drjdpowell
-
Posts
1,986 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by drjdpowell
-

Date/Time To Seconds Function and Daylight Savings
drjdpowell replied to rharmon@sandia.gov's topic in LabVIEW General
That's right. And make sure you test your code as it changes to/from Summer Time, as that is where once a year bugs can happen. -
Date/Time To Seconds Function and Daylight Savings
drjdpowell replied to rharmon@sandia.gov's topic in LabVIEW General
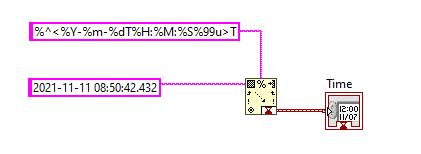
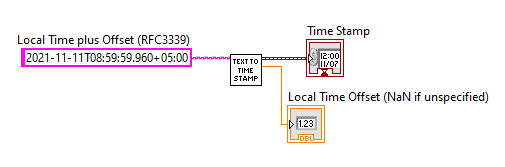
I used to use Scan From String function, with %T codes: But I wouldn't say this was any stronger than your method. Now I use a reusable library for RFC3339 (subset of ISO-8601). This uses Scan From String mostly, but is robust against a variety of edge cases. Also handles things like the Local Time plus Offset format, which is nice in that it stores both Local Time and UTC time:
-
Date/Time To Seconds Function and Daylight Savings
drjdpowell replied to rharmon@sandia.gov's topic in LabVIEW General
There I was thinking about a simple fix to your immediate problem, rather than the much bigger change of switching to UTC. Using DST=-1 is to use true Local Time, which is what your Users will find most intuitive. But one time a year your times will jump back one hour, which is a rather problematic behaviour. You could use Local Time never corrected for Summer Time; easier for you but confusing to Users. Aside: I suffer the programmer disadvantage of living in the Western European Timezone, which is the same as UTC for half the year, making it hard to notice errors in my UTC-Local conversion. I often have my computer set to a far away Timezone when I'm debugging time-related things. -
Date/Time To Seconds Function and Daylight Savings
drjdpowell replied to rharmon@sandia.gov's topic in LabVIEW General
But to answer you question, I would go with DST=-1. There will be one hour per year (Fall Back) where LabVIEW won't be able to know what the UTC time actually is (as there are two possibilities), but otherwise it would work. Note, though, that i never use that function that you are using. -
Date/Time To Seconds Function and Daylight Savings
drjdpowell replied to rharmon@sandia.gov's topic in LabVIEW General
I also strongly recommend using UTC usually (with conversion to Local Time for display). And using an existing, hopefully well tested, library to convert to/from ISO-8601 (my own functions are in https://www.vipm.io/package/jdp_science_lib_common_utilities/, though they are intended just for the RFC3339 internet standard and may not be as complete as Francois'). -
I remember CognoscentUI being quite impressive: https://forums.ni.com/t5/Example-Code/CognoscentUI-XControl-LVOOP-Animation-Unicode-and-Image/ta-p/3495160
-
JKSH has explained as well as I could the expected use. "Missing from Object" is determined when operating on the Object. I had a look, and it should be reasonably easy to give a different error for a string with only whitespace, but I'll need to understand use case for it better. I, personally, never find the need to write custom error-handling code. By the way, if one's use case is "set from this JSON as much as possible, or use supplied default for items where this is not possible", then one can just not use the error wires at all.
-
I am actual about to commit to making the next release in LaVIEW 2019, rather than 2017, as VIMs were very new in 2017 and both buggy and of limited capability.
-
Use case? Why do you need different custom error than the 402841: "Invalid JSON formatting" that you have now?
-
Since Latin for six is "sex", we could have gone for "sexidecimal".
-
So? Main.vi knows it might need disposing, as it did the creating, so do the cast.
-
Note that System could have a method to remove the Transport ("uninject"?). Main.vi can remove the TCP and dispose of it, just before it disposes of System.
-
The problem I have with the Network Streams QoS arguement is that TCP already does this, using ACKs and retries to ensure an ordered stream. And if I really needed to be sure a message is handled, I need to verify it all the way through the application to the final result, not just through the Network Stream message delivery. For example, if I need to send something to be saved to disk, I need QoS all the way to disk, and would have to implement a custom buffer on the send side, layered on top of Network Streams.
