

drjdpowell
-
Posts
1,986 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by drjdpowell
-
-
Suggestion: Hide the graph's inbuilt scrollbar and use separate System Horizontal Scrollbar. Monitor the events from the Graph and Scrollbar and on any change redisplay the data. In fact, I would only display the visible data in the graph: that which is in view and decimated if too many points are in view (no more than a couple thousand points). By keeping the number of points written to the Graph low you’ll get very fast updates, and the user won’t notice that the Scrollbar isn't an inherent part of the Graph.
This is an application of a technique described by mje for similar large-data issues with Listboxes.
— James
As an aside, I would use my new favorite tool, SQLite (here, or here), to actually hold and serve up the data. I believe one could even delegate the decimation to SQLite via an appropriate “GROUP BY” clause in the data “SELECT” statement. I’ve used mje’s technique and SQLite in an error and data logger that can handle large log databases very quickly (and very cleanly — complicated code like your decimation function becomes single-line SQL statements). The User cannot tell that the multicolumn listbox isn’t actually listing 30,000 log entries, even as they drag the scrollbar up and down.
-
 1
1
-
-
Yep, the JKI template doesn't support interrupts.
If all one wants is “abort” functionality then that is easily addable to a JKI template. One has use a separate method of receiving the abort command (such as the notifier in Daklu’s example, or just a terminal to poll).
I have in the past used something like this, with three extra cases added to the template:
1) “Check for Abort” which checks whatever you use as an abort signal and if true calls “Abort"
2) “Abort”, which if called takes the sequence queue (actually a string) and throws way all text up to the word “Jump_Here_On_Abort:” (throwing away everything if that word is not present).
3) “Jump_Here_On_Abort:”..“Jump_Here_On_Abort:~”, which doesn’t actually contain any code; it’s just a marker used by “Abort"
Note that any statement placed after Jump_Here_On_Abort: will execute only if “Abort” is called.
Then you write macros where you explicitly check for abort, at places in the sequence where you are sure it is OK to abort.
For example:
Macro: Ready equipment
Check for Abort
Macro: Step one
Check for Abort
Macro: Step two
Check for Abort
Macro: Step three
Jump_Here_On_Abort: Macro: Execute this only on abort
Macro: Equipment to Standby
One can add a similar functionality to an all-subVI design by using a “Check for Abort" subVI that throws an error on abort, with Jump_Here_On_Abort: replaced by your error-handling code.
— James
-
The event structure. Events are handled in the owning vi.
I may not understand the architecture in question. As I understand it, if you have a subVI Front Panel in a subpanel of the main VI, then clicks on that (sub)Front Panel trigger events in the subVI’s event structure. And Alex is going to communicate this to the main VI via a queue, with the main VI talking back via a User Event. Should all work fine.
-
Which events don’t work in subpanels?
-
You’re not going to get much argument Alex. I’m the one advocating QSMs, yet I’m strongly against the common single-queue designs where user input can interfere with an executing macro (in the JKI template, for example, the Event structure is only run in the “idle” case, which executes only when the internal sequencing queue is empty). I don’t even like macros potentially interfering with each other by enqueuing on the back.
-
First off I want to make it clear…
I think I should restate how I use the JKI.
Mostly I use it for something that either is a UI or incorporates the UI. I use the cases of the case structure not to replace subVIs in general, but instead:
1) code closely related to the UI (where with a case one can use terminals and locals, and one can find the property nodes from the front-panel control right-click menu).
2) high-level code that if in a subVI would be a method of the “clustersaurus” cluster/object and would mainly be called in a simple chain connected by the clustersaur. Calling these instead as a “macro” doesn’t really lose any clarity.
At finer levels of abstraction I use subVIs (basically, once I’m writing methods on components of the clustersaur). I do not, thus, "break down each function into small pieces to improve reusability”, at least not with cases. Your complex, enqueue-at-back example strikes me as something that should really be handled at this level (as a single case or clustersaur method). Or simplified, such as by subsuming both C and D under B (so B enqueues in front either C or CD). I am not an advocate of very complex branching logic in the QSM.
As I use cases as an alternate to (some) subVIs, I tend to use them like subVIs in that one subVI can “contain” another subVI call. By enqueuing on front, and not having external writers to the internal queue, I can mentally abstract “macros” as unified operations independent of other macros (example: “Macro: refresh main table” refreshes the main display table, it doesn’t depend on what I enqueue after it).
Second, my thoughts and comments about state machines are almost always directed at 2L1Q QSMs, not JKI's SM.Using a single queue for both internal sequencing and inter-loop communication is a major flaw, IMO. All “QSM”s should use two queues.
