

drjdpowell
-
Posts
1,986 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by drjdpowell
-
-
Hi Daklu,
What do you think of my collection-of-objects-that-can-switch-between-type-identities idea posted above?
-
According to the LabVIEW 2012 Features and Changes it does not preallocate:
Note The Conditional tunnel option performs memory allocations as often as the Build Array implementation. Therefore, just like with the Build Array function, National Instruments recommends you consider alternatives to the conditional tunnel in portions of your application where performance is critical.
And a quick test I ran just now indicates the same; its performance matches that of a continuous build function. I think a change in this behaviour is planned for LV2013.
There was a big discussion about this on the 2012 Beta forum at NI.com, with a very strong recommendation from most beta testers that conditional indexing behave like regular indexing. I guess it was too late to make the change for 2012.
-
drjdpowell, this is just a basic example and not the actual feature I'm trying to implement. True, it is possible to remove the init in my example and leave only the member access vi or join them two together. Yet, even in this example there are reasons to have a separate init which is dynamically dispatched:...
OK, but why do you you call the Init.vi in a loop over an array of objects? Why not take the individual objects, call Init on them, then call the Parameter setting VI, and only then put them in an array. Like this (modifying your “old style” example):
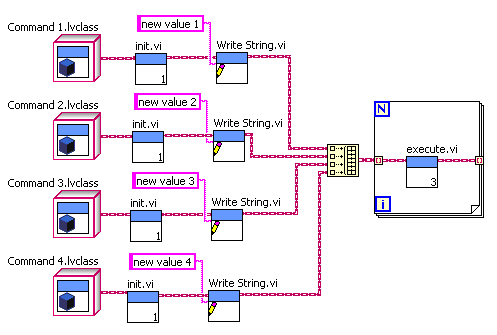
Here “Init.vi” can be dynamically dispatched, while “Write String.vi” can be a unique method for each child class. You could even branch the wire and reuse the preinitialized object with different parameters.
Basically I don’t understand the reasoning behind your initial example, where you put the objects in a array to call Init in a loop, then strip them all out again to treat them individually, then put them all back in an array again. Seems pointlessly over complicated.
— James (sorry for the late reply, I’ve been on holiday without internet access)
-
I usually use DVRs whenever I want to use the aggregation pattern (zero or more relationship).
If you’d like to stay by-value and avoid the DVRs, you can instead keep your objects in an array, and store the object’s array index in the variant attribute look up tables.
-
Why are you using a dynamically-dispatched “Init” method at all? Why not just have a “Create <commandname>” specific method in each command class that initializes it (with specific parameter inputs) and then send it off to be executed?
-
 1
1
-
-
He’s using a Property Node: Right-click>>Create>>Property Node>>Value
Should exist in 8.0.
You could also use a local variable (Right-click>>Create>>Local Variable)
-
Other than for TCP and UDP, how many different “Is Valid” methods can you possibly need?
Note that you can make a method “protected”, which would allow your base class to call child-class methods without making the methods public.
Also note this conversation and consider if you really need an “Is Valid” method.
-
I wish it were easier to change namespacing once code is used in multiple projects. Or if it were possible to define a “display name” and a separate unique identifier that one could leave unchanged. So my “Actor” class could secretly be “47D44584FGHT” or whatever. No collisions then.
-
The thing then, is that every child needs to know about the parent's private data, which brings me to a question that's been puzzling me. If children inherit, they don't necessarily have access to the data that was defined as part of their parent, but when you hover over the child's class wire, the parent data structures are listed in there. If I call an accessor (a parent's accesor?) on that wire, what do I get? The actual state of the parent's data? Or, the default value of said data?
The actual parent-class data of the object. An object of a child class is a collection of clusters, one for each level of class hierarchy. You can call any parent-class method on any child-class object. Note that I am being careful to call it a “child-class object”, not a “child object”, as the whole “parent/child” metaphor really only applies to classes. No actual object is a “child” of any other object.
-
Seven months later and I’m working on getting my reuse messaging code in a VIPM package. And another issue occurs to me. I now have most of my classes outside of any lvlib library, which prevents unnecessary loading. However, that means I have rather generic class names like “ErrorMessage”, “Messenger”, and “Actor” with no further namespacing that I could easily imagine another package using. What do other people do about this potential conflict?
