a TCPIP interface on it? Or,put another way How bad do you think the current (working) code is and whats wrong with it? -
It's a classic symptom of upgrading to Windows 10
- 6 replies
-
- 1
-
-
- front panel
- clone
- (and 2 more)
-
Yes. But........ 3rd party APIs never create their functions with that in mind and may need more than one parameter or the pointer is passed back as a result rather than a parameter. You can't guarantee what order the multiple CFLN callbacks will be executed in so the "Close" may be before others (can only destroy it once there is no possibility it will be used). Can only populate it from within the DLL requiring special functions and handling in the DLL rather than LabVIEW. Cannot test to see if the pointer is valid (ok, so thats a hard one regardless but you can do stuff to mitigate it) Some of those aren't an issue for you since you use a wrapper DLL so you can write special functions to fit squares into round holes. You probably don't need it at all because you can make your DLL arbiter and guardian of the pointers.As you know,I choose not to write wrapper DLLs and the InstanceDataPtr doesn't quite cover it.
-
Multiple Client, Single Server Configuration
ShaunR replied to stefanusandika's topic in LabVIEW General
For an internal server (since they are all under one process) I would suggest Events or queues depending whether you are pulling or pushing the data. This will be the fastest and most efficient TCPIP I would suggest Network Streams. UDP anything but multicast. -
I'm hoping he'll hijack all those and replace them with ones we can send arguments to 10 years ago I complained about this to NI We'll need to talk about how we configure such a hack (per project, per VI, per node, per IDE, any or all of the above? )
-
This has other positive implications for developers that interface to external code. One issue I (we?) have is that we cannot pass opaque pointers to the "abort", "reserved" and "unreserved callbacks" in CLFNs which are direct hooks to the LabVIEW IDE. Many 3rd party API libraries have an Init and Deinit procedure which is global. You only want to de-init if An init succeeded and allocated resources(no error, say) No residual inits are floating around from the last run. However, the callbacks for the CLFN are on each node so you only know that you can cater for 1&2 if the last node is executed and other nodes didn't error. Aborting in the IDE LabVIEW stops it dead before the last node and therefore you leak the callback. Any other strategy results in a crash of LabVIEW because you don't know whether the callback actually exists. If we had an abort hook (and a reserve and unreserve) that could take arguments then we can easily cater for this type of API. As an example. In order for the the OpenSSL library to be thread safe you must attach a callback to the library. This is a global callback, across all instances and invocations of the library and can only exist once as it is basically a mutex function. So when the library is initialised, a thread callback is created and passed to the API . You are supposed to then free the pointer and "de-init" the callback when you shut down but - and this is a "but" with a capital "CRASH" - only if you created the callback rather than another application.....bummer! Regardless of that GOTCHA; when you abort the IDE, however, you cannot execute your shutdown function which is in the close or De Init VI. Similarly, There is no way to track the callback instance from the LabVIEW dev environment since the pointer allocation exists outside of LabVIEW so you don;lt know how many de-inits to call to clean up. So when you press abort, you leak that callback until LabVIEW exits and the OS cleans it up for you. Ideally, we would use the abort, reserved and unreserved callback function of the CFLN to clean up. (Note that this is not a problem in an application as a Close or De-Init can always be called and is no worse than forgetting to close a queue refnum) Now. NI will argue that you can create these functions in you DLL and call them so it's not a problem. Except that, of course that would only work if you run all nodes in the root loop which defeats the whole point of multi-threaded callback -DOH! (as well as a huge performance hit).Additionally and probably even worse for me is that I use unmolested (or I should say "untampered with" so that hashes can be checked) 3rd party code so that users can update binaries without my intervention and, of course I don't run the risk of introducing nasty, hard to trace bugs into an already extensively tested API I'm not intimate with. So your abort could also enable a global cleanup of a 3rd party API when in the IDE. We could detect the run-time engine or IDE and snatch whatever arguments the clean-up requires then, using your abort hook, pass that directly to the APIs clean up function.
-
There also used to be a "Rusty Nails" section on LavaG.org for stuff that was cool but might blow up LabVIEW. I wonder what happened to that?