drjdpowell
-
Posts
1,989 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by drjdpowell
-

Multi-Device Acquisition
drjdpowell replied to JamesMc86's topic in Application Design & Architecture
I usually save data as XY sets in a TDMS file, so different data sources can be at different rates and offsets. But if I wanted all data at the same time points, I would probably have a single queue to a “data logger” that all processes would send messages to (one queue, not many, with the source of the message as part of the message). Then the “Data logger” process could do any necessary resampling. This, IMO, has some advantages over using a Functional Global, though the advantages are pretty minor, at least for the typical use case of a steady data rate (where buffering is not needed). — James -
I’ve used User Menus in VIs in sub panels before without problem. Perhaps I’m misunderstanding the issue.
-
Self-addressed stamped envelopes
drjdpowell replied to drjdpowell's topic in Application Design & Architecture
Hello, I’m uploading the latest version of my framework, even though it isn’t polished, as I’m unlikely to have any time to polish it for months (baby on the way). It includes all the extra stuff since the last version, including the Actor Manager, and TCP-network versions of the Queue and User Event Messengers. It is in LabVIEW 2011. — James Messenging.zip -
Techniques for componentizing code
drjdpowell replied to Daklu's topic in Object-Oriented Programming
Short answer: started (and had the first app using it) before I knew LapDog existed. Keep meaning to see if I can reformat the message part into a LapDog extension. Or make the messenger part interoperate with your "Message Queue”. -
Thanks for the insight. I’m going to leave creating SQL functions for another day.
-
Some don’t, some do. But the ones that don’t are cheap enough to throw in the trash and get a different brand.
-
No, but it has been suggested.
-
Techniques for componentizing code
drjdpowell replied to Daklu's topic in Object-Oriented Programming
I have a reusable “Actor” that does the same thing: It’s one of the more useful things to have in the toolkit. Doesn’t sound that great to me. Personally, all my “Queues” (actually anything to which I can send a message, via queue, User Event, TCP server, notifier, etc.; my parent class is called “Send") use the same base “MSG” class, and I keep track of what is what by holding them in a cluster in shift register, and unbundling by name when I want to send something to one. I never put them in an array unless I mean to send the same message to everybody. So I never search through an array of “Send” objects. In fact, the container I use for multiple “Send”s, called “Observer”, deliberately doesn’t provide the ability to access individual elements. — James
-
Techniques for componentizing code
drjdpowell replied to Daklu's topic in Object-Oriented Programming
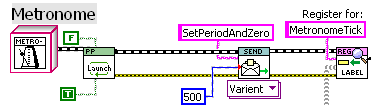
I keep the last timestamp in the object data. Yes, “Do.vi” is no-op for the parent message class. One can get around that by making the calculation like a metronome. Using the scheduled last time rather than the actual last execution time. Though in this application I didn’t, as true periodicity is not desired. Instead, I just need a minimal time between writes to disk, and doing it this way works better than a periodic heartbeat. True. I’ve been meaning to think how to generalize this to multiple tasks. Perhaps an array of “tasks” that each output a timeout, with the minimum timeout being used, or an array of tasks sorted by next one scheduled, with only the first element actually checked. — James -
I do all coding on a single 15”-screen laptop. High res, though: 1680x1050. Don’t require things fit on the screen but they mostly do.