— James
-
In the end I decided to add a “Text Encoding” property to the "SQL Statement” class, with choices of UTF-8, system (converted to UTF-8 with the primitives Shaun linked to), and UTF-16. System is the default choice. I also added the system-to-UTF-8 conversion primitives on all things like SQL text or database names (thanks Shaun).
I also used the sqlite3_errmsg text to give more useful errors (thanks Matt).
-
Are you being sure to throw away any bits > 25 when the encoder rolls over? The code below should give the correct U25 difference even though it’s using U32’s:
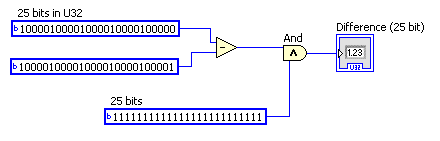
Added later: actually, the fact that the “random values” alternate with the good ones suggests some other problem, unless you are reading the encoder about two times a revolution.
-
Yes, but you I wouldn't want to use a heartbeat to keep all your my actors alive just in case you I ever decide to use it over a network.
The heartbeat can be built in to your reusable TCP component (I’ve considered adding it to my background processes running the TCP connection). You don’t have to make them part of the actor code itself.
-
I see. I took your statement to mean you can take an arbitrary actor, replace the QueueMessenger with a TCPMessenger, and all of a sudden have an actor suitable for network communication. I think that would be a tough trick to pull off without adding a lot of potentially unnecessary code to every actor.
I was a reaching a bit with the “any actor” thing. Though my actors tend to be a quite “server” like already, much more than your “SlaveLoops” or the Actor Framework “Actors”. They publish information and/or reply to incoming messages, and don’t have an “output” or “caller” queue or any hardwired 1:1 relationship with an actor at a higher level. They serve clients. The higher-level code that launches them is usually the main, and often only, client, but this isn’t hardcoded in. Thus, they are much more suitable to be sitting behind a TCP server.
— James
-
How do you write your components so they terminate in the case of unusual conditions? For example, if a bug in a governing (master) actor exits incorrectly due to a bug, how do the sub (slave) actors know they should exit? Typically my actors will execute an emergency self termination under two conditions:
1. The actor's input queue is dead. This can occur if another actor improperly releases this actor's input queue. Regardless, nobody can send messages to the actor anymore so it shuts down.
2. The actor's output queue is dead. An actor's output queue is how it sends its output messages to its governing actor. In fact, a sub actor's output queue is the same as its governing actor's input queue. If the output queue is dead, then the actor can no longer send messages up the chain of command and it shuts down.
This scheme works remarkably well for queues, but I don't think it would be suitable for other transports like TCP. What logic do you put in place to make sure an actor will shut down appropriately if the messaging system fails regardless of which transport is used?
Well, my current TCPMessenger is set up as a TCP Server, and is really only suitable for an Actor that itself acts as a server: an independent process that waits for Clients to connect. A break in the connection throws an error in the client, but the server continues waiting for new connections. This is the behavior I have in the past needed, where I had Real-Time controllers that must continue operating even when the UI computer goes down.
However, most of my actors (in non-network, single-app use) are intended to shutdown if their launching code/actor shutdown for any reason. For this I have the communication reference (queue, mostly) be created in the caller, so it goes invalid if the caller quits, which triggers shutdown as in your case 1. Case 2 doesn’t apply in my system as there is no output queue.
Now, if I wanted auto-shutdown behavior in a remote actor, then I would probably need to make a different type of TCPMessenger that worked more like Network Streams than a TCP server. So a break in the connection is an error on both ends, and the remote actor is triggered to shutdown.
— James
-
For example, suppose I have loop A that needs to be aware of messages from loop B (via queue) AND from loop C on another target (via streams,) rather than trying to route messages directly from loop C to loop A I'd create loop D, whose job it is to get messages from the stream and put them on loop A's queue. This also gives me someplace to put all the network connection management code if I need that without cluttering up the loop A with lots of extra stuff.
That’s the route I took in adding TCP message communication to my system, with “loop D” being a reusable component dynamically launched in the background. Incoming TCP messages are placed on a local queue, which can also have local messages placed on it directly.
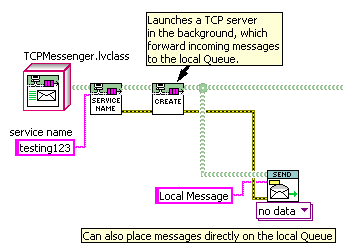
Because “TCPMessenger” is a child of “QueueMessenger”, I can substitute it into any pre-existing component that uses QueueMessenger, making that component available on the network without modifying it internally.
— James
-
I added variant messages to support James' request for values with units attached to them and to give users the ability to use variants if they want to. In general creating custom message classes for different data types will give you better performance by skipping the variant conversion.
I use variants mostly for simple values; to avoid having 101 different simple message types. I have four or five polymorphic VIs for simple messages, and having so many different message types would be unmanageable. But for any complex message, I usually have a custom message class. It’s no more complex to make a new message class then make a typedef cluster to go inside a variant message.
— James
However, I have heard unconfirmed reports from a CLA I know and trust that there is a small memory leak in RT targets when using objects. The issue has to do with LV not releasing all the memory when an object was destroyed. It wouldn't be a problem for a system with objects that are supposed to persist through the application's execution time, but it could be an issue if objects are frequently created and released (like with an object-based messaging system.)
I’m hoping to work up to testing my object messages on an sbRIO next week. I will be sure to run a memory-leak test.
-
Out of curiosity, what kind of throughput do you see? How big (generally) are your payloads?
My limited testing was mostly functional (and over a slow-uploading home broadband connection) so I can’t answer for throughput. My messages vary in size, but common small ones have at least two objects in them (the message itself and a “reply address” in the message) and so flatten into quite a long string: a “Hello World” message is 75 bytes. I wrote a custom flattening function for the more common classes of message which greatly reduced that size. Also, for larger messages that can involve several objects I found that ZLIB compression (OpenG) works quite well, due to all the repeated characters like “.lvclass” and long strings of mostly zeroes in the class version info.
Do you flatten to string or to XML (and does it really matter)? Sorry, I'm rather new to all this - finally stepping away from the JKI State machine architecture

I use “Flatten to String”, which works great communicating between LabVIEW instances. If you need one end to be non-LabVIEW then you’ll want something like XML or JSON.
— James
-
I believe AMC uses UDP, instead of TCP, for network communication. Depending on what you are doing, you might require the lossless nature of TCP.
You should also have a look at ShaunR’s “Transport” and “Dispatcher” packages in the Code Repository; they do TCP.
I’ve done some (limited) testing of sending objects over the network (not Lapdog, but very similar), and the only concern I had was the somewhat verbose nature of flattened objects. I used the OpenG Zip tools to compress my larger messages and that worked quite well.
-
An update on the use of the library path in the CLN node:
I found through testing that some of my subVIs ran considerably slower than others, and eventually identified that it was do to details of how the class wire (from which the library path is unbundled) is treated. Basically, a subVI in parallel to the CLN node (i.e., not forced by dataflow to occur after it) would cause the slowdown. I suspect some magic in the compiler allows it to identify that the path has not changed as it was passed through several class methods and back through a shift register, and this magic was disturbed by the parallel call.
This being a subtle effect, which future modifiers may not be aware off, I’ve rewritten the package to use In-Place-Elements to access the library, thus discouraging parallel use.
The old problem of character encoding when it comes to crossing application borders. Why not create two polymorphic VIs. One specifically doing conversion from the current local to whatever the DB is using as default, and one passing the string entirely unaltered for the case where the user knows his data is already in the right encoding. Even more useful although almost impossible to implement fully would be if you can specify the local encoding and the VI does all the necessary conversion to whatever the db encoding is supposed to be. This is already a nightmare to do, when the db encoding stays constant, but if that can be configured too, then OMG!!!
I’m considering having multiple “Bind Text” versions: "Bind Text (UTF8)”, “Bind Text (UTF16)” (might as well add UTF16 as SQLIte supports it), and “Bind Text (system)” or something like that. And corresponding “Get Column” versions.
-
What’s the purpose of your “GUI manager”? Personally, I tend to keep all control manipulation on the block diagram of the VI containing the control. If I want a UI separated from the rest of the program I use messaging between VIs. The messages carry information, not control references.
If the “GUI manager” is supposed to provide a loose coupling between program and UI (i.e. if you want to be able to substitute a different UI) then you need to channel all UI actions through it. But you’d also need your UI in a different VI from the main code (so you could swap it out) which would prevent you writing to control terminals or local variables. So I don’t really understand the purpose of “GUI Manager”.
