ShaunR
-
Posts
5,033 -
Joined
-
Days Won
313
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by ShaunR
-
Holy crap in a cabbage!......Have 500 likes (compressed into one) To celebrate, you can all have data aware controls in the next release of the SQLite API for LabVIEW because I couldn't be bothered with xnodes.but this should work.
-
I chose 1 & 3. I thought that covered the most basic requirements with an offload of decision in strategy to the person who knows more. There is no need to flush a queue if you destroy it and my little queue wrapper means you can just crowbar queues and they get reconstituted if it really was being used. (effectively just clearing it) You will find the lossy/normal and limit choice in the Dispatcher and the queue size transmitted to the Dispatcher so the status could be monitored for each producer to assist the strategy decision (#1) . I never got around to a heartbeat or pinging and fail-over/retrying which was the next on my list (#3) before I got sidetracked by Websockets.. I wouldn't be too concerned about complexity of the API as such. As long as it is a simple interface. Things like heartbeats, pings, bandwidth management and fail-over etc can all be switchable features and completely transparent. Many of those don't make sense if your not traversing the network boundary but your design isn't limited to local processes Can't wait to see where you go with this.
-
OK. So what if a subscriber doesn't unregister but fails to service its queue? Both our systems are reliant on the registration being valid , up to date and the subscriber consuming otherwise messages start piling up. In mine, I have the TCPIP refnum that acts as a notifier for remote subscribers disappearing but locally I have the same problem as I bypass the TCPIP and place directly on subscribers queues like you do. What is your strategy here?
-

Channel Wires (Asynchronous Wires) Discussion
ShaunR replied to AutoMeasure's topic in LabVIEW General
This is something the hierarchy diagram (HD) has needed for a while. The HD could be so much more useful for navigating the architecture - an interface like the Firefox 3D view. It would mean I wouldn't have to visualise the bipyramidal architectures in my head (the flat diamond is all you can see) and give real insight into multi-level state machines. Double click and open a VI diagram.....it'd be great. -
I like this idea. Encryption is demonstrably faster on 64 bit machines than 32. SQLite performance is very disk dependent. There was a benchmark from NI to demonstrate VI call overhead to compare inline, re-entrant and normal which is extremely insightful (not sure where I saw it). There;s the disk performance comparison tests from NI used for benchmarking our SSDs. You've already mentioned Fourier. Sort algorithms are good for assessing computation capability. There used to be an issue with 64 bit labview when allocating memory so something to assess array performance could be used as a proxy for memory efficiency. During investigating the Ring buffer we bench-marked queues and while loops and stuff. Has to be lots around here for you to pull out and formalise into a test suite.
-
OK. So let me clarify some points here. There is a "distributor" which is launched dynamically and acts as the dealer to deal out the messages to a number of "registered" subscribers to that producer. So when you "create" you launch a distributor. The distributor is a permanent consumer for the producer (i.e. it prevents queue fill-up when no subscribers). It also is the "dealer" to multiply messages by copying a message to each subscriber's incoming queue, if and when they appear. So you have a Distributor per publisher that deals messages on a per publisher basis to subscribers. If I'm close in understanding; it might be worth looking at Dispatcher as it sounds like this is an almost identical philosophy where I call the "distributor" a "handler"
-
Channel Wires (Asynchronous Wires) Discussion
ShaunR replied to AutoMeasure's topic in LabVIEW General
Leaving aside "what a wire means" in LabVIEW for now. There are two points I would raise here. If data flow isn't followed. That's not a weakness. That is a consequence of breaking dataflow in a dataflow language.LabVIEW is inherently concurrent and has implicit sequencing but go ahead and use your GO4 templated framework - just don;t come crying to me about needing extra language semantics to get synchronization back again for an architecture where you've specifically chosen to remove what the language gave you. I spend a lot of my time writing little bits of code to remove wires. I remove them for three reasons. 1) Modularity-I can just plonk the VI on any number of diagrams and it will just work (get rid of init, do something, deinit). 2) Break dataflow - Encapsulate events, for example, into an API where each call is atomic and refnum free. 3) Diagram readability-More of a side effect. I feel the example they show is rather contrived. Most of the time I would use such a system in different VIs because of 1&2 Generally I want to share data between processes, not individual while loops. Then the whole idea showing where the data comes from with a wire becomes moot and it is no different to what I usually use.....except more complex to create,, it seems. That said. I haven't played fully yet. So I am open to being convinced with a killer application of them. -
Channel Wires (Asynchronous Wires) Discussion
ShaunR replied to AutoMeasure's topic in LabVIEW General
Woah, there pardner. Apart from giving you many ways to confuse and shoot yourself and others in the foot. What problem do these "asynchronous wires" solve, exactly? At first glance, it looks to me like a solution looking for a problem. -
FTFY
-
This is desirable in my apps too. I created a queue wrapper (umpteen years ago) that ensures there is always exactly one of any queue and is created when any queue function is called thereby removing the Init, Do Something. Destroy overhead and memory runaway from creating refs. Destroying the queue merely has the effect of clearing the queue which is reconstituted on the next call, Queue.vi
-
I gave you closure; move on. The List is here by the way.
-
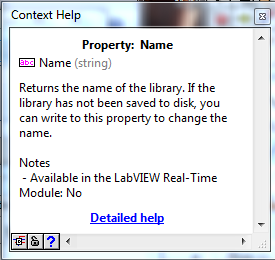
LabVIEW Real-Time VI Property Node throws Error Code 1
ShaunR replied to PLeVasseur's topic in Real-Time
Available in the LabVIEW Real-Time module: No (Hover your mouse of the name property)
-
Attached is a tentative alpha for 2.0.0. As much as I hate the alpha and beta philosophy, I only have one test device so I am not comfortable in fully releasing as it may be tuned to that one device. I usually pull products I cannot adequately test; the choice was an alpha release or remove it completely and put it back in my "cool stuff for me" toolbox. But I said I would do something so lets see if we can get this usable for most people with a view to a release proper. Oh. And I changed the licence to a much more amenable BSD3 .OPP 2.0.0-ALPHA.zip Of course, if you want to send me lots and lots of bluetooth enabled phones, I'll happily support them
-
Any cool new features of LabVIEW or toolkit?
ShaunR replied to doradorachan's topic in LabVIEW General
I can see it fine. -
Any cool new features of LabVIEW or toolkit?
ShaunR replied to doradorachan's topic in LabVIEW General
Here are the upgrade notes that detail the new features. I don;t see anything in there about loading block diagrams in different versions, though. -
Sweet. Check back next week for version 2.0.0.
-
OK. Figured it out. The spec has changed quite a lot over the 5 or so years since it was written-damned progress I've got it working now with some non trivial changes i.e. it works but is a mess and it needs refactoring. So my question is what is your timeline for this? Do you need it by tomorrow, by the weekend? By next month? By next year?
-
Stream a VI file across a network
ShaunR replied to John Lokanis's topic in Application Design & Architecture
Set the prepend array size to false on the Binary Write -
Touche
-
I imagined you writing that with exactly the look you have in your avatar ...lol.
-
Synchronous to what? Do you mean adheres to the LabVIEw dataflow that you broke with your free asynchronous messaging?
-
Debugging them isn't free though
-
That's why I like the idea of an event on automatic error handling. You can still use the cluster, in fact, you would use the cluster to handle local error and recovery as per usual,if required. There may be a tiny overhead only when a listener is attached but since people nowadays seem to be throwing messages around like confetti; I don;t think they can complain about a couple of really useful ones when something goes wrong..
-
APIs, quickdrop and most of the other stuff isn't language.Sure. There's a few good toolkits, and primitives that have been added over time but even the language aspects that you've listed; e.g classes and DVRs and most of the others are between 5 and 10 years old (2005 for classes?) and pretty much all the other stuff with a very small number of exceptions is in 2009 (QD, DVR, bluetooth, XML, Web services, Shared variables and yes, dynamic user events) and those that aren't I have solutions for. Conditional tunnels and network streams I might give you but none of what you are talking about is project busting technology. Where's the inheritable FP controls? Where's the event driven VISA? Where's the inheritance that actually inherits methods and properties without recreating them? (I'm looking at you x-controls ). Where's the thousands of events to choose from in the event structure (maximise, minimise, open etc).. Why are there still bugs from 8.x? Perhaps I'm being harsh. It's probably because I've looked every year at upgrading on a wave of enthusiasm. Then I weigh project risk vs features I might actually use it seems there are too few pros once the eye candy is taken out. Upgrade to LV2013 because of a JSON primitive? Almost did but it was a real pain to use than the open source one, so back to 2009.
-
Don't be too sure. Not much has changed in the language since, probably, the event structure-maybe xcontrols etc. It's one of the reasons I still program in 2009. Recent updates have had some very low hanging fruit when it comes to new features. It's almost as if they are afraid to touch the core. When AQ talks about things nowadays it is generally a user framework of some description. Serialisation, for example, should have been handled by the flatten primitives but AQ came up with the Character Lineator instead (can you serialise objects properly now?). If an error system does come forth, it is likely to be specific to the Actor Framework or some other marotte du jour and require obnoxious compromises when used outside of the framework. That is the fate of all tactical solutions IMO. They can already catch errors at the VI boundary with the Automatic Error Handling and exposing an in-built event in the event structure would be extremely useful. If it could also broadcast and bubble through the hierarchy you would also have a strategy similar to other languages and you wouldn't have to code anything except filtering in the handler and how you react to the events. Additionally it would be completely backwards compatible.