— James
-
So I've mentioned before my criticisms are aimed at the multi-loop QSMs commonly produced by beginning/intermediate developers. Single loop QSMs like the JKI SM do solve the problem of race conditions by virtue of separating the message transport and the function sequence, and they are harder to screw up than the typical multi-loop QSM. On the other hand, combining the UI event producer (the event structure) and event consumer (the case structure) into a single loop also has side effects that may not be acceptable to the end user. (Like an unresponsive UI.)
Sorry, I didn’t understand this comment. It’s easy to make a multi-loop with a function sequence independent of the inter-loop message queue.
No they aren't. JKI splits the message transport and function sequence into separate elements. That's good; it helps eliminate race conditions. But they specifically allow items to be placed on either the front or the rear of the function sequence in any case statement. If it can be done there needs to be guidelines explaining when it should or should not be done.I agree. I realized my mistake there and edited my post.
Okay, so sometimes you break the rules. We all do. The question is how do you know when it is okay to break them? What do you do to make sure breaking the rule will not introduce unwanted side effects?...
I'm interpreting this to mean these rules are sufficient to implement any arbitrary sequence of functions. After all, the most often cited benefit of the QSM is it's flexibility, right?
I was thinking more about code clarity. Do it the clear and simple way and reserve the arbitrary sequence for when it is really necessary. They’re not rules, there guidelines. And they aren’t complete. Sorry, I realize I wasn’t really meeting your challenge.
Here's another one:Sequence 3: A; X; B; X; C; X; D; Where X=True aborts the remainder of the sequence.
Can you implement this in JKI's QSM? Yep, but can't implement it if you only put items on the front of the queue. Your rules are incomplete. You have to be able to flush the queue too.
“Abort” does involve manipulation of the queue (partial flush) that would be against the normal “rules”. No enqueuing on the end, though.
[Edit]
And another one:
Sequence 4: A; B; if B = True then append D; C; if C = 4 then append E; {D;} {E;}
There's no obvious way to implement this functionality at all without being able to add things to the end of the queue or examining the contents of the queue and maintaining sequence specific information in the clustersaur.
Is this kind of thing common? Why can’t D happen right after B? Why does C have to happen in between? And why can’t E happen after C? Even if you did this in subVIs it would seem a bit strange to me. Though certainly far clearer in subVis.
Gotta go...
— James
-
Simple Rules:
1. Only the producer (UI loop), not the consumer (QSM), is permitted to put items on the queue.
2. Always put items on the rear of the queue.
If developers follow these rules they will not have race conditions. But nobody does because it takes away one of the primary features people like about QSMs--the ability to interrupt an ongoing process.
Difficult Rule:
1. It is okay for both the producer and consumer loops to manipulate the queue as needed, provided the manipulation does not introduce unintended side effects.
The rule is correct. ...
Like the simple rules; don’t like the difficult one. And the simple rules are followed by the JKI template. (2) is absolute because the message “queue” in the JKI is an event registration and you can only add to the end of the queue. (1) can be broken with Value(signaling) nodes and User Events (I sometimes use the first to initialize the UI) but it is easy to follow with the JKI.
The simple rules can be followed with the JKI because it uses a separate queue for internal “operations”. This has different rules:
1. Only write from one process (enforced in the JKI by using a by-value queue implementation).
2. Always put items on the front of the queue.
However, these rules aren’t the one I was talking about, as they CAN be built into a good “QSM” design. And should be. Like the JKI.
[Edit: actually, JKI doesn’t enforce or guide one to put items only on the front of the internal queue. Wish it did.]
— James
-
If I had to do that exact same fp update in response to more than one message, the first thing I'd do is copy and paste using local variables. Eventually I'd move the limit checking logic to a sub vi. Yeah, it does cause some code duplication. IMO that's the lesser of two evils in this situation.
To me the evils are in the opposite order. Having the case-structure cases all correspond to atomic operations is certainly nice, but I really don’t like copying the UI update code. I don’t particularly like doing UI work by property nodes in subVI either (I like to be able to find the property nodes by right-clicking on the control, or vis versa).
BTW, looking at the “Track History” VI does make me admit something: QSMs give you enough rope to hang yourself. QSMs give you a lot of flexibility; they don’t force you to follow narrow rules. But this doesn’t mean you shouldn’t be following the rules! Most of the time at least. And if you don’t know what the rules are then the QSM structure isn’t really going the guide you to them. So I would advise anyone using QSMs to understand the good arguments against them, not necessarily to stop using them, but to understand the rules, which you need to understand to use QSMs effectively.
-
Serial devices can be quite slow, so you have probably flushed the buffers long before the device sends back its response (including the echoed command).
Since you know what the command string was, you can easily strip it off the front of the response.
