
LogMAN
-
Posts
656 -
Joined
-
Last visited
-
Days Won
70
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by LogMAN
-
-
Edit: Nevermind, I misread your post 😄
21 minutes ago, Gribo said:What is the difference between these two methods? If a .NET library is included in a project, does LV load it before the VI is run?
In order for LabVIEW to know about all dependencies in a project, it has to traverse all its members. Because this operation is slow, it probably keeps references open for as long as possible. I'm not sure why it would unload the assembly in standalone, but that is how it is.
-
There is something strange about how this library is managed. For some reason it seems to work if the VI is part of a project, but not as a standalone VI.
Standalone
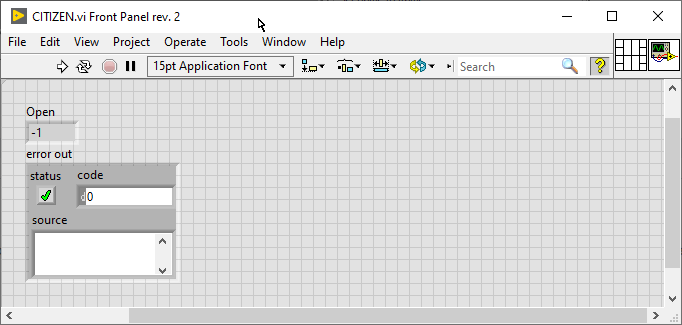
As part of a project
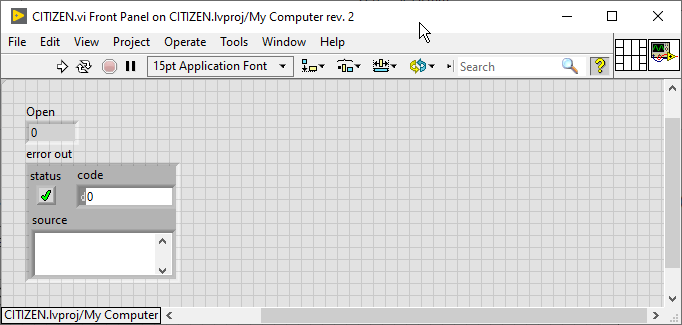
I did not reproduce the entire example, so it might fail. At least you can try adding your VI to a project and see if it works (make sure the assembly is listed under Dependencies).
-
 2
2
-
-
I was wondering why it wasn't documented, now I know 😄
-
2 hours ago, drjdpowell said:
Support for writing multiple rows in this manner is on the Roadmap, but not yet existing, partly because I am debating multiple options:
- A new function, "Execute SQL Multiple Times", that takes a parameter input of arrays of clusters or a cluster of arrays and does multiple executions of one SQL statement.
- Integrating it into the existing "Execute SQL" node.
- Upping the LabVIEW version to 2017 and introducing a new VIM version of either (1) or (2).
1+3 makes the most sense in my opinion. And it should be limited to a single SQL statement (or multiple statements if they use absolute parameter bindings like "?NNN").
Perhaps it also makes sense to apply that limitation to Execute SQL, because it can get very confusing when executing multiple statements in a single step with parameters that include arrays. For example, what is the expected outcome of this?
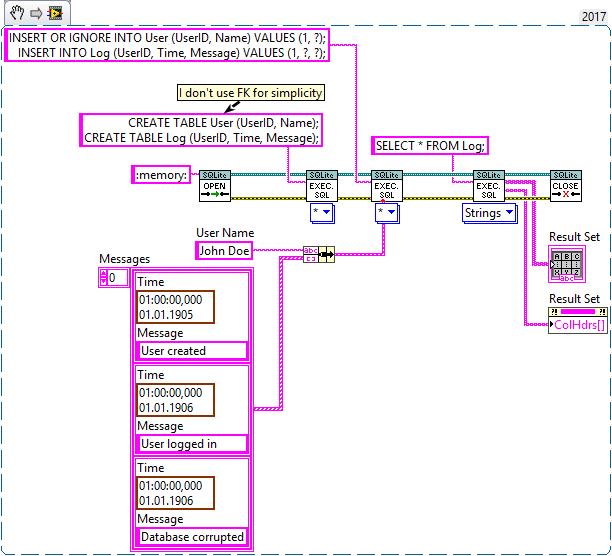
I could be mislead into thinking that the user name only applies to the first SQL statement and the array to the second, or perhaps that it uses the same user name multiple times while it iterates over each element of the array, but that is not how it works.
Right now it produces empty rows 😟
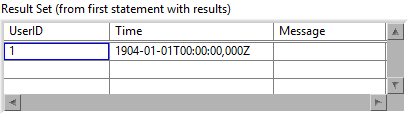
With my fix above, it will produce exactly one row 🤨
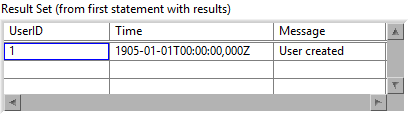
By executing the statement over-and-over again until all parameters are used up (processed sequentially), it will insert data into wrong places 😱
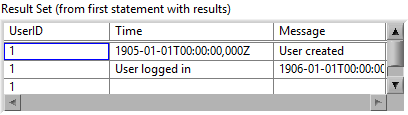
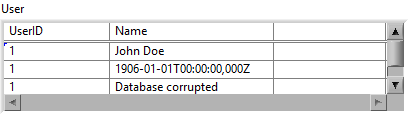
In my opinion it should only accept
a) an array of any type, each element of which must satisfy all parameter bindings.
b) a cluster of any type, which must satisfy all parameter bindings.
c) a single element of any type.In case of a or b, subarrays are not allowed (because a subarray would imply 3D data, which is tricky to insert into 2D tables).