-
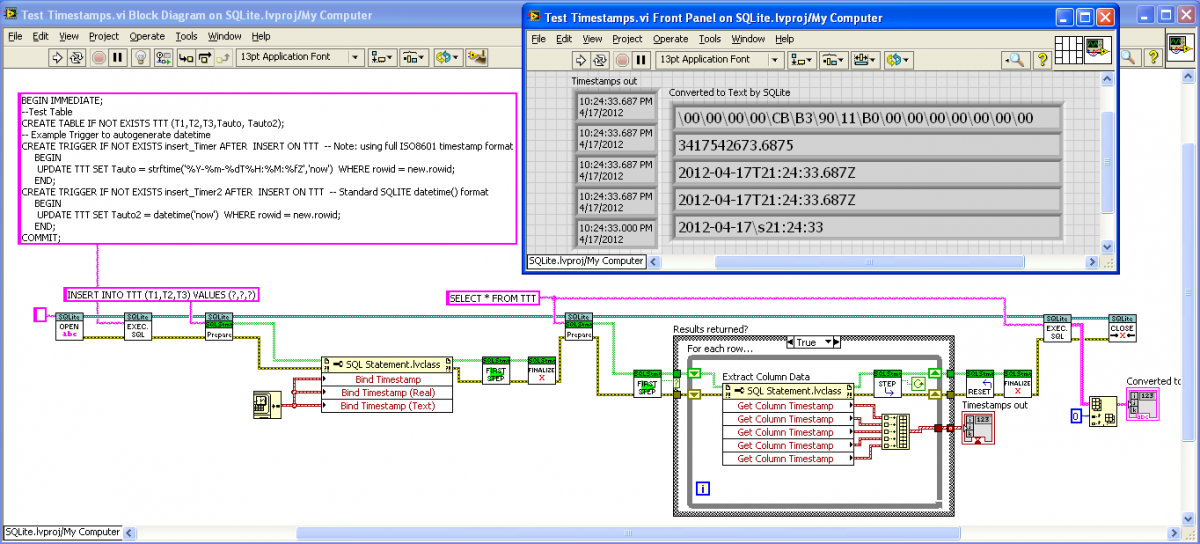
Here’s what I decided with the Timestamps. LabVIEW Timestamps saved as 128-bit BLOB or 8-byte DBL, or ISO8601 Timestring with “T” and “Z”. The “Get Column Timestring” property recognizes all these formats as well as the standard SQLite text format (sans “T” or “Z”). Shown is a “Test Timestamps" VI that records Timestamps in five ways, the three bindings and two autotimestamping Triggers (using strftime() to get the full ISO8601, and date time()): SQLite LabVIEW.zip
-
LabVIEW dll functions can be called from C, I’m pretty sure, but I can’t figure out how toy get a pointer to the function in LabVIEW.
-
Techniques for componentizing code
drjdpowell replied to Daklu's topic in Object-Oriented Programming
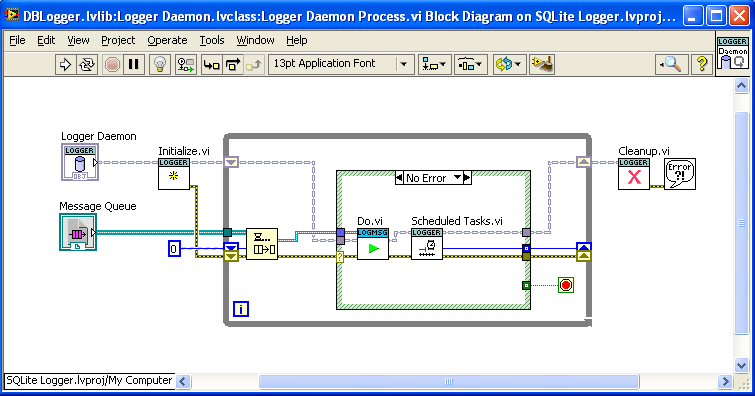
I had a similar issue recently that I tried a different way with. A fourth option to consider with Timeouts, Heartbeats and DVRs (never thought of the last one). I was writing software to log to an SQLite database; each individual SQLite transaction to disk takes a large amount of time, so it is best to store up log messages and save them as a batch periodically. I solved it with a “Scheduled Tasks” VI shown below (in a background process in the “Command Pattern” OOP style): “Scheduled Tasks” is called after each message and outputs a timeout that feeds back into the dequeue. Internally, “Scheduled Tasks” checks to see if it is time to write the accumulated log messages to disk, and if not, calculates the remaining milliseconds, which is output. Thus, the task always gets done on time, regardless of how many messages are incoming. A disadvantage is that the timeout calculation has to be done after each message, but it isn’t a big calculation. An advantage is that “Scheduled Tasks” outputs −1 (no timeout) after it flushes all waiting messages to disk; thus if log messages arrive very rarely, this loop is spending most of its time just waiting. It worked out quite well in this application, so I thought I’d mention it. — James
-
On a side note, does anyone know how one might implement this using LabVIEW? It would allow creation of new SQL functions (such as ones that can handle LabVIEW timestamps). It requires the passing of a function pointer to the SQLite dll function. I have no real experience in such things, but I would have thought one could make a VI into a dll, and somehow pass a pointer to it to SQLite. But Google says no.
-
Yet another Timestamp issue: SQLite3’s datetime function (which can be handily used in an SQL statement as "datetime(now)”) is in the format YYYY-MM-DD HH:MM:SS and is UTC, but the proper ISO8601 format is YYYY-MM-DDTHH:MM:SS.SSSZ. One can get this format in an SQL statement by using the longer "strftime('%Y-%m-%dT%H:%M:%fZ','NOW’)”. Currently, my thinking is to have “Bind Timestamp” which saves the full 128-bit LV Timestamp as a BLOB, and “Bind Timestamp (Text)” which saves the ISO8601 format as TEXT. I will have a single “Get Column Timestamp” that checks for the datatype and tries to convert accordingly (16-byte BLOBs or TEXT of the right format).