-
The reactor controller is a perfect example of someplace I'd use sub vis instead of sequences cases. The sequence of 5 cases (SimulateReactor, NormalOperatingModel, InstabilityModel, ReadReactorTemp, and IsTempOverLimit?) that executes every 50 ms should be compressed into a single message handling case with sub vis chained together. It would be far easier to understand what is going on than switching between multiple cases.
I just don’t see it. The 5 subVIs chained on some clustersaurous object doesn’t seem that clearer than a JKI macro:
SimulateReactor
NormalOperatingModel
InstabilityModel
ReadReactorTemp
IsTempOverLimit?
And reordering the sequence or adding/removing actions is very fast with a macro.
I'll admit on rare occasions I do find it more efficient to execute a fixed sequence of case statements instead of putting each one in a sub vi. Here's an example from a recent project I did.Ah, yes, the ability to connect directly to UI indicators and locals is one of the reasons I like using the JKI cases instead of subVIs for the high-level code that interfaces with the UI. But often times a particular UI update needs to be triggered by more than one action; in your design your updates only happen in one message case.
— James
There's more to it than that. Having two event queues behind the scenes occasionally trips people up. In general, there are far more posts asking "Why don't my events work right?" than there are posts asking "Why don't my queues work right?"
Events are more complicated than a simple queue. But not necessarily more complex than a structure you might use instead. Note that if you have a separate loop for UI events that send messages by queue to your main message handler, then you have the exact same ordering issue in the link you gave above (i.e. you could fire a value change event, then enqueue a message, and the order of arrival at the message handler is indeterminate.
The topology I've now adopted for inter-process comms is a queue for the control, and events for response. This gives a Many-To-One for control (great for controlling via UI and TCPIP) and a One-to-Many for the response. A queue for the response has inherent problems with leftover messages and difficulties with permeating the messages to other processes. However, with Events you can easily add monitors to the response and dynamically register other subsytems to the messages (errors for example).
I use one Queue (or User Event) per receiving process and to get One-to-Many I have the senders maintain an array of the receivers’ Queues. A difference with this from User Events is that instead of the sender needing to pass the User Event to the receiver in order to set things up, the receiver has to get it’s queue reference passed to the sender (in a “registration” message).
-
For instance, I'm not at all fond of the practice of using cases as a substitute for sub vis.
I mostly use subVIs for lower-level operations, with cases for the high-level operations. At the high level I don’t find any advantage to subVIs; a “macro” of JKI commands just becomes a long chain of subVIs. The cases have no reusability like a subVI, but the higher level is application-specific so that doesn’t matter.
It is perhaps way too easy to carry on using cases down into the low-level operations that really should be subVIs. I did make that mistake at first.
Another thing I don't like is using user events for the primary communication transport between loops. Events are... quirky. Every so often a thread springs up with somebody having a weird issue with events not behaving how they expect. (Somewhere in the back of my head I have the notion that multiple event structures on a single block diagram is dangerous, but the memory is vague and could be wrong.) Events favor broadcast or observer-based systems and I've described on other threads why I don't like those. Queues are far more transparent, predictable, controllable, and just easier to work with.I’m not sure Events are actually quirky, rather than just people mistakenly using the same event registration in more than one event structure.
I use the JKI and Events with VIs that have a UI. I tend to use queues for non-UI loops (I assume they have less overhead). And I tend not to use Events as broadcast or one-to-many communication methods.
-
I need to implement a temperature control by changing the voltage of a power supply connected to a heater.
I don't have PID toolkit, but I know how PID theorically works.
Years ago I implemented the algorithm from this link. It’s not that hard to write in LabVIEW. It’s my oldest bit of code still in use (and I would be embarrassed to post it), but I’ve found it very reliable.
— James
-
BTW, you know those three rules of thumb I gave you to get started on multi-loop programming? They are not generally accepted by the larger LV community. You might find yourself having to defend your decision to follow them if you post code or questions online. We who distrust QSM designs are still in the minority. Just giving you a heads up...
The JKI template follows (or at least allows one to follow) those three good rules. It has one message receiving system and has no need to send messages to itself nor have messages that must be executed in a specific order. It does this by keeping a separate, internal-only, by-value queue for actual operations (actually a string). This makes it a lot better than many/most “QSM” designs.
-
Are you aware of the “Measurement and Automation Explorer” or “MAX”? This is a NI application that should install with LabVIEW (I think it should exist on Mac OSX versions). It is used to set up “Tasks” that can be called within LabVIEW (and as asbo points out, there should be examples to help you at that point).
-
Only last week I had to diagnose a problem with one of these units in a new application, and the problem was they didn’t read the manual before wiring it up for 5VDC output (it’s TTL current-sink and they wired it as current-source). So I can’t really tell what kind of help the OP needs.
