ShaunR
-
Posts
5,033 -
Joined
-
Days Won
313
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by ShaunR
-
Whos TCPIP read functions use the tried and tested read length then data like the following? (ShaunR puts his hand up ) What happens if I connect to your LabVIEW program like this? Does anyone use white lists on the remote address terminal of the Listener.vi?

-
Yes Orange="run in UI thread" Yellow="run in any thread" Orange: Requires the LabVIEW root loop. All kinds of heartache here but you are guaranteed all nodes will be called from a single LabVIEW thread context. This is used for non thread-safe library calls when you use a 3rd party library that isn't (thread-safe) or you don't know. If you are writing a library for LabVIEW, you shouldn't be using this as there are obnoxious and unintuitive side effects and is orders of magnitude slower. This is the choice of last resort but the safest for most non C programmers who have been dragged kicking an screaming into do it Yellow: Runs in any thread that LabVIEW decides to use. LabVIEW uses a pre-emptively scheduled thread pool (see the execution subsystems) therefore libraries must be thread-safe as each node can execute in an arbitrary thread context.. Some light reading that you may like - section 9 If you are writing your own DLL then you should be here - writing thread safe ones. Most people used to LabvIEW don't know how to. Hell, Most C programmers don't know how to. Most of the time, I don't know how to and have to relearn it If you have a pet C programmer.; keep yelling "thread-safe" until his ears bleed. If he says "what's that?" trade him in for a newer model It has nothing to do with your application architecture but it will bring your application crashing down for seemingly random reasons. I think I see a JackDunaway NI Days presentation coming along in the not too distant future
-
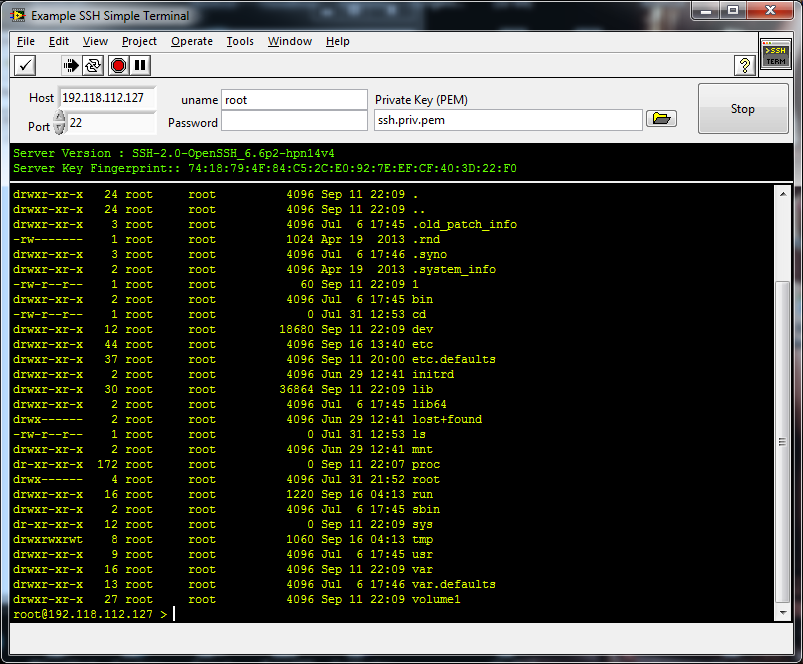
There is a whole thread on LabVIEW and SSH. and one of the posts has your solution Cat is the expert on SSH now I will however reiterate that using a username and password, although exchanged securely, is a lot less desirable than private/public keys. The later makes it impossible to brute force. There is only one real weakness with SSH - verification. When you first exchange verification hashes you have to trust that the hash you receive from the server is actually from the server you think it is. You will probably have noticed that plink asked you about that when you first connected. You probably said "yeah, I trust it" but it is important to check the signature to make sure someone didn't intercept it and send you theirs instead. Once you hit OK, you won't be asked again until you clear the trusted servers' cache so that first time is hugely important for your secrecy.
-
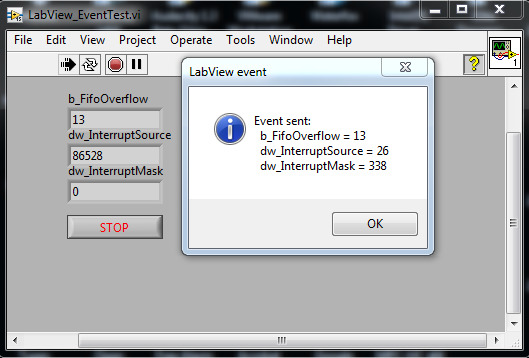
Indeed they are. In fact. It is this that means that the function calls must be run in the root loop (orange node).. That is really, really bad for performance.. If you passed the ref into the callback function as a parameter then you could turn those orange nodes into yellow ones. This means you can just call the EventThread directly without all the C++ threading, (which is problematic anyway) and integrate into the LabVIEW threading and scheduling. The problem then becomes how do you stop it since you can't use the global flag, b_ThreadState, for the same reasons. I'll leave you to figure that one out since you will have to solve it for your use case if you want "Any Thread" operation When you get into this stuff, you realise just how protected from all this crap you are by LabVIEW and why engineers don't need to be speccy nerds in basements to program in it (present company excepted, of course ). Unfortunately, the speccy nerds are trying their damnedest to get their favourite programming languages' crappy features caveats into LabVIEW. Luckily for us non-speccy nerds; NI stopped progressing the language around version 8.x.
-
As if by magic, the shopkeeper appeared. (LabVIEW 64 bit) You getting scared yet, Mr Pate?
