ShaunR
-
Posts
5,033 -
Joined
-
Days Won
313
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by ShaunR
-
Because I can immediately test the correctness of any of those VI's by pressing run and viewing the indicators. Nope. That's just a generalisation based on your specific workflow. If you have a bug, you may not know what VI it resides in and bugs can be introduced retrospectively because of changes in scope. Bugs can arise at any time when changes are made and not just in the VI you changed. If you are not using blackbox testing and relying on unit tests, your software definitely has bugs in it and your customers will find them before you do. Again. That's just your specific workflow. The idea of having "debugging sessions" is an anathema to me. I make a change, run it, make a change, run it. That's my workflow - inline testing while coding along with unit testing at the cycle end. The goal is to have zero failures in unit testing or, put it another way, unit and blackbox testing is the customer! Unlike most of the text languages; we have just-in-time compilation - use it. I can quantitively do that without running unit tests using a front panel. What's your metric for being happy that a VI works well without a front panel? Passes a unit test? It may be in the codebase for 30 years but when debugging I may need to use the suspend (see below) to trace another bug through that and many other VI's. There is a setting on subVI's that allow the FP to suspend the execution of a VI and allow modification of the data and run it over and over again while the rest of the system carries on. This is an invaluable feature which requires a front panel This is simply not true and is a fundamental misunderstanding of how exe's are compiled. Can't wait for the complaint about the LabVIEW garbage collector. We'll agree to disagree.

-
ECL Version 4.5.0 was released with CoAP support. Next on the hit-list will be QUIC (when it's supported by OpenSSL properly). I'm also thinking of opening up the Socket VI's as a public API so people can create their own custom protocols.
-
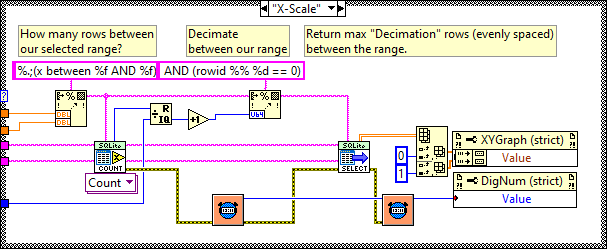
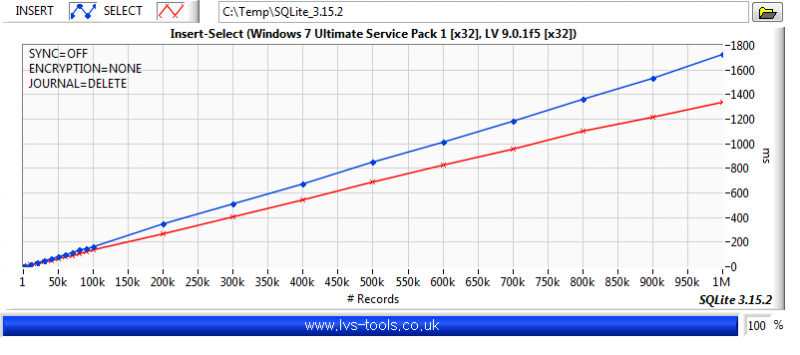
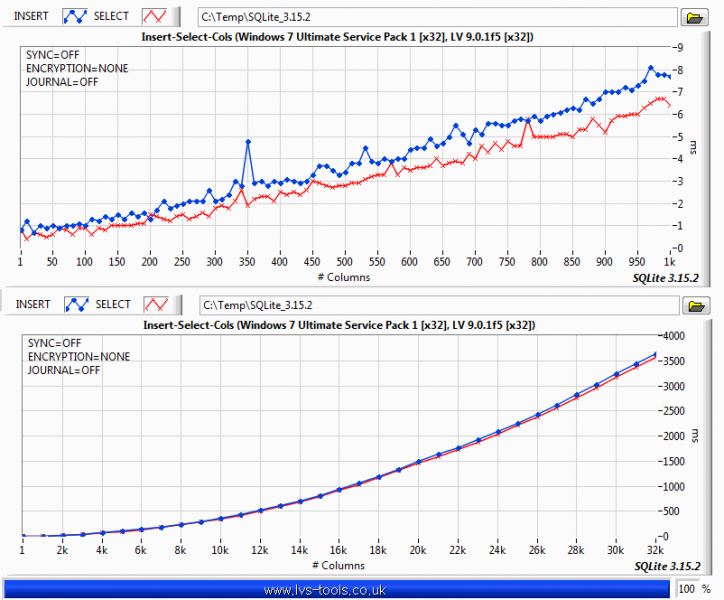
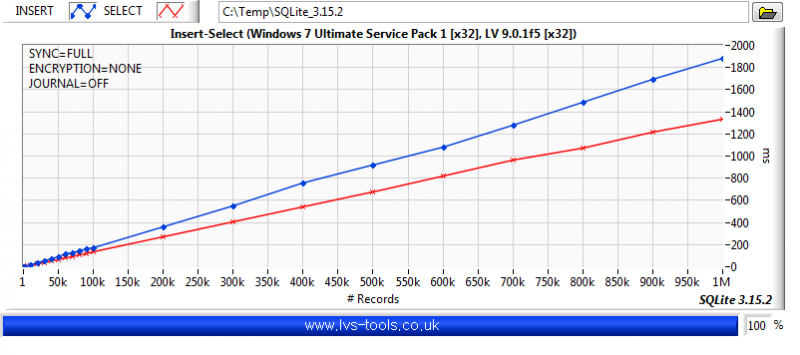
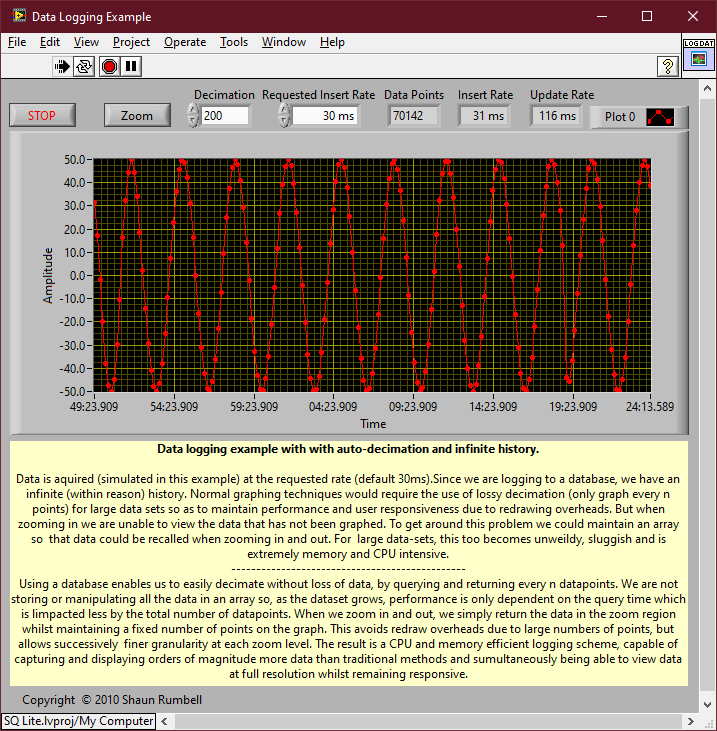
You want a table per channel. If you want to decimate, then use something like (rowid %% %d == 0) where %d is the decimation number of points. The graph display will do bilinear averaging if it's more than the number of pixels it can show so don't bother with that unless you want a specific type of post analysis. Be aware of aliasing though. The above is a section of code from the following example. You are basically doing a variation of it. It selects a range and displays Decimation number of points from that range but range selection is obtained by zooming on the graph rather than a slider. The query update rate is approximately 100ms and it doesn't change much for even a few million data points in the DB. It was a few versions ago but I did do some benchmarking of SQLite. So to give you some idea of what effects performance:
-
I'm not sure what you mean by "not fully transparent" but if you want to get rid of the border you can do something like this. sr_test1.zip
-
Not so much mind boggling - I used to support VxWorks . It's not just Apple OS's though. Linux is similar. The same mind-set pervades both ecosystems. I used to support Mac, Linux and Windows for my binary based products because LabVIEW made it look easy. Mac was the first to go (nobody used it anyway) then Linux went (they are still in denial about distribution).
-
It doesn't have to. Just back-save () to a version that supports the OS then compile under that version. If you are thinking about forward compatibility then all languages gave up looking for that unicorn many years ago. That is excellent news.
-
This wouldn't be much of an issue since you could always use an older version of LabVIEW to compile for that customer. However. Now LabVIEW is subscription based so hopefully you have kept copies of your old LabVIEW installation downloads.
-
Anyone interested in QUIC? I have a working client (OpenSSL doesn't support server-side ATM but will later this year). I feel I need to clarify that when I say I have a working client, that's without HTTP3 (just the QUIC transport). That means the "Example SSL Data Client" and "Example SSL HTTP Client TCP" can use QUIC but things like "Example SSL HTTP Client GET" cannot (for now). If you are interested, then now's the time to put in your use-cases, must haves and nice-to-haves. I'm particularly interested in the use-cases as QUIC has the concept of multiplexed streams so may benefit from a complete API (similar to how the SSH API has channels) rather than just choosing between TLS/DTLS/QUIC as it now operates.