That way I am forced to write code like this, which is easier to comprehend in my opinion:
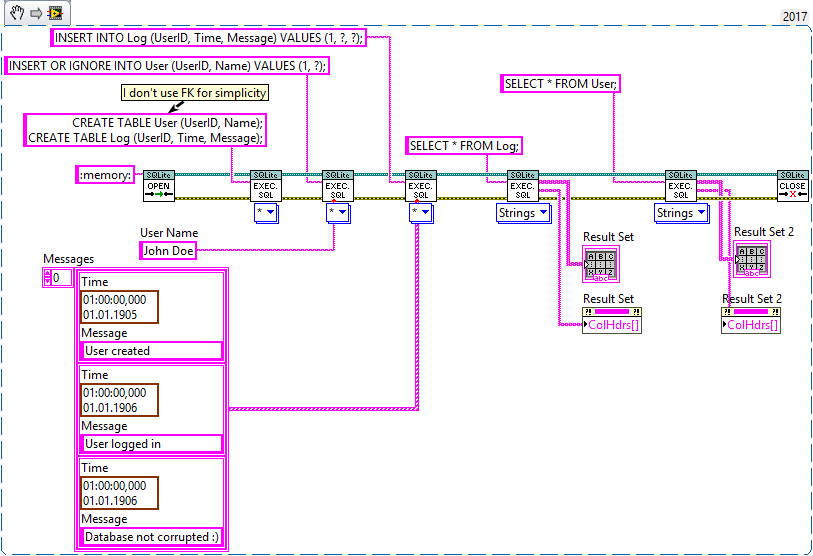
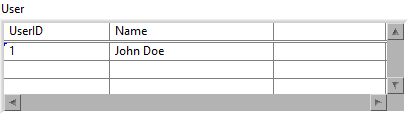
This is the expected output:
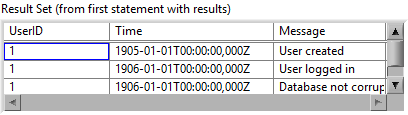
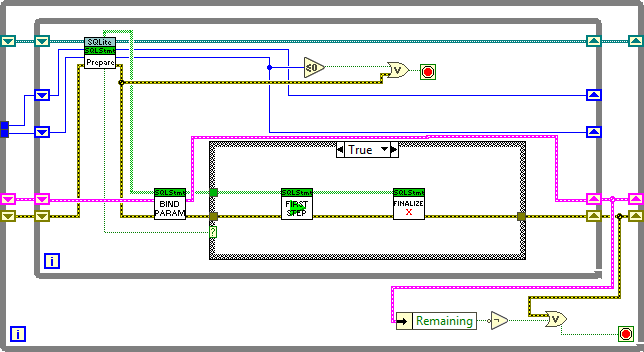
Here is what I did to Execute SQL (in addition to the fix mentioned before):
-
2 hours ago, mramsdale said:
1) Can parameters be used for writing multiple rows to a table? (rather than the step method)
Guessing the answer is to use a loop for multiple parameter values.
I think you already answered your own question. Each statement only affects a single row, which means you have to wrap arrays in loops. Don't forget that Execute SQL can handle multiple statements at once. This is shown in one of the examples:
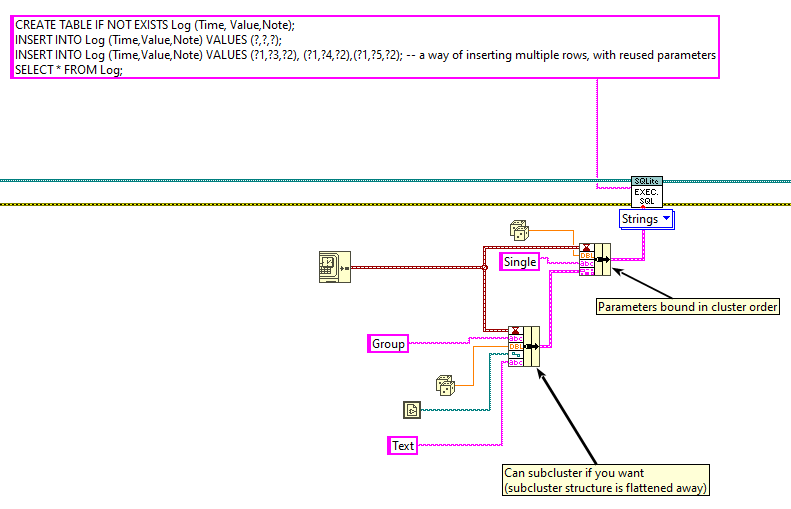
Note that there are multiple statements that utilize the same input cluster.
2 hours ago, mramsdale said:I can parameter input one row, using two strings, and it works, relatively intuitive. But I was hoping this could be used to enter multiple rows too, without loops to pull from an array and then separate into strings or insert into clusters. (Feeling greedy am I)
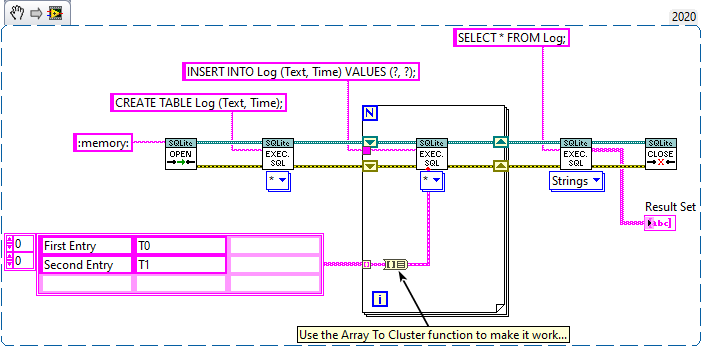
You could use the Array To Cluster function to simplify the task:
 3 hours ago, mramsdale said:
3 hours ago, mramsdale said:2)I'm guessing the one row array doesn't work as the datatype is not an array, and there are two fields but only one array (datatype). Does this sound more or less correct?
You are on the right path. In this case Execute SQL will report an error because only arrays of clusters are allowed:
QuoteSQLite.lvlib:SQL Statement.lvclass:Parse Parameters (Core).vi:6060003<ERR>
Unable to Bind Array of Type: "String"Please take the following section with a grain of salt, I make a few assumptions based on my own findings.
