ShaunR
-
Posts
5,005 -
Joined
-
Days Won
311
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by ShaunR
-
I got as far as thinking it required a session parameter which is used in later protocols but I no longer have access to the OBEX spec which is behind a pay-wall. That's not to say it can't be done, it just means it will be a lot, lot harder to find information and some protocol sniffing.which was where I was at when if fell off my radar. I'll have a another look at the weekend to see if I can do anything.
-
No release, no judgement. You've released...Doh!
-
It is something I've said on numerous occasions. Nice someone is finally agreeing with me For example. You can immediately reduce the number of VIs and code size in a LVPOOP project by between [anecdotally] 25% and 50% (50% if its just a small object with only accessors). Only by putting a boolean for get/set rather than using individual VIs for accessors. Oh, wait. We could make it a typdef enum get/set instead of a boolean to make the code more readable. Oh. Now we have an AE......Doh
-

Strongly require Zoom function in diagram
ShaunR replied to wawhe's topic in LabVIEW Feature Suggestions
The Idea exchange is where you need to float ideas like this. Add it to the list.of other people who have requested zoom and been denied. The current feeling is that if you think you need zoom; you are not making use of sub VIs (and don;t ask us to maintain your code ) -
I managed to track down a later paper from 1983 called Implementing Atomic Actions on Decentralized Data where David P. Reed extends his original paper to talk about using Pseudo Time specifically for distributed atomic actions. That is, an action and a failure of that action is atomic across multiple remote sites.
-
Ah. I must have missed that (the deletion). The example just created one ove every enumeration with all controls when I tried it. There are a few directories of this in my temp directory now...lol. I must have opened a slightly older one. I'll take another look to see how you defined that that terminal had to be deleted on that VI. Polymorphic VIs are very useful. I wouldn't throw the baby out with the bathwater. The pros just have to outweigh the cons. Sometimes you don;t need to do a full factorial polymorphic VI if you are just grouping individual functions that already exist into an API. There is no explosion of code then. You ae just consolidating into a single VI for convenience and labeling. It's when you do adapt to type that things get out of hand as it is basically "Save As" then make a tiny change, rinse and repeat N times.
-
It's all great but there needs to be thought about the pros and cons of doing this with polymorphic VIs and classes.The fallout is, that if you take the supplied example, you go from a single VI of 30kB so several VIs totaling ~180kB with no change in functionality. That's nearly a 6x increase in code size with a 7 fold increase in the number of VIs That's why applications take 10 hrs to compile When I choose to use a polymorphic VI, I make that choice very carefully as a trade off between user friendliness (the menus, adapt to type and terminal reduction) and code complexity and size. As I've said before, classes and polymorphic VIs bloat code and cause replication. The worst use would be to effectively just move the enum list of an AE to a poly menu "because it looks better". The tradeoff is the increase of the number of VIs and code size in proportion to the number of items in the enum list with consequences to performance, maintenance, compile times and understanding complexity with no change in function. The gain is a subjective aesthetic for a developer, not even an end user.. The best use is hiding controls unused for an enum item and logical groupings of functions.That is not easy to achieve with automatic wizards as there is no context that can be gleaned from the VI itself. It is very easy to create huge quantities of code and complexity with wizards though. Why, for example does the "Return Settings" need file terminals? How could we tell the wizard to not wire and create those terminals for that enum?
-
It looks like you can operate sequentially from your examples so another method s to use a simple scripting language. This assumes also that the file format is negotiable or can be translated but results in much more flexible and easier to maintain and understand code.. SR ExcelTest.zip
-
Hmmmm. This got me thinking (always a problematic occurrence) If we combined your scripting stuff with the ideas of OMeta we could create a Requirements Spec Translator and convert specs directly to LabVIEW like they do in the CLA exams - make all the CLAs redundant
-
Except I already stated that "From the initial cursory reading (which may change as I re-read another 20 times)" and "Still getting my head around it though" so it wasn't an authoritative stance-you just chose to jump on a specific tangential comment that you thought you might score points on You can bet it has been refined and re-imagined. I even said I was looking for the superseding research in the original post. I also asked for any examples so you know there are none, so far. It is clear that you require to be spoon-fed solutions with concrete implementations. Drive by the fill-up station of knowledge and stick the nozzle in your ear. It is the programmers equivalent of the "pictures or it's not true" that is in some online cultures. I will let you know if and when I have such a solution, an example of it working, a published paper for you to annotate and a licence for you to use it. In the mean-time you will just have to watch to me brainstorm as to possible uses and applications as I piece together the timeline after a serendipitous stumbling over of an ancient text that was written a long time ago by one of the founders of TCP and UDP.
-
Leaving aside your beliefs and the strange disclaimer.... It's not new because it is over 30 years old but I have never heard anyone talking of Pseudo Time until Alan Kay mentioned it and I have a feeling, neither have you. I'm surprised you didn't point to page 72 to challenge my assertion about consistency where he states You are reading it now, . I need to read it at least twice more and then I will have a full understanding and will address your points but rather than think of Pseudo Time as a kind of subversion-like database for values, I think it would be better to think of it more as a mechanism within a subversion-like database that has similarities to a hard, real-time system - atomic execution slots where batches of operations can be executed under a single label. As I said before He is still a professor at MIT, so I might email him and ask about his thoughts about it after 30 years and if there are implementation examples. I have a feeling it was the basis for the TeaTime synchronization architecture in Croquet.
-
I get rather tired of this type of cop-out. It is basically saying "I won't engage your arguments because I don't want to - I will talk about this!". So I will throw back to you that CAP is not a central idea to pseudo-time or the paper so please stay on topic.
-
Maybe the blind leading the blind at this point but are you saying that you accept that with this approach availability and partition tolerance are satisfied? Assuming the affirmative the issue then is consistency (as defined as "atomic consistency" - a property of a single request/response operation sequence) which is not itself absolutely time constrained and a constraint that data must be seen at the same time. Whos time? EST? GMT? System Time?. How about clock ticks? Is that excluded from being time? So what is the reasoning for a "Translation between pesudo-time and absolute"? In LabVIEW we have "execute when all inputs have been satisfied" (dataflow). Does that violate the first rule?
-
I just reread what you said here and it seems there is a paper written 30 years ago by David P. Reed that debunks that theory if you consider consistency to be able see data at the same pseudo time rather than absolute time. Still getting my head around it though.
-
Won't work on Windows. Only works on Windows Lets see who cares about what
-
why so little love for statecharts
ShaunR replied to MarkCG's topic in Application Design & Architecture
LabVIEW is a Dataflow language rather than Functional Programming. State is implicit rather than explicit and execution is inherently parallel - it is quite a different beast to Functional Programming.That's not to say you don't need a state-machine at some level to control execution. In the LabVIEW world it is usually a sequence engine which is a lot simpler since LabVIEW execution can be represented as a directed graph and that is basically your block diagram. -
why so little love for statecharts
ShaunR replied to MarkCG's topic in Application Design & Architecture
Because state-machines are hard and have to be debugged with witchcraft. So just avoiding the problem means you don't need tools for that problem. -
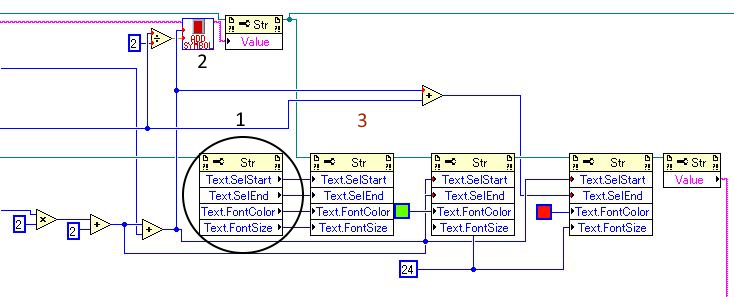
Text control- text color gets reset after char append.