-
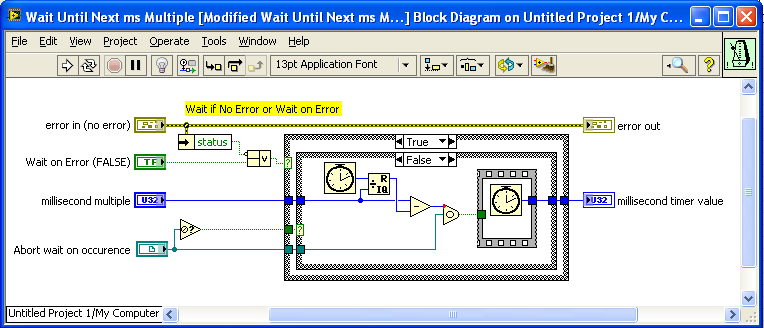
I just noticed that, although the OpenG version of “Wait (ms)” has an optional input for an Occurrence to use to Abort the wait, the complimentary version of "Wait Until Next ms Multiple” does not. I suggest modifying this VI to also accept an optional Abort Occurrence. Here is a modified version I just made:

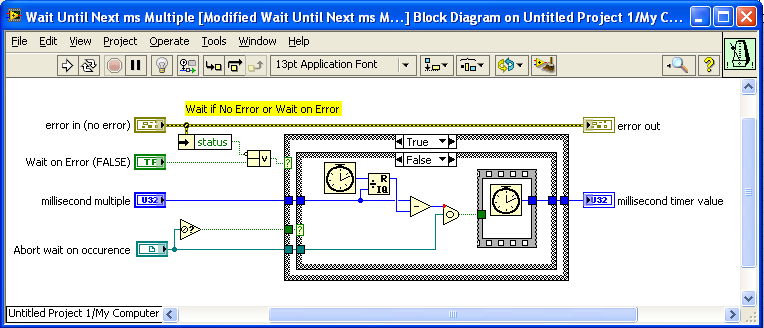
Modified Wait Until Next ms Multiple__ogtk.vi
— James
-
That's the point. IF you are going to make it viewable by other applications, they inherently assume the encoding by the pragma call (PRAGMA encoding; ). Sqlites default encoding scheme is UTF8 but you can set it to others so text in the DB "should" be one of the defined types (none of which LabVIEW supports natively). If, for example, Chinese characters are inserted ( which, in labview are MBCS) then they will not display correctly in other apps.
Yes, but can I be certain that the string the User provides is actually meant to be interpreted in LabVIEW's standard encoding? Strings can be anything; LabVIEW only really applies an encoding for display purposes. The User could already be working with UTF-8 or any other encoding, and applying the so-called “String-to-UTF8” function would scramble that.
-
I wouldn't worry too much about performance to begin with. Getting everything mapped out and functioning is (IMHO) more important since the optimisation does not prevent it's use and can take a while due to it being an iterative process (this can be achieved with each stable release).
Hi Shaun,
I agree (which is why I hadn’t spent much time on benchmarking till recently). Getting a working implementation in OpenG is more important, as optimization can happen later. And SQLite is very valuable even when less than 100% optimized; I’ve written a couple of applications with it so far and the speed is not an issue.
If you are looking at making it directly compatible with other apps for viewing, you will need to insert using the "string to UTF8" and recover using the "UTF8 To String" vis as the methods Matt and I use do not honor this. UTF8 ConversionI’m not sure I want to make that conversion an implicit part of the API. Users may want the full UTF-8 (which I don’t think is recoverable once it goes through "UTF8 to String”). And if they are using regular LabVIEW text (ANSI, I think) then it is a subset of UTF-8. I think it is better to document that the SQLite character encoding is UTF-8 and that ANSI is a subset, and let the User deal with any issues explicitly. Perhaps I should include those conversion primitives in the palettes.
— James
Inheriting default data, confused
in Object-Oriented Programming
Posted
As a different take on it, if “Number of Wheels” is a constant of the class (2 for Motorbike, etc.) then it shouldn’t be a “data” item at all. It should be an overridable method that returns the constant value:
Car.lvclass would have a similar override with the constant 4. Use this method wherever you need the number of wheels.
— James
Added later: if the number of wheels isn’t a constant, you can still have different defaults. Make the default number of wheels “-1”, and have the methods return the default value for the class only if the data item is “-1”. That way you can change the value if you want, but the default exists without needing an “Init” method.