@drjdpowell It would be great to have an example of how Arrays of Clusters are supposed to work.
I opened the source code and it looks like it is supposed to take an array of cluster and iterate over each element in the order of appearance (as if it was a single cluster). So these will appear equivalent (The "Text" element of the second cluster is used for the 'Reason' field in this example):
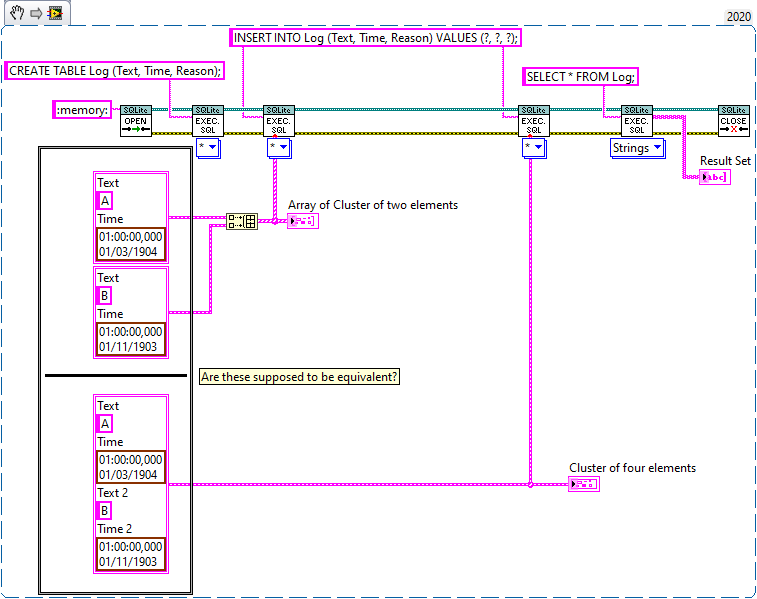
However, in the current version (1.12.2.91) this doesn't work at all. The table returns empty. I had to slightly change Parse Parameters (Core) to get this to work:
Before:
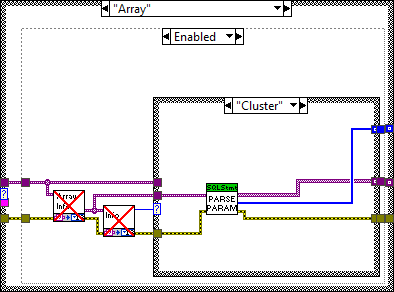
Note that it parses the ArrayElement output of the GetArrayInfo VI, which only contains the type info but no data.
After:
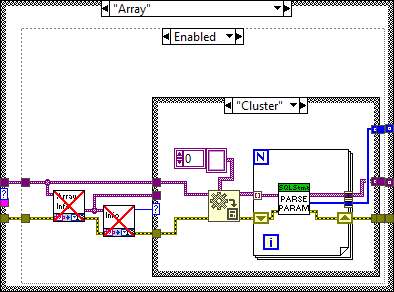
This will concatenate each element in the array as if it was one large cluster.
Perhaps I'm mistaken on how this is supposed to work?
-
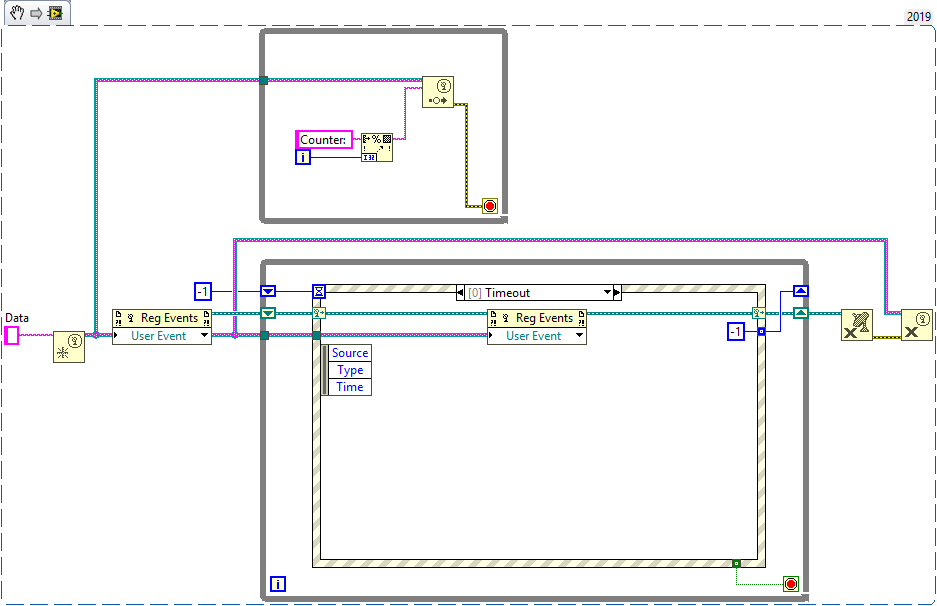
+1 for flushing the event queue.
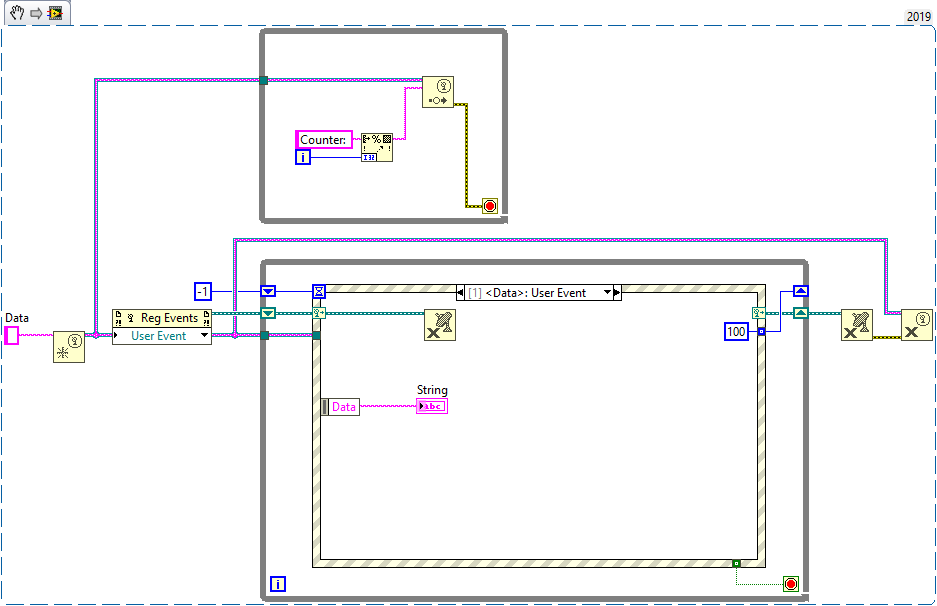
Here is another solution that involves unregistering and re-registering user events.
Whenever the event fires, the event registration is destroyed. At the same time it sets the timeout for the timeout case, which will re-register the event and disable the timeout case again.This could be useful in situations where the consumer runs much (order of magnitudes) slower than the producer, in which case it makes sense to reconstruct the queue every time the consumer desires a new value. I haven't done any benchmarks, nor used it in any real world application so far, but it works.
-
10 hours ago, Neil Pate said:
No need to apologise, it did not come across like that at all.
There is no rule that says you have to update your entire GUI every time a big chunk of data comes in. Its perfectly ok to have the GUI consumer react to the "data in" type event and then just ignore it if its not sensible to process. Assuming your GUI draw routines are pretty fast then its just about finding the sweet spot of updating the GUI at a sensible rate but being able to get back to processing (maybe ignoring!) the next incoming chunk.
That said, I normally just update the whole GUI though! I try and aim for about 10 Hz update rate, so things like DAQ or DMA FIFO reads chugging along at 10 Hz and this effectively forms a metronome for everything. I have done some work on a VST with a data rate around 100 MS/s for multiple channels, and I was able to pretty much plot that in close to real-time. Totally unnecessary, yes, but possible.
My consumers also tend to update the whole GUI if it doesn't impact the process negatively (it rarely does). I was looking for a solution that doesn't require each consumer to receive their own copy in order to save memory. But as @Bhaskar Peesapati already clarified, there are multiple consumers that need to work lossless, which changes everything. Discarding events will certainly prevent the event queue to run out of memory. I actually have a project where I decided to use the Actor Framework to separate data processing from UI and which filters UI update messages to keep it at about 10 Hz. Same thing, but with a bunch of classes. I'm pretty sure there are not many ways to write more code for such a simple task 😅
-
6 hours ago, Bhaskar Peesapati said:
Looks like you do not like to use DVRs. I read and write to DVR as property in a class in the following way only. Do you still think I am might run into problems. If so what do you suspect. The write or SET happens only in open place.
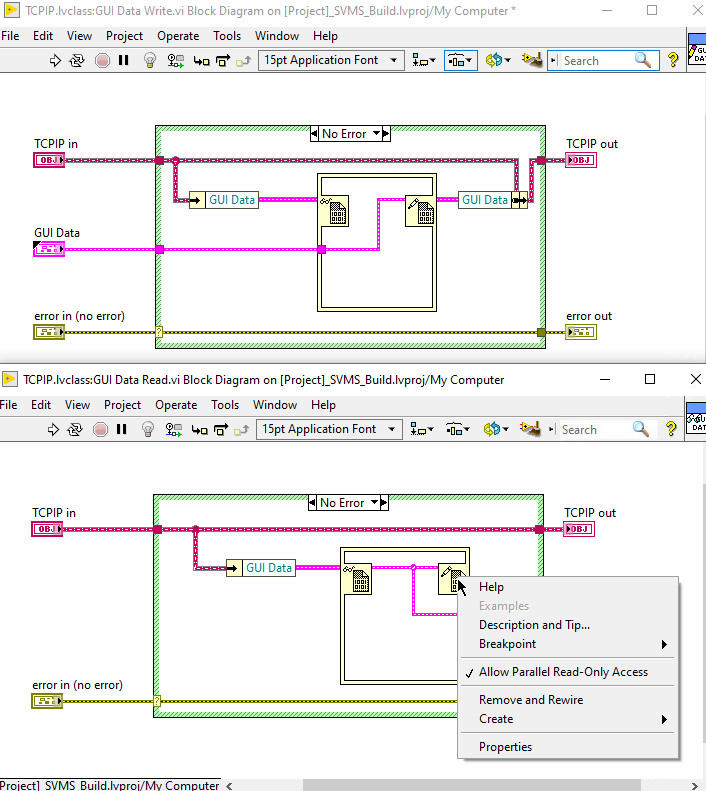
I have only one project that uses multiple DVRs to keep large chunks of data in memory, which are accessed by multiple concurrent processes for various reasons. It works, but it is very difficult to follow the data flow without a chart that explains how the application works.
In many cases there are good alternatives that don't require DVRs and which are easier to maintain in the long run. The final decision is yours, of course. I'm not saying that they won't work, you should just be aware of the limitations and feel comfortable using and maintaining them. For sure I'll not encourage you to use them until all other options are exhausted.
1 hour ago, Neil Pate said:At some point any architecture is going to fall over even with the biggest buffer in the world if data is building up anywhere. User Events or queues or whatever, if you need lossless data it is being "built up" somewhere.
I agree. To be clear, it is not my intention to argue against events for sending data between loops. I'm sorry if it comes across that way.
My point is that the graphical user interface probably doesn't need lossless data, because that would throttle the entire system and I don't know of a simple way to access a subset of data using events, when the producer didn't specifically account for that.
-
 1
1
-
-
37 minutes ago, Bhaskar Peesapati said:
All consumers will listen only for 'NeDataAvailable' trigger and all of the events can read from the same DVR.
This will force your consumers to execute sequentially, because only one of them gets to access the DVR at any given time, which is similar to connecting VIs with wires.
You could enable Allow Parallel Read-only Access, so all consumers can access it at the same time, but then therewill becould be multiple data copies.37 minutes ago, Bhaskar Peesapati said:My requirement is that I process all data without loss. This means I need to have multiple queues. That means 12 MB * # of of consumers is the data storage requirement. With 1 DVR that will be 12 MB storage plus 1 byte to indicate to consuming events that new data is available.
Have you considered sequentially processing?
Each consumer could pass the data to the next consumer when it is done. That way each consumer acts as a producer for the next consumer until there is no more consumer.
It won't change the amount of memory required, but at least the data isn't quadrupled and you can get rid of those DVRs (seriously, they will hunt you eventually). -
1 hour ago, Neil Pate said:
No, not at all. My producers just publish data onto their own (self-created and managed) User Event. Consumers can choose to register for this event if they care about the information being generated. The producer has absolutely no idea who or even how many are consuming the data.
Okay, so this is the event-driven producer/consumer design pattern. Perhaps I misunderstood this part:
20 hours ago, Neil Pate said:The trick is to have multiple events so that processes can listen to just those they care about.
If one consumer runs slower than the producer, the event queue for that particular consumer will eventually fill up all memory. So if the producer had another event for these slow-running consumers, it would need to know about those consumers. At least that was my train of thought 🤷♂️😄
-
15 hours ago, Neil Pate said:
I exclusively use events for messages and data,even for super high rate data. The trick is to have multiple events so that processes can listen to just those they care about.
Doesn't that require the producer to know about its consumers?
14 hours ago, Bhaskar Peesapati said:In the case of using queues how can I ensure that the process which is removing the element does not run before other processes have worked on the current element. TCPIP process is like display process.
You don't. Previewing queues is a lossy operation. If you want lossless data transfer to multiple concurrent consumers, you need multiple queues or a single user event that is used by multiple consumers.
If the data loop dequeues an element before the UI loop could get a copy, the UI loop will simply have to wait for the next element. This shouldn't matter as long as the producer adds new elements fast enough. Note that I'm assuming a sampling rate of >100 Hz with a UI update rate somewhere between 10..20 Hz. For anything slower, previewing queue elements is not an optimal solution.
-
1 hour ago, Bhaskar Peesapati said:
Essentially what your are saying is only one loop dequeues and other loops only examine the element and perform necessary operations on it. That way only one queue is necessary.
That is correct. Since the UI loop can run at a different speed, there is no need to send it all data. It can simply look up the current value from the data queue at its own pace without any impact on one of the other loops.
1 hour ago, Bhaskar Peesapati said:The data block is in a DVR so there is only one copy the data block.
How is a DVR useful in this scenario?
Unless there are additional wire branches, there is only one copy of the data in memory at all times (except for the data shown to the user). A DVR might actually result in less optimized code.
1 hour ago, Bhaskar Peesapati said:In the case of events, The producer triggers the event to indicate new data is present and the consumers process the data. Is there a drawback in this.
Events are not the right tool for continuous data streaming.
- It is much more difficult to have one loop run at a different speed than the other, because the producer decides when an event is triggered.
- Each Event Structure receives its own data copy for every event.
- Each Event Structure must process every event (unless you want to fiddle with the event queue 😱).
- If events are processed slower than the producer triggers them, the event queue will eventually use up all memory, which means that the producer must run slower than the slowest consumer, which is a no-go. You probably want your producer to run as fast as possible.
Events are much better suited for command-like operations with unpredictable occurrence (a user clicking a button, errors, etc.).
-
Welcome to Lava!
The loops in both of your examples are connected with Boolean wires, which forces them to execute sequentially. This is certainly not what you want. Also, both examples are variations of the Producer/Consumer design pattern.
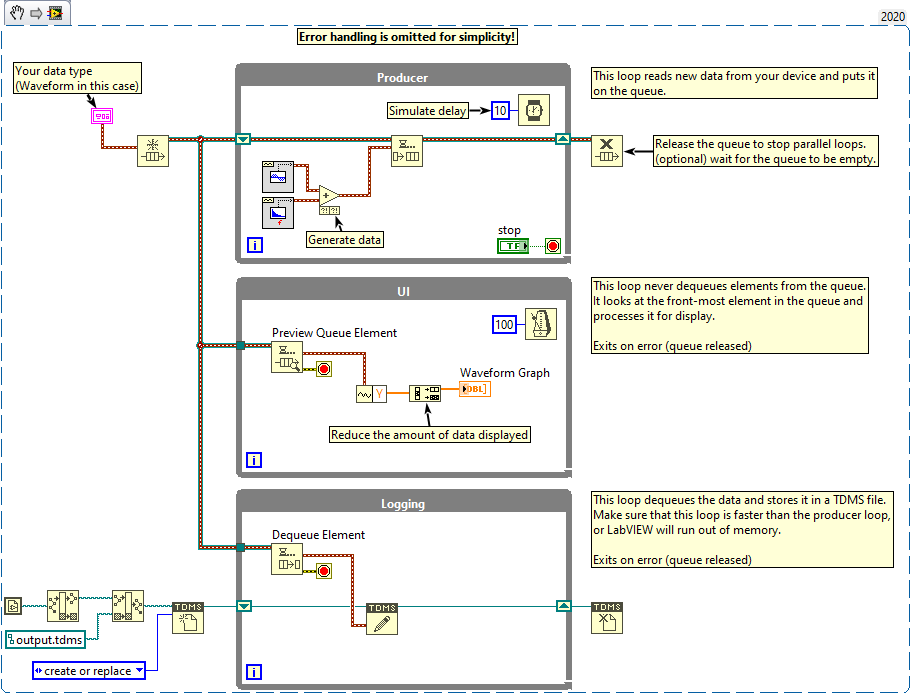
You probably want to store data lossless, so a queue is fine. Just make sure that the queue does not eat up all of your memory (storing data should be faster than capturing new data). Maybe use TDMS files for efficient data storage. Use events if you have a command-like process with multiple sources (i.e. the UI loop could send a command to the data loop to change the output file).
Displaying data is very slow and resource intensive. You should think about how much data to display and how often to update. It is probably not a good idea to update 24 MB worth of data every second. A good rule of thumb is to update once every 100 ms (which is fast enough to give the user the impression of being responsive) and only show the minimum amount of data necessary.
In this case you could utilize the data data queue and simply check for the next value every 100 ms, then decimate and display the data. Here is an example:
-
You need to take time zones into account (UTC+14:00 in your case).
By default the Scan From String function returns time stamps in local time if you use the "%<>T" format specifier. This is mentioned under section Format Specifier Examples, here: https://zone.ni.com/reference/en-XX/help/371361R-01/lvconcepts/format_specifier_syntax/
You'll get the right response if you use the "%^<>T" format specifier: "%[+-]%^<%H:%M>T"
-
You have to install at least the LabVIEW Runtime Environment for your particular version of LabVIEW and any dependencies. Otherwise you'll receive many error messages.
The best way to go about it is to add a build specification for an installer to your LabVIEW project, with which you can distribute your application and any dependencies in one package. It will produce an installer for your application. Here is a KB article that explains the process: https://knowledge.ni.com/KnowledgeArticleDetails?id=kA00Z0000019PV6SAM
Additionally, you can include MAX configurations from your machine and have them automatically installed on the target machine. Here is a KB article that explains the process for custom scales: https://knowledge.ni.com/KnowledgeArticleDetails?id=kA00Z0000019MvuSAE
There is probably a better source for this, but ni.com is down for maintenance right now... 😱
-
1
-
-
36 minutes ago, brownx said:
Probably I'll use named queue instead
1 hour ago, brownx said:So I have Labview 1-->Teststand --> Labview2 and the two Labviews are separated (like two different executable is).
Named queues will only work in the same instance of LabVIEW. If there are two instances, those queues are isolated from each other (labview1 and labview2 don't share their address space), which means you need inter-process communication.
@drjdpowell If I remember correctly, the Messenger Library has built-in network capabilities, right?
-
From what we have discussed so far, the Messenger Library certainly seems to be a perfect fit. It'll provide you with the infrastructure to run any number (and type) of workers and communicate with them in a command-like fashion. It is, however, a much more advanced framework than the simple message handler from my examples. As such, it will take more time to learn and use properly.
1 hour ago, brownx said:this stuff will be used by Labview programmers - they need to be able to maintain it, slightly modify it to taylor it to their needs.
As someone who enjoys the company of technicians who get scared by things like "classes" (not to mention inheritance 🙄), I strongly suggest to evaluate the skill levels of your maintainers before going too deep into advanced topics. If nobody has the skills to maintain the solution, you could just as well do it in C++. Perhaps you can include them in the development process? This will make the transition much easier and they know what is coming for them. If they also do some programming, they have nobody to blame 😉
@drjdpowell already mentioned his videos on YouTube. I really suggest you watch them in order to understand the capabilities of the Messenger Library

Here is also a link with more information for the message handler in my examples (sorry no video, +1 for the Messenger Library): http://www.ni.com/tutorial/53391/en/
-
1
-
1
-
-
1 hour ago, brownx said:
It's not opensource is it? :))
Sorry, it is not 😄
-
6 hours ago, brownx said:
Not that much - around 110 Booleans basically (digital IO's) and less than 10 analog (double) per hardware.
Since I have less than 64 inputs and 64 outputs I can even use a 64 bit unsigned for Inputs and another for Outputs and deal with the "BOOL" on the reader side with number to bool array.You are trying to optimize something that really isn't a bottleneck. Even if each bit was represented by a 8-bit integer, the total size of your data is less than 200 Bytes per hardware. Even with 100 devices (hardware) only 20 KB of memory is needed for all those inputs and outputs (analog and digital). In the unlikely event that there are 1000 consumers at the same time, each of which have their own copy, it will barely amount to 20 MB...
As a C/C++ programmer I feel the urge for memory management, but this is really not something to worry about in LabVIEW, at least not until you hit the upper MB boundary.
6 hours ago, brownx said:Since the HW responds anyway with all his IO's packed into one response probably it's much easier to do a "get everything" and than just mask the bit or bits at the other end.
It might seem easier at first glance, but now all your consumers need to know the exact order of inputs and outputs (by index), which means you need to update every consumer when something changes. If you let the worker handle it, however, (i.e. with a lookup table) consumers can simply "address" inputs and outputs by name. That way the data structure can change independently. You'll find this to be much more flexible in the future (i.e. for different hardware configurations).
6 hours ago, brownx said:I also need a background loop too which does maintenance stuff so it's not enough to be completely on demand (exp. one of the inputs usually is Abort which stops everything).
I'd probably use another worker that regularly (i.e. every 100 ms) polls the state of the desired input and sends the stop signal if needed.
6 hours ago, brownx said:Probably the easiest way to go is to do a worker to feed the notifier with real hw data on every 50msec, in this case I don't even need read io command since a complete read will be performed anyway periodically.
The only setback of this would be that a read IO 1 would wait for maximum 50 msec (or less).That, and the fact that the worker has to poll continuously even if there is no consumer. It is also not possible to add new features to such a worker, which can be problematic in case someone needs more features...
6 hours ago, brownx said:The only thing which will be a pain is the interrupt IO's - I'll have to deal with them somehow but I will figure it out - probably I can deal with that in the background reader ...