-
That conversation is the one I came across, and the solution I chose. +Inf and -Inf store in SQLite3 with no problem. It is only NaN that is treated differently. I’m considering removing the “Bind Timestamp” and “Get Column Timestamp” methods entirely, thus forcing the User to explicitly decide on what to use as Timestamps. Possibly with some support VIs to convert LabVIEW Timestamps into ISO8601 text formats or the other two types suggested in the SQLite3 documentation: Julian day number as a DBL, or Unix Time as an integer. Other options (the number of possibilities is why I’m considering dropping Timestamps altogether) is LV timestamp as a DBL, or the full 128-bit LV timestamp as a BLOB. — James
-
And that library is a mere 564 kB. Very light. Being so small and simple, it allows one to think of using a database solution for a wider array of problems. One thing that needs to be done is for someone to compile the SQLite source for Real Time targets. Any volunteers?
-
Yes, the collation is a big reason not to just go with BLOB for all LV strings. I think searches would go wrong for U64 values too high to convert into an I64. That’s what I did. But they’re 23 bytes instead of 8. I can modify “Get Column Timestamp” to handle ISO8601 strings in addition to DBLs. And perhaps I could have two “Bind Timestamps”: “Bind Timestamp DBL” and “Bind Timestamp ISO8601”?
-
If anyone has SQLite experience, can you comment on my choices for data type conversion between SQLite3 and LabVIEW? There isn't a clear one-to-one conversion between LabVIEW types and SQLite's dynamic typing system, so I ended up deciding to leave the choice of type up to the User. This has the disadvantage of requiring the user to understand the SQLite3 datatypes in addition to LV types, but it has the advantage of full control. The specific issues/choices I made are: 1) SQLite3 has "TEXT" (UTF-8 encoded, zero-terminated strings) and "BLOB" (binary), while LabVIEW has strings used as either ANSI-encoded characters or binary (as in "Flatten to String"). This is a problem for any possible Variant-to-SQLite converter, as it is not possible to determine if a particular string is really character text or binary. 2) SQLite3 "INTEGER" is variable size (1 to 8) bytes and can hold any LabVIEW integer type except U64. I use I64 as the corresponding LV type. Not sure what to do about U64. 3) "REAL" is easy, as it is exactly the same as LabVIEW DBL. Except for one slight issue: "NaN" is not allowed by SQLite and is converted to "NULL", but "NULL" is retrieved by SQLite as zero! I opted to override this and return any NULLs as "Not a Number" if retrieved as a DBL. 4) There is no timestamp data type in SQLite3. I added functions for saving LV Timestamps as REAL (DBL) values. However there are alternate possible choices for timestamps that would allow the use of inbuilt SQL functions. There is a “Get Column Variant” property that converts any SQLite value to a LV Variant (REAL—>DBL, INT—>I64, NULL—>Void,TEXT/BLOB—>String), but no function for binding a LV Variant, because of the above described difficulties. — James
-
My Actor Manager is very specific to my messaging framework, but I did a trial prototype for the 2012beta Actor Framework here.
-
Perhaps with VITs, the block diagram as to be traversed to see if changes need to be made? I notice that when using a VIT, the block diagram is changed slightly, by having the reference updated to point to the new VI created rather than the original VIT. Checking the block diagram could take considerable time (215 ms on my XP-on-virtual-machine system). Making a clone, on the other hand, requires only a new data space.
-
[CR] GPower toolsets package
drjdpowell replied to Steen Schmidt's topic in Code Repository (Uncertified)
I usually use “launch” to mean asynchronously running a VI, so “VI Launcher” sounds best to me. -
I got a vip file when I downloaded it.
-
Yes. They’re public domain. "Anyone is free to copy, modify, publish, use, compile, sell, or distribute the original SQLite code, either in source code form or as a compiled binary, for any purpose, commercial or non-commercial, and by any means… All of the deliverable code in SQLite has been written from scratch. No code has been taken from other projects or from the open internet. Every line of code can be traced back to its original author, and all of those authors have public domain dedications on file. So the SQLite code base is clean and is uncontaminated with licensed code from other projects."
-
Thanks, should have mentioned that. I took the precompiled win32 binary from the SQLite Downloads page. I specify the SQLite binary at only one point in the library, so it should be easy to substitute different compiled code for different operating systems using a single conditional disable structure. -- James