ShaunR
-
Posts
5,033 -
Joined
-
Days Won
313
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by ShaunR
-
Can you clarify? There are a couple that work with the standard error cluster so what is meant by "really work"?.
-
Three points jump out at me from an implementation point of view.. The user is expected to propagate the error list. This is fraught with foot shooting possibilities (forgetting to wire a case through, for example, will clear all the errors). Try and encapsulate the errors into your API so that storage is handled and managed by the API itself. Creating and passing arrays around as you have will become a performance and memory concern as the array grows and is not deterministic. This will make it a no-go for real-time systems. Instead of just a string for your labels. Consider using a typdef'd string combo box. Then you can give the user a drop down list to choose from to avoid spelling mistakes but still allow them to enter their own custom labels.
-
How long does it take you to create a scheme for all controls/indicators? Have you automated any of it?
-

emphasize (envelope) portion of waveform chart
ShaunR replied to rharmon@sandia.gov's topic in LabVIEW General
I will echo this. 99% of the time you will find that charts are deficient in one way or another. They always start out great as a quick way to visualise data but as soon as the data is not contiguous across multiple plots or you need a data/time axis you always end up switching to the XY graph.I go straight for XY graphs every time. -
Browsers.
-
Presentation About Forums :: Looking for feedback
ShaunR replied to Norm Kirchner's topic in LAVA Lounge
Soooo. Shouldn't we remove the site search then if that's not the recommended way of searching or (shock horror) fix it so it works? -
+1 with Hooovahh. Checkboxes and LEDs. FWIW. I no longer use LabVIEW front panels at at all for commercial user interfaces..
-
Sour. The one use-case where VIMs finally solved a [decade old] problem and was getting me so excited that I wrote a whole demo on it - VIM HAL Demo). Is only going to solve half the problem, I'm getting the JSON blues feeling
-
That's nice (you tease ). But the big question is "do my 'named events' work properly now?"
-
Presentation About Forums :: Looking for feedback
ShaunR replied to Norm Kirchner's topic in LAVA Lounge
Do #1 should be a don't. The site search is useless and we all use Google Do: 8. Use emoticons liberally. Subtle meanings or intentions may be lost or misconstrued when writing text so use them to reinforce your intended meaning. -
Presentation About Forums :: Looking for feedback
ShaunR replied to Norm Kirchner's topic in LAVA Lounge
Elaborate? -
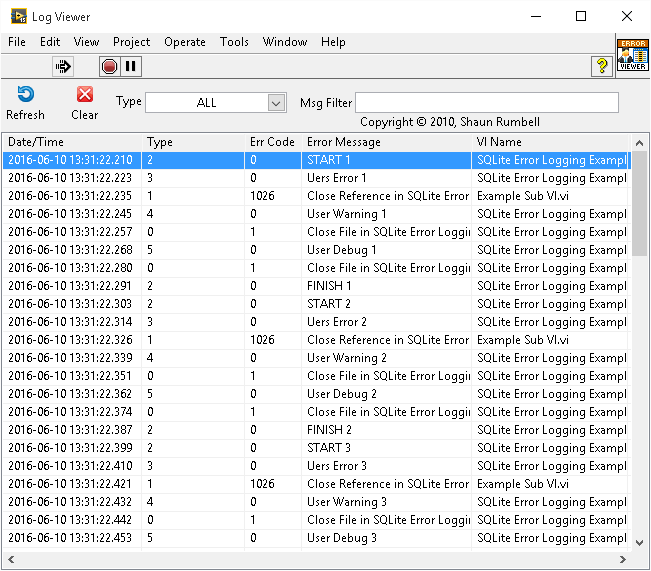
The API distinguishes between user errors and native LabVIEW errors. Since the implementation does not allow you to input user error numbers, the code number for user errors or warnings is moot and defaults to zero.This way it does not interfere with native LabVIEW errors and warnings. If you want to force an error with a specific error number then there is already a primitive to do so (Error Cluster From Error Code.vi) and the API will log it when you pass it in. But don't get hung up on specifics. It's a an example of using a SQLite database for error logging so it isn't meant to be the ultimate silver bullet to error logging (although I don't think it is far off-it's a case of it works for me in everything so far ). If you have some good ideas (like your suggestion of more levels/priorities) then maybe we can improve the example. But at the very least it is a good starting point. Lets see how it fails your use-case and what we can do about it, eh?
-
I think you misunderstand. An API doesn't decide the meaning of a priority as such. It's just another field that you can use to group errors. The developer still decides if it's fatal, recoverable or just nice to know but he can decide to limit the granularity of written data or filter and sort it (e.g.fatal only). Think of it as categories of errors. Most APIs have a few built-in "categories" for the developer to use.
-
Or as Linus Tovalds says: "Never break user space" and "if you change the ABI, I will crush you!" . (Shame they don't listen to him )
-
Umm. No. The numbers in the user source string is just so you can see which message belongs to which error otherwise you'd just have a load of starts and finishes and unable to check which write generated it. The "priority", or "level" as it is called is the Typedef (Error, Warning, User etc). I've used 4 because that was always enough for me, although I think I will change it from a U8 field to a U64 to give 61 User level/priorities in total rather than 5. That should be enough, right?
-
Have a look at the SQLite API for LabVIEW. It has an errors API and an example. I use it in messaging systems with a service that listens to error messages.

-
This is what LavaG is here for. No-one has even seen this new structure yet and we are already trying to figure out how we can abuse it
-
Sweet. OK. So the default behaviour is no error (accept everything), each case is then tested at design-time in order to make sure it compiles (using normal primitives and preserving coercion and polymorphism) and there is a little bit of manual fnuggery with two new primitives to force a type error so we can implement our own logic. An awesome, outside-of-the-box solution to controlling permissive types. If we have a "To variant (Type Only)" does that mean we can wire it directly to this new structure and use it like an ENUM wired to a case statement but for different types? (I'm thinking outside of macros and at run-time here )
-
Sweet. Similarly. Many of the primitives have default transformations for type, an example being numerics where we can wire in a double and output an Int (coercion) and this is also apparent on controls and indicators. A case-like feature that detects it's terminals has the potential to "explode" that convenience into umpteen subdiagrams where the type must be explicitly defined. Do you have any thoughts how to keep the generic convenience?
-
What is your solution here to the "polymorphic problem" - where we have to define a subVI (or in this case a subdiagram) for every LabVIEW type.
-
Nice. You are only 1 femtometer away from replacing the VIM and removing the old-school named cluster.
-
Well. The fist thing I will do is fire up the VIM Hal Demo. If that works without having to replace all the VIMs and has meaningful event names; I will be a very happy bunny.
-
It sounds from the [brief] description that if no cases match then it could break the Vi, thus achieving what you desire by adapting to only those types you define in the structure (maybe an optional default case?). Except this is more powerful in that you could also do things like "nearly equal to zero" if it is a double type, for example.
-
Dealing with multiple DNS entries
ShaunR replied to John Lokanis's topic in Remote Control, Monitoring and the Internet
Oooooh. Never knew it could do that. -
I don't claim it works under Windows. Thats why I suggested the file change notification for Windows..