Suggestion: Keep them in a separate list as part of the worker. For example, define a list of interrupt IOs (addresses) that the worker keeps track of. On every cycle, the worker updates the interrupt state (which is a simple OR condition). Consumers can use a special "read interrupt state" command to get the current state of a specific interrupt (you can still read the regular input state with the other command). When "read interrupt state" is executed, the worker resets the state.
Now that I think about it, there are quite a few things I might just use in my own I/O Server... 😁
-
1 hour ago, brownx said:
You are suggesting that instead of the data references I should use a notifier reference?
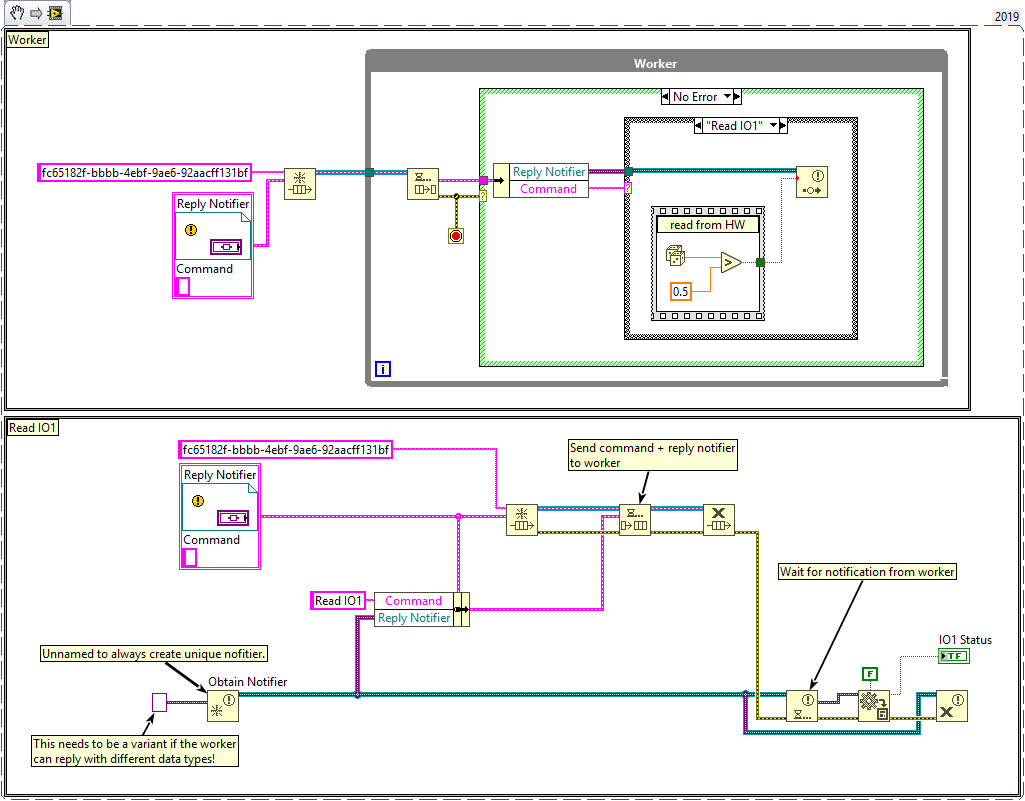
Yes, either notifier or queue. You can store the notifier reference, or give the notifier a unique name (i.e. GUID), which allows you to obtain an existing notifier by name if it already exists in the same address space (application). Here is an example using notifiers:
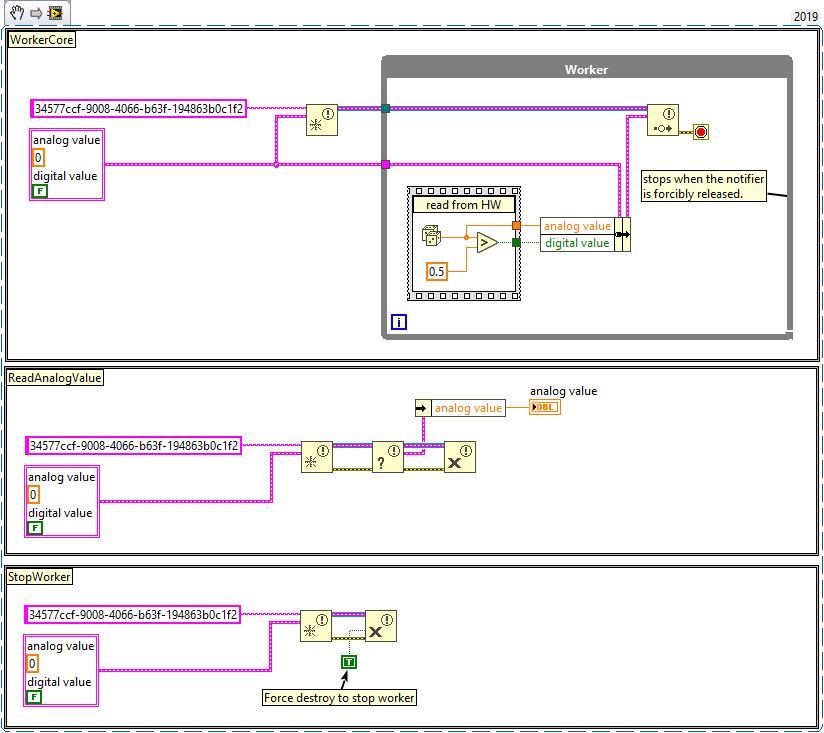
Queues work the same way.
1 hour ago, brownx said:As far as I understand the notifier can send notification of a value changed (and keep the last change only) but it will not provide me a way to "read IO1" unless I keep the last value on a local variable on the receiver end in the persistent vi.
Either your notification always contains the value for "read IO1", in which case the latest value also contains it, or you need to inform the worker about which channel to read. For example, by sending a message to your worker that includes the desired channel name, as well as a reply target. For things like this, the Queued Message Handler template (included with LabVIEW) or the Messenger Library are probably worth looking into.
 1 hour ago, brownx said:
1 hour ago, brownx said:Thus I will still end in mirroring the data in the background, the only difference is that I will not loop continuously but rather run only when something changed, right? Sort of event based programming instead of continuous loops.
How much data are we talking about?
Yes, there is some copying going on, but since the data is requested on-demand, the overall memory footprint should be rather small because memory is released before the next step starts. If you really need to gather a lot of data at the same time (i.e. 200 MB or higher), there is the Data Value Reference, which gives you a (thread safe) reference to the actual data. DVRs, however, should be avoided whenever possible because they limit the ability of the compiler to optimize your code. Not to mention breaking dataflow, which makes the program much harder to read...
-
Sorry, I'm not familiar with TestStand. I'd assume that there is some kind of persistent state and perhaps a way to keep additional code running in the background, otherwise it wouldn't be very useful. For example, it should be possible to use Start Asynchronous Call to launch a worker that runs parallel to TestStand and which can exchange information via queues/notifiers whose references are maintained by TestStand (and that are accessible by step scripts). In this case, there would be one step to launch the worker, multiple steps to gather data, and one step to stop the worker.
Maybe someone with more (any) experience in TestStand could explain if and how this is done.
-
Oh I see, my first impression was that the issue is about performance, not architecture.
Here are my thoughts on your requirements. I assume that your hardware is not pure NI hardware (in which case you can simply use DAQmx).
34 minutes ago, brownx said:- a generic API (sort of a driver interface) which can deal with two-three types of hardware, 1-10 of each (TCP/IP, UDP or serial connected). This might scale later.
- all this HW is polling type (no async events in the communication)Create a base class for the API (LabVIEW doesn't have interfaces until 2020, a base class is the closest thing there is). It should have methods to open/close connections and read data. This is the Read API.
For each specific type of hardware, create a child class and implement the driver-specific code (TCP/IP, UDP, serial).
Create a factory class, so that you can create new instances of your specific drivers as needed. The only thing you need to work out is how to configure the hardware.
I can imagine using a VISA Resource Name (scroll down to VISA Terminology) for all drivers, which works unless you need to use protocols that VISA doesn't support (TCP/IP, UDP, and serial are supported though). Alternatively create another base class for your configuration data and abstract from there.Of course, the same should be done for the Write API.
35 minutes ago, brownx said:- the inputs are mostly digital or analog type, the outputs are digital
The easiest way is to have two methods, one to read analog values and one to read digital values. Of course, hardware that doesn't support one or the other will have to return sensible default values.
Alternatively, have two specific APIs for reading analog/digital values. However, due to a lack of multiple inheritance in LabVIEW (unless you use interfaces in 2020), hardware that needs to support both will have to share state somehow.
35 minutes ago, brownx said:- some of the inputs once became active have to be kept active until first read even if they go inactive meantime (sort of an interrupt, HW is prepared to do this, SW has to be as well)
It makes sense to implement this behavior as part of the polling thread and have it cache the data, so that consumers can access it via the API. For example, a device reads all analog and digital values, puts them in a single-element queue and updates them as needed (dequeue, update, enqueue). Consumers never dequeue. They only use the "Preview Queue Element" function to copy the data (this will also allow you to monitor the last known state). This is only viable if the dataset is small (a few KB at most).
32 minutes ago, brownx said:- the data will have multiple consumers (same data too) and I need a "last known value" support at any time to any of the data
- due to high debug demand I also need to "cache" the outputs (last known value which was sent to the HW)Take a look at notifiers. They can have as many consumers as necessary, each of which can wait for a new notification (each one receives their own copy). There is also a "Get Notifier Status" function, which gives you the latest value of a notifier. Keep in mind, however, that notifiers are lossy.
-
3 hours ago, brownx said:
Tried to use arrays of data, arrays of clusters, than arrays of classes and with all of them my problem was the multiple data copies while I am doing a single operation (one input change causes a copy of the whole array of all inputs or clusters or classes). Thought about functional variables too but that is hard to scale (with my current labview experience).
Arrays of clusters and arrays of classes will certainly have a much higher memory footprint than an array of any primitive type. The amount of data copies, however, depends on your particular implementation and isn't affected by the data type. LabVIEW is also quite smart about avoiding memory copies: https://labviewwiki.org/wiki/Buffer_Allocation
Perhaps, if you could show the particular section of code that has high memory footprint, we could suggest ways to optimize it.
3 hours ago, brownx said:So I decided to use references - the basic idea is below - it it a valid one ore I try to push my luck with something not recommended?
I don't want to be mean, but this particular approach will result in high CPU usage and low throughput. What you build requires a context switch to the UI thread on every call to one of those property nodes, which is equivalent to simulating keyboard presses to insert and read large amounts of data. Not to mention that it forces LabVIEW to copy all data on every read/write operation... Certainly not the recommended way to do it 😱
3 hours ago, brownx said:Also I would like to know the granularity of Labview in the sense of reference variables (Ref_DataIn and his elements in the case below) - do I need to sync the read and write of the values or it is good as it is?
You don't need to sync read and write for property nodes, they are thread safe.
3 hours ago, brownx said:I would like to avoid reading the Value while the data acquisition loops write it - it is not a problem if I read an array half old, half new values but it is a problem if I read empty array or half array when this kind of collision occurs.
Have no idea how this works in Labview - in C/C++ I would need to sync it.Do you really need to keep all this data in memory in large chunks?
It sounds to me as if you need to capture a stream of data, process it sequentially, and output it somewhere else. If that is the case, perhaps the producer/consumer template, which comes with LabVIEW, is worth looking into.
-
If we are talking about automating factories, isn't Factorio the game of choice, rather than Minecraft? 😋
-
1
-
.NET: Citizen.LayoutUtilities.Printing - Controller.Open() open fails
in Calling External Code
Posted
Here is an interesting note: How LabVIEW Locates .NET Assemblies - National Instruments (ni.com)