-
- Popular Post
- Popular Post
By reading the manual and trying it out. At least until you can come up with a more specific question.
-
3
-
My biggest suggestion is to use the JKI template as is. It’s a tested and well-thought-out design. If you need a second process, you can use another JKI SM or a simpler queue-run process.
As to your current design:
1) as Daklu mentioned, don’t have two different receiving mechanisms in the same loop; use a User Event to communicate through the event structure.
2) A subtler flaw is that the loops use the same queue for internal operations and for receiving messages from external processes. This can lead to race-condition bugs as various processes queue up sets of messages at the same time. The JKI template uses a separate queue (actually a string) for internal operations.
— James
Oh, and instead of the functional global, consider using a “Message” system like Daklu’s Lapdog package for getting data between loops.
-
I'll try different things, see how they work out and post back.
Are you planning on using an Xcontrol? The thing I’ve done that is most similar (I think) to what you are doing is an Xcontrol that allows the User to configure a list of “Actions” that they want the equipment to perform. The “actions” were an array of objects that were the datatype of the Xcontrol. The Xcontrol, containing a Table rather than a Listbox, allowed the user to configure each action via direct data entry or User menus. I’ll attach it in case it gives you any useful ideas. Note that it was never really polished or tested as the project it was for was discontinued. Probably not commented either. Oh, and working with Xcontrols can be a pain.
— James
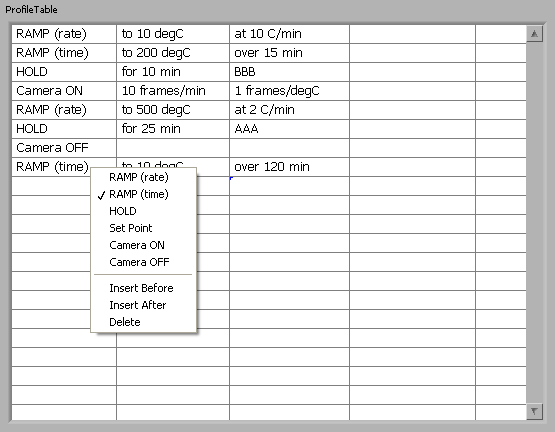
-
My first thought is that a listbox is just a UI element for display purposes, and your real classes are “Users” and “Test Info”, which don’t had any obvious reason to inherit from the same parent class. Design them that way, and include a method in each called “Listbox Entries” that returns the necessary info to fill a listbox.
-
There are a few LabVIEW examples that might help, including “DateServerUsingStartAsynchronousCall.vi” that shows how to pass off new connections to a dynamically launched VI as ned mentioned.
-
I've found adapters to be a simpler and more flexible solution in nearly all cases where I wanted to use an Interface.
I had wondered about that, once I understood interfaces to have strict rules about private data, as one can’t make an interface the descendant of any class that has any private data.
I hope it didn't come across as overly critical of your efforts. I sat on the response for a couple hours trying to decide whether to post it as is or rewrite it to soften it up. Eventually I decided I didn't have the time or energy to rewrite it. Laziness triumphs again!Oh, it was just an idea I threw together in response to this conversation. Anyway, criticism is better than apathy.

-
Thanks Daklu, that helps me understand “Interfaces” better. I hadn’t appreciated the fact that interfaces should have no private data themselves, and I see now how your implementation can work with by-value objects (I suggest adding a by-value example if you ever have the time). My design above was motivated by what I perceived as a desire to create some kind of combined object that can simultaneously belong to two independent inheritance trees (complete with the private data of both trees).
-
I've done that before, but ultimately abandoned it for a couple reasons:
1. I prefer to have all code related to object initialization (or default values) contained in a single place.
2. It's nice to be able to see the values when I probe the class wire.
Depends how many default values you have. If you’re carrying along a dozen constants you’ll have complex “Create” methods and generic probes which are well nigh unreadable. Note that a custom probe can call the classes methods in order to display the values. I usually put a method called “Text description” in any class hierarchy that gives a clear-english description of only the important information of the object; this makes making custom probes or other debug or logging tools easier.
Martin: a slight variation on drjdpowell's suggestion, which works if it is not a constant: Add the value and a Boolean "has been set?". The data accessor VI that returns the value first checks the Boolean. If the value has never been set, it returns the default for that class (call the dynamic dispatch function exactly as described by drjdpowell above). If it has been set, it returns whatever value has been stored into the object.
Yes. And that method will work with parameters that don’t have non-physical values (like −1 wheels).
Fixing the Waveform Graph
in User Interface
Posted
There’s actually three LabVIEW interfaces to SQLite that you should look into: mine, Shaun’s, and one on the LabVIEW Tool Network by SAPHIR. I’m hoping to get mine into OpenG in the next few months.