drjdpowell
-
Posts
1,989 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by drjdpowell
-
I've just implemented this and posted a beta: https://forums.ni.com/t5/JDP-Science-Tools/BETA-version-of-JSONtext-1-5-0/m-p/4136116 Handles comments like this: // Supports Comments { "a":1 // like this "b":2 /*or this style of multiline comment*/ "c": 3 /*oh, and notice I'm forgetting some commas A new line will serve as a comma, similar to HJSON*/ "d":4, // except I've foolishly left a trailing one at the end }
-
I have been coming round to supporting comments in JSONtext, at least for ignoring comments on reading (which is quite simple to implement, I think). And possibly features to be more forgiving of common User error, such as missing commas.
-
 Can't tell if that is just NI being overcautious, or there is an actual reason for that. Python 2 was sunsetted at the start of this year, so no one should use that. I'm guessing the NI's testing was done against 3.6, as the latest available version when they originally developed the python node.
Can't tell if that is just NI being overcautious, or there is an actual reason for that. Python 2 was sunsetted at the start of this year, so no one should use that. I'm guessing the NI's testing was done against 3.6, as the latest available version when they originally developed the python node. -
Not sure it is sophisticated, but here is a simple implementation of an Example that increments a counter (state variable), with an error thrown if count exceeds a MaxCount (state variable). The py Module is called from a LVOOP Object that encapsulates the Python instance. The Class has methods that call the corresponding py-module functions. Python Incrementer.zip py module is this: # Demo of a Python Module, to be called by LabVIEW # Notes on Errors: # Return errors in a form matching the LabVIEW Error Cluster. Examples: # Error = (False,0,"") # No Error # Error = (True,1,"MySource<Err>MyDescription") # 1==Error in input import time # used for sleep() # Example of having global data (global just to this module): Count = 0 MaxCount = 10 def Initialize(): Error = (False,0,"") # No Error (change to indicate an error) return(Error,) def GetCount(): global Count return (Count); def Increment(): Error = (False,0,"") # No Error (change to indicate an error) global Count global MaxCount if Count >= MaxCount: Error=(True,1,"Increment<Err>Can't Increment as at MaxCount") else: Count += 1 time.sleep(.3) # Wait, to count slow enought to see return (Error,Count); def SetMaxCount(NewMaxCount): Error = (False,0,"") # No Error (change to indicate an error) global MaxCount MaxCount = NewMaxCount return(Error,)
-
Side note: I am definitely going with the native node, in LabVIEW 2020. I think NI is underselling it by providing examples that are far too simple (including no examples of cluster-to-tuple or how to hold state data in your py module). I prototyped my analysis template py module yesterday and it went easy. No head banging frustrations at all.
-
Hey, I haven't got even one project using python yet. And my Dev PC uses virtual machines, which I already use for issues like developing with or without Vision installed.
-
Though I see the value in that, I don't think that is a significant advantage in my case. Actually a disadvantage, as my client is already overburdened with "too many things" complexity and would benefit from a standardized python environment. I also want to minimize the complexity of install on a fresh computer, and I think the native node only requires python itself.
-
Can you say more about that? What do you mean by a "virtual environment"? I experimented with the native node in LabVIEW 2020 and I'm liking it so far.
-
I've been investigating this: But I failed to get it to work.
-
For example, my Interface in JSONtext (if JSONtext were based in 2020 rather than 2017) would just implement "To JSON" and "From JSON" methods, whose default implementations would just use the standard flattening of the class in a JSON string. I've have been holding off implementing this as a parent class because I was waiting for interfaces. Should I just go ahead and make this a Class? Note that a User could not use your Lineator to actually do the conversion to JSON, as they cannot inherit off your Lineator if they are already inherited off my Class. If Interfaces were used, they could use your Lineator to produce JSON inside my JSONtext subVIs.
-
Just top-level parent classes that inherit from LVObject, then? If LVObject gets private data, even an inheritance-based serializer will fail. I haven't looked at your "lineator" in a long time, but I feel there must have been some architectural choices made that other developers may have reasons for making other choices. Thus, there is a need to be able to support more than one type of serializer in the same class hierarchy. Thus interfaces, maybe?
-
I am just starting on trying to be able to use Python code from a LabVIEW application (mostly for some image analysis stuff). This is for a large project where some programmers are more comfortable developing in Python than LabVIEW. I have not done any Python before, and their seem to be a bewildering array of options; many IDE's, Libraries, and Python-LabVIEW connectors. So I was wondering if people who have been using Python with LabVIEW can give their experiences and describe what set of technologies they use.
-
You can add them to classes whose ancestors have no data (such as LVObject). You might have a "Flatten to JSON" interface and a "Flatten to XML" interface and a "Store in My Special Format" interface, and can decide which formats to implement. Inheritance only works once.
-
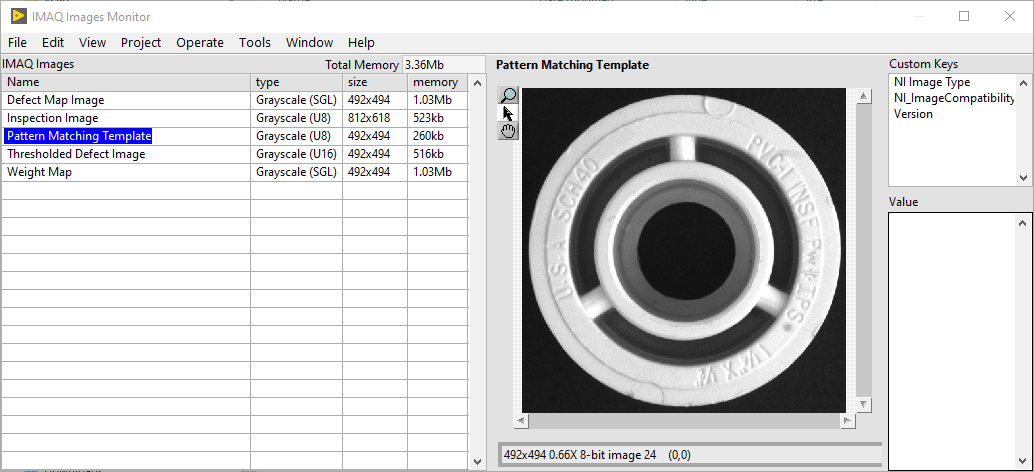
Q: How to list all IMAQ images in memory
drjdpowell replied to drjdpowell's topic in LabVIEW General
Code for this posted at NI: https://forums.ni.com/t5/JDP-Science-Tools/IMAQ-Images-Monitor/m-p/4131248#M31 -
Q: How to list all IMAQ images in memory
drjdpowell replied to drjdpowell's topic in LabVIEW General
Update: I used the dll call from the link @dadreamer provided, and made a Messenger-Library "actor" that I can use for debugging. Already found a couple of bugs with it.
-
I assume you've seen my conversation: https://lavag.org/topic/21651-git-cant-be-this-terrible-what-am-i-doing-wrong/
-
Actually, I missed the "doesn't pause till lower loop is stopped bit"; that can't be a compiler issue (unlike updating the indicator after the breakpoint) so seems to be a bug.
-
How much of a performance loss would you be prepared to take to fix this bug?
-
I would guess it is a compiler optimization, where the terminal points to the same memory location as the output tunnel. It is arguable that some breakpoint weirdness is better than the forced memory copies just in case a breakpoint might be added at some point (given the huge number of places a breakpoint could be added). Alternately, it could be something to do with "chunking"; dividing a VI into executable chunks. I wouldn't be surprised if a breakpoint can only pause between chunks. Exiting the loop and writing to the indicator terminal could be one chunk.
-
Looking for option to speed up my usage of SQLite
drjdpowell replied to Thang Nguyen's topic in Database and File IO
Saving your images directly in a binary file would probably be the fastest way to save. Not the best format for long-term storage, but if you only keeping them temporarily so they can be read and compressed later then that doesn't matter. I would first consider your Compression step; can you make that any faster? You only need it 33% faster to get 150 FPS. Is this your own developed compression algorithm? How much CPU does it use when it is running? If only one CPU then there are parallelization options (such as compressing multiple images in parallel). BTW: do you really have 8-byte pixels? -
Looking for option to speed up my usage of SQLite
drjdpowell replied to Thang Nguyen's topic in Database and File IO
Best to state performance numbers in per operation. I assume these are for 5528 images, so the "Drop Table" is 50ms each time? Try eliminating the Drop Table and instead just delete the row. If that works then your remaining dominant step is the 10ms/image for Compression. I think your initial mistake was to go, "Since we want to speed up the process, <we do extra steps and make things extra complicated and in parallel modules in hopes that will be faster>." Better to have said, "Since we want to speed up the process, we will make a simple-as-possible prototype VI that we can benchmark." That prototype would be a simple loop that gets data, compresses, and saves to db. -
Q: How to list all IMAQ images in memory
drjdpowell replied to drjdpowell's topic in LabVIEW General
I would much rather than IMAQ references behaved the same as other LabVIEW references, like Queues. -
Q: How to list all IMAQ images in memory
drjdpowell replied to drjdpowell's topic in LabVIEW General
How to get a list of image buffers? Thanks! That's great. -
Q: How to list all IMAQ images in memory
drjdpowell replied to drjdpowell's topic in LabVIEW General
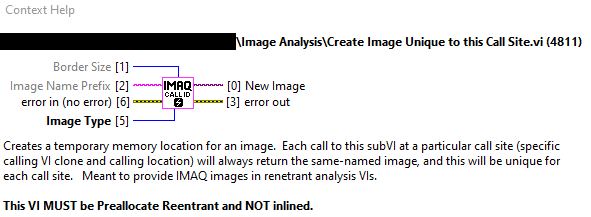
As a side question, how do people deal with the non-standard way that IMAQ image references work (alway globally named; don't clean up when owning VI goes idle)? For background, I am currently trying to get a large amount of non-reentrant image analysis code to work reentrantly, and have to deal with preventing one clone of a VI modifying an image inadvertently shared with another. I am attacking the problem by auto-generating image names based on call site (ie, a pre-allocate clone that uses its own clone id in the image name):
-
Is there any way to list all IMAQ images currently in memory? This is as a diagnostic and code check, rather than to actually use this in code.