drjdpowell
-
Posts
1,989 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by drjdpowell
-
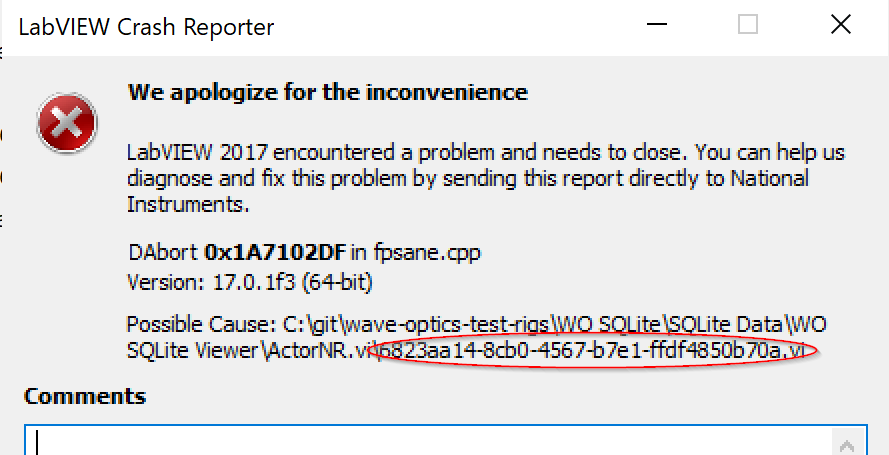
 Having problems building my EXE. Generates this error sometimes (when it doesn't just silently crash): Does someone know what the long-meaningless-named VI might be (a vim instance, I'm guessing). Any help appreciated. -- James
Having problems building my EXE. Generates this error sometimes (when it doesn't just silently crash): Does someone know what the long-meaningless-named VI might be (a vim instance, I'm guessing). Any help appreciated. -- James
-
Using JSONText to parse a poorly formatted JSON string
drjdpowell replied to jed's topic in LabVIEW General
There is a page on Path notation too: -
Using JSONText to parse a poorly formatted JSON string
drjdpowell replied to jed's topic in LabVIEW General
Did you look at the detailed help on teh JSONtext VIs? They should all contain links to further documentation pages (or you can go to Help>>JDP Science>>JSONtext...). The "<JSON> tags" page explains: -
Using JSONText to parse a poorly formatted JSON string
drjdpowell replied to jed's topic in LabVIEW General
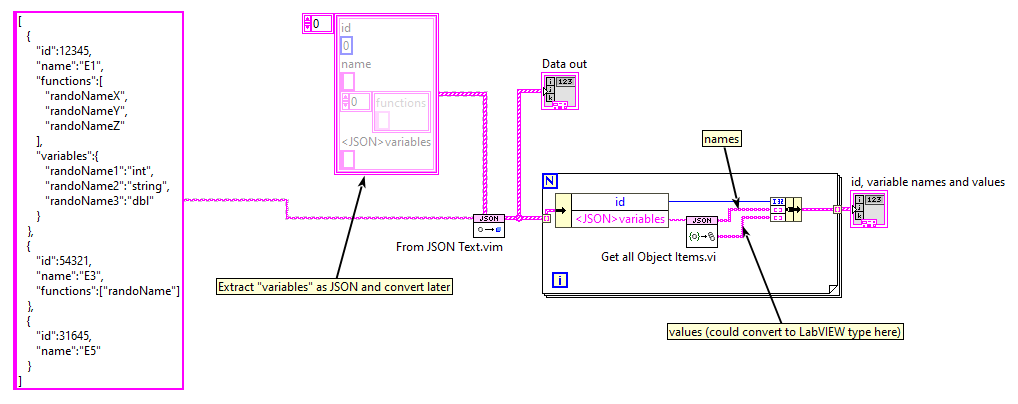
Just a comment, but I have noticed that people very often deal with JSON by looking for the "monster cluster" that completely converts the JSON into a monolithic LabVIEW structure. I suggest people think a bit more modularly in terms of "subJSON". The first question I would ask you if I were working with you on your actual project is why do you need (at this code level, at least) to convert your variables from their perfectly reasonable JSON format to an array of clusters? -
Using JSONText to parse a poorly formatted JSON string
drjdpowell replied to jed's topic in LabVIEW General
You've solved your problem, but this is the solution I just did:
-
Malleable Buffer (seeing what VIMs can do)
drjdpowell replied to drjdpowell's topic in Code In-Development
I've put 0.4 on VIPM.io. -
Working on the next JSONtext functionality, which is features to improve support of JSON Config Files. See https://forums.ni.com/t5/JDP-Science-Tools/BETA-version-of-JSONtext-1-6/td-p/4146235
-
- 3
-

-
Unflatten From JSON breaks on NUL characters (LabVIEW 2017+)
drjdpowell replied to LogMAN's topic in LabVIEW Bugs
I reported that in 2018: CAR 605085. I don't think they are planning on fixing it. Must use C strings under the hood. -
You could ignore the error, with NaN as default pressure and temperature. Or you could read flow first, and only get pressure/temperature if flow isn't "<unset>".
-
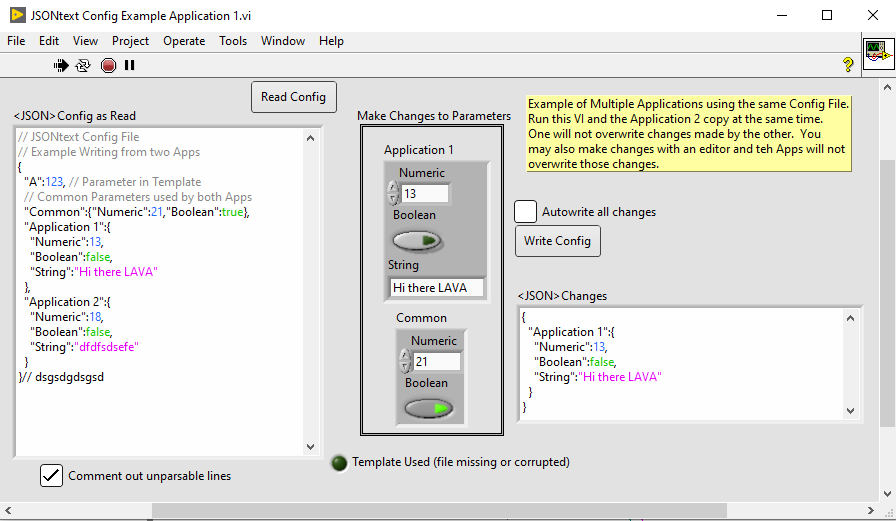
BTW, one other use case I've had is "Multiple applications read/write to common config file", which requires careful thinking about preventing one App from overriding changes made by another App.
-
I think you just need an extra string for each item to hold end-of-line comments, plus a "no item" data type to allow full-line comments. See how teh NI INI Library does it.
-
There are actually multiple different use cases of config files, and multiple ways to implement those uses cases. My most common use case is "Computer writes config; Human reads and may modify; Computer reads config". The way I do this is mostly: Read config file into Application data structures. Later, convert Application data structures into config file. Comments don't exist in the Application data structures, so comments get dropped. Another (used, by the NI/OpenG INI libraries, and I'm guessing your TOML stuff) is: Read config file into intermediate structure Query structure to set Application data structures Update intermediate structure with changed values from Application data convert intermediate structure back to a config file Here, the intermediate structure can remember the comments in the initial file and thus preserve them. But, IMO, this is also less clean and more complex than the first method, as you have an additional thing to carry around, and the potential to forget to do that "update" part. Currently, with the latest version of JSONtext (now available!), I haven't really developed this second, comment-preserving method. I am more thinking of another, less common but important, use case: "Human writes (possibly from a template); Computer reads", where the computer never writes (this is @bjustice use case, I think). Here, the human writes comments (or the Template can be extensively commented). But I do intend to support keeping comments. It will probably involve applying changes from the new JSON into the original config-file JSON, preserving comments (and other formatting). But that is for the future. Note added later: the config-file JSON with Comments is now available in JSONtext 1.6.5. See https://forums.ni.com/t5/JDP-Science-Tools/BETA-version-of-JSONtext-1-6/m-p/4146235#M39
-
Note: that package also has RFC3339-compliant Datetime format VIs, if you haven't already done Timestamps.
-
Kill lonely clones vi without close Project windows
drjdpowell replied to Bobillier's topic in Development Environment (IDE)
Messenger Library uses the same watchdog mechanism, although I just trigger normal shutdown via an "Autoshutdown" message ; I don't call STOP. I would have thought 500 ms is too short a time to wait before such a harsh method. -
class instance sharing in multi loops
drjdpowell replied to VadimB's topic in Object-Oriented Programming
A "queue" is a first-in-first-out mechanism. Don't be confused by specific implementations; the LabVIEW Event system is just as much a queue** as the LabVIEW "Queue". **Specifically, the "event registration refnum" is an event queue. -
class instance sharing in multi loops
drjdpowell replied to VadimB's topic in Object-Oriented Programming
As thols says, the best practice is to NOT share things between loops, but if you do, I'd suggest a DVR. -
Like most problems, once I had a workaround, I no longer spent any time thinking about it.
-
I've encountered a black imaq image display in exes, solved by unchecking the box to allow running in a later runtime version. Don't know if that is related to your problem.
-
There are quite a lot of other message-passing frameworks that you might want have a look at. DQMH, (my own) Messenger Library, Workers and Aloha are on the Tools Network, for example. AF and the QMH template are not the only things out there.
-
https://bitbucket.org/drjdpowell/jsontext/issues/80/2d-array-of-variants-not-converting Will be fixed in 1.5.2
-
Can you attach the vi you show? Nevermind, I've reproduced it.
-
Your attribute Values need to be valid JSON. You are inputting just strings. Convert your strings to JSON first.
-
SQLite: lock on file not currently in use
drjdpowell replied to osvaldo's topic in Database and File IO
Do you check for an error coming out of SQLite Close? SQLite will not close and throw an error if unfinalized Statements exist on that connection. The unclosed connection would then continue to exist till your app is closed. -
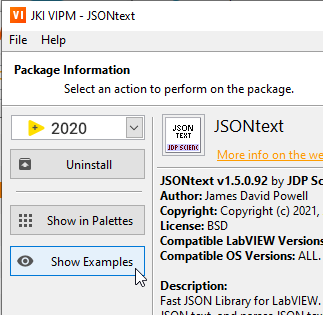
Example are in <LabVIEW>\examples\JDP Science\JSONtext, accessible through VIPM: The JSONpath example might help.
-
Have you looked at the examples?