-

Optimization of reshape 1d array to 4 2d arrays function
ShaunR replied to Bruniii's topic in LabVIEW General
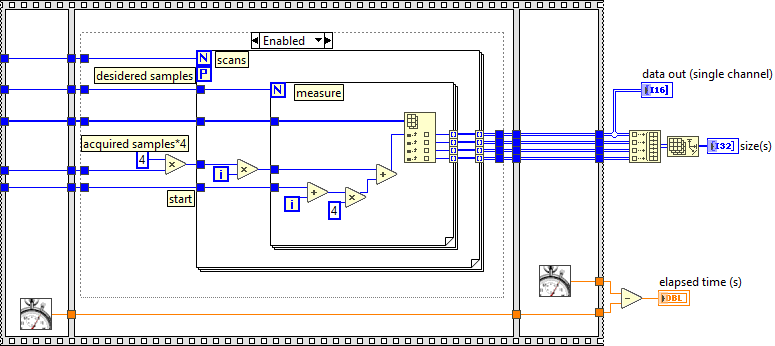
There is a GPU Toolkit if you want to try it. No need to write wrapper DLL's. It's in VIPM so you can just install it and try. Don't bother with the download button on the website-it's just a launch link for VIPM and you'd have to log in. One afterthought. When benchmarking you must never leave outputs unwired (like the 2d arrays in your benchmark). LabVIEW will know that the data isn't used anywhere and optimise to give different results than when in production. So you should at least do something like this: On my machine your original executed in ~10ms. With the above it was ~30ms.
-
Optimization of reshape 1d array to 4 2d arrays function
ShaunR replied to Bruniii's topic in LabVIEW General
Nope. I can't beat it. To get better performance i expect you would probably have to use different hardware (FPGA or GPU). Self auto-incrementing arrays in LabVIEW are extremely efficient and I've come across the situation previously where decimate is usually about 4 times slower. Your particular requirement requires deleting a subsection at the beginning and end of each acquisition so most optimisations aren't available. Just be aware that you have a fixed number of channels and hope the HW guys don't add more or make a cheaper version with only 2. -
Optimization of reshape 1d array to 4 2d arrays function
ShaunR replied to Bruniii's topic in LabVIEW General
Post the VI's rather than snippets (snippets don't work on Lavag.org) along with example data. It's also helpful if you have standard benchmarks that we can plug our implementation into (sequence structure with frames and getmillisecs) so we can compare and contrast. e.g -
OpenG LabVIEW Zip 5.0.0-1 - stuck at the readme
ShaunR replied to PA-Paul's topic in OpenG General Discussions
This is why it takes me hours to make an ECL build that works and is one of the many reasons only Windows is now supported (can load from same dir). Even then. I have to fight VIPM to get things in the right places. I refuse to do #2. -
Well. There's a few problems but the reason it's not showing the next image is because you increment the counter during acquisition until it's 300 and when you start the next acquisition it indexes into the path array at 300 (which yields Not A Path). You've confused your 30 second timer with the file index. Make a proper timer with a time function and increment the index on stop.
-
Parallel For Loop versus Async Call and Collect
ShaunR replied to Stagg54's topic in LabVIEW General
Yes but you'd need to define "reliably". I think there would be few milliseconds of jitter and probably a minimum of about 4ms. -
Parallel For Loop versus Async Call and Collect
ShaunR replied to Stagg54's topic in LabVIEW General
There are surprising few situations where a parallel for loop (pLoop) is the solution. There are so many caveats and foot-shooting opportunities even if you ignore the caveats imposed by the IDE dialogue. For example. For the pLoop to operate as you would imagine, Vi's that are called must be reentrant (and preferably preallocated clones). If a called VI is not reentrant then the loop will wait until it finishes before calling it in another parallel loop (that's just how dataflow works). If a called VI is set to reentrant shared clones then you get the same problems as with any shared clone that has memory but multiplied by the number of loop iterations. Another that you often come across with shared, connectionless resources (say, raw sockets) is that you cannot guarantee the order that the underlying resource is accessed in. If it is, say, a byte stream then you would have to add extra information in order to reconstruct the stream which may or may not be possible. I have actual experience of this and it is why the ECL Ping functionality cannot be called in a pLoop.
-
What is the best way to handle errors for external DLL/C code,
ShaunR replied to Neon_Light's topic in Calling External Code
I'm a simple programmer. Catch them all where possible (try { /* */ } catch (...)) and pass errors back as a return value. That's my tuppence. -
It's the example from MDI Toolkit for LabVIEW
-
If you put a Call By Reference Node in the case you've reinvented Dynamic Dispatch with extra steps.
-
Booh with bells on. Hello 7 hr build time.
-
Booooh!
-
Agreed. Even just 100 and UI updates become a bit flakey.
-
They have fixed a bug, is my guess. Concatenating by using null char is a huge security smell. Multiple file types are [supposed to be] defined by using the semicolon separator. Does "*csv;*txt" not work?
-
Interfacing with digital x-ray plates?
ShaunR replied to grubin's topic in Machine Vision and Imaging
It's probably DICOM which is partially supported in the Biomedical Toolkit. -
The variant attribute cannot have duplicates. If you set it, it overwrites the previous values. With the "array with tag" you can have duplicates.
-
Convert to JSON string a string from "Byte Array to String"
ShaunR replied to Bruniii's topic in LabVIEW General
Try print(json.dumps(convert['test'], ensure_ascii=False))