ShaunR replied to Sharon_'s topic in LabVIEW General
Are you sure it's not a sequencing issue? ...... ..... because you need.
-
I think it applies to all projects that have asynchronous processes which is why I'm interested. I don't know how all that works internally. From the initial cursory reading (which may change as I re-read another 20 times ) ) he is generally talking about a journaling system for messages (I think) and using this pseudo time mechanism to resolve contention by what seems to be a slot-scheduling method. Indeed. He has given me the prism and terminology to [succinctly] describe why I am so unhappy with all the frameworks and architectures I see being produced in LabVIEW. However, I'm hoping that this paper, or one of its later incarnations, results in an elegant solution to remote messaging that I have been unhappy about for quite some time.
-
[CR] TaskDialogIndirect (win-api comctl32.dll)
ShaunR replied to peterp's topic in Code Repository (Uncertified)
Nice work. Don't over-reach for a first release. Named pipes for progress bars are a stateful digression from just showing a dialogue. Maybe take stock and put a stake in the ground of where you are - package and clean. Then look at that for version 2. Productionise. Then you can incrementally add features under version control. Just a thought -
I am constantly amazed that some ideas were prescient in hindsight but rejected in their time for more mainstream alternatives. The sands of time covering their bones for an archeologist to piece together later. Luckily, the internet is an excavator I was watching a video called "Is it really "Complex"? Or did we just make it "Complicated" because I've felt for a number of years that the whole idea about using frameworks is really a dead horse flogging exercise because we can't innovate out of a rut. Anyway. During the video there is a throwaway comment that semaphores had a superior alternative called Pseudo Time. Wait. What? Non deadlocking semaphores? Well. Perhaps, perhaps not. The only reference I could find was a paper written in 1978 called Naming and Synchronization in a Decentralized Computer System by David P. Reed. In there he talks about an alternative (NAMOS) to mutual exclusion A.K.A. critical sections around shared resources, rather than semaphores specifically, but the real gold is his definition of the reliable and self recovering synchronisation of unreliable shared resources. In a nutshell, he's talking about synchronising across cloud servers and blockchain forks and any other distributed computational system you care to design - in 1978! This is a bit more than non-deadlocking semaphores, I think. So why am I posting. Well. a) Has anyone ever heard of this or any superseding research (links would be great) and b) Has anyone got any LabVIEW examples?
-
I think quite often new guys/gals don't really know the difference between LabVIEW source code and an image; especially if it is their first foray into programming at all. LabVIEW is just programming with pictures, right? Posting a screenshot is posting code, isn't it? I see all the time old timers posting screenshots. OK, they call them snippets, but they are screenshots and they say it is code, right? edited to add emoticons for Rolf
-
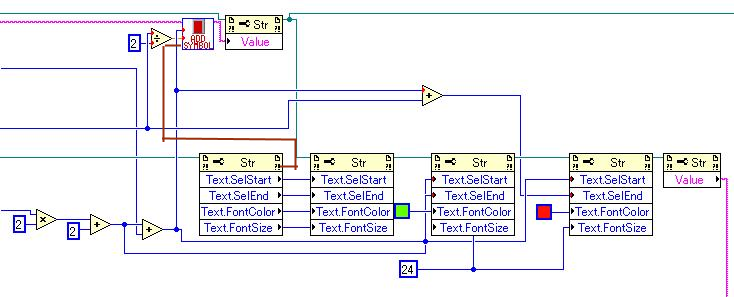
Text control- text color gets reset after char append.
ShaunR replied to Sharon_'s topic in LabVIEW General
Are you sure? From you image, it looks to me that the first text selection node can operate before, during or after the "add symbol" sub VI as LabVIEW decides. -
[CR] TaskDialogIndirect (win-api comctl32.dll)
ShaunR replied to peterp's topic in Code Repository (Uncertified)
If you like wmic you'll love the wmi-delphi-code-creator