-
Answered in a PM.
-
Funny you should mention that. I've just been playing with forward and reverse SSH proxies for the Encryption Compendium for LabVIEW now that it has SSH client capabilities (no cygwin or other nasty Linux emulators ). If you have SSH (or TLS for that matter) you don't need a VPN. If you are thinking about requiring VPN for Remote Desktop then there are flavours of VNC that tunnel over SSH/TLS or use encryption.(disclaimer: haven't used them in anger but know they exist) Once you go for direct TCPIP through TLS or SSH there isn't much of a reason to use a VPN, apart from IP address hiding, since end-to-end doesn't require control over the entire path of the infrastructure to maintain secrecy.
-
 The scientific notation is still not 7 digits. It also looks on the face of it like the precision of doubles is set ti 9 significant digits.rather than 15 decimal places.
The scientific notation is still not 7 digits. It also looks on the face of it like the precision of doubles is set ti 9 significant digits.rather than 15 decimal places. -
A nice workaround for those who don;t have access to TLS and SSH tools.
-
The one outstanding reason to use dynamic loading is you can replace the dependencies without recompiling your DLL (as long as the interface doesn't change). So you can update your driver DLL with a newer version just by overwriting the old one (either manually or with an installer). You will find this a must if you ever piggyback off of NI binaries which change with each release/update. With static bindings it is forever set in stone for that *.lib version until you decide to recompile with the new lib..
-
In a production environment the strategy is network isolation because the engineer has complete control over the devices, infrastructure and users. Where isolation isn't desirable or achievable; VPN seems to be the strategy which requires the company to have complete control over the devices, infrastructure and users. We have already heard from one engineer that uses mobile devices with a web server and no VPN when there is no complete control.and with websockets now stable; mobile devices are being connected to LabVIEW systems without web servers. So it was intended as a leading question.
-
So. Who is using a VPN on their Android or iOS to connect to their LabVIEW software?
-
Does this mean you have never used this method but if you were specifically asked to, then this would be a proposal? Yes. That is clearer. You have a (XML?) protocol that contains security tokens.
-
When you talk of "Package" are you talking about software updates to the cRIO?
-
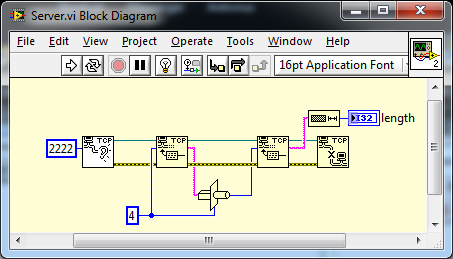
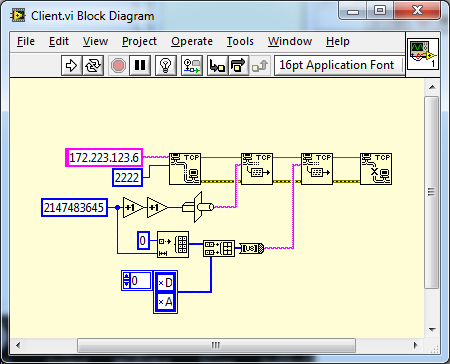
This is demonstrated in the shipped TCPI/IP examples with LabVIEW. You are effectively creating a simple proprietary protocol with a single header field of "Data Length". Transport extends this further by adding a timestamp, encryption and compression flags to the header.
-
cData can be passed as an array of U8 and you avoid all that.
-
A VPN will help to mask your IP and traffic will be encrypted for the entire journey only if both ends are within the VPN network (note I'm not using the phrase "end-to-end" here). If you use a 3rd party, they will potentially have visibility of all traffic so it would be the same trust issue as a cloud service. This probably isn't an option for VxWorks targets as you are pretty much stuck with what NI have installed.
-
Because it is far more pragmatic to remote into (and send data out of) devices in offshore oil rigs than it is to send a survival trained engineer via helicopter.
-
what about for cRIO or PXI?
-
There is an API for interfacing to RDS. As it is a session based system you would need to get the session information and use that to create a unique ID to route your data. Your channel setup process is an almost exact description of the Dispatcher handshake. I notice you have only specified a single connection to a client so I think for network streams the end points are dedicated to either writing or reading so it would be uni-directional only. You are also missing the "dealer" in your description that needs to copy the data to each end-point if there are multiple clients to a single service. That may or may not be a requirement in your case but most of the time it is needed and you might need to consider control contention if multiple clients are to ultimately all have bi-directional or reverse control channels.
-
I've often think about security of my LabVIEW applications but I haven't seen much discussion in the LabVIEW community and almost never see consideration given to securing network communications even at a trivial level. So I am wondering...... What do you do to protect your customers'/companies' data and network applications written in LabVIEW? (if anything). How do you mitigate attacks on your TCPIP communications? What attacks have you seen on your applications/infrastructure? Do you often use encryption? (For what and when?). Do you trust cloud providers with unencrypted sensitive data?
-
You will have to wrap the existing functions too so that you can call them. A better strategy may be to create a separate DLL that just provides a call-back pointer that wraps and invokes the LabVIEW user event. You can then pass the opaque pointer to the existing DLL and get the data in an event structure. You wouldn't need to wrap all the existing functions for pass-through then.
-
You need a diffuse light source and it helps if you put some black tape on the opposite side so it doesn't get washed out by the ambient light. If you do it right, the meniscus should be a lot brighter and you will see the tape change from colour (where there is liquid) to black (where there is air)
-
1. Change the title of the topic to something descriptive of your question. 2. Shine a coloured light up through the base of the column.
-
Turtles and elephants.