-
I've never used Network Streams. It appears to me to be an API that makes TCP communication easier, for a specific use case of a one-way stream. But I've seen, on more than one occasion, people use it build APIs for entirely different use cases, ones that would (in the end) be simpler and more performant to base on straight TCP.
-
I've done this kind of thing, with a 32-bit-only dll needed from a 64-bit one. Actually, it was two 64-bit Test Stations that both needed the same info from the 32-bit equipment, so having both be Clients of the 32-bit Server worked well. I used the TCP capability of Messenger Library, which is very little effort. One question: why Network Streams? If you are wrapping things in your own API then why not a standard TCP connection? What are Network Streams giving you?
-
Your DB Browser and LabVIEW are possibly using different versions of sqlite. Can you run this in each to detect the version: select sqlite_version();
-
Does anyone actually use Variants in clusters in this way? To me, this is not even a tertiary use case of JSONtext, so it would be helpful to hear from people with real-world uses. I am tempted to suggest throwing a "Variants not supported" error, but even that would add overhead which I am loath to do.
-
Can you attach a small VI demonstrating the error?
-
Please try this fix: jdp_science_jsontext-1.6.6.106.vip
-
Issue 92: https://bitbucket.org/drjdpowell/jsontext/issues/92/all-integer-types-needed-for-set-map
-
Again, Variants are tricky, and have two names and serve two purposes. Viewed as a container of named data, your Variants are just placeholders, not actual data themselves (which is why I suggested in the last post to put a named Variant as Data inside the placeholder).
-
Consider just not including those parameters. Rather than {"A":123,"B":null,"C":789} just have {"A":123,"C":789}; then "B" will be default. Alternately you could put named-Variant values inside your variants (which teh Variant-to-Data node will pass through: Variants are quite tricky, as they can serve both as a temporary container for a value, and a value itself.
-
LabVIEW Clusters and Arrays do not map directly onto JSON Objects and Arrays. LabVIEW Clusters are fixed-size ordered sets of optionally-named values JSON Objects are variable-size, unordered sets of must-be-named values LabVIEW Arrays are variable sized ordered sets of values all the same type JSON Arrays are variable sized ordered sets of values that can all be different type So a LabVIEW Cluster with unnamed elements cannot map onto a JSON Object, but can map onto a JSON Array. Similarly, mixed-type JSON Arrays cannot be converted to a LabVIEW array, but can be converted to a LabVIEW cluster (assuming you know the number of elements and types). JSONtext thus supports two mappings for LabVIEW Clusters, as explained in Help>>JDP Science>>JSONtext...
-
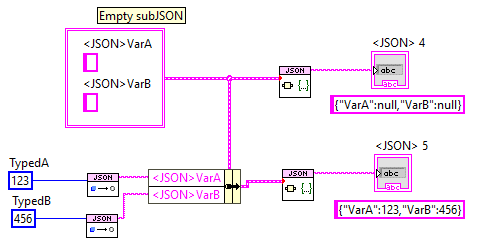
People who wish to use Variants and JSON generally want to do this: Put Static-Typed Data in a Variant in a larger data structure Convert larger structure to JSON Send the JSON somewhere Convert JSON back to larger structure (containing Variant) Convert Variant to Static-Typed Data But Step (4) is a big problem, as at that point we don't have access to the Type-description information to rebuild the Variant. But I say do this: Convert Static-Typed Data to JSON Assemble larger JSON from this subJSON Send the JSON somewhere Extract the subJSON Convert subJSON to Static-Typed Data This avoids the problem, as we only need the Type at the first and last steps,where we statically know the type.
-
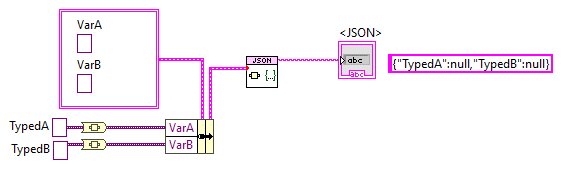
I've had multiple requests to "support Variants", but there is a mismatch between Variants (Data plus full type description including name) and JSON (Data with only weak type info: string, number, etc.). To support unflattening JSON to Variant would require a form something like this: { "VarA":{"Variant type":"long","name":"TypedA","Value":123}, "VarB":{"Variant type":"long","name":"TypedB","Value":456} } But this is a rabbit hole I'm not going down. I'd rather ask "Why are you using Variants here instead of subJSON?" This gives you the